




Linux 驱动开发之网络设备分析2(基于Linux6.6)---网络栈介绍
一、协议简介
虽然对于网络的正式介绍一般都参考了 OSI(Open Systems Interconnection)模型,但是本文对 Linux 中基本网络栈的介绍分为四层的 Internet 模型。
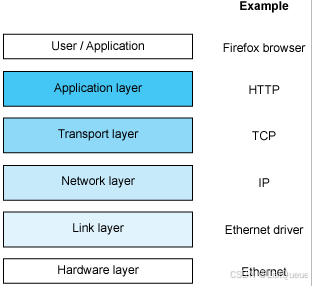
1.1、Internet 模型图(四层模型)
+-------------------------+
| 应用层 (Application Layer) | -- 用户与应用程序之间的交互
+-------------------------+
| 传输层 (Transport Layer) | -- 提供端到端通信 (如 TCP, UDP)
+-------------------------+
| 网络层 (Internet Layer) | -- 路由和IP寻址 (如 IP协议)
+-------------------------+
| 链路层 (Link Layer) | -- 物理网络传输和访问介质 (如 Ethernet, Wi-Fi)
+-------------------------+
1.2、各层的功能和协议
1. 应用层(Application Layer)
- 功能:为用户提供具体的网络服务,负责数据的输入输出,处理具体的应用协议。
- 协议:HTTP、FTP、DNS、SMTP、POP3、IMAP、Telnet等。
- 描述:应用层包括了最接近用户的协议和服务,它们通过底层的传输和网络层来实现数据的交换。比如,Web浏览器通过 HTTP 协议向服务器发送请求,或电子邮件客户端通过 SMTP 协议发送邮件。
2. 传输层(Transport Layer)
- 功能:为应用层提供端到端的通信服务,确保数据完整性、可靠性和流量控制。
- 协议:TCP、UDP。
- 描述:传输层负责在发送方和接收方之间提供可靠的或不可靠的通信。它通过使用不同的协议(如 TCP 和 UDP)来确保数据的可靠传输。TCP 提供面向连接的可靠传输,而 UDP 提供无连接的快速传输。
3. 网络层(Internet Layer)
- 功能:负责将数据从源设备传输到目标设备,主要通过路由选择和IP寻址实现数据转发。
- 协议:IP(IPv4、IPv6)、ICMP、ARP。
- 描述:网络层的主要任务是通过不同的网络传输数据包,确定从源主机到目标主机的路径,并通过 IP 地址进行标识和定位。它还包括了 ICMP 协议(如 Ping)来处理错误报告和诊断。
4. 链路层(Link Layer)
- 功能:定义了网络设备如何在物理网络上发送和接收数据帧。它负责物理传输介质和数据链路的管理。
- 协议:Ethernet、Wi-Fi、PPP、ARP等。
- 描述:链路层主要涉及数据帧的封装和解封装,确保数据在局部网络内的传输。它处理硬件地址(如 MAC 地址)和物理网络的访问控制(如通过 Ethernet 和 Wi-Fi 进行通信)。
1.3、各层之间的交互
- 应用层:应用层协议通过传输层协议(如 TCP 或 UDP)来进行数据传输。
- 传输层:传输层为应用提供端到端通信服务。在发送数据时,它会将数据传输给网络层处理,而接收方传输层会将数据交给应用层。
- 网络层:网络层通过路由协议和IP协议来决定数据包的转发路径。它负责确保数据包能够从源设备发送到目标设备。
- 链路层:链路层负责物理媒介的数据传输,主要作用是确保数据能够在物理网络设备之间可靠地传递。
1.4、示例:从浏览器请求网页的过程
- 应用层:用户在浏览器中输入网址(例如
http://www.example.com)。浏览器使用 HTTP 协议发起请求。 - 传输层:HTTP 请求通过 TCP 协议被封装在一个 TCP 段中,传输层确保数据传输的可靠性。
- 网络层:IP 地址通过 IP 协议封装,网络层负责路由选择,将数据包发送到目标服务器。
- 链路层:链路层负责将数据包封装成数据帧并通过物理介质(如以太网、Wi-Fi)发送到目标设备。
二、核心网络架构
现在继续了解 Linux 网络栈的架构以及如何实现这种 Internet 模型。下图提供了 Linux 网络栈的高级视图。最上面是用户空间层,或称为应用层,其中定义了网络栈的用户。底部是物理设备,提供了对网络的连接能力(串口或诸如以太网之类的高速网络)。中间是内核空间,即网络子系统,也是本文介绍的重点。流经网络栈内部的是 socket 缓冲区(sk_buffs),它负责在源和汇点之间传递报文数据。您很快就将看到sk_buff 的结构。
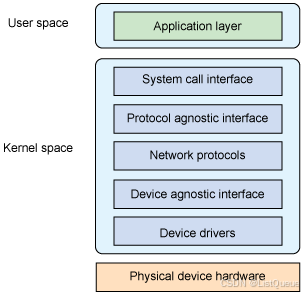
它简单地为用户空间的应用程序提供了一种访问内核网络子系统的方法。位于其下面的是一个协议无关层,它提供了一种通用方法来使用底层传输层协议。然后是实际协议,在 Linux 中包括内嵌的协议 TCP、UDP,当然还有 IP。然后是另外一个协议无关层,提供了与各个设备驱动程序通信的通用接口,最下面是设备驱动程序本身。
三、系统调用接口
系统调用接口可以从两个角度进行描述。用户发起网络调用时,通过系统调用接口进入内核的过程应该是多路的。最后调用 net/socket.c 中的sys_socketcall 结束该过程,然后进一步将调用分路发送到指定目标。系统调用接口的另一种描述是使用普通文件操作作为网络 I/O。例如,典型的读写操作可以在网络 socket 上执行(socket 使用一个文件描述符表示,与一个普通文件一样)。因此,尽管有很多操作是网络专用的(使用 socket 调用创建一个 socket,使用 connect 调用连接一个收信方,等等),但是也有一些标准的文件操作可以应用于网络对象,就像操作普通文件一样。最后,系统调用接口提供了在用户空间应用程序和内核之间转移控制的方法。
四、协议无关接口
socket 层是一个协议无关接口,它提供了一组通用函数来支持各种不同协议。socket 层不但可以支持典型的 TCP 和 UDP 协议,而且还可以支持 IP、裸以太网和其他传输协议,例如 SCTP(Stream Control Transmission Protocol)。
通过网络栈进行的通信都需要对 socket 进行操作。Linux 中的 socket 结构是 struct sock,这个结构是在 linux/include/net/sock.h 中定义的。这个巨大的结构中包含了特定 socket 所需要的所有状态信息,其中包括 socket 所使用的特定协议和在 socket 上可以执行的一些操作。
网络子系统可以通过一个定义了自己功能的特殊结构来了解可用协议。每个协议都维护了一个名为 proto 的结构(可以在 linux/include/net/sock.h 中找到)。这个结构定义了可以在从 socket 层到传输层中执行特定的 socket 操作(例如,如何创建一个 socket,如何使用 socket 建立一个连接,如何关闭一个 socket 等等)。
五、网络协议
网络协议这一节对一些可用的特定网络协议作出了定义(例如 TCP、UDP 等)。它们都是在 linux/net/ipv4/af_inet.c 文件中一个名为inet_init 的函数中进行初始化的(因为 TCP 和 UDP 都是 inet 簇协议的一部分)。 inet_init 函数使用 proto_register 函数来注册每个内嵌协议。这个函数是在 linux/net/core/sock.c 中定义的,除了可以将这个协议添加到活动协议列表中之外,如果需要,该函数还可以选择分配一到多个 slab 缓存。
通过 linux/net/ipv4/ 目录中 udp.c 和 raw.c 文件中的 proto 接口,您可以了解各个协议是如何标识自己的。这些协议接口每个都按照类型和协议映射到 inetsw_array,该数组将内嵌协议与操作映射到一起。inetsw_array 结构及其关系如图 3 所示。最初,会调用 inet_init 中的inet_register_protosw 将这个数组中的每个协议都初始化为 inetsw。函数 inet_init 也会对各个 inet 模块进行初始化,例如 ARP、ICMP 和 IP 模块,以及 TCP 和 UDP 模块。
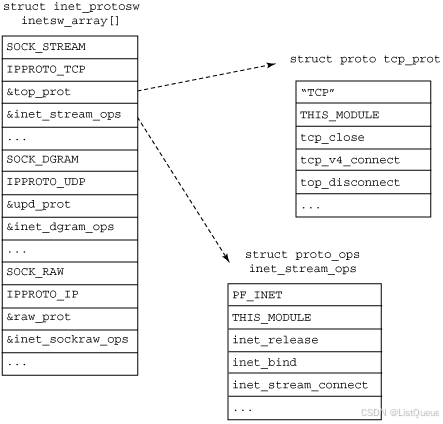
5.1、Socket 协议的相互关系
回想以下在创建 socket 时,需要指定类型和协议,例如my_sock = socket( AF_INET, SOCK_STREAM, 0 )。AF_INET 表示一个 Internet 地址簇,它使用的是一个流 socket,定义为 SOCK_STREAM(如此处的inetsw_array 所示)。
上图proto 结构定义了传输特有的方法,而 proto_ops 结构则定义了通用的 socket 方法。可以通过调用inet_register_protosw 将其他协议加入到 inetsw 协议中。例如,SCTP 就是通过调用 linux/net/sctp/protocol.c 中的 sctp_init 加入其中的。
socket 中的数据移动是使用一个所谓的 socket 缓冲区(sk_buff)的核心结构实现的。sk_buff 中包含了报文数据,以及涉及协议栈中多个层次的状态数据。所发送或接收的每个报文都是使用一个 sk_buff 表示的。sk_buff 结构是在 linux/include/linux/skbuff.h 中定义的,如下图:
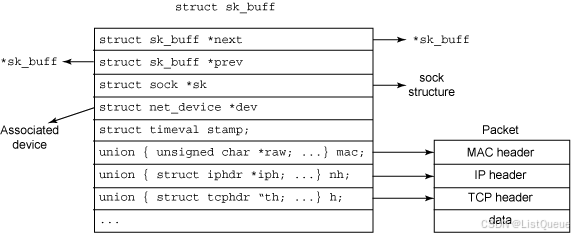
如图所示,多个 sk_buff 可以针对某个给定连接链接在一起。每个 sk_buff 都在设备结构(net_device)中标识报文发送的目的地,或者接收报文的来源地。由于每个报文都是使用一个 sk_buff 表示的,因此报文头都可以通过一组指针(th、iph 和 mac[用于 Media Access Control 或者 MAC 头])方便地进行定位。由于 sk_buff 是 socket 数据管理的中心,因此创建了很多支持函数来对它们进行管理。其中有些函数用于创建和销毁 sk_buff 结构,或对它进行克隆或排队管理。
针对给定的 socket,Socket 缓冲区可以链接在一起,这样可以包含众多信息,包括到协议头的链接、时间戳(报文是何时发送或接收的),以及与这个报文相关的设备。
六、设备无关接口
协议层下面是另外一个无关接口层,它将协议与具有很多各种不同功能的硬件设备连接在一起。这一层提供了一组通用函数供底层网络设备驱动程序使用,让它们可以对高层协议栈进行操作。
首先,设备驱动程序可能会通过调用 register_netdevice 或 unregister_netdevice 在内核中进行注册或注销。调用者首先填写net_device 结构,然后传递这个结构进行注册。内核调用它的 init 函数(如果定义了这种函数),然后执行一组健全性检查,并创建一个sysfs 条目,然后将新设备添加到设备列表中(内核中的活动设备链表)。在 linux/include/linux/netdevice.h 中可以找到这个 net_device 结构。这些函数都是在 linux/net/core/dev.c 中实现的。
要从协议层向设备中发送 sk_buff,就需要使用 dev_queue_xmit 函数。这个函数可以对 sk_buff 进行排队,从而由底层设备驱动程序进行最终传输(使用 sk_buff 中引用的 net_device 或 sk_buff->dev 所定义的网络设备)。dev 结构中包含了一个名为hard_start_xmit 的方法,其中保存有发起 sk_buff 传输所使用的驱动程序函数。
报文的接收通常是使用 netif_rx 执行的。当底层设备驱动程序接收一个报文(包含在所分配的 sk_buff 中)时,就会通过调用 netif_rx将 sk_buff 上传至网络层。然后,这个函数通过 netif_rx_schedule 将 sk_buff 在上层协议队列中进行排队,供以后进行处理。可以在 net/core/dev.c 中找到 dev_queue_xmit 和 netif_rx 函数。
七、设备驱动程序
网络栈底部是负责管理物理网络设备的设备驱动程序。例如,包串口使用的 SLIP 驱动程序以及以太网设备使用的以太网驱动程序都是这一层的设备。
在进行初始化时,设备驱动程序会分配一个 net_device 结构,然后使用必须的程序对其进行初始化。这些程序中有一个是 dev->hard_start_xmit,它定义了上层应该如何对 sk_buff 排队进行传输。这个程序的参数为 sk_buff。这个函数的操作取决于底层硬件,但是通常 sk_buff 所描述的报文都会被移动到硬件环或队列中。就像是设备无关层中所描述的一样,对于 NAPI 兼容的网络驱动程序来说,帧的接收使用了 netif_rx 和 netif_receive_skb 接口。NAPI 驱动程序会对底层硬件的能力进行一些限制。
设备驱动程序在 dev 结构中配置好自己的接口之后,调用 register_netdevice 便可以使用该配置。在drivers/net 中可以找出网络设备专用的驱动程序。
7.1、NAPI 工作原理
- 初始阶段:当网络接口卡(NIC)接收到数据包时,它首先会触发中断,通知网络驱动程序进行数据处理。
- 轮询切换:驱动程序会关闭中断,并通过轮询的方式处理接收到的数据包。这种方式避免了中断上下文频繁切换的高开销。
- 恢复中断:当网络负载较轻时,驱动程序可以重新启用中断,以便在需要时及时处理新到的数据包。
NAPI的核心优势在于它减少了因中断引起的上下文切换和调度开销,提高了大流量情况下的网络性能。
7.2、NAPI 在驱动中的应用
接下来是一个简单的 Linux NAPI 驱动程序示例。我们通过实现 NAPI API 来创建一个网络接口驱动程序。
1. NAPI 驱动程序实现的基本步骤
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/netdevice.h>
#include <linux/interrupt.h>
#include <linux/pci.h>
#include <linux/etherdevice.h>
static struct net_device *my_net_device;
static int my_open(struct net_device *dev)
{
netif_start_queue(dev); // 启动网络队列
return 0;
}
static int my_stop(struct net_device *dev)
{
netif_stop_queue(dev); // 停止网络队列
return 0;
}
// 处理网络接收到的数据包
static int my_poll(struct napi_struct *napi, int budget)
{
int work_done = 0;
// 模拟从硬件读取数据包的过程
while (work_done < budget) {
// 在这里处理接收到的数据包
// 如果没有更多数据包,则退出
work_done++;
}
// 如果处理完所有数据包,重新启用中断
if (work_done < budget) {
napi_complete(napi);
return 0;
}
return work_done;
}
// 网络接口卡的接收中断处理函数
static irqreturn_t my_rx_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
// 启动 NAPI 轮询机制
napi_schedule(&dev->poll);
return IRQ_HANDLED;
}
static const struct net_device_ops my_netdev_ops = {
.ndo_open = my_open,
.ndo_stop = my_stop,
};
static int __init my_driver_init(void)
{
int ret;
// 创建一个网络设备
my_net_device = alloc_etherdev(sizeof(struct napi_struct));
if (!my_net_device)
return -ENOMEM;
// 设置驱动程序的操作
my_net_device->netdev_ops = &my_netdev_ops;
// 初始化 NAPI 结构
napi_init(&my_net_device->poll, my_poll, 64);
// 注册网络设备
ret = register_netdev(my_net_device);
if (ret) {
free_netdev(my_net_device);
return ret;
}
// 启用中断并设置接收中断处理函数
ret = request_irq(10, my_rx_interrupt, IRQF_SHARED, "my_rx_interrupt", my_net_device);
if (ret) {
unregister_netdev(my_net_device);
free_netdev(my_net_device);
return ret;
}
printk(KERN_INFO "My NAPI driver loaded\n");
return 0;
}
static void __exit my_driver_exit(void)
{
free_irq(10, my_net_device);
unregister_netdev(my_net_device);
free_netdev(my_net_device);
printk(KERN_INFO "My NAPI driver unloaded\n");
}
module_init(my_driver_init);
module_exit(my_driver_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A Simple NAPI Example");
2. 驱动程序实现解释
-
网络设备:我们通过
alloc_etherdev()创建了一个网络设备,并分配了必要的内存。每个网络设备会包含一个napi_struct,这个结构体用于管理NAPI相关的轮询逻辑。 -
my_open()和my_stop():这两个函数用于启动和停止网络设备的传输队列。在my_open()中,我们启动了设备的队列,准备进行数据发送。my_stop()则停止了队列,通常在设备关闭时调用。 -
my_poll():这是 NAPI 的核心,负责轮询网络设备接收的数据包,并处理它们。在这个函数中,我们可以定义接收数据包的逻辑,并控制 NAPI 在处理完数据包后如何退出轮询。budget参数表示一次轮询能处理的最大数据包数量。 -
中断处理:我们使用
my_rx_interrupt()函数来处理接收到的中断。该函数会调用napi_schedule()来启动 NAPI 的轮询。调用napi_schedule()后,Linux 内核会在稍后的调度周期中调用my_poll()来轮询处理数据包。 -
NAPI 初始化和中断绑定:在驱动程序初始化时,我们调用
napi_init()来初始化napi_struct结构体。然后,我们使用request_irq()来注册网络设备的中断处理程序。 -
napi_complete():在my_poll()完成轮询时,我们调用napi_complete()来标记轮询已完成,并重新启用中断。
3. 驱动模块加载与卸载
-
加载:当我们加载这个模块时,内核会调用
my_driver_init()初始化网络设备,并设置接收中断处理和 NAPI。 -
卸载:当我们卸载模块时,调用
my_driver_exit()来清理资源,包括释放中断、注销网络设备以及释放内存。
7.3、NAPI 驱动的优势
-
减少中断处理开销:传统的中断处理方式会频繁触发上下文切换,而 NAPI 通过轮询方式将大量的数据包处理转移到调度上下文,从而减少了中断上下文切换的开销。
-
优化大流量情况下的性能:在流量高峰期,NAPI 允许在一个周期内处理更多的数据包,避免了频繁的中断请求对 CPU 造成的压力。
-
减少延迟:NAPI 通过优化中断和轮询的结合,减少了高流量场景下的延迟。

















 3570
3570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









