




Linux-进程的管理与调度20(基于6.1内核)---Linux进程优先级
一、 linux优先级的表示
1.1、 优先级的内核表示
1. 进程优先级类型
Linux 使用不同的优先级类型来表示进程的优先级,主要有两个:静态优先级(Static Priority)和动态优先级(Dynamic Priority)。
(1) 静态优先级(Static Priority)
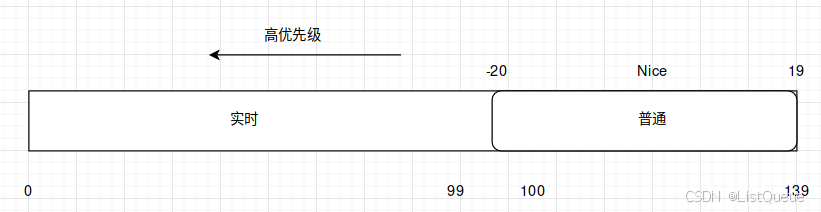
静态优先级是操作系统在创建进程时根据某些因素(如进程的优先级参数)确定的。静态优先级较高的进程在调度时会优先获得 CPU 资源。静态优先级的范围通常在 0 到 139 之间,其中 0 表示最高优先级,139 表示最低优先级。静态优先级的改变通常与进程的优先级设置(例如通过 nice 命令)有关。
- 0-99:标准优先级(可以通过
nice命令调整) - 100-139:实时优先级(由实时调度策略控制)
(2) 动态优先级(Dynamic Priority)
动态优先级是由 Linux 内核根据进程的执行状态(如进程的等待时间、CPU 使用情况等)动态调整的。在大多数情况下,Linux 使用 CFS(完全公平调度器) 来处理动态优先级。CFS 根据进程的执行时间、等待时间和系统负载来动态调整优先级。
动态优先级的范围一般为 100-139,它表示进程的“相对优先级”。在 CFS 中,进程的动态优先级会根据其“虚拟运行时间”(vruntime)进行调整,vruntime 较小的进程会优先得到调度。动态优先级较低的进程将被延迟执行。
2. nice 值与优先级
nice 是 Linux 中用来调整进程静态优先级的工具。通过设置进程的 nice 值,可以影响其调度优先级。nice 值 的取值范围是 -20 到 19,其中:
- -20 表示最高优先级,进程会尽可能占用 CPU 资源。
- 19 表示最低优先级,进程会尽可能等待其他高优先级的进程执行。
通过调整 nice 值,用户可以影响某个进程的优先级,或者给一些进程设置较低优先级,以便为系统中的其他进程腾出更多的资源。
例如:
# 启动一个nice值为10的进程(较低优先级)
nice -n 10 my_program
3. 实时调度与优先级
Linux 支持实时进程调度,实时进程拥有最高的调度优先级。实时调度的优先级范围是 1-99,其中 1 是最高优先级,99 是最低的实时优先级。实时进程不受 nice 值的影响,实时任务会被调度器优先执行。
Linux 提供了两种主要的实时调度策略:
- SCHED_FIFO:先进先出调度策略,进程按顺序执行,当前进程执行完毕后才会切换到下一个进程。实时进程不会被打断,直到它执行完毕。
- SCHED_RR:轮转调度策略,实时进程按照优先级和时间片轮流执行。每个实时进程执行一段时间后会被中断,调度器会选择下一个同等优先级的进程执行。
例如,使用 chrt 命令可以设置一个进程为实时进程:
# 将进程的调度策略设置为 SCHED_FIFO,优先级为50
chrt -f 50 my_program
4. 调度器与优先级
Linux 中的调度器是基于 CFS(完全公平调度器) 和 实时调度策略(SCHED_FIFO 和 SCHED_RR)来处理进程调度的:
- CFS(完全公平调度器):对于普通进程,CFS 使用“虚拟运行时间”(
vruntime)来决定进程的调度顺序。CFS 会尽可能保证每个进程获得公平的 CPU 时间,优先调度那些等待时间较长的进程。 - 实时调度策略:对于实时任务,Linux 使用 FIFO 或轮转策略来进行调度,实时任务优先级高,不会被其他普通进程打断。
5. 优先级与 CPU 时间分配
进程的优先级直接影响其在 CPU 时间分配中的权重:
- 高优先级进程:更频繁地获得 CPU 资源,优先执行。
- 低优先级进程:只有当系统空闲或高优先级进程没有任务时才会被执行。
6. 优先级和负载均衡
在多核系统中,Linux 还会考虑负载均衡的问题。操作系统会在多个 CPU 核心之间动态地分配任务,以避免某些核心过载,而其他核心空闲。
| 优先级范围 | 描述 |
|---|---|
| 0——99 | 实时进程 |
| 100——139 | 非实时进程 |
内核的优先级表示
内核表示优先级的所有信息:include/linux/sched/prio.h, 其中定义了一些表示优先级的宏和函数.
优先级数值通过宏来定义, 如下所示,其中MAX_NICE和MIN_NICE定义了nice的最大最小值
而MAX_RT_PRIO指定了实时进程的最大优先级, 而MAX_PRIO则是普通进程的最大优先级数值
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
/*
* Priority of a process goes from 0..MAX_PRIO-1, valid RT
* priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH
* tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority
* values are inverted: lower p->prio value means higher priority.
*/
#define MAX_RT_PRIO 100
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
| 宏 | 值 | 描述 |
|---|---|---|
| MIN_NICE | -20 | 对应于优先级100, 可以使用NICE_TO_PRIO和PRIO_TO_NICE转换 |
| MAX_NICE | 19 | 对应于优先级139, 可以使用NICE_TO_PRIO和PRIO_TO_NICE转换 |
| NICE_WIDTH | 40 | nice值得范围宽度, 即[-20, 19]共40个数字的宽度 |
| MAX_RT_PRIO, MAX_USER_RT_PRIO | 100 | 实时进程的最大优先级 |
| MAX_PRIO | 140 | 普通进程的最大优先级 |
| DEFAULT_PRIO | 120 | 进程的默认优先级, 对应于nice=0 |
| MAX_DL_PRIO | 0 | 使用EDF最早截止时间优先调度算法的实时进程最大的优先级 |
而内核提供了一组宏将优先级在各种不同的表示形之间转移。
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
/*
* Convert nice value [19,-20] to rlimit style value [1,40].
*/
static inline long nice_to_rlimit(long nice)
{
return (MAX_NICE - nice + 1);
}
/*
* Convert rlimit style value [1,40] to nice value [-20, 19].
*/
static inline long rlimit_to_nice(long prio)
{
return (MAX_NICE - prio + 1);
}
DEF最早截至时间优先实时调度算法的优先级描述
include/linux/sched/deadline.h
static inline int dl_prio(int prio)
{
if (unlikely(prio < MAX_DL_PRIO))
return 1;
return 0;
}
static inline int dl_task(struct task_struct *p)
{
return dl_prio(p->prio);
}
static inline bool dl_time_before(u64 a, u64 b)
{
return (s64)(a - b) < 0;
}
1.2、 进程的优先级表示
struct task_struct
{
/* 进程优先级
* prio: 动态优先级,范围为100~139,与静态优先级和补偿(bonus)有关
* static_prio: 静态优先级,static_prio = 100 + nice + 20 (nice值为-20~19,所以static_prio值为100~139)
* normal_prio: 没有受优先级继承影响的常规优先级,具体见normal_prio函数,跟属于什么类型的进程有关
*/
int prio, static_prio, normal_prio;
/* 实时进程优先级 */
unsigned int rt_priority;
}
动态优先级 静态优先级 实时优先级
其中task_struct采用了三个成员表示进程的优先级:prio和normal_prio表示动态优先级, static_prio表示进程的静态优先级.
为什么表示动态优先级需要两个值prio和normal_prio?
调度器会考虑的优先级则保存在prio. 由于在某些情况下内核需要暂时提高进程的优先级, 因此需要用prio表示. 由于这些改变不是持久的, 因此静态优先级static_prio和普通优先级normal_prio不受影响。
此外还用了一个字段rt_priority保存了实时进程的优先级
| 字段 | 描述 |
|---|---|
| static_prio | 用于保存静态优先级, 是进程启动时分配的优先级, ,可以通过nice和sched_setscheduler系统调用来进行修改, 否则在进程运行期间会一直保持恒定 |
| rt_priority | 用于保存实时优先级 |
| normal_prio | 表示基于进程的静态优先级static_prio和调度策略计算出的优先级. 因此即使普通进程和实时进程具有相同的静态优先级, 其普通优先级也是不同的, 进程分叉(fork)时, 子进程会继承父进程的普通优先级 |
| prio | 保存进程的动态优先级 |
实时进程的优先级用实时优先级rt_priority来表示。
二、 进程优先级的计算
前面说了task_struct中的几个优先级的字段:
| 静态优先级 | 实时优先级 | 普通优先级 | 动态优先级 |
|---|---|---|---|
| static_prio | rt_priority | normal_prio | prio |
但是这些优先级是如何关联的呢, 动态优先级prio又是如何计算的呢?
2.1、 normal_prio函数设置普通优先级normal_prio
静态优先级static_prio(普通进程)和实时优先级rt_priority(实时进程)是计算的起点。
因此他们也是进程创建的时候设定好的, 我们通过nice修改的就是普通进程的静态优先级static_prio
首先通过静态优先级static_prio计算出普通优先级normal_prio, 该工作可以由nromal_prio来完成kernel/sched/core.c
/*
* Calculate the expected normal priority: i.e. priority
* without taking RT-inheritance into account. Might be
* boosted by interactivity modifiers. Changes upon fork,
* setprio syscalls, and whenever the interactivity
* estimator recalculates.
*/
static inline int normal_prio(struct task_struct *p)
{
return __normal_prio(p->policy, p->rt_priority, PRIO_TO_NICE(p->static_prio));
}
static inline int __normal_prio(int policy, int rt_prio, int nice)
{
int prio;
if (dl_policy(policy)) /* EDF调度的实时进程 */
prio = MAX_DL_PRIO-1;
else if (rt_policy(policy)) /* 普通实时进程的优先级 */
prio = MAX_RT_PRIO-1 - rt_priority;
else /* 普通进程的优先级 */
prio = NICE_TO_PRIO(nice);
return prio;
}
| 进程类型 | 调度器 | 普通优先级normal_prio |
|---|---|---|
| EDF实时进程 | EDF | MAX_DL_PRIO-1 = -1 |
| 普通实时进程 | RT |
prio = MAX_RT_PRIO - 1 - rt_prio; |
| 普通进程 | CFS |
prio = NICE_TO_PRIO(nice); |
普通优先级normal_prio需要根据普通进程和实时进程进行不同的计算, 其中__normal_prio适用于普通进程, 直接将普通优先级normal_prio设置为静态优先级static_prio. 而实时进程的普通优先级计算依据其实时优先级rt_priority.
1、 辅助函数task_has_dl_policy和task_has_rt_policy
kernel/sched/sched.h
其本质其实就是传入task->policy调度策略字段看其值等于SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE, SCHED_FIFO, SCHED_RR, SCHED_DEADLINE中的哪个, 从而确定其所属的调度类, 进一步就确定了其进程类型
static inline int idle_policy(int policy)
{
return policy == SCHED_IDLE;
}
static inline int fair_policy(int policy)
{
return policy == SCHED_NORMAL || policy == SCHED_BATCH;
}
static inline int rt_policy(int policy)
{
return policy == SCHED_FIFO || policy == SCHED_RR;
}
static inline int dl_policy(int policy)
{
return policy == SCHED_DEADLINE;
}
static inline bool valid_policy(int policy)
{
return idle_policy(policy) || fair_policy(policy) ||
rt_policy(policy) || dl_policy(policy);
}
static inline int task_has_rt_policy(struct task_struct *p)
{
return rt_policy(p->policy);
}
static inline int task_has_dl_policy(struct task_struct *p)
{
return dl_policy(p->policy);
}
2、 关于rt_priority数值越大, 实时进程优先级越高的问题
对于一个实时进程,他有两个参数来表明优先级——prio 和 rt_priority,
prio才是调度所用的最终优先级数值,这个值越小,优先级越高;
而rt_priority 被称作实时进程优先级,他要经过转化——prio=MAX_RT_PRIO - 1- rt_priority;
MAX_RT_PRIO = 100, ;这样意味着rt_priority值越大,优先级越高;
而内核提供的修改优先级的函数,是修改rt_priority的值,所以越大,优先级越高。
所以用户在使用实时进程或线程,在修改优先级时,就会有“优先级值越大,优先级越高的说法”,也是对的。
为什么增加了一个__normal_prio函数做了这么简单的工作, 这个其实是有历史原因的: 在早期的O(1)O(1)调度器中, 普通优先级的计算涉及相当多技巧性地工作, 必须检测交互式进程并提高其优先级, 而必须”惩罚”非交互进程, 以便是得系统获得更好的交互体验. 这需要很多启发式的计算, 他们可能完成的很好, 也可能不工作.
2.2、 effective_prio函数设置动态优先级prio
可以通过函数effective_prio用静态优先级static_prio计算动态优先级prio, 即·
p->prio = effective_prio(p);
kernel/sched/core.c
/*
* Calculate the current priority, i.e. the priority
* taken into account by the scheduler. This value might
* be boosted by RT tasks, or might be boosted by
* interactivity modifiers. Will be RT if the task got
* RT-boosted. If not then it returns p->normal_prio.
*/
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
首先effective_prio设置了普通优先级, 显然我们用effective_prio同时设置了两个优先级(普通优先级normal_prio和动态优先级prio)
因此计算动态优先级的流程如下:
-
设置进程的普通优先级(实时进程99-rt_priority, 普通进程为static_priority)
-
计算进程的动态优先级(实时进程则维持动态优先级的prio不变, 普通进程的动态优先级即为其普通优先级)
不同类型进程的计算结果:
| 进程类型 | 实时优先级rt_priority | 静态优先级static_prio | 普通优先级normal_prio | 动态优先级prio |
|---|---|---|---|---|
| EDF调度的实时进程 | rt_priority | 不使用 | MAX_DL_PRIO-1 | 维持原prio不变 |
| RT算法调度的实时进程 | rt_priority | 不使用 | MAX_RT_PRIO-1-rt_priority | 维持原prio不变 |
| 普通进程 | 不使用 | static_prio | static_prio | static_prio |
| 优先级提高的普通进程 | 不使用 | static_prio(改变) | static_prio | 维持原prio不变 |
1、 为什么effective_prio使用优先级数值检测实时进程
t_prio会检测普通优先级是否在实时范围内, 即是否小于MAX_RT_PRIOinclude/linux/sched/rt.h
static inline int rt_prio(int prio)
{
if (unlikely(prio < MAX_RT_PRIO))
return 1;
return 0;
}
而前面我们在normal_prio的时候, 则通过task_has_rt_policy来判断其policy属性来确定
policy == SCHED_FIFO || policy == SCHED_RR;
那么为什么effective_prio重检测实时进程是rt_prio基于优先级数值, 而非task_has_rt_policy或者rt_policy?
对于临时提高至实时优先级的非实时进程来说, 这个是必要的, 这种情况可能发生在是哦那个实时互斥量(RT-Mutex)时.
2.3、 设置prio的时机
- 在新进程用wake_up_new_task唤醒时, 或者使用nice系统调用改变其静态优先级时, 则会通过effective_prio的方法设置p->prio
wake_up_new_task(), 计算此进程的优先级和其他调度参数,将新的进程加入到进程调度队列并设此进程为可被调度的,以后这个进程可以被进程调度模块调度执行。
- 进程创建时copy_process通过调用sched_fork来初始化和设置调度器的过程中会设置子进程的优先级
2.4、 nice系统调用的实现
nice系统调用是的内核实现是sys_nice, kernel/sched/core.c
/*
* sys_nice - change the priority of the current process.
* @increment: priority increment
*
* sys_setpriority is a more generic, but much slower function that
* does similar things.
*/
SYSCALL_DEFINE1(nice, int, increment)
{
long nice, retval;
/*
* Setpriority might change our priority at the same moment.
* We don't have to worry. Conceptually one call occurs first
* and we have a single winner.
*/
increment = clamp(increment, -NICE_WIDTH, NICE_WIDTH);
nice = task_nice(current) + increment;
nice = clamp_val(nice, MIN_NICE, MAX_NICE);
if (increment < 0 && !can_nice(current, nice))
return -EPERM;
retval = security_task_setnice(current, nice);
if (retval)
return retval;
set_user_nice(current, nice);
return 0;
}
2.5、 fork时优先级的继承
在进程分叉处子进程时, 子进程的静态优先级继承自父进程. 子进程的动态优先级p->prio则被设置为父进程的普通优先级, 这确保了实时互斥量引起的优先级提高不会传递到子进程.
可以参照sched_fork函数, 在进程复制的过程中copy_process通过调用sched_fork来设置子进程优先级。kernel/sched/core.c
/*
* fork()/clone()-time setup:
*/
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
/* ...... */
/*
* Make sure we do not leak PI boosting priority to the child.
* 子进程的动态优先级被设置为父进程普通优先级
*/
p->prio = current->normal_prio;
/*
* Revert to default priority/policy on fork if requested.
* sched_reset_on_fork标识用于判断是否恢复默认的优先级或调度策略
*/
if (unlikely(p->sched_reset_on_fork)) /* 如果要恢复默认的调度策略, 即SCHED_NORMAL */
{
/* 首先是设置静态优先级static_prio
* 由于要恢复默认的调度策略
* 对于父进程是实时进程的情况, 静态优先级就设置为DEFAULT_PRIO
*
* 对于父进程是非实时进程的情况, 要保证子进程优先级不小于DEFAULT_PRIO
* 父进程nice < 0即static_prio < 的重新设置为DEFAULT_PRIO的重新设置为DEFAULT_PRIO
* 父进程nice > 0的时候, 则什么也没做
* */
if (task_has_dl_policy(p) || task_has_rt_policy(p))
{
p->policy = SCHED_NORMAL; /* 普通进程调度策略 */
p->static_prio = NICE_TO_PRIO(0); /* 静态优先级为nice = 0 即DEFAULT_PRIO*/
p->rt_priority = 0; /* 实时优先级为0 */
}
else if (PRIO_TO_NICE(p->static_prio) < 0) /* */
p->static_prio = NICE_TO_PRIO(0); /* */
/* 接着就通过__normal_prio设置其普通优先级和动态优先级
* 这里做了一个优化, 因为用sched_reset_on_fork标识设置恢复默认调度策略后
* 创建的子进程是是SCHED_NORMAL的非实时进程
* 因此就不需要绕一大圈用effective_prio设置normal_prio和prio了
* 直接用__normal_prio设置就可 */
p->prio = p->normal_prio = __normal_prio(p); /* 设置*/
/* 设置负荷权重 */
set_load_weight(p);
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
/* ...... */
}

















 2
2

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









