




Linux深入理解内存管理3(基于Linux6.6)---TLB
一、前情回顾
分页机制的硬件原理, 从虚拟内存地址到物理内存地址的转换, 通过页表来处理。 为了节约页表的内存存储空间, 我们会使用多级页表。 但是, 多级页表虽然节约了存储空间, 但是却存在问题:原本对于只需要进行一次地址转换, 只需要访问一次内存就能找到对应的物理页号了,算出物理地址现在我们需要多次访问内存, 才能找到对应的物理页号。
最终带来了时间上的开销, 变成了一个“以时间换空间” 的策略, 极大的限制了内存访问性
能问题。 所以为了解决这种问题导致处理器性能下降的问题, 计算机工程师们专门在 CPU
里放了一块缓存芯片, 这块缓存芯片称之为 TLB, 全称是地址变换高速缓冲。
(Translation-Lookaside Buffer)
1.1、分页机制
分页机制将虚拟地址空间划分为多个固定大小的“页”(Page),物理地址空间也划分为相同大小的“页框”(Page Frame)。在程序运行时,虚拟内存地址通过页表来转换为物理内存地址。具体流程如下:
-
虚拟地址拆分:虚拟地址通常被拆分为两部分:
- 页号(Page Number):用来标识虚拟地址空间中的页。
- 页内偏移(Offset):用来标识页内的具体位置。
-
页表:页表存储了虚拟页与物理页框之间的映射关系。每一条页表项包含了一个虚拟页号和对应的物理页框号。
-
地址转换过程:
- 查找页表:通过虚拟地址中的页号,访问页表来查找该虚拟页号对应的物理页框号。
- 计算物理地址:通过物理页框号与虚拟地址中的偏移量,计算出最终的物理地址。
1.2、多级页表
为了节约内存空间,尤其是在地址空间较大的系统中,采用了 多级页表(Multilevel Paging)。在传统的单级页表中,页表的大小与虚拟内存空间成正比。而在多级页表中,页表本身的大小得到压缩。
- 多级页表的工作原理:
- 将虚拟地址拆分为多个部分,通常包括多个“页表索引”和一个“页内偏移”。
- 使用多个页表来逐级转换虚拟地址。
- 第一级页表将虚拟页号映射到一个二级页表的位置。
- 第二级页表将虚拟页号映射到物理页框。
通过这种方式,只有在访问到某一级页表时,才会分配相应的内存空间,从而减少了内存的浪费。
-
举例:假设虚拟地址是 32 位,分为:
- 10 位用于第一级页表(可以指向 1024 个二级页表)。
- 10 位用于第二级页表(每个二级页表指向 1024 个物理页框)。
- 剩下的 12 位用于页内偏移。
这样,虚拟地址中的前 10 位去查找第一级页表,接着再用接下来的 10 位查找二级页表,最后得到物理页框号。最后通过物理页框号和页内偏移量就能计算出物理地址。
1.3、多级页表带来的问题
尽管多级页表节省了内存空间,但它也引入了性能上的问题:
-
多次内存访问:每次进行地址转换时,需要依次访问多个级别的页表。每一次访问都需要访问内存,特别是在多级页表较深时,内存访问次数会显著增加,从而带来较大的时间开销。
- 例如:如果有 3 级页表,每次转换地址都需要访问三次内存:一次访问第一级页表,第二次访问第二级页表,第三次访问物理内存。这样就增加了每次内存访问的延迟。
-
时间开销:随着页表级数的增加,内存访问的延迟也随之增加,导致系统的性能下降。
1.4、TLB(Translation Lookaside Buffer)
为了解决多级页表带来的性能问题,CPU 引入了 TLB(Translation Lookaside Buffer),即地址转换高速缓存。
1.TLB 的工作原理
TLB 是一个高速缓存,它存储了最近使用的虚拟地址到物理地址的转换结果。通过将常见的页表项存储在 TLB 中,可以大大减少访问页表的次数,从而提高地址转换的效率。
- 访问流程:
- 当 CPU 发起虚拟地址访问时,首先检查 TLB 是否存在该虚拟地址的映射。
- 如果 TLB 中存在对应的条目(称为TLB命中),则直接使用缓存中的物理地址进行访问,节省了多次访问内存的时间。
- 如果 TLB 中没有找到对应的条目(称为TLB未命中),则需要访问页表进行地址转换,转换结果会被缓存到 TLB 中,供后续访问使用。
2.TLB 的作用
- 减少内存访问次数:通过缓存地址转换结果,减少了访问多级页表的次数。
- 提高系统性能:尤其在具有高访问局部性(局部性原理)的程序中,TLB 能显著提高性能,因为很多内存访问都会访问相同或相邻的地址。
3.TLB 的组织
TLB 通常采用类似于页表的结构,存储虚拟页号与物理页框号之间的映射关系。为了提高查找速度,TLB 通常使用 全相联映射 或 部分相联映射,以便能够更快地查找到映射条目。
- TLB 命中率:TLB 的效果与命中率密切相关,命中率越高,性能提升越显著。
- TLB 替换策略:当 TLB 满时,需要根据一定的替换算法(如 FIFO、LRU 等)选择一个条目进行替换。
二、TLB 介绍
TLB 是 Translation Lookaside Buffer 的简称, 可翻译为“地址转换后援缓冲器”, 也可简称为
“快表”。 简单地说, TLB 就是页表的 Cache, 属于 MMU 的一部分, 其中存储了当前最可能
被访问到的页表项, 其内容是部分页表项的一个副本。 处理器在取指或者执行访问 memory
指令的时候都需要进行地址翻译, 即把虚拟地址翻译成物理地址。 而地址翻译是一个漫长的
过程, 需要遍历几个 level 的 Translation table, 从而产生严重的开销。 为了提高性能, 我们
会在 MMU 中增加一个 TLB 的单元, 把地址翻译关系保存在这个高速缓存中, 从而省略了对
内存中页表的访问。
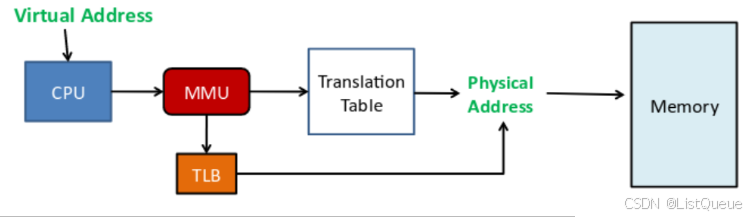
TLB 存放了之前已经进行过地址转换的查询结果。 这样, 当同样的虚拟地址需要进行地址转
换的时候, 可以直接在 TLB 里面查询结果, 而不需要多次访问内存来完成一次转换。
TLB 其实本质上也是一种 cache,既然是一种 cache,其目的就是为了提供更高的 performance。
而知道的指令 cache 和数据 cache 又又什么不同呢?
- 1.指令 cache: 解决 cpu 获取 main memory 中的指令数据的速度比较慢的问题而设立。
- 2.数据 cache: 解决 cpu 获取 main memory 中的数据的速度比较慢的问题而设立。
Cache 为了更快的访问 main memory 中的数据和指令, 而 TLB 是为了更快的进行地址翻译而
将部分的页表内容缓存到了 Translation lookasid buffer 中, 避免了从 main memory 访问页表
的过程。
三、TLB 的转换过程
TLB(地址转换旁路缓存)是 CPU 中的一种缓存,用于加速虚拟地址到物理地址的转换过程。它存储了最近访问的虚拟地址与物理地址的映射关系,从而避免每次访问内存时都去查询完整的页表,提高内存访问效率。下面是 TLB 转换过程的详细说明:
3.1、地址转换过程
当程序访问一个虚拟地址时,CPU 会进行虚拟地址到物理地址的转换,通常分为以下几个步骤:
-
拆分虚拟地址: 虚拟地址首先被拆分为两个部分:页号和页内偏移量(offset)。页号用于查找页表,偏移量指明了虚拟页内的具体位置。
假设我们有一个 32 位的虚拟地址,且页面大小为 4 KB(即 12 位偏移量),虚拟地址可能会被分成以下部分:
- 虚拟页号:高 20 位(用于索引页表)
- 页内偏移量:低 12 位(指定页面内的具体位置)
-
TLB 查询:
- 当 CPU 需要访问虚拟地址时,它首先会查询 TLB,看看该虚拟地址是否已经存在于 TLB 中。TLB 是一个小型的、非常快速的缓存,它存储了最近访问的虚拟地址到物理地址的映射。
- TLB 中存储的每一项条目包含:
- 虚拟页号
- 对应的物理页框号
- 可能还包括标志位(如有效位、权限位等)
-
TLB 命中:
- 命中(TLB Hit):如果虚拟地址的虚拟页号在 TLB 中存在,则表示该虚拟地址与物理地址的映射已缓存。
- CPU 直接从 TLB 中获得物理页框号,再结合虚拟地址中的页内偏移量(offset)计算出物理地址。
- 计算方式:物理地址 = 物理页框号 + 页内偏移量。
- TLB 命中意味着无需再访问页表,极大地加速了地址转换过程。
- 命中(TLB Hit):如果虚拟地址的虚拟页号在 TLB 中存在,则表示该虚拟地址与物理地址的映射已缓存。
-
TLB 未命中:
- 未命中(TLB Miss):如果虚拟地址的虚拟页号在 TLB 中找不到对应的物理页框号,则表示该映射不在缓存中。
- 在这种情况下,CPU 必须查阅 页表 来查找虚拟地址对应的物理页框号。
- 这个查找过程通常会经历多级页表(如果系统使用多级页表的话),直到找到物理页框号。
- 找到物理页框号后,CPU 会将映射关系(虚拟页号与物理页框号)缓存到 TLB 中,以便下次访问时能够直接命中。
-
更新 TLB:
- 替换策略:当 TLB 满时,需要根据某种替换策略(如最少使用算法 LRU、先进先出算法 FIFO 等)替换掉最旧或最不常用的条目。
- 替换后的条目会被更新为新的映射关系,这样可以保持 TLB 缓存的最新有效性。
3.2、具体流程
TLB 中的项由两部分组成:
- 标识区:存放的是虚地址的一部
- 数据区:存放物理页号、 存储保护信息以及其他一些辅助信息
对于数据区的辅助信息包括以下内容:
有效位(Valid): 对于操作系统, 所有的数据都不会加载进内存, 当数据不在内存的时候, 就
需要到硬盘查找并加载到内存。 当为 1 时, 表示在内存上, 为 0 时, 该页不在内存, 就需要
到硬盘查找。
引用位(reference):由于 TLB 中的项数是一定的, 所以当有新的 TLB 项需要进来但是又满了的
话, 如果根据 LRU 算法, 就将最近最少使用的项替换成新的项。 故需要引用位。 同时要注
意的是, 页表中也有引用位。
脏位(dirty):当内存上的某个块需要被新的块替换时, 它需要根据脏位判断这个块之前有没有
被修改过, 如果被修改过, 先把这个块更新到硬盘再替换, 否则就直接替换。
当存在 TLB 的访问流程:
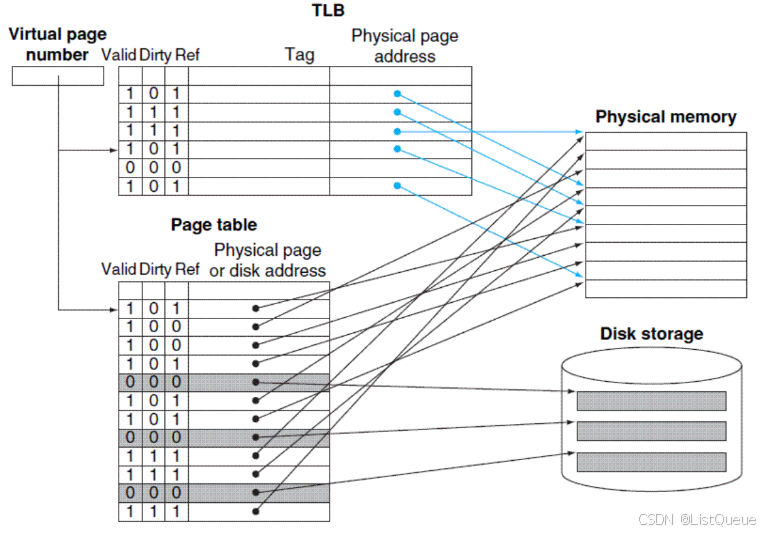
当 CPU 收到应用程序发来的虚拟地址后, 首先去 TLB 中根据标志 Tag 寻找页表数据, 假如
TLB 中正好存放所需的页表并且有效位是 1, 说明 TLB 命中了, 那么直接就可以从 TLB 中获
取该虚拟页号对应的物理页号。
假如有效位是 0, 说明该页不在内存中, 这时候就发生缺页异常, CPU 需要先去外存中将该
页调入内存并将页表和 TLB 更新
假如在 TLB 中没有找到, 就通过上一章节的方法, 通过分页机制来实现虚拟地址到物理地址
的查找。
如果 TLB 已经满了, 那么还要设计替换算法来决定让哪一个 TLB entry 失效, 从而加载新的
页表项。
3.3、引用位、 脏位何时更新?
1. 如果是 TLB 命中, 那么引用位就会被置 1, 当 TLB 或页表满时, 就会根据该引用位选择适
合的替换位置。
2. 如果 TLB 命中且这个访存操作是个写操作, 那么脏位就会被置 1, 表明该页被修改过, 当
该页要从内存中移除时会先执行将该页写会外存的操作, 保证数据被正确修改。
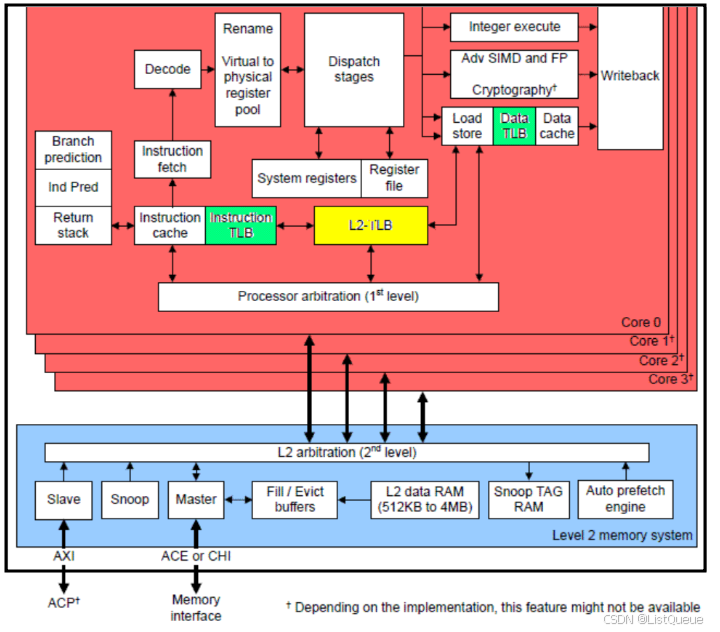
四、如何确定 TLB match
选择 Cortex-A72 processor 来描述 ARMv8 的 TLB 的组成结构以及维护 TLB 的指令
A72 实现了 2 个 level 的 TLB,绿色是 L1 TLB, 包括 L1 instruction TLB(48-entry fully-associative) 和 L1 data TLB(32-entryfully-associative)。
黄色 block 是 L2 unified TLB, 它要大一些, 可以容纳 1024 个 entry, 是 4-way set-associative
的。 当 L1 TLB 发生 TLB miss 的时候, L2 TLB 是它们坚强的后盾
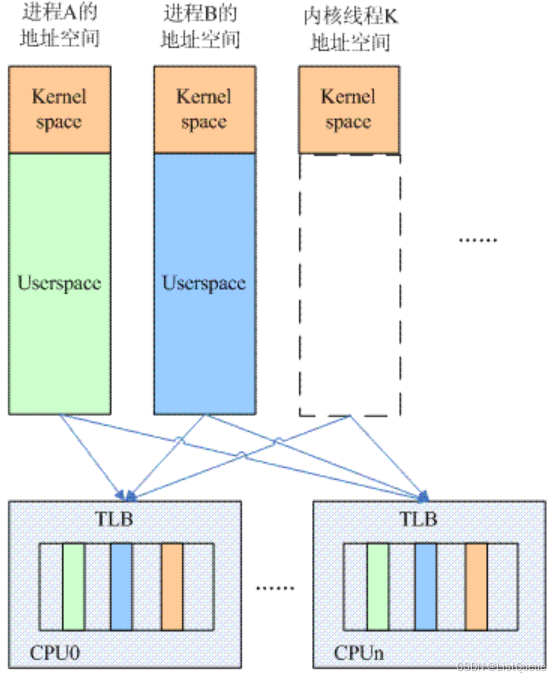
通过上图, 还可以看出: 对于多核 CPU, 每个 processor core 都有自己的 TLB。
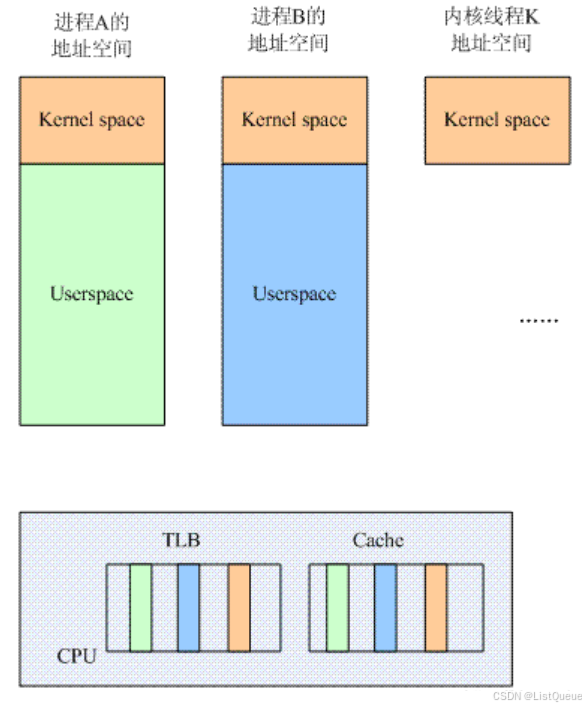
假如不做任何的处理, 那么在进程 A 切换到进程 B 的时候, TLB 和 Cache 中同时存在了 A 和
B 进程的数据。
对于 kernel space 其实无所谓, 因为所有的进程都是共享的。
对于 A 和 B 进程, 它们各种有自己的独立的用户地址空间, 也就是说, 同样的一个虚拟地
址 X, 在 A 的地址空间中可以被翻译成 Pa, 而在 B 地址空间中会被翻译成 Pb, 如果在地址
翻译过程中, TLB 中同时存在 A 和 B 进程的数据, 那么旧的 A 地址空间的缓存项会影响 B 进
程地址空间的翻译,因此, 在进程切换的时候, 需要有 tlb 的操作, 以便清除旧进程的影响, 具体怎样做呢?
当系统发生进程切换, 从进程 A 切换到进程 B, 从而导致地址空间也从 A 切换到 B, 这时候,
我们可以认为在 A 进程执行过程中, 所有 TLB 和 Cache 的数据都是 for A 进程的, 一旦切换
到 B, 整个地址空间都不一样了, 因此需要全部 flush 掉。
这种方案当然没有问题, 当进程 B 被切入执行的时候, 其面对的 CPU 是一个干干净净, 从
头开始的硬件环境, TLB 和 Cache 中不会有任何的残留的 A 进程的数据来影响当前 B 进程的
执行。 当然, 稍微有一点遗憾的就是在 B 进程开始执行的时候, TLB 和 Cache 都是冰冷的(空
空如也), 因此, B 进程刚开始执行的时候, TLB miss 和 Cache miss 都非常严重, 从而导致了性能的下降。 我们管这种空 TLB 叫做 cold TLB, 它需要随着进程的运行 warm up 起来才能慢慢发挥起来效果, 而在这个时候有可能又会有新的进程被调度了, 而造成 TLB 的颠簸效应。
采用进程地址空间这样的术语,其实它可以被进一步细分为内核地址空间和用户地址空间。 对于所有的进程(包括内核线程), 内核地址空间是一样的, 因此对于这部分地址翻译,无论进程如何切换, 内核地址空间转换到物理地址的关系是永远不变的, 其实在进程 A 切换到 B 的时候, 不需要 flush 掉, 因为 B 进程也可以继续使用这部分的 TLB 内容(上图中,橘色的 block)。 对于用户地址空间, 各个进程都有自己独立的地址空间, 在进程 A 切换到 B的时候, TLB 中的和 A 进程相关的 entry(上图中, 青色的 block) 对于 B 是完全没有任何意义的, 需要 flush 掉。
在这样的思路指导下,其实需要区分 global 和 local(其实就是 process-specific 的意思)这两种类型的地址翻译,因此,在页表描述符中往往有一个 bit 来标识该地址翻译是 global还是 local 的, 同样的, 在 TLB 中, 这个标识 global 还是 local 的 flag 也会被缓存起来。 有了这样的设计之后,可以根据不同的场景而 flush all 或者只是 flush local tlb entry。
TLB 匹配的详细过程:
1. 虚拟地址拆分
虚拟地址通常会被拆分成两个部分:虚拟页号和页内偏移量。假设使用的是一个常见的 32 位虚拟地址空间,且页面大小为 4KB(即 2^12 字节),虚拟地址可以被拆分为:
- 虚拟页号(Virtual Page Number, VPN):通常是虚拟地址的高位部分,用来标识虚拟地址对应的页。
- 页内偏移量(Page Offset):通常是虚拟地址的低位部分,指示该地址在页内的具体位置。
2. TLB 条目结构
每个 TLB 条目通常存储以下信息:
- 虚拟页号:用于标识该条目所对应的虚拟地址的虚拟页。
- 物理页框号(Physical Page Frame Number, PFN):对应虚拟页号的物理页框号,即虚拟地址映射到的物理地址。
- 有效位(Valid Bit):指示该条目是否有效,如果为 0,表示该条目无效,不应被使用。
- 其他控制位:包括权限位(如只读、只写)、修改位等,可能会影响地址转换的合法性。
3. TLB 匹配过程
当 CPU 访问一个虚拟地址时,TLB 会检查是否存在该虚拟地址的映射。具体的匹配过程如下:
步骤 1: 提取虚拟页号
- 从虚拟地址中提取虚拟页号(VPN),通常是虚拟地址的高位部分。具体位数取决于虚拟地址的长度和页面大小。
- 例如,如果虚拟地址是 32 位,页面大小为 4KB(12 位偏移量),则虚拟页号占 20 位。
步骤 2: TLB 查询
- CPU 会将提取出的虚拟页号与 TLB 中的所有条目进行比较,查找是否有条目存储了相同的虚拟页号。
- 匹配条件:
- 如果 TLB 中的某一条目包含与访问的虚拟页号相同的虚拟页号,且该条目的有效位(valid bit)为 1,则发生 TLB 命中(TLB hit),表明该虚拟页号有对应的物理页框号。
- 如果没有找到匹配的虚拟页号,或者有效位为 0,则发生 TLB 未命中(TLB miss)。
步骤 3: TLB 命中后的处理
- 命中:如果 TLB 匹配成功(即虚拟页号与 TLB 条目中的虚拟页号相同),则从该 TLB 条目中提取物理页框号(PFN)。
- 计算物理地址时,将该物理页框号与虚拟地址中的页内偏移量结合,得到物理地址。物理地址 = 物理页框号 + 页内偏移量。
- 未命中:如果没有找到匹配的条目,则需要通过查阅页表来完成虚拟地址到物理地址的转换。之后,将该新的映射关系加载到 TLB 中以便将来使用。
4. TLB 更新与替换
如果发生 TLB 未命中,并且页表查询得到的映射关系被加载到 TLB 中,CPU 会根据 TLB 的替换策略(如 LRU、FIFO 等)更新缓存。这时,新的虚拟页号和物理页框号会被写入到 TLB 条目中。
五、多核的 TLB 操作
完成单核场景下的分析之后, 我们一起来看看多核的情况。 进程切换相关的 TLB 逻辑 block
示意图如下:
在多核系统中, 进程切换的时候, TLB 的操作要复杂一些, 主要原因有两点: 其一是各个 cpu
core 有各自的 TLB, 因此 TLB 的操作可以分成两类, 一类是 flush all, 即将所有 cpu core 上的
tlb flush 掉, 还有一类操作是 flush local tlb, 即仅仅 flush 本 cpu core 的 tlb。 另外一个原因是
进程可以调度到任何一个 cpu core 上执行(当然具体和 cpu affinity 的设定相关), 从而导致
task 处处留情(在各个 cpu 上留有残余的 tlb entry)。
多核环境中的 TLB 操作涉及多个核心的 TLB 缓存与共享内存之间的交互,主要面临以下挑战:
- TLB 一致性(TLB Coherence)
- TLB 协同操作
- TLB 缓存失效的处理(TLB Invalidations)
- TLB 替换策略
1. 每个核心的独立 TLB
在多核系统中,通常每个核心都拥有自己的本地 TLB(有时称为 L1 TLB),用于存储该核心最近访问过的虚拟页到物理页的映射。因为 TLB 的作用是加速虚拟地址到物理地址的转换,所以每个核心在执行自己的程序时,会使用自己的 TLB 来减少对共享内存的访问延迟。
2. TLB 一致性问题
多核系统中的一个关键问题是 TLB 一致性,特别是在某个核心修改了某个虚拟页到物理页的映射后,其他核心需要知道这个变化,以确保一致性。
示例:TLB 一致性
- 如果核心 0 更新了一个虚拟页的映射,而核心 1 仍然保留旧的映射,则核心 1 可能会在访问该虚拟页时发生 TLB 命中,但由于映射已经发生变化,核心 1 将获得错误的物理地址。
为了保证各核心 TLB 中存储的虚拟页映射保持一致,多核系统需要采取一定的同步机制。常见的解决办法包括:
-
TLB 无效化(TLB Invalidations):当一个核心更新了某个虚拟页的映射(比如通过页表修改),它需要通知其他核心使它们的 TLB 条目失效。这通常是通过硬件支持的广播机制来实现的。
- 例如,某些架构支持 TLB shootdown(TLB 打击)机制,即当页表发生改变时,操作系统可以通过一个广播机制使所有其他核心的 TLB 中关于该虚拟页的条目失效。
-
TLB 更新协议:有些处理器架构(如 ARM 和 x86)支持 TLB 更新协议,即当一个核心对某个虚拟页的映射进行更新时,它会发送一条信息到其他核心,通知它们更新或清空对应的 TLB 条目。
3. TLB 协同操作
由于每个核心的 TLB 是本地的,TLB 协同操作在多核处理器中尤为重要。例如,在 SMP(对称多处理)系统中,如果某个核心需要访问另一个核心所修改的数据,可能会遇到 TLB 不一致的问题。因此,处理器必须支持以下协同操作:
-
TLB shootdown(失效)机制:当页表发生更改时,操作系统会协调核心之间的 TLB 更新。在这个过程中,涉及到对所有相关核心的 TLB 进行失效操作,确保它们不会使用过时的页表信息。
-
TLB 刷新:为了避免 TLB 中的映射与内存中的页表不一致,操作系统或硬件会在某些操作后触发 TLB 刷新,强制所有核心重新加载页表信息。尤其是当内核空间的页表发生变化时,操作系统会执行 TLB 刷新,以确保每个核心使用最新的映射。
4. TLB 缓存失效的处理
TLB 缓存失效通常发生在以下情况:
- 页表修改:如果操作系统修改了页表(比如通过页面置换、内存映射等操作),核心必须失效其本地 TLB 中相关的条目。
- 上下文切换:当一个核心发生上下文切换,操作系统可能会修改当前进程的页表。因此,操作系统需要清除 TLB 中与当前进程不相关的条目。
- 硬件支持的 TLB 无效化:一些处理器提供了硬件支持的 TLB 无效化指令,当进程或线程切换时,可以通过这些指令清除或更新 TLB 中的条目。
5. TLB 替换策略与多核
在多核系统中,每个核心的 TLB 通常会有自己的替换策略。常见的替换策略有:
- LRU(Least Recently Used):使用最少的虚拟页条目会被最先替换。
- FIFO(First In First Out):最早进入 TLB 的条目会被替换。
- 随机替换:随机选择一个条目进行替换。
尽管各个核心的 TLB 有独立的替换策略,但为了减少在多核系统中可能出现的缓存失效,操作系统和硬件需要优化 TLB 使用,尽量减少跨核心的数据访问延迟。
6. TLB 共享(跨核心共享 TLB)
一些高性能的处理器架构还支持共享 TLB,即多个核心可以共享某些 TLB 条目。这种情况下,TLB 一致性和缓存同步变得更加复杂,因为更新的虚拟页映射可能会影响到多个核心的 TLB。为了保证一致性,通常需要硬件支持高效的同步机制。
7. 多核系统中的 TLB 持久性与优化
为了进一步优化性能,某些多核系统还使用了多级 TLB(如 L1 和 L2 TLB),L1 TLB 是每个核心独有的,而 L2 TLB 可能是共享的。当一个核心未能在 L1 TLB 中找到映射时,它会查询 L2 TLB。
这种多级缓存设计能够减少跨核心访问的冲突,并减少不同核心之间的 TLB 失效带来的开销。
六、PCID
按照这种思路走下去, 那就要思考, 有没有别的办法能够不刷新 TLB 呢? 有办法的, 那就是
PCID。
1. PCID(Process Context Identifier)的概念
PCID 是一种由硬件支持的机制,用来区分不同进程或上下文的 TLB 条目。通过使用 PCID,可以让 TLB 条目在不同的进程或上下文之间进行区分,这样就可以避免因为进程切换或上下文切换而清空 TLB 中所有条目。
在没有 PCID 的情况下,当一个操作系统进行进程切换时,通常需要清空 TLB 中所有条目,因为不同进程的虚拟地址空间是完全独立的,旧进程的虚拟地址映射可能会影响到新进程的地址映射。因此,每次上下文切换时都需要执行 TLB 刷新(TLB flush)。
然而,使用 PCID 后,不同进程的 TLB 条目可以同时存在,而不发生冲突。具体来说,PCID 为每个进程分配一个唯一的标识符,并将该标识符与进程相关的 TLB 条目进行关联。这样,在上下文切换时,处理器不需要刷新整个 TLB,而只需要更新当前正在运行的进程的 PCID。
2. PCID 如何避免 TLB 刷新?
-
分配唯一的 PCID:当一个进程开始执行时,操作系统为该进程分配一个唯一的 PCID。每当该进程进行内存访问时,处理器会根据该进程的 PCID 来区分 TLB 中存储的虚拟地址映射。
-
进程切换时更新 PCID:当操作系统发生进程切换时,它不会清空 TLB,而是通过修改硬件的 PCID 寄存器来使得当前 TLB 中的条目与新的进程对应的映射匹配。
-
共享 TLB 条目:由于不同的 PCID 允许 TLB 存储多个进程的映射,它们之间不会相互干扰。因此,进程切换时不需要清空 TLB 或执行 TLB 刷新,极大地提高了效率。
-
提高上下文切换性能:没有 PCID 的情况下,上下文切换通常需要清空并重填 TLB,这会导致显著的性能开销。而有了 PCID,进程切换可以通过简单地更新 PCID 寄存器来避免这种开销,从而显著提高了多核系统中的上下文切换效率。
3. 实现原理
在硬件实现层面,PCID 依赖于处理器的虚拟地址到物理地址映射机制。具体来说,x86 架构中的 CR3 寄存器 存储了当前页表的物理地址,而 PCID 则为每个进程分配一个附加的标识符。每当发生地址转换时,PCID 会附加到虚拟地址的转换过程中,这样处理器能够在不同的进程之间区分 TLB 中的条目。
-
在 x86-64 架构中,支持 PCID 的指令包括
INVPCID,它允许操作系统选择性地无效化某些进程的 TLB 条目,而无需全局刷新所有条目。 -
ARMv8 架构也支持类似的机制,使用 ASID(Address Space Identifier)来实现多上下文的 TLB 管理。
4. PCID 的优势
- 减少 TLB 刷新开销:通过避免每次上下文切换时清空整个 TLB,PCID 可以显著减少 TLB 刷新带来的性能损失。
- 提高多核系统的效率:在多核系统中,多个核心通常需要访问共享的内存和缓存,而 PCID 可以使得各核心在切换进程时不必执行全局的 TLB 刷新,从而提高并行处理的效率。
- 提高虚拟化性能:在虚拟化环境中,虚拟机的切换通常会涉及频繁的 TLB 刷新。PCID 使得虚拟机的上下文切换更加高效,从而提升虚拟化性能。
- 降低操作系统负担:操作系统不再需要频繁地管理 TLB 刷新,从而减轻了操作系统的工作负担,减少了调度和切换的延迟。
5. PCID 的限制和挑战
尽管 PCID 提供了许多性能优势,但它的使用也有一些局限性和挑战:
-
硬件支持:并不是所有处理器都支持 PCID。早期的处理器可能不具备这一特性,或者只在高端处理器中提供对 PCID 的支持。随着硬件技术的进步,越来越多的现代处理器开始支持 PCID。
-
内存管理复杂性:虽然 PCID 可以避免频繁刷新 TLB,但操作系统仍需要小心管理不同 PCID 之间的映射关系。特别是在多核系统中,操作系统需要确保不同核心之间的上下文切换和映射的正确性。
-
兼容性问题:在一些老旧硬件或虚拟化环境中,可能需要专门的支持来启用或优化 PCID。在这种情况下,操作系统和硬件的兼容性可能成为一个挑战。
七、TLB shootdown
一切看起来很美好, PCID 这个在多年前就有了的技术, 现在已经在每个 Intel CPU 中生根了,
那么是不是已经被广泛使用了呢? 而实际的情况是 Linux 在 2017 年底才在 4.15 版中真正全
面使用了 PCID, 这是为什么呢?
PCID 这么好的技术也有副作用。 在它之前的日子里, Linux 在多核 CPU 上调度进程时候, 因
为每次进程调度都会刷掉进程用户空间的 TLB, 并没有什么问题。 如果支持 PCID 的话, TLB
操作变得很简单, 或者说我们没有必要去执行 TLB 的操作, 因为在 TLB 的搜索的时候已经区
分各个进程, 这样 TLB 不会影响其他任务的执行。
在单核系统中, 这样的操作确实能够获得很好的性能, 例如场景为 A—>B—>A, 如果 TLB 足
够大, TLB 再两个进程中反复切换, 极大的提升了性能。
但是在多核系统重, 如果 CPU 支持 PCID, 并且在进程切换的时候不 flush tlb, 那么系统中各
个 CPU 中的 TLB entry 则保留各个进程的 TLB entry, 当在某个 CPU 上, 一个进程被销毁了,
或者该进程修改了自己的页表的时候, 就必须将该进程的 TLB 从系统中请出去。 这时候, 不
仅仅需要 flush 本 CPU 上对应的 TLB entry, 还需要 flush 其他 CPU 上和该进程相关的残余。
而这个动作就需要通过 IPI 实现, 从而引起了系统开销, 此外 PCID 的分配和管理也会带来额
外的开销。 再加上 PCID 里面的上下文 ID 长度有限, 只能够放得下 4096 个进程 ID, 这就需
要一定的管理以便申请和放弃。 如此种种, 导致 Linux 系统在应用 PCID 上并不积极, 直到不
得不这样做。
1. TLB Shootdown 简介
TLB shootdown 是操作系统中与 Translation Lookaside Buffer (TLB) 相关的一种机制,通常发生在多处理器(多核)系统中。它的目的是确保所有处理器核(CPU cores)在进行虚拟地址到物理地址转换时使用一致的地址映射。当地址映射发生变化(如页面映射被修改或撤销)时,必须确保各处理器的 TLB 中的旧条目被更新或失效,以避免地址映射不一致的问题。
2. TLB 和 TLB Shootdown 的背景
TLB (Translation Lookaside Buffer) 是一种硬件缓存,用来存储虚拟地址到物理地址的映射。它是为了提高虚拟内存访问的效率而设计的,因为每次访问内存时,CPU 需要通过页表进行虚拟地址到物理地址的转换。如果每次都去查找页表,会显著影响性能。因此,TLB 提供了高速缓存的机制,将最近使用的地址映射存储起来,避免每次都进行完整的页表查找。
然而,TLB 是局部的(每个 CPU 核心有独立的 TLB),这意味着不同的 CPU 核心可能会保存不同的虚拟地址映射副本。如果某个进程或内核修改了某个虚拟地址的映射,而其他核心的 TLB 仍然保留了旧的映射,就会导致访问到错误的物理内存,产生不一致性。
为了解决这个问题,操作系统会执行 TLB shootdown 操作,来确保所有 CPU 核心的 TLB 都能及时更新或失效,以维持一致性。
3. TLB Shootdown 的工作原理
-
TLB 失效操作:
- 当某个 CPU 核心修改了页表或某个虚拟地址的映射(如释放了某个内存页),它会通知其他所有核心,要求它们清除自己 TLB 中的相关条目。
- TLB shootdown 的基本目的是让其他核心失效(flush)自己缓存的过时的地址映射条目,以避免访问过时的数据。
-
同步机制:
- 在多核系统中,执行 TLB shootdown 通常涉及到同步操作,以确保所有 CPU 核心都能正确地失效并更新自己的 TLB。这通常通过中断、信号量、或其他同步机制来实现。
- 操作系统可能需要使用锁来协调 TLB shootdown 操作,防止多个 CPU 核心同时尝试更新 TLB,导致数据竞争。
-
TLB Shootdown 过程:
- 发送通知:当一个核心修改了页表,操作系统会通过中断、写入某个共享数据结构,或直接向其他 CPU 核心发送指令,通知它们清除自己 TLB 中的相关条目。
- 等待所有核心完成:发送通知后,操作系统需要等待其他核心完成 TLB 失效操作。一些实现会在每个核心上执行一次 TLB 刷新指令,以保证所有 TLB 条目被清除。
- 继续执行:一旦 TLB shootdown 完成,操作系统才允许其他操作继续执行。
4. 为什么 TLB Shootdown 是必要的?
TLB shootdown 是为了保证系统的 虚拟地址一致性。在多核系统中,每个处理器核心可能会独立地使用自己的 TLB 缓存虚拟地址到物理地址的映射。如果某个核心的映射发生变化(例如,释放了内存页),而其他核心的 TLB 仍然保存了过时的映射,那么其他核心在访问这些地址时将会读取错误的物理内存,导致数据不一致,甚至崩溃。
因此,TLB shootdown 机制通过强制所有核心同步 TLB 中的映射,确保地址转换的一致性,从而避免了可能出现的内存访问错误。
5. TLB Shootdown 的性能影响
虽然 TLB shootdown 是确保多核系统一致性的重要机制,但它也会带来一定的性能开销。主要的性能影响体现在以下几个方面:
-
延迟增加:
- TLB shootdown 会导致操作系统的上下文切换和同步延迟。当一个核心修改了页表后,它需要等待其他所有核心完成 TLB 刷新操作。这可能导致较长的同步延迟,尤其是在多核心系统中,等待的时间会随着核心数的增加而增加。
-
缓存一致性开销:
- TLB shootdown 会导致多个核心之间的缓存失效,需要额外的通信和同步成本。特别是在大规模的多核处理器中,TLB 刷新的频率和成本可能显著增加。
-
系统吞吐量下降:
- 由于 TLB shootdown 需要同步多个核心并确保一致性,可能会导致系统整体吞吐量下降,尤其是在大量上下文切换和频繁访问内存的高负载情况下。
6. TLB Shootdown 的优化方法
-
减少 TLB Shootdown 的频率:
- 操作系统可以通过优化内存管理策略来减少 TLB shootdown 的发生。例如,可以使用更细粒度的页面映射和虚拟内存技术,避免频繁的页面映射更改。
-
使用更高效的同步机制:
- 操作系统可以采用更高效的同步原语,减少 TLB shootdown 操作的延迟。例如,可以通过优化锁机制或使用更轻量级的中断和通知机制来加速 TLB 刷新过程。
-
硬件支持:
- 现代处理器(如 x86 架构中的 PCID)支持更细粒度的 TLB 管理,通过区分不同的进程上下文或核心来减少全局的 TLB 刷新需求。这种机制可以显著减少 TLB shootdown 操作的开销。
-
批量失效:
- 有些系统允许在一次 TLB shootdown 操作中批量处理多个核心的 TLB 刷新请求,而不是一个核心一个核心地处理,减少同步开销。

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









