






起因:
发现测试环境的Hbase不能使用,插入数据出现异常,正如上一篇博客所介绍,通过df和du的方式,查看到hbase和Hadoop的log部分占据了大量内存,然后删除一些日志数据后,Hbase 使用不了,具体症状为:
使用Hbase shell语句,查看list,会出现如下异常:Can't get master address from Zookeeper;znode data == null;
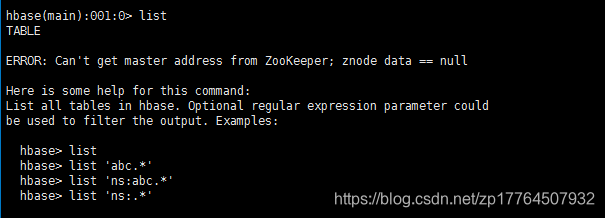
通过Hadoop的相关指令 hadoop dfs -ls /
可以发现如下异常:ipc.Client:Failed to connect to server 或者是Connect refused
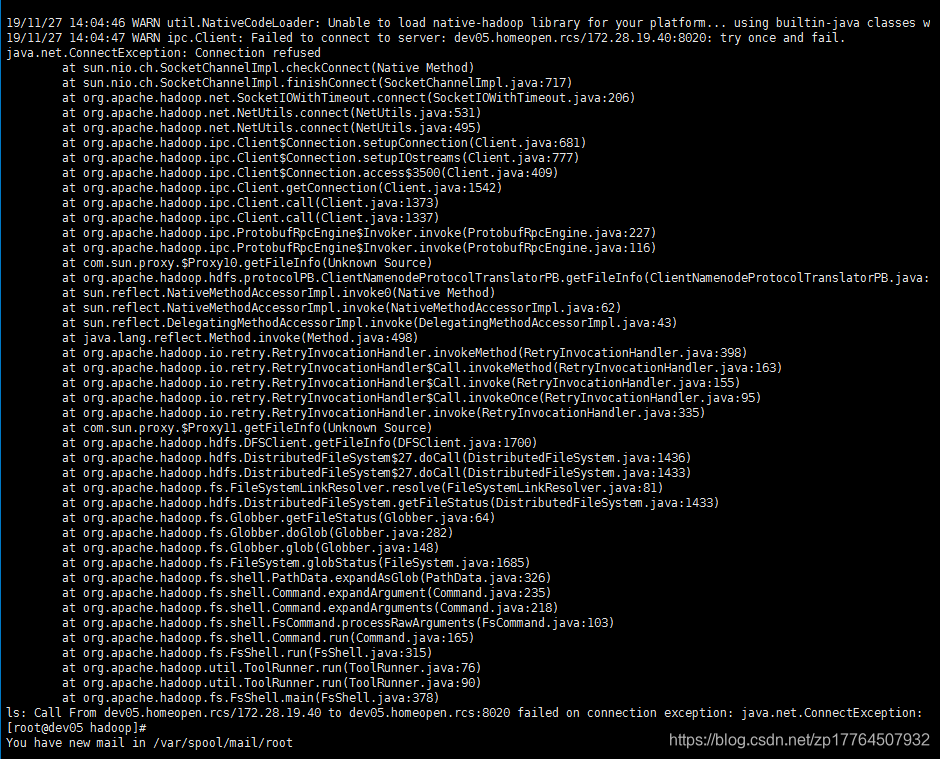
也可以去Hadoop的日志目录去查看,发现同样是这种异常,8020端口是啥呢?
在Hadoop的etc/core-site.xml 里可以看到该配置,具体该配置文件的其他信息可参考core-site.xml的具体意义,
这里,我们可以看master节点和其他两个从节点的jps,只有SecondaryNameNode
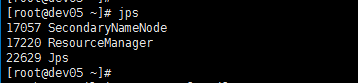
由此得知是nameNode节点无法启动,也就是我们的8020端口无法启动
参考相关文献后,考虑使用格式化Namenode的方式来解决
格式化一下就可以,格式化namenode的命令:在hadoop安装文件夹的bin下输入./hadoop namenode -format。
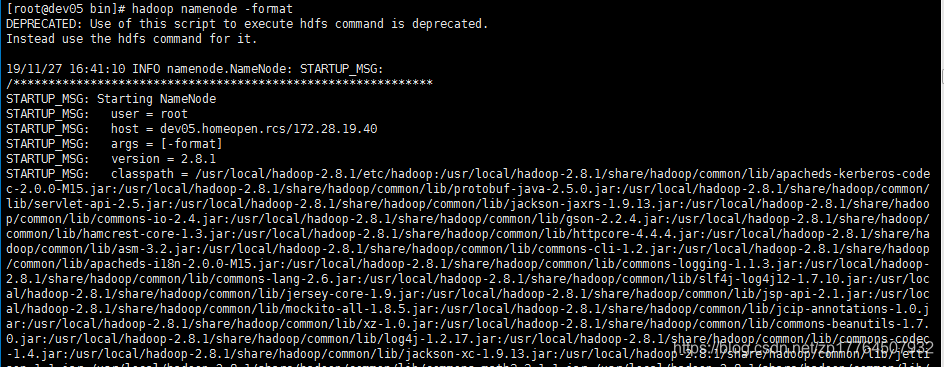
进行格式化的操作
然后再在Hadoop的sbin目录下,执行stop-all.sh,看下jps是否相关进程已停止,然后start-all.sh
然后看我们的jps
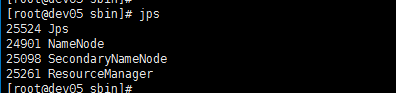
namenode已经启动
查看Hadoop dfs -ls /,也没有发现8020启动异常了

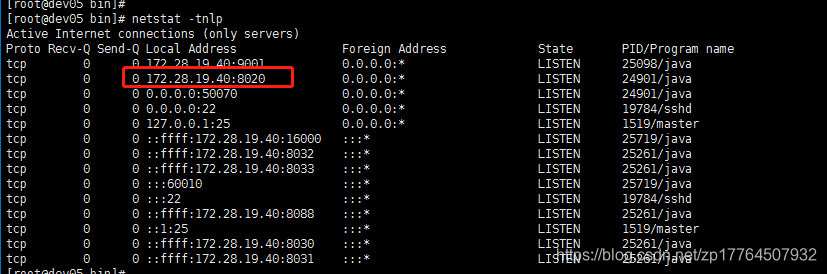
久违的8020已已经看到了,然后去启动hbase的相关部分,
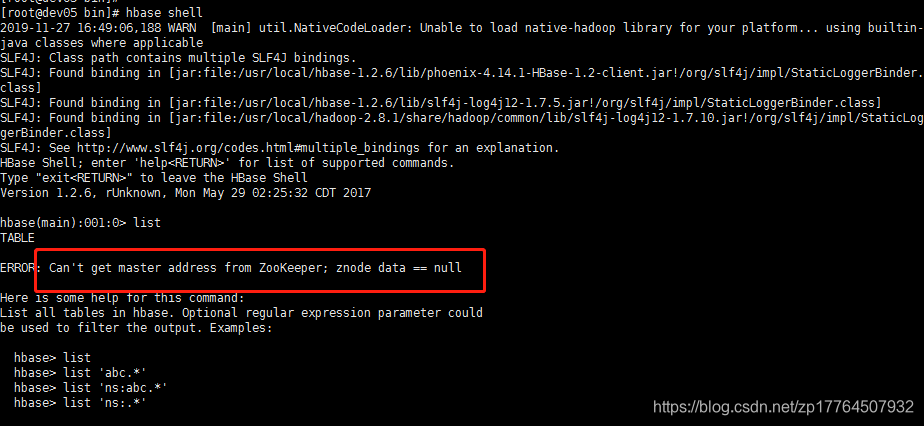
发现还是这个异常,但是之前由于8020的问题已经解决了,那么去看hbase的log相关日志
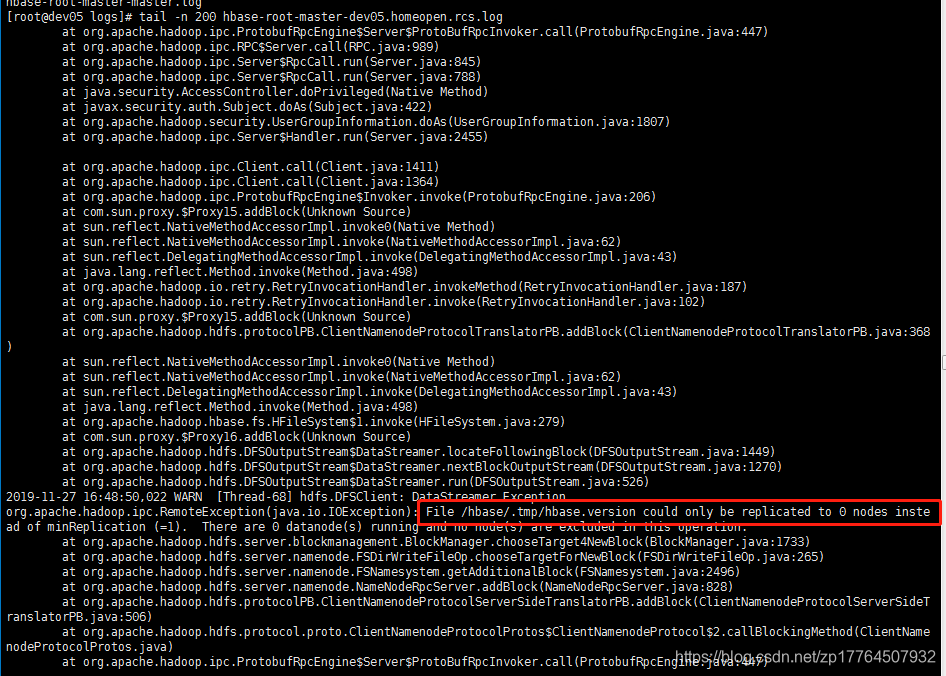
我看到了上面那句,猜测是不是slaver部门的datanode没有启动,于是去slaver服务器查看
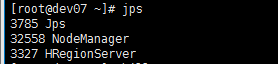
果然,没看到datanode节点启动起来,于是,又去查资料,发现其他人有遇到相关问题,具体表述为:
有时hadoop集群非首次启动时也无法启动namenode,而格式化以后,namenode能够启动了,可是datanode又无法启动。这时仅仅须要删除全部slave节点的data/curren文件夹下的VERSION文件。然后再格式化namenode,重新启动hadoop集群就可以解决这个问题。
OK,照着操作就好。。。。
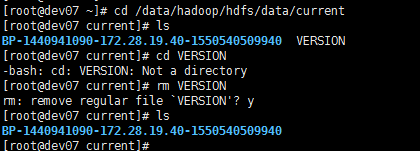
两台服务器,全部操作,干就完事了。。。,操作完后,再来看hbase
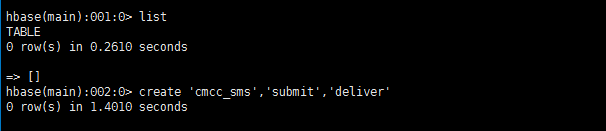
list表不抛异常了,但是表却没了,后来知道是meta区没了,那么咋办呢?只能建表了
于是有了。

纳尼?不是没表吗?怎么还提示存在
【关于Hbase Table already exists的处理方法~!】
原因:hadoop重新格式化后,hdfs上没有了数据,在hbase中新建表却提示Table already exists。是因为以前建过同名的表,虽然HDFS上和Hbase相关的东西都已经删除了。但是zookeeper保存有hbase表的地址,数据访问是通过zookeeper的地址转到hdfs上,这是hbase物理存储结构所决定的。因此需要将Zookeeper中的相应的表也删除。
解决办法:
进入HMaster节点,执行,bin/zkCli.sh
ls /hbase/table,查看是否有要新建的表面,如果有使用rmr命令删除,之后重启Hbase,使用create即可成功。
那么干起来
进入zookeeper服务器(具体怎么查看zookeeper,可以进入hbase的conf文件夹下查看)
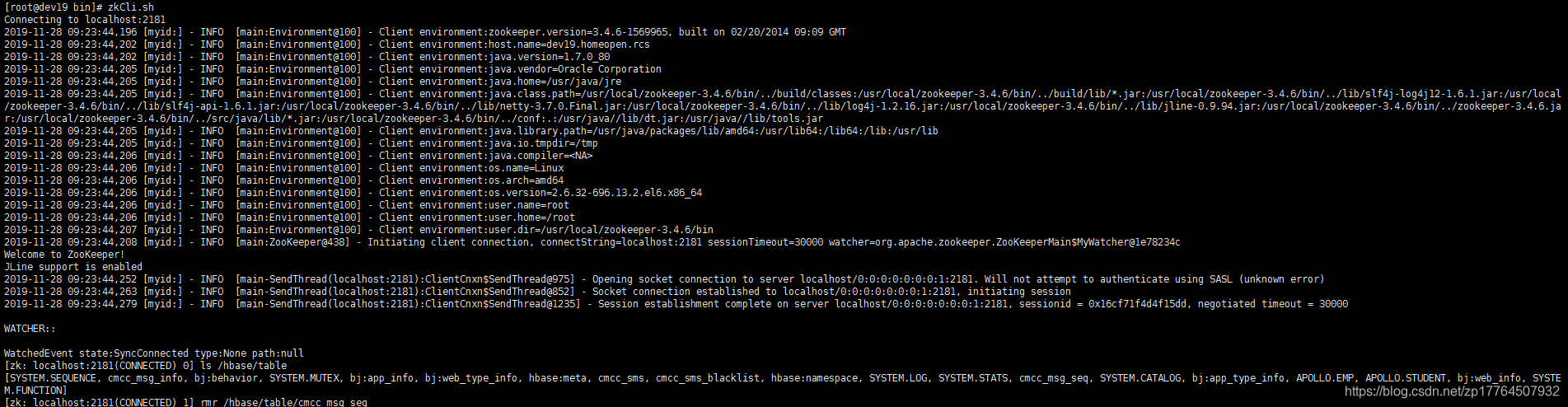
再次建表,
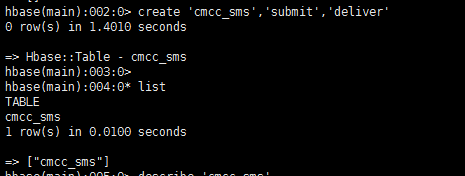
大工告成
后续,记录一下线上regionserver奔溃,通过查找日志,发现出现oom,然后采取调整heap大小的方式来解决问题。
备注:cloudera manager的使用,可以很好地监控hadoop集群的情况


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









