




Linux内存管理2(基于6.1内核)---内存节点node
一、内存节点概述
在 Linux 内核中,内存节点是 NUMA 支持的一部分。内存节点在内核的内存管理中起到了至关重要的作用,尤其在多处理器系统中,每个节点的内存区域被单独管理,以便优化内存分配和访问。
在 Linux 内核中,内存节点的管理主要依赖于 NUMA(Non-Uniform Memory Access) 架构的支持,内核使用 node 来标识每个内存节点。每个内存节点会有一个唯一的编号,通常从 0 开始递增。
- NUMA 系统中的节点:每个节点上的内存都可以看作是一个独立的内存池,内存分配、内存访问等操作都考虑到 NUMA 的拓扑结构。
- 内存节点和 CPU 绑定:在 NUMA 系统中,每个处理器可能会与一个或多个内存节点相关联,内存分配策略也会根据 CPU 核心与内存节点的关系来优化。
二、内存节点node
2.1 node来描述内存?
NUMA结构下, 每个处理器CPU与一个本地内存直接相连, 而不同处理器之前则通过总线进行进一步的连接, 因此相对于任何一个CPU访问本地内存的速度比访问远程内存的速度要快。
Linux适用于各种不同的体系结构, 而不同体系结构在内存管理方面的差别很大. 因此linux内核需要用一种体系结构无关的方式来表示内存。
因此linux内核把物理内存按照CPU节点划分为不同的node, 每个node作为某个cpu结点的本地内存, 而作为其他CPU节点的远程内存, 而UMA结构下, 则任务系统中只存在一个内存node, 这样对于UMA结构来说, 内核把内存当成只有一个内存node节点的伪NUMA。
2.2 内存结点的概念
CPU被划分为多个节点(node), 内存则被分簇, 每个CPU对应一个本地物理内存, 即一个CPU-node对应一个内存簇bank,即每个内存簇被认为是一个节点。
系统的物理内存被划分为几个节点(node), 一个node对应一个内存簇bank,即每个内存簇被认为是一个节点。
内存被划分为结点. 每个节点关联到系统中的一个处理器, 内核中表示为pg_data_t的实例. 系统中每个节点被链接到一个以NULL结尾的pgdat_list链表中<而其中的每个节点利用pg_data_tnode_next字段链接到下一节.而对于PC这种UMA结构的机器来说, 只使用了一个成为contig_page_data的静态pg_data_t结构。
内存中的每个节点都是由pg_data_t描述,而pg_data_t由struct pglist_data定义而来, 该数据结构定义:include/linux/mmzone.h
在分配一个页面时, Linux采用节点局部分配的策略, 从最靠近运行中的CPU的节点分配内存, 由于进程往往是在同一个CPU上运行, 因此从当前节点得到的内存很可能被用到。
2.3 pg_data_t描述内存节点
表示node的数据结构include/linux/mmzone.h,结构体的内容如下
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES];
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* number of populated zones in this node */
#ifdef CONFIG_FLATMEM /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn,
* node_present_pages, node_spanned_pages or nr_zones to stay constant.
* Also synchronizes pgdat->first_deferred_pfn during deferred page
* init.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
/* workqueues for throttling reclaim for different reasons. */
wait_queue_head_t reclaim_wait[NR_VMSCAN_THROTTLE];
atomic_t nr_writeback_throttled;/* nr of writeback-throttled tasks */
unsigned long nr_reclaim_start; /* nr pages written while throttled
* when throttling started. */
#ifdef CONFIG_MEMORY_HOTPLUG
struct mutex kswapd_lock;
#endif
struct task_struct *kswapd; /* Protected by kswapd_lock */
int kswapd_order;
enum zone_type kswapd_highest_zoneidx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_highest_zoneidx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
bool proactive_compact_trigger;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* node reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
CACHELINE_PADDING(_pad1_);
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
struct deferred_split deferred_split_queue;
#endif
#ifdef CONFIG_NUMA_BALANCING
/* start time in ms of current promote rate limit period */
unsigned int nbp_rl_start;
/* number of promote candidate pages at start time of current rate limit period */
unsigned long nbp_rl_nr_cand;
/* promote threshold in ms */
unsigned int nbp_threshold;
/* start time in ms of current promote threshold adjustment period */
unsigned int nbp_th_start;
/*
* number of promote candidate pages at start time of current promote
* threshold adjustment period
*/
unsigned long nbp_th_nr_cand;
#endif
/* Fields commonly accessed by the page reclaim scanner */
/*
* NOTE: THIS IS UNUSED IF MEMCG IS ENABLED.
*
* Use mem_cgroup_lruvec() to look up lruvecs.
*/
struct lruvec __lruvec;
unsigned long flags;
#ifdef CONFIG_LRU_GEN
/* kswap mm walk data */
struct lru_gen_mm_walk mm_walk;
/* lru_gen_folio list */
struct lru_gen_memcg memcg_lru;
#endif
CACHELINE_PADDING(_pad2_);
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
#ifdef CONFIG_NUMA
struct memory_tier __rcu *memtier;
#endif
#ifdef CONFIG_MEMORY_FAILURE
struct memory_failure_stats mf_stats;
#endif
} pg_data_t;
| 字段 | 描述 |
|---|---|
| node_zones | 每个Node划分为不同的zone,分别为ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM |
| node_zonelists | 这个是备用节点及其内存域的列表,当当前节点的内存不够分配时,会选取访问代价最低的内存进行分配。分配内存操作时的区域顺序,当调用free_area_init_core()时,由mm/page_alloc.c文件中的build_zonelists()函数设置 |
| nr_zones | 当前节点中不同内存域zone的数量,1到3个之间。并不是所有的node都有3个zone的,比如一个CPU簇就可能没有ZONE_DMA区域 |
| node_mem_map | node中的第一个page,它可以指向mem_map中的任何一个page,指向page实例数组的指针,用于描述该节点所拥有的的物理内存页,它包含了该页面所有的内存页,被放置在全局mem_map数组中 |
| bdata | 这个仅用于引导程序boot 的内存分配,内存在启动时,也需要使用内存,在这里内存使用了自举内存分配器,这里bdata是指向内存自举分配器的数据结构的实例 |
| node_start_pfn | pfn是page frame number的缩写。这个成员是用于表示node中的开始那个page在物理内存中的位置的。是当前NUMA节点的第一个页帧的编号,系统中所有的页帧是依次进行编号的,这个字段代表的是当前节点的页帧的起始值,对于UMA系统,只有一个节点,所以该值总是0 |
| node_present_pages | node中的真正可以使用的page数量 |
| node_spanned_pages | 该节点以页帧为单位的总长度,这个不等于前面的node_present_pages,因为这里面包含空洞内存 |
| node_id | node的NODE ID 当前节点在系统中的编号,从0开始 |
| kswapd_wait | node的等待队列,交换守护列队进程的等待列表 |
| kswapd_max_order | 需要释放的区域的长度,以页阶为单位 |
| classzone_idx | 这个字段暂时没弄明白,不过其中的zone_type是对ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGH,ZONE_MOVABLE,__MAX_NR_ZONES的枚举 |
2.4 结点的内存管理域
include/linux/mmzone.h
typedef struct pglist_data {
/* 包含了结点中各内存域的数据结构 , 可能的区域类型用zone_type表示*/
struct zone node_zones[MAX_NR_ZONES];
/* 指点了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存 */
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* 保存结点中不同内存域的数目 */
...
} pg_data_t;
node_zones[MAX_NR_ZONES]数组保存了节点中各个内存域的数据结构,
而node_zonelist则指定了备用节点以及其内存域的列表, 以便在当前结点没有可用空间时, 在备用节点分配内存。
nr_zones存储了结点中不同内存域的数目。
2.5 结点的内存页面
include/linux/mmzone.h
typedef struct pglist_data
{
...
#ifdef CONFIG_FLATMEM /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif /* 指向page实例数组的指针,用于描述结点的所有物理内存页,它包含了结点中所有内存域的页。 */
/* /*起始页面帧号,指出该节点在全局mem_map中的偏移
系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一) */
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages 结点中页帧的数目 */
unsigned long node_spanned_pages; /* total size of physical page range, including holes 该结点以页帧为单位计算的长度,包含内存空洞 */
int node_id; /* 全局结点ID,系统中的NUMA结点都从0开始编号 */
...
} pg_data_t;
其中node_mem_map是指向页面page实例数组的指针, 用于描述结点的所有物理内存页. 它包含了结点中所有内存域的页。
node_start_pfn是该NUMA结点的第一个页帧的逻辑编号. 系统中所有的节点的页帧是一次编号的, 每个页帧的编号是全局唯一的. node_start_pfn在UMA系统中总是0, 因为系统中只有一个内存结点, 因此其第一个页帧编号总是0。
node_present_pages指定了结点中页帧的数目, 而node_spanned_pages则给出了该结点以页帧为单位计算的长度. 二者的值不一定相同, 因为结点中可能有一些空洞, 并不对应真正的页帧。
2.6 交换守护进程
include/linux/mmzone.h
typedef struct pglist_data
{
...
wait_queue_head_t kswapd_wait; /* 交换守护进程的等待队列,
在将页帧换出结点时会用到。后面的文章会详细讨论。 */
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() 指向负责该结点的交换守护进程的task_struct。 */
...
};
kswapd指向了负责将该结点的交换守护进程的task_struct. 在将页帧换出结点时会唤醒该进程。
kswap_wait是交换守护进程(swap daemon)的等待队列。
而kswapd_max_order用于页交换子系统的实现, 用来定义需要释放的区域的长度。
三、结点状态
3.1 结点状态标识node_states
内核用enum node_state变量标记了内存结点所有可能的状态信息,include/linux/nodemask.h
enum node_states {
N_POSSIBLE, /* The node could become online at some point
结点在某个时候可能变成联机*/
N_ONLINE, /* The node is online
节点是联机的*/
N_NORMAL_MEMORY, /* The node has regular memory
结点是普通内存域 */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory
结点是普通或者高端内存域*/
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};
| 状态 | 描述 |
|---|---|
| N_POSSIBLE | 结点在某个时候可能变成联机 |
| N_ONLINE | 节点是联机的 |
| N_NORMAL_MEMORY | 结点是普通内存域 |
| N_HIGH_MEMORY | 结点是普通或者高端内存域 |
| N_MEMORY | 结点是普通,高端内存或者MOVEABLE域 |
| N_CPU | 结点有一个或多个CPU |
其中N_POSSIBLE, N_ONLINE和N_CPU用于CPU和内存的热插拔。
对内存管理有必要的标志是N_HIGH_MEMORY和N_NORMAL_MEMORY, 如果结点有普通或高端内存则使用N_HIGH_MEMORY, 仅当结点没有高端内存时才设置N_NORMAL_MEMORY。
N_NORMAL_MEMORY, /* The node has regular memory
结点是普通内存域 */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory
结点是高端内存域*/
#else
/* 没有高端内存域, 仍设置N_NORMAL_MEMORY */
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
同样ZONE_MOVABLE内存域同样用类似的方法设置, 仅当系统中存在ZONE_MOVABLE内存域内存域(配置了CONFIG_MOVABLE_NODE参数)时, N_MEMORY才被设定, 否则则被设定成N_HIGH_MEMORY, 而N_HIGH_MEMORY设定与否同样依赖于参数CONFIG_HIGHMEM的设定
#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
3.2 结点状态设置函数
内核提供了辅助函数来设置或者清楚位域活特定结点的一个比特位:
include/linux/nodemask.h
static inline int node_state(int node, enum node_states state)
static inline void node_set_state(int node, enum node_states state)
static inline void node_clear_state(int node, enum node_states state)
static inline int num_node_state(enum node_states state)
此外宏for_each_node_state(__node, __state)用来迭代处于特定状态的所有结点,
#define for_each_node_state(__node, __state) \
for_each_node_mask((__node), node_states[__state])
而for_each_online_node(node)则负责迭代所有的活动结点.
如果内核编译只支持当个结点(即使用平坦内存模型), 则没有结点位图, 上述操作该位图的函数则变成空操作, 其定义形式如下:include/linux/nodemask.h
#if MAX_NUMNODES > 1
/* some real function */
#else
/* some NULL function */
#endif
四、查找内存结点
4.1 linux6.1的实现
for_each_online_pgdat遍历所有的内存结点:
内核提供了include/linux/mmzone.h来遍历节点:
/**
* for_each_online_pgdat - helper macro to iterate over all online nodes
* @pgdat: pointer to a pg_data_t variable
*/
#define for_each_online_pgdat(pgdat) \
for (pgdat = first_online_pgdat(); \
pgdat; \
pgdat = next_online_pgdat(pgdat))
其中first_online_pgdat可以查找到系统中第一个内存节点的pg_data_t信息, next_online_pgdat则查找下一个内存节点。
下面我们来看看first_online_pgdat和next_online_pgdat是怎么实现的。
first_online_node和next_online_node返回结点编号。
由于没了next指针域pgdat_next和全局node链表pgdat_list, 因而内核提供了first_online_node指向第一个内存结点, 而通过next_online_node来查找其下一个结点, 他们是通过状态node_states的位图来查找结点信息的, include/linux/nodemask.h
#define first_online_node first_node(node_states[N_ONLINE])
#define first_memory_node first_node(node_states[N_MEMORY])
static inline unsigned int next_online_node(int nid)
{
return next_node(nid, node_states[N_ONLINE]);
}
first_online_node和next_online_node返回所查找的node结点的编号, 而有了编号, 我们直接去node_data数组中按照编号进行索引即可去除对应的pg_data_t的信息.内核提供了NODE_DATA(node_id)宏函数来按照编号来查找对应的结点, 它的工作其实其实就是从node_data数组中进行索引。
NODE_DATA(node_id)查找编号node_id的结点pg_data_t信息
移除了pg_data_t->pgdat_next指针域. 但是所有的node都存储在node_data数组中, 内核提供了函数NODE_DATA直接通过node编号索引节点pg_data_t信息。
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[(nid)])
first_online_pgdat和next_online_pgdat返回结点的pg_data_t
-
首先通过first_online_node和next_online_node找到节点的编号
-
然后通过NODE_DATA(node_id)查找到对应编号的结点的pg_data_t信息
mm/mmzone.c
struct pglist_data *first_online_pgdat(void)
{
return NODE_DATA(first_online_node);
}
struct pglist_data *next_online_pgdat(struct pglist_data *pgdat)
{
int nid = next_online_node(pgdat->node_id);
if (nid == MAX_NUMNODES)
return NULL;
return NODE_DATA(nid);
}
五、总结
1. NUMA 节点的管理
在 Linux 内核中,NUMA 节点通常通过以下几个数据结构和机制来管理:
struct node:这个结构体表示一个 NUMA 节点,内核通过它来管理每个节点的资源和状态。sysfs文件系统:通过/sys/devices/system/node/路径来访问内存节点的信息。numactrl工具:一个命令行工具,用来显示和设置 NUMA 拓扑结构。
2. 查找内存节点的方法
Linux 6.1 提供了多种查找内存节点的方法,既可以通过命令行工具查看,也可以通过内核代码进行访问。
2.1. 通过 sysfs 查找内存节点
在 Linux 中,sysfs 文件系统提供了访问内存节点的接口。内存节点的信息存储在 /sys/devices/system/node/ 路径下。
可以使用以下命令来列出所有的 NUMA 节点:
可以通过读取每个节点目录下的文件来查看该节点的详细信息,例如查看每个节点的内存大小:
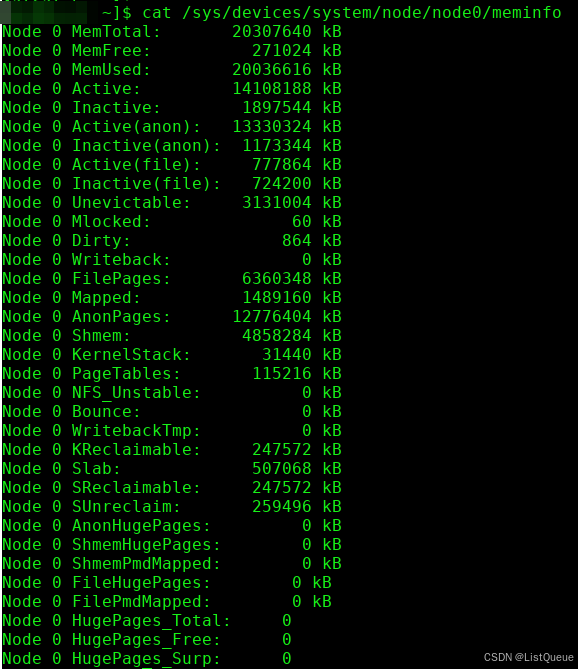
cat /sys/devices/system/node/node0/meminfo
这个文件包含了关于节点的内存使用情况,包括总内存、可用内存、已用内存等信息。
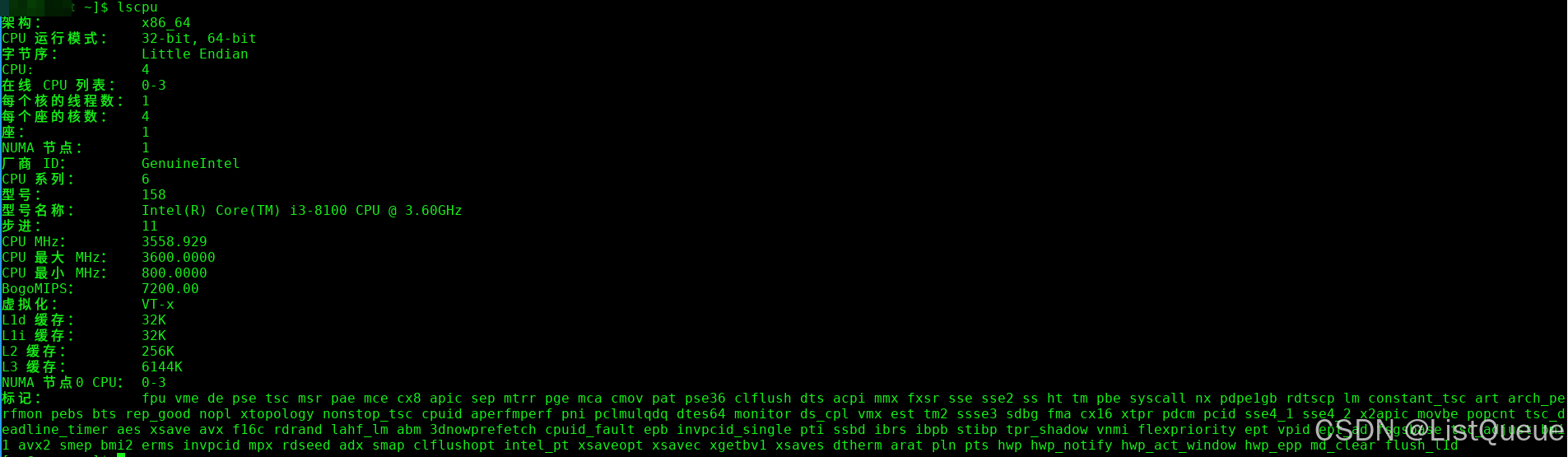
2.2. 通过 lscpu 命令查看 NUMA 节点
lscpu 命令是一个显示 CPU 架构信息的工具,它也会显示系统中的 NUMA 节点信息。运行以下命令:
输出中会包含一个 NUMA node(s) 字段,显示系统中有多少个 NUMA 节点。
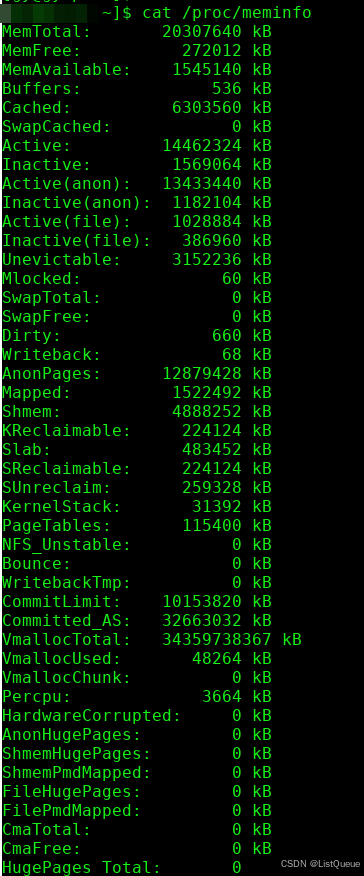
2.3. 通过 /proc 文件系统查找内存节点
Linux 还通过 /proc 文件系统暴露了内存和 CPU 信息,虽然它主要用于提供运行时信息,但也可以间接帮助了解 NUMA 节点。
此命令会显示当前系统内存的详细信息,但不会直接显示 NUMA 节点的详细信息。为了获得 NUMA 节点的细节,依赖于 /sys 文件系统是更为直接的方式。
2.4. 通过内核代码查找 NUMA 节点
在 Linux 内核代码中,可以通过访问内核中的相关数据结构来查找 NUMA 节点。例如,内核中的 node_to_cpu() 函数用于获取 NUMA 节点与 CPU 核心的映射。
#include <linux/topology.h>
unsigned int node_to_cpu(unsigned int node);
3. 内存节点的数据结构
在内核中,NUMA 节点的管理是通过一些关键数据结构来实现的。以下是一些主要的结构体:
3.1. struct node
每个 NUMA 节点由 struct node 来表示,该结构体包含了与节点相关的内存管理信息、CPU 关联信息等。
struct node {
unsigned long node_id;
struct pglist_data *node_data;
struct cpumask node_cpumask;
// 其他内存和CPU相关的数据
};
3.2. pglist_data
pglist_data 是与每个 NUMA 节点相关联的内存数据结构。它包含了该节点上所有物理内存的管理信息。
struct pglist_data {
unsigned long node_start_pfn;
unsigned long node_spanned_pages;
struct free_area free_area[MAX_ORDER];
// 其他与内存分配相关的数据
};
3.3. numactrl 和 numa_node
Linux 中的 numactrl 工具通过与 numa_node 进行交互来查询和管理 NUMA 节点。每个节点都有一个唯一的标识符 node_id,用于区分不同的内存节点。
4. 内核中查找 NUMA 节点的实现
内核通过访问 NUMA 数据结构中的节点信息来查找 NUMA 节点。例如,node_online() 函数用于检查一个 NUMA 节点是否处于活动状态:
int node_online(int node)
{
return node_state(node, N_NORMAL_MEMORY);
}
node_state() 函数检查特定节点的状态,以确定该节点是否在线(即是否具有可用内存)。
5. 内存节点的拓扑结构
在 NUMA 系统中,每个节点可以包含多个 CPU 核心,每个 CPU 核心可以访问本地或远程的内存。操作系统会通过 NUMA 拓扑结构来优化内存访问,确保每个进程尽可能访问本地节点的内存,从而减少远程内存访问的开销。
内核会根据这些拓扑结构分配内存给进程,并通过 NUMA 策略确保进程尽量在本地节点执行,以提高性能。

















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









