







笔者课余时间刷完了代码随想录中【数组】章节的所有算法题,在此做一个总结,记录思路和一些想法,方便后续复习查阅。
文章目录
1,二分法
二分法基于分治策略,每次将搜索区间分为两部分,通过比较目标值与中间元素的大小,确定目标值可能存在的区间,然后继续在该区间内搜索,直到找到目标值或者确定目标值不存在为止。
704.二分查找
题目描述:给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
题解:
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while(left <= right){
int middle = left + (right - left) / 2;
if(nums[middle] > target){
right = middle -1;
}
else if(nums[middle] < target){
left = middle + 1;
}
else{
return middle;
}
}
return -1;
}
};
思路:二分法的目的在于将算法复杂度O(n)降低为O(logn),本题思路在于使用二分法不断缩小搜索区间来定位目标值,初始化两个指针left和right,分别指向搜索区间的左右边界,将中间值middle与目标值进行比较,若大于,则说明目标值在middle的左侧,则搜索右边界更新到middle的左边,反之同理,直到查询到或者未查询到;
- middle的防溢出计算:测试用例的nums.size()可能是个int型上限的值,因此直接
int middle = (left + right) / 2;可能会出现溢出情况,于是采用int middle = left + (right - left) / 2;代替,防止溢出 - 边界指针更新:更新为middle ± 1而不是middle,因为在判断条件里middle已经不等于目标值了,所以要额外内收一位缩小搜索范围,同时也为循环结束判断伏笔
- 循环结束条件:搜索边界指针不断内收,在二者相等时,左右边界是刚更新完成,中间还有一个元素没有检查,这个元素有可能就是目标元素,因此不能跳出循环;若这个元素不是目标值,则左或右边界会出现收缩过度的情况,此时即可结束循环,因此循环结束条件为
left <= right而不是left < right - 改进思路:可以添加一些输入验证,例如检查数组nums是否为空。如果nums为空,直接返回 -1,这样可以提高代码的健壮性
35.搜索插入位置
题目描述:给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
题解:
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
// 左边界索引
int leftIndex = 0;
// 右边界索引
int rightIndex = nums.size() - 1;
int midIndex;
while (leftIndex <= rightIndex) {
midIndex = leftIndex + (rightIndex - leftIndex) / 2;
// 如果中间元素大于目标值,目标值在左半区间
if (nums[midIndex] > target) {
rightIndex = midIndex - 1;
}
// 如果中间元素小于目标值,目标值在右半区间
else if (nums[midIndex] < target) {
leftIndex = midIndex + 1;
}
// 找到目标值,返回其索引
else {
return midIndex;
}
}
// 未找到目标值,返回目标值应插入的位置(rightIndex + 1)
return rightIndex + 1;
}
};
思路:与【704.二分查找】相似,仍然是使用二分法降低时间复杂度,区别在于未找到目标值时,需要返回顺序插入的位置,这个位置可以由搜索区间的边界指针计算得到
- 目标值插入位置:当目标值不存在于数组中时,right是最后一个小于目标值的元素索引,所以目标值应该插入到
right + 1的位置 - 代码风格优化:先前的变量left、right和middle表意不够清晰。可以使用更具描述性的名称,比如leftIndex、rightIndex和midIndex,这样能让代码的可读性更强;在关键代码处添加注释可以提高代码的可理解性;增加空行,体现代码层次感
34. 在排序数组中查找元素的第一个和最后一个位置
题目描述:给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
题解:
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int left = searchLeftRange(nums, target);
int right = searchRightRange(nums, target);
vector<int> result(2);
result[0] = left;
result[1] = right;
if(left == -1 || right == -1) return {-1, -1};
return result;
}
private:
int searchLeftRange(vector<int>& nums, int target){
int left = 0;
int right = nums.size() - 1;
int middle;
int leftrange = -1;
while(left <= right){
middle = left + (right - left) / 2;
if(nums[middle] < target){
left = middle + 1;
}
else{
right = middle - 1;
if(nums[middle] == target)
leftrange = middle;
}
}
return leftrange;
}
int searchRightRange(vector<int>& nums, int target){
int left = 0;
int right = nums.size() - 1;
int middle;
int rightrange = -1;
while(left <= right){
middle = left + (right - left) / 2;
if(nums[middle] <= target){
left = middle + 1;
if(nums[middle] == target)
rightrange = middle;
}
else if(nums[middle] > target){
right = middle - 1;
}
}
return rightrange;
}
};
思路:二分法的一种变体,分别寻找左右边界,当寻找到目标值时,先保存为待定边界,然后继续缩小范围,直到全部查询结束
- 保存边界:两个边界查询函数的区别在于
if(nums[middle] == target)的位置,当nums[middle] > target时,说明目标值在middle的左边,当nums[middle] == target时,middle可能位于多个target的中间,此时若要寻找左边界,则需要将搜索区间放到左半边,即我们真正的目标值变成了target左边界,所以nums[middle] > target应该和nums[middle] == target一起处理,使右边界赋值为middle - 1 - 改进:searchLeftRange和searchRightRange函数中有较多相似的代码逻辑。可以考虑将公共部分提取出来,形成一个更通用的二分查找函数,然后通过不同的参数或者条件来实现查找左边界和右边界的功能,提高代码的复用性和可维护性
改进后的代码如下:
class Solution {
public:
// 主函数,用于查找目标值在数组中的起始和结束位置
vector<int> searchRange(vector<int>& nums, int target) {
// 检查输入数组是否为空,如果为空,直接返回{-1, -1}
if (nums.empty()) {
return {-1, -1};
}
int leftBoundary = findBoundary(nums, target, true);
int rightBoundary = findBoundary(nums, target, false);
vector<int> result(2);
result[0] = leftBoundary;
result[1] = rightBoundary;
// 如果左边界或右边界为 -1,表示未找到目标值,返回{-1, -1}
if (leftBoundary == -1 || rightBoundary == -1) {
return {-1, -1};
}
return result;
}
private:
// 通用的二分查找边界函数
int findBoundary(vector<int>& nums, int target, bool isLeft) {
int left = 0;
int right = nums.size() - 1;
int middle;
int boundary = -1;
while (left <= right) {
middle = left + (right - left) / 2;
// 如果当前中间值与目标值的比较满足条件
if ((isLeft && nums[middle] >= target) || (!isLeft && nums[middle] <= target)) {
// 更新边界值
if (nums[middle] == target) {
boundary = middle;
}
// 根据是查找左边界还是右边界,调整搜索区间
if (isLeft) {
right = middle - 1;
} else {
left = middle + 1;
}
} else if (nums[middle] > target) {
right = middle - 1;
} else {
left = middle + 1;
}
}
return boundary;
}
};
- 将查找左边界和右边界的功能合并到一个findBoundary函数中,通过isLeft参数来区分是查找左边界还是右边界,提高了代码的复用性
- 变量命名更加清晰,leftBoundary、rightBoundary和boundary等名称更准确地表达了变量的含义
69. x 的平方根
题目描述:给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
示例 1:
输入:x = 4
输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842…, 由于返回类型是整数,小数部分将被舍去
题解:
class Solution {
public:
int mySqrt(int x) {
int left = 0, right = x; //优化:int left = 0, right = x / 2 + 1;
while(left <= right){
int middle = left + (right-left)/2;
if((long long)middle * middle > x){
right = middle - 1;
}
else{
left = middle + 1;
}
}
return left - 1;
}
};
- 防止整数溢出:在比较middle * middle和x的大小时,将middle强制转换为
long long类型,以防止当x较大时middle * middle溢出,这保证算法正确性的关键步骤 - 效率优化思路:可以利用数学性质优化算法,对于较大的x,可以先通过一些简单的计算来缩小搜索区间,比如x的平方根一定小于等于x / 2 + 1(当x >= 4时),可以将right初始化为x / 2 + 1,这样可以减少二分查找的迭代次数
367. 有效的完全平方数
给你一个正整数 num 。如果 num 是一个完全平方数,则返回 true ,否则返回 false 。
完全平方数 是一个可以写成某个整数的平方的整数。换句话说,它可以写成某个整数和自身的乘积。
示例 1:
输入:num = 16
输出:true
解释:返回 true ,因为 4 * 4 = 16 且 4 是一个整数
示例 2:
输入:num = 14
输出:false
解释:返回 false ,因为 3.742 * 3.742 = 14 但 3.742 不是一个整数
题解:
class Solution {
public:
bool isPerfectSquare(int num) {
int left = 1;
int right = num;
while(left <= right){
int middle = left + (right - left) / 2;
long square = (long) middle * middle;
if(square > num){
right = middle - 1;
}
else if(square < num){
left = middle + 1;
}
else{
return true;
}
}
return false;
}
};
- 防止整数溢出:在计算middle的平方square时,将middle转换为long类型,避免了在计算较大数的平方时可能出现的整数溢出问题,保证了算法的正确性
- 与上题相同采用二分法查找平方根,查找不到则返回false
- 特殊情况处理:可添加对特殊情况的处理,如num为0或1时的快速判断逻辑,虽然当前代码对这些情况也能正确处理,但添加显式判断可以使代码逻辑更加清晰
2,双指针法
双指针法通常使用两个指针来遍历数据结构(如数组、链表等),通过巧妙地移动指针来解决问题。这两个指针可以有不同的移动策略,在代码随想录的数组章节中,主要用到快慢指针和滑动窗口两种方式,区别在于快慢指针主要侧重于两个指针以不同速度移动来处理数据,重点是利用速度差;而滑动窗口更强调维护一个窗口,通过调整窗口的左右边界来包含或排除元素,重点是窗口内元素的整体性以及窗口大小的控制。
双指针法经常用在原地操作数组的场景;
27. 移除元素
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2,,]
解释:你的函数函数应该返回 k = 2, 并且 nums 中的前两个元素均为 2
你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3,,,_]
解释:你的函数应该返回 k = 5,并且 nums 中的前五个元素为 0,0,1,3,4
注意这五个元素可以任意顺序返回。
你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)
题解:
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int slowindex = 0;
for(int fastindex = 0; fastindex < nums.size();fastindex++){
if(nums[fastindex] != val){
nums[slowindex++] = nums[fastindex];
}
}
return slowindex;
}
};
- 核心思路在于快慢指针,快指针用于快速遍历原数组的每一个元素,相当于for循环中的
int i;慢指针仅在符合某种特殊条件时,才进行移动,进行覆盖等操作; - 本题中快指针进行遍历,慢指针移动条件为快指针遍历到的元素不等于目标值,由此达到
26.删除有序数组中的重复项
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
题解:
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int slowindex = 1; //num[0]是必定放入的,所以快慢指针都从1开始
for(int fastindex = 1; fastindex < nums.size(); fastindex++){
if(nums[fastindex] != nums[fastindex - 1]){
nums[slowindex++] = nums[fastindex];
}
}
return slowindex;
}
};
- 核心思路在于快慢指针处理,快指针进行遍历,慢指针检查当前元素是否与上一个元素重复,重复则跳过
- 本题中快慢指针都初始化为1,防止检查重复时,nums[fastindex - 1]的索引为-1
283.移动零
题目描述:给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12]
输出: [1,3,12,0,0]
示例 2:
输入: nums = [0]
输出: [0]
题解:
class Solution {
public:
void moveZeroes(vector<int>& nums) {
int slowindex = 0;
for(int fastindex = 0; fastindex < nums.size(); fastindex++){
if(nums[fastindex]){
swap(nums[slowindex++],nums[fastindex]);
}
}
}
};
- 核心思路是快慢指针,本题中0元素会阻碍慢指针的移动,只有快指针指向元素非0时,才将非零元素置换覆盖到指针位置,形成覆盖操作;
844. 比较含退格的字符串
题目描述:给定 s 和 t 两个字符串,当它们分别被输入到空白的文本编辑器后,如果两者相等,返回 true 。# 代表退格字符。
注意:如果对空文本输入退格字符,文本继续为空。
示例 1:
输入:s = “ab#c”, t = “ad#c”
输出:true
解释:s 和 t 都会变成 “ac”。
示例 2:
输入:s = “ab##”, t = “c#d#”
输出:true
解释:s 和 t 都会变成 “”。
示例 3:
输入:s = “a#c”, t = “b”
输出:false
解释:s 会变成 “c”,但 t 仍然是 “b”。
题解:
class Solution {
public:
bool backspaceCompare(string s, string t) {
return outstring(s) == outstring(t);
}
private:
string outstring(string in){
int slowindex = 0;
for(int fastindex = 0; fastindex < in.length(); fastindex++){
if(in[fastindex] != '#'){
in[slowindex++] = in[fastindex];
}
else{
if(slowindex) slowindex--;
}
}
return in.substr(0, slowindex);
}
};
- 核心思路是快慢指针,快指针遍历到’#'时,慢指针退回一格,即指向了最后一次赋值的元素,下一次快指针指向非#时,将对慢指针指向的元素进行覆盖,从而达到删除的效果;
- 截取操作:通过 return in.substr(0, slowindex); 返回从字符串开头到 slowindex 位置的子字符串
977.有序数组的平方
题目描述:给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
题解:
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int first = 0;
int last = nums.size() - 1;
vector<int> result(nums.size());
for(int i = 1; i <= nums.size(); i++){
if((nums[first] * nums[first]) > (nums[last] * nums[last])){
result[nums.size() - i] = nums[first] * nums[first];
first++;
}
else{
result[nums.size() - i] = nums[last] * nums[last];
last--;
}
}
return result;
}
};
- 核心思路为双指针法,比较开头和末尾两个指针所指元素平方的大小,更大的优先放入结果数组的后位
209. 长度最小的子数组
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
题解:
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int result = nums.size() + 1;
int i = 0, sum = 0;
for(int j = 0; j < nums.size(); j++){
sum += nums[j];
while(sum >= target){
int sublength = j - i + 1;
result = result > sublength ? sublength : result;
sum -= nums[i++];
}
}
if(result == (nums.size() + 1)){
return 0;
}
return result;
}
};
- 核心思路为滑动窗口法,维护一个窗口(由指针 i 和 j 界定,i 指向窗口的起始位置,j 指向窗口的末尾位置),关键在于窗口扩大和缩小的处理
- 窗口扩大操作:窗口末尾位置
j会在窗口内总和小于target时,往右扩充一位,直到总和大于target - 窗口缩小操作:在内置while循环中,若窗口内总和大于
target,左边界i会往右移动,直到总和小于target
904. 水果成篮
示例 1:
输入:fruits = [1,2,1]
输出:3
解释:可以采摘全部 3 棵树。
示例 2:
输入:fruits = [0,1,2,2]
输出:3
解释:可以采摘 [1,2,2] 这三棵树。
如果从第一棵树开始采摘,则只能采摘 [0,1] 这两棵树。
示例 3:
输入:fruits = [1,2,3,2,2]
输出:4
解释:可以采摘 [2,3,2,2] 这四棵树。
如果从第一棵树开始采摘,则只能采摘 [1,2] 这两棵树。
示例 4:
输入:fruits = [3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:可以采摘 [1,2,1,1,2] 这五棵树。
题解:
class Solution {
public:
int totalFruit(vector<int>& fruits) {
int sum = 0;
int i = 0, result = 0;
unordered_map<int, int> cnt;
for(int j = 0; j < fruits.size(); j++){
++cnt[fruits[j]];
//窗口缩小条件
while(cnt.size() > 2){
auto it = cnt.find(fruits[i]);
--it->second;
if(it->second == 0){
cnt.erase(it);
}
i++;
}
result = max(result, j - i + 1);
}
return result;
}
};
- 核心思路采用滑动窗口法,窗口的边界和上题相同使用
i和j表示,判断是否超过两种水果可以采用哈希表实现(方便去重),这里采用map是为了方便窗口缩小时,擦去窗口被去掉的值 - 窗口缩小条件为哈希表大小大于2,对对应种类水果的数目进行-1,若数目为0则删去条目
76. 最小覆盖子串
示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
解释:最小覆盖子串 “BANC” 包含来自字符串 t 的 ‘A’、‘B’ 和 ‘C’。
示例 2:
输入:s = “a”, t = “a”
输出:“a”
解释:整个字符串 s 是最小覆盖子串。
示例 3:
输入: s = “a”, t = “aa”
输出: “”
解释: t 中两个字符 ‘a’ 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
题解:
class Solution {
public:
unordered_map<char, int> cri, cnt;
bool check(){
for(auto c:cri){
if(cnt[c.first] < c.second){
return false;
}
}
return true;
}
string minWindow(string s, string t) {
int r_l = -1, r_r = -1;
int result = INT_MAX;
int i = 0;
for(int j = 0; j < t.length(); j++){
++cri[t[j]];
}
for(int j = 0; j < s.length(); j++){
++cnt[s[j]];
while(check()){
auto it = cnt.find(s[i]);
--it->second;
if((j - i + 1) < result){
r_l = i;
result = j - i + 1;
}
i++;
}
}
return r_l == -1 ? string() : s.substr(r_l, result);
}
};
- 核心思路为滑动窗口,使用哈希表map存入字符串,从而对各个字符进行计数
- 窗口缩小条件为窗口内字符涵盖目标字符串
- 返回值应用了子字符串,截取左边界开始,长度为result的子字符串
3,模拟遍历
即并不涉及到什么算法,主要为对过程的模拟,考察对代码的掌控能力
59. 螺旋矩阵 II
题目描述:给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
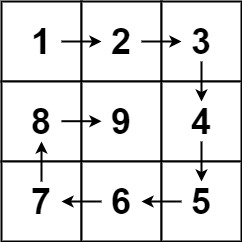
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
题解:
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> res(n, vector(n, 0));
int circle = n / 2;
int nowcircle = 1;
int i = 1;
while(nowcircle <= circle){
for(int j = (nowcircle - 1); j < (n - nowcircle); j++){
res[nowcircle - 1][j] = i++;
}
for(int j = (nowcircle - 1); j < (n - nowcircle); j++){
res[j][n - nowcircle] = i++;
}
for(int j = (n - nowcircle); j > (nowcircle - 1); j--){
res[n - nowcircle][j] = i++;
}
for(int j = (n - nowcircle); j > (nowcircle - 1); j--){
res[j][nowcircle - 1] = i++;
}
nowcircle++;
}
if((n % 2) == 1){
res[n/2][n/2] = n*n;
}
return res;
}
};
- 核心思路为以当前圈数为变量,遍历四个边,最后处理中心的情况
54. 螺旋矩阵
题目描述:给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
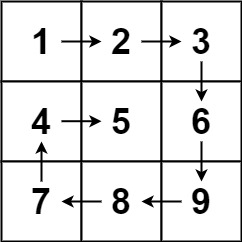
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
题解:
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
int m = matrix.size(); // 行数
if (m == 0) return {}; // 处理空矩阵的情况
int n = matrix[0].size(); // 列数
int left = 0, right = n - 1;
int top = 0, bottom = m - 1;
vector<int> res;
while (left <= right && top <= bottom) {
// 处理顶部行
for (int i = left; i <= right; ++i) {
res.push_back(matrix[top][i]);
}
top++; // 移动顶部边界
// 处理右侧列
if (top <= bottom) { // 防止只有一行的情况
for (int i = top; i <= bottom; ++i) {
res.push_back(matrix[i][right]);
}
right--; // 移动右侧边界
}
// 处理底部行
if (left <= right && top <= bottom) { // 防止只剩一列的情况
for (int i = right; i >= left; --i) {
res.push_back(matrix[bottom][i]);
}
bottom--; // 移动底部边界
}
// 处理左侧列
if (left <= right && top <= bottom) { // 防止只剩一行的情况
for (int i = bottom; i >= top; --i) {
res.push_back(matrix[i][left]);
}
left++; // 移动左侧边界
}
}
return res;
}
};
- 与上一题相似,这里采用边界移动的方式,使得内部for循环更加清晰
- 本题不一定是正方形的结构,所以可能出现只剩下一行或一列的情况,所以加上if判断,避免有些行或列不存在
4,前缀和
可以理解为预处理,前缀和是一种在算法中常用的数据处理技巧,主要用于快速计算数组中某一区间的元素总和。对于一个给定的数组nums,其前缀和数组prefixSum的定义为:prefixSum[i]表示数组nums中从第 0 个元素到第i个元素的总和(包含第i个元素)
58. 区间和
题目描述:给定一个整数数组 Array,请计算该数组在每个指定区间内元素的总和。
输入描述:第一行输入为整数数组 Array 的长度 n,接下来 n 行,每行一个整数,表示数组的元素。随后的输入为需要计算总和的区间下标:a,b (b > = a),直至文件结束。
输出描述:输出每个指定区间内元素的总和。
输入示例
5
1
2
3
4
5
0 1
1 3
输出示例
3
9
题解:
#include<iostream>
#include<vector>
using namespace std;
int main(){
int n, a, b;
cin >> n;
vector<int> Array(n);
vector<int> sum(n);
int presum = 0;
for(int i = 0; i < n; i++){
scanf("%d", &Array[i]);
presum += Array[i];
sum[i] = presum;
}
while(~scanf("%d%d", &a, &b)){
if(a == 0){
printf("%d\n", sum[b]);
}
else{
printf("%d\n", sum[b] - sum[a - 1]);
}
}
}
- 核心思路在于在读入时顺带计算子数组的和,后面输出时重复利用计算过的子数组之和,从而降低区间查询需要累加计算的次数
- 前缀和在涉及计算区间和的问题时非常有用
44. 开发商购买土地
注意:区块不可再分。
输入描述
第一行输入两个正整数,代表 n 和 m。
接下来的 n 行,每行输出 m 个正整数。
输出描述
请输出一个整数,代表两个子区域内土地总价值之间的最小差距。
输入示例
3 3
1 2 3
2 1 3
1 2 3
输出示例
0
题解:
#include<iostream>
#include<vector>
#include<climits>
using namespace std;
int main(){
int n, m;
scanf("%d%d",&n, &m);
vector<vector<int>> vec(n, vector<int>(m, 0));
int sum = 0;
vector<int> horizontal(n, 0);
vector<int> vertical(m, 0);
int res = INT_MAX;
//前缀和,计算每行的总和
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
scanf("%d", &vec[i][j]);
sum += vec[i][j];
horizontal[i] += vec[i][j];
}
}
//前缀和,计算每列的总和
for(int j = 0; j < m; j++){
for(int i = 0; i < n; i++){
vertical[j] += vec[i][j];
}
}
//水平切分
int horizontalCut = 0;
for(int i = 0; i < n; i++){
horizontalCut += horizontal[i];
res = min(res, abs(sum - horizontalCut - horizontalCut));
}
//垂直切分
int verticalCut = 0;
for(int i = 0; i < m; i++){
verticalCut += vertical[i];
res = min(res, abs(sum - verticalCut - verticalCut));
}
printf("%d",res);
}
- 本题感觉难点在于读懂题,本来以为是可以参差不齐地切分,需要注意读题,不能只看输入输出示例



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









