




Linux深入理解内存管理41(基于Linux6.6)---内存规整介绍
一、概述
在深入理解 Linux 内存管理 之前,了解 内存规整(Memory Defragmentation)是非常重要的,它在提高系统内存使用效率和性能方面扮演着关键角色。内存规整涉及将内存中散乱的、无法有效利用的空闲空间整合起来,从而最大化内存的使用效率,减少内存碎片的影响。
1. 内存碎片化
内存碎片化是指内存被分配和释放的过程会导致系统中的空闲内存空间不连续。这些散落的空闲内存块虽然总和可能很大,但因为它们的分布和大小不规则,无法被大型进程或大数据结构所利用。
内存碎片分为两类:
- 外部碎片:指内存中存在许多大小不一、分布零散的空闲内存块,导致无法满足对较大内存块的分配请求。
- 内部碎片:指内存分配时为了满足某些特定的大小要求,可能会分配大于请求内存的块,从而在分配的内存块内部留下浪费的空间。
内存碎片化在长时间运行的系统中尤为明显,尤其是当大量小内存块频繁分配和释放时,外部碎片化的程度就会增加。
2. 内存规整的目的和方法
内存规整的目标是将内存中不连续的空闲内存区域重新整理,使得空闲区域变得更加连续和紧凑,从而便于分配更大的内存块,减少因外部碎片化带来的性能损失。
内存规整主要通过以下方法进行:
- 页面合并(Page Merging):将相邻的空闲页面合并为一个更大的连续空闲区域,减少外部碎片。
- 物理页面压缩:通过内存回收和页面压缩技术,减少不必要的内存占用,并尝试将更多的数据压缩到较小的内存空间内。
- 页表压缩:通过优化页表的数据结构,使得操作系统能够更高效地管理内存空间,减少管理开销。
- 内存回收:通过内存回收机制,及时释放不再需要的内存区域,避免这些区域长时间处于“已分配但未使用”状态。
3. Linux 内存管理中的内存规整
在 Linux 中,内存管理是由内核通过页表(Page Tables)来管理的,系统中的物理内存和虚拟内存之间是通过页框(Page Frame)映射的。内存规整机制需要在这些物理内存和虚拟内存之间协调工作。
以下是 Linux 内存管理中涉及内存规整的一些重要机制:
(1) Buddy 分配器(Buddy Allocator)
Buddy 分配器是 Linux 内存管理中最常见的内存分配算法。其基本思想是将物理内存划分为大小为 2 的幂次方的块,然后将内存划分成多个“伙伴”(buddy),通过合并相邻的空闲内存块来减少外部碎片。
- 当释放一个内存块时,Linux 会检查其伙伴块是否也为空闲。如果是,两个内存块将被合并成一个较大的块。这种方式帮助减少内存碎片化,保证较大内存块的高效使用。
- Buddy 分配器有效地通过分配和合并的策略来实现内存的规整,减少了内存外部碎片的影响。
(2) 内存区域划分:ZONE 和 NUMA
Linux 内核通过将内存分成多个 zone(内存区域)来进行管理。内存区域包括:
- ZONE_DMA:用于存放 16MB 以下的内存,这部分内存一般用于设备访问。
- ZONE_NORMAL:常规内存区域,用于操作系统常规的内存分配。
- ZONE_HIGHMEM:高端内存区域,用于物理内存大于某一特定值的情况,通常在 32 位系统中使用。
- NUMA(Non-Uniform Memory Access):在支持 NUMA 架构的系统中,内存被划分为多个节点,每个节点有自己的局部内存,内存访问速度依赖于访问节点的物理距离。NUMA 通过局部性优化内存访问性能。
内存划分的这些策略使得 Linux 在处理不同内存区域的碎片时能够进行更为高效的规整。
(3) 内存页回收和压缩:
-
页回收(Page Reclaiming):Linux 会通过内存回收机制来定期释放不再使用的内存页,减少长时间未被访问的内存块占用。
-
透明大页(Transparent Huge Pages, THP):为了减少碎片和提高性能,Linux 提供了透明大页功能。大页将多个较小的内存页面合并为一个更大的页面,减少了页表的大小,并提高了内存管理的效率。透明大页功能会自动决定何时使用大页,进而减少了外部碎片。
-
Swap 和压缩内存(zswap, zswap):Linux 支持在内存不足时将部分内存内容压缩后转移到交换空间(swap)或压缩内存区,这可以节省内存空间并减少外部碎片的影响。
(4) 内存压缩
-
Zswap 和 Zram 是 Linux 中两种常见的内存压缩机制。Zswap 将交换数据压缩后存储在内存中,从而减少了对磁盘 swap 的依赖,减少了内存的 I/O 压力;而 Zram 则通过在压缩的虚拟块设备中存储数据来实现内存压缩。
-
内存页合并(KSM, Kernel Samepage Merging):KSM 是 Linux 中一种内存节省技术,能够合并多个进程中相同的内存页面,减少内存的使用。这种机制尤其对虚拟化环境中的内存管理非常有效。
4. 内存规整对性能的影响
内存规整是确保系统高效运行的关键因素之一。它能有效减少内存碎片,最大化物理内存的利用率,从而提高系统的性能。特别是在服务器和高负载环境中,内存规整能够显著降低由于内存碎片带来的性能下降。
- 性能提升:减少内存碎片使得内存的分配和回收更高效,从而减少了内存访问延迟。
- 延迟减少:通过内存规整,系统能够减少因碎片化导致的内存分配失败和页面交换(swap)带来的延迟。
- 更少的 I/O 操作:内存规整减少了对 swap 的依赖,从而减少了磁盘 I/O,提升了系统的整体响应速度。
二、内存规整的基本原理
Linux使用的是虚拟地址,以提供进程地址空间的隔离。它还带来一个好处,就是像vmalloc这种分配,不用太在乎实际使用的物理内存的分配是否连续,因此也就弱化了物理内存才会面临的内存碎片化问题。但是如果使用的时kmalloc,则要求物理内存必须连续,系统中空闲内存的总量(比如空闲时10个page),大于申请的内存大小,但是没有连续的物理内存,我们就可以通过migrate(迁移/移动)空闲的page frame,来聚合形成满足需求的连续的物理内存。
多年来,内核开发人员已经做出各种尝试来缓解这个问题;这些尝试包括[定义新的域 ZONE_MOVABLE和引入 块状回收(lumpy reclaim这样的技术。但是,光有这些还不够,特别是在解决内存碎片以及生成更大的内存块方面。在该领域淡出了一段时间的 Mel Gorman 最近又回来了,并带来了一个新的补丁用于实现 内存规整(memory compaction)。在这里,给大家简短介绍一下这个补丁的工作原理。
假设存在一个非常小的内存域(zone),如下图所示:

页框为白色表示空闲,而红色的是由于某种用途被分配了的页框。可以看出,该域(zone)中的空闲页框非常分散,没有大于两页的连续内存块;如果要从该域中分配包含连续四页的内存块必将失败。实际上,即便是分配包含两页连续的内存也会失败,因为所有连续两页的内存块都不满足伙伴系统对内存分配的对齐要求。
下面来演示一下规整(compaction)算法的工作原理。代码中会运行两个独立的扫描;第一个扫描从域的底部(bottom)开始(如下图所示从左往右进行扫描),一边扫描一边将可以移动(movable)的页框记录到一个列表中:
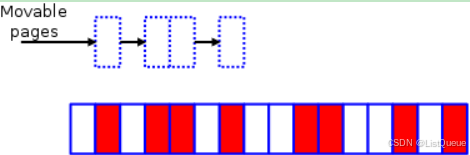
在区域的顶部(top),另一个扫描(如下图所示从右往左)创建另一个列表,用于记录可作为页框迁移目标的空闲页框位置:
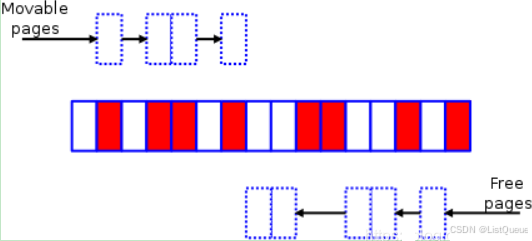
最终,两个扫描会在域中间的某个位置相遇(意味着扫描结束)。此时,剩下的工作主要是调用 页面迁移(page migration)功能(从这里我们可以看到页面迁移的功能已经不仅仅只针对 NUMA 系统)将左边扫描得到的已分配的页框上的内容转移到右边空闲的空间中,产生的结果如下如下所示,规整后的内存看上去是不是很整齐?

现在得到了一个拥有大小为 8 页并且连续的可用空间,可用于满足更 “高阶” 的内存分配。当然,这里展示的流程和真实系统比起来已经大大简化了。特别地,实际的内存域会大得多;这意味着扫描的工作量也会大很多,但由此获得的空闲区也可能更大。
对于内存规整技术,其核心的思想是把内存页面按照可移动、可回收、不可移动等特性进行分类:
- 可移动的页面:是指用户程序分配的内存,移动这些页面仅仅是需要修改页表映射关系,代价很低
- 可回收的页面:是指不可以移动但可以释放的内存
- 不可移动的页面:目前的内核使用的物理页面
所以Linux物理页面规整机制,类似于磁盘整理,主要是应用了内核的页面迁移机制,是一种将可移动页面进行迁移后腾出连续物理内存的方法。
三、触发内存规整
Linux内核中触发内存规整途径有3个途径:
- 手动触发:通过写1到/proc/sys/vm/compact_memory节点,会手动内存规整。它会扫面系统中所有的内存节点上的zone,对每个zone都会做一次内存规整。
- kcompactd内核线程:和页面回收kswapd内核线程一样,每个内存节点都会创建一个kcompactd内核线程,名称为"kcompactd0",“kcompactd1"等。
- 直接内存规整:和页面回收一样,当页面分配器发现在低水位的情况下无法满足页面分配时,会进入慢速路径,在慢速路径中,除了唤醒kswapd内核线程外,还会调用函数__alloc_pages_direct_compact(),尝试整合出一大块空闲内存。
三、内存规整的使用方法
1. 内存规整的核心配置
(1) 内存回收和页合并(Compaction)
Linux 内核在处理内存碎片时,使用了内存回收(compaction)机制。这个机制通过尝试将内存页面移动到一起来减少外部碎片,以便分配更大的内存块。如果系统内存中存在大量碎片,内核会触发内存合并操作。
内核配置选项:
CONFIG_COMPACTION: 这个选项启用内存页合并功能,使内核可以尝试通过内存回收来规整空闲内存区域。
可以通过以下命令查看当前是否启用该配置:
zcat /proc/config.gz | grep CONFIG_COMPACTION
如果未启用,可以在编译内核时启用此选项:
CONFIG_COMPACTION=y
(2) 内存压缩:Transparent Huge Pages (THP)
透明大页(THP) 是减少内存碎片和提高性能的有效手段。启用 THP 后,Linux 会将多个小页合并成一个大页,以减少页表的管理开销,并提高内存访问效率。
相关配置选项:
CONFIG_HUGETLBFS: 启用大页支持。CONFIG_TRANSPARENT_HUGEPAGE: 启用透明大页。
查看是否启用了透明大页:
zcat /proc/config.gz | grep CONFIG_HUGETLBFS
zcat /proc/config.gz | grep CONFIG_TRANSPARENT_HUGEPAGE
THP 是可以在运行时动态启用和禁用的。通过以下命令查看当前 THP 的状态:
cat /sys/kernel/mm/transparent_hugepage/enabled
可以通过以下命令启用或禁用 THP:
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/enabled
(3) Kernel Samepage Merging (KSM)
KSM 是一个用于合并多个相同内存页的功能,可以有效节省内存,尤其在虚拟化环境下。例如,在虚拟机中,多个虚拟机可能会运行相同的程序,KSM 会将相同的内存页合并,避免重复占用内存空间。
相关配置选项:
CONFIG_KSM: 启用 KSM 功能。
查看是否启用了 KSM:
zcat /proc/config.gz | grep CONFIG_KSM
如果未启用,可以在编译时启用:
CONFIG_KSM=y
KSM 也可以在运行时动态启用和禁用:
echo 1 > /sys/kernel/mm/ksm/run
echo 0 > /sys/kernel/mm/ksm/run
(4) Zswap 和 Zram
Zswap 和 Zram 是两种内存压缩机制,可以减少内存的使用并提高内存性能,尤其是在低内存的情况下。它们通过将页面压缩后存储在内存中,减轻对交换空间的需求,进而提高系统响应速度。
- Zswap:压缩内存页,将交换的页面压缩后存放。
- Zram:将内存压缩并作为块设备使用,尤其用于交换空间。
相关配置选项:
CONFIG_ZSWAP: 启用 Zswap。CONFIG_ZRAM: 启用 Zram。
查看是否启用:
zcat /proc/config.gz | grep CONFIG_ZSWAP
zcat /proc/config.gz | grep CONFIG_ZRAM
启用配置时,确保 CONFIG_ZSWAP 和 CONFIG_ZRAM 都是 y 或 m(模块):
CONFIG_ZSWAP=y
CONFIG_ZRAM=y
(5) 内存区域管理
在 Linux 内核中,内存区域管理(如 NUMA 和 ZONE)可以帮助提升内存的访问效率,从而间接影响内存规整。在多处理器或 NUMA 系统上,内存的分配和管理是分区的,优化 NUMA 设置有助于提高系统性能。
相关配置:
CONFIG_NUMA: 启用 NUMA 支持。
2. 如何在运行时调整内存规整
除了内核配置外,系统管理员还可以在系统运行时调整内存规整的行为。
(1) 手动触发内存合并
你可以手动触发内存合并(compaction),通过以下命令:
echo 1 > /proc/sys/vm/compact_memory
这将触发内核进行内存合并操作,尝试整理碎片化的内存空间。
(2) 调整内存回收参数
内核有多个与内存回收和碎片整理相关的参数,可以通过 vm 相关设置进行调整:
- vm.compaction_proactor:控制内存合并的“工作方式”。
- vm.zone_reclaim_mode:调整区域回收模式,减少外部碎片。
查看当前设置:
sysctl vm.compaction_proactor
sysctl vm.zone_reclaim_mode
(3) 增加内存合并的优先级
Linux 还提供了调整内存合并的优先级,通过 sysctl 配置文件(如 /etc/sysctl.conf)来调整:
vm.compaction_proactor=1
然后通过以下命令使配置生效:
sysctl -p
3. 编译内核启用内存规整
如果你的系统内核没有启用上述功能,你可以重新编译内核来启用相关配置。在内核源码目录中执行以下命令:
- 运行
make menuconfig或make xconfig打开配置界面。 - 启用以下选项:
CONFIG_COMPACTIONCONFIG_HUGETLBFSCONFIG_TRANSPARENT_HUGEPAGECONFIG_KSMCONFIG_ZSWAPCONFIG_ZRAM
编译内核并安装:
make -j$(nproc)
make modules_install
make install
重启系统以使新的内核配置生效。
4. 直接内存规整
进程分配内存时发现内存不足从而启动直接回收内存操作,这种模式下分配和回收是同步的关系,也就是说分配内存的进程会因为等待内存回收而被阻塞。
内存规整的一个重要应用场景是分配大块连续物理内存,低水位情况下分配失败时唤醒kswapd内核线程,但依然无法分配出内存,因此调用__alloc_pages_direct_compact,其处理流程如下所示:
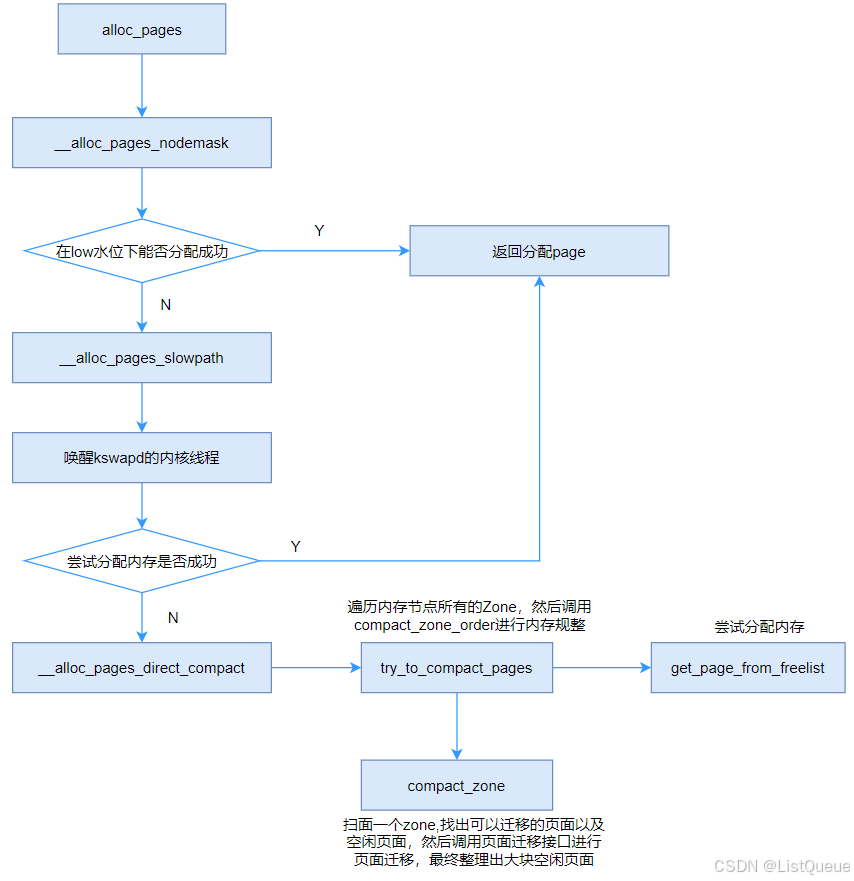
5. kcompactd内核线程
kcompactd是一个内核规整的后台进程,它跟memory compaction的区别在于:
- memory compaction的触发途径是内存分配进入direct_reclaim(暂不分析costly_order情况)后系统会根据内存剩余判断是否触发内存规整,或者用户手动触发;
- kcompactd在唤醒kswapd或者kswapd进入休眠时,主动触发内存规整。
kcompactd的触发路径如下:主要有如下两个途径:
- 唤醒kswapd之前触发规整,触发的条件是:本次分配不支持direct_reclaim,node内存节点是平衡的,并且kswapd失败的次数大于MAX_RECLAIM_RETRIES(默认16)。
- kswapd 即将进入睡眠时 。
kcompactd 触发路径概述
+-------------------+
| 内存不足或碎片严重 |
+-------------------+
|
+----------------+----------------+
| |
+---------------+ +----------------+
| 内存不足触发 | | 手动触发或高优先级 |
| 页分配失败 | | 内存合并请求 |
+---------------+ +----------------+
| |
+-------------------+ +----------------------+
| 触发合并进程 | | `kcompactd` 启动 |
| 调用 kcompactd | | 进行内存合并 |
+-------------------+ +----------------------+
|
+-------------------+
| 合并成功或失败 |
+-------------------+
|
+--------------+---------------+
| |
+----------------+ +-------------------+
| 合并成功 | | 合并失败 |
| 系统内存释放 | | 继续尝试或等待 |
+----------------+ +-------------------+
(1)内存不足触发 (kcompactd 调用条件)
kcompactd 的主要触发条件有两个:
-
内存不足:当系统内存紧张或页分配失败时,内核会检查是否需要进行内存合并。如果内存中碎片太多,无法满足大内存页的分配需求,系统会触发内存合并来释放更多的连续内存区域。这时会调用
kcompactd来进行内存合并。 -
手动触发或高优先级内存合并请求:在某些情况下,系统可能需要手动触发内存合并,或者当某些进程请求较大块的内存时,也可能会触发内存合并。
(2)kcompactd 启动和内存合并
一旦触发内存合并进程,kcompactd 会启动,并开始执行以下步骤:
- 检查内存页面的碎片情况:首先,
kcompactd会分析系统的内存碎片情况。 - 执行内存合并:如果内存合并有可能成功,
kcompactd会尽力将碎片化的内存页合并成较大的连续内存块,从而提高内存分配器的效率。 - 合并结果反馈:内存合并后,系统会根据合并的结果进行后续操作。如果合并成功,系统将能够分配更大的内存块;如果合并失败,系统可能会继续尝试,或者等待内存状态的变化。
(3)合并成功与失败
-
合并成功:如果
kcompactd成功地进行了内存合并,系统会获得更多的连续空闲内存,进而避免由于碎片化导致的内存分配失败。 -
合并失败:如果
kcompactd无法有效合并内存,系统将继续尝试,或者可以由其他内存管理机制(如压缩交换空间、交换区回收等)来应对内存压力。
四、使用局限
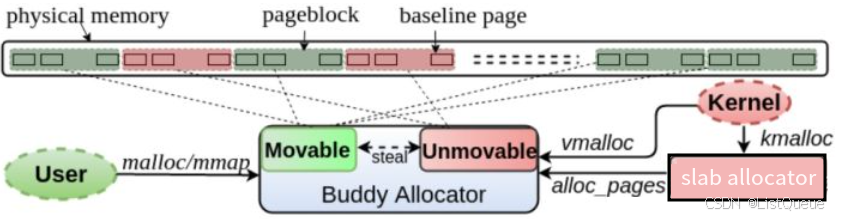
由于要保持虚拟地址不变,像kernel space中线性映射的这部分物理内存就不能被migrate,因为线性映射中虚拟地址和物理地址之间是固定的偏移,migration导致的物理地址更改势必也造成虚拟地址的变化。也就是说,并非所有的page都是“可移动”的,这也是为什么buddy系统中划分了"migrate type"。
五、优化方法
内核经过不断的优化,那为何Linux为何还有物理内存外碎片化呢?那是因为物理内存外碎片化虽然是可以不断优化的,但却无法得到根除。目前的内核,导致物理外碎片化还有以下两个主要原因:
- 不可移动页面污染了内存环境,导致页面规整失败;
- 随着系统不断申请和释放的页面,导致伙伴系统分配的物理内存页帧号越发随机,从而导致内存被隔断的概率越高,碎片化的程度越高。
针对以上两个原因,以下的优化措施可能达到一定的优化效果:
- 预留法
根据这种情况,可以通过预留的方式进行相应的优化。
- 预留一定的内存专门用于小块内存分配,经过这个优化措施后,可以有效降低小块内存分配的物理页帧号的随机性,从而降低小块内存污染内存环境的概率。
- 预留一定的内存专门用于大块内存分配,经过该优化措施后,预留的内存被小块内存污染的概率就会降低,可以提升预留内存分配大块内存的成功率。
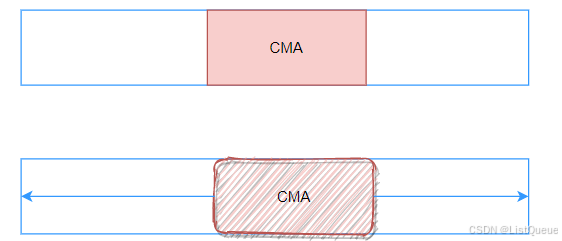
目前内核使用CMA和reserve memory的方法可以解决这个问题,CMA也会预留一块内存区域,但在DMA设备不使用这段内存的时候,它也可以被OS的其他模块所使用。而在DMA设备真正需要的时候,可以对其他模块使用的page frame做migration操作,以腾出CMA区域中的空间。

















 2392
2392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









