




Linux-进程的管理与调度16(基于6.1内核)---Linux进程调度策略
一、 Linux 调度器的演变
Linux 调度器主要版本的演变过程:
1. 早期的 Linux 调度器(2.0 之前)
在 Linux 内核的最早版本中,调度器非常简单,最初只支持 抢占式调度(preemptive scheduling),并且主要基于 轮转调度(round-robin scheduling)算法。调度器的设计目标是使系统能够运行多任务,但没有很高的性能优化。早期的调度器没有太多对 CPU 亲和性、进程优先级、实时任务等高级特性的支持。
2. Linux 2.4 系列调度器
在 2.4 内核中,调度器得到了较大的改进。主要变化包括:
- 引入了 多级队列调度算法(multi-level feedback queue, MLFQ)。
- 增强了 实时任务调度,例如支持 FIFO(先进先出)和 Round Robin(轮转调度)调度策略。
- 增加了对 进程优先级的更精细控制。
尽管 2.4 的调度器有所改进,但它仍然没有很好地支持多核处理器的特性。调度主要是基于任务的优先级和进程的时间片进行调度,系统对于多处理器的调度策略较为简单。
3. Linux 2.6 系列调度器
Linux 2.6 内核是一个具有里程碑意义的版本,它在调度器方面进行了大量的改进。主要的变化包括:
- O(1) 调度器:Linux 2.6.0 引入了 O(1) 调度器,这意味着调度算法在每次调度时的复杂度是常数时间。该调度器引入了两个主要的数据结构:运行队列和就绪队列,使得调度变得更加高效。
- CPU 亲和性:O(1) 调度器增加了支持 CPU 亲和性,即进程更倾向于在曾经运行过的 CPU 上运行,从而减少缓存失效,提高性能。
- 实时任务支持:改进了实时调度算法,使得实时任务(如 RT 进程)能够在多核机器上得到更好的支持。
- 负载平衡:O(1) 调度器也增强了负载平衡的功能,改进了多核系统下的进程调度。
尽管 O(1) 调度器在多核系统上有显著改进,但由于它仍然依赖于优先级轮转,因此在负载变化较大的场景下,它并不总是表现得最好。
4. 完全公平调度器(CFS,Linux 2.6.23)
Linux 2.6.23 引入了 完全公平调度器(CFS),这被认为是 Linux 调度器的一个重大变革。CFS 的目标是实现一个“公平”的调度策略,使得每个任务都能平等地使用 CPU 时间,基于任务的 虚拟运行时间(virtual runtime,vruntime)来决定任务的执行顺序。
CFS 的主要特点包括:
- 公平性:通过使用虚拟运行时间来确保每个任务在多个任务竞争 CPU 时能够公平地得到 CPU 时间。
- 平滑的调度:CFS 尽量避免了任务优先级变化带来的不必要的上下文切换,从而减少了调度延迟。
- 无时间片:CFS 不再使用传统的时间片(time slice)机制,而是使用任务的虚拟运行时间来进行调度。任务的虚拟运行时间越小,越有可能被调度到 CPU 上运行。
- 红黑树数据结构:CFS 使用了一个红黑树来管理就绪队列,这使得查找下一个最有可能运行的任务更加高效。
- 负载均衡:CFS 在多核系统中有更好的负载均衡性能,能够更智能地将任务分配到不同的 CPU 上。
5. 实时调度器改进(RT 调度器)
在 2.6.28 版本中,Linux 增强了实时任务的调度能力,特别是对于 SCHED_FIFO 和 SCHED_RR 实时调度策略的改进。实时调度器的目标是确保实时任务能够在更短的延迟内执行,并确保这些任务能优先于其他普通任务执行。
- 实时任务的优先级:实时任务有较高的优先级,因此调度器会优先考虑实时任务,避免它们被抢占或延迟。
- 内核预占性:实时调度器的改进还包括内核的预占性增强,使得实时任务即使在内核中运行时,也能优先于其他任务得到执行。
6. CFS 的进一步优化
在之后的版本中,CFS 持续得到了改进,主要包括:
- 针对多核优化:在多核系统中,CFS 引入了更多的负载均衡机制,以确保每个 CPU 上的负载尽量平衡,提高系统的整体性能。
- 调度延迟优化:进一步减少了调度延迟,尤其是针对短时任务的调度。
- I/O 调度的融合:CFS 逐渐与 I/O 调度机制进行了更深层次的集成,使得 I/O 密集型任务也能够更公平地与 CPU 密集型任务竞争资源。
7. Linux 4.x 系列
Linux 4.x 版本中的调度器进一步加强了对 NUMA(非一致性内存访问)架构的支持和对 多核系统的优化。以下是一些改进:
- NUMA-aware 调度:CFS 被优化以适应 NUMA 架构,能够根据内存的物理位置智能地调度任务,减少跨节点内存访问的开销。
- 多队列调度器:对多队列调度器进行了改进,进一步提高了多核系统的调度效率。
- 进程间隔和任务亲和性增强:调度器更加注重进程的亲和性,进一步优化了跨 CPU 迁移时的性能。
8. Linux 5.x 和 6.x 系列
在 Linux 5.x 和 6.x 版本中,调度器继续改进,重点是:
- 调度器的可调性增强:CFS 和实时调度器的参数可调性增强,允许用户根据特定的应用场景进行更加细致的调整。
- 更智能的负载均衡算法:进一步优化了多核和多线程环境下的负载均衡,尤其是对大规模并行计算的支持。
- 优化虚拟化支持:Linux 的调度器对虚拟机环境进行了优化,能够更好地处理虚拟机内的调度需求。
- 优化 I/O 性能:针对 I/O 密集型任务,调度器与 I/O 子系统的协同工作更加高效,减少了 I/O 阻塞对系统性能的影响。
总结
Linux 调度器经历了多次重要的改进,从最初的简单轮转调度,到引入 O(1) 调度器,再到革命性的完全公平调度器(CFS),每一代调度器都朝着更高效、更公平的目标前进。随着硬件架构的不断发展,特别是在多核处理器、NUMA 系统和虚拟化环境中的广泛应用,Linux 调度器的演变仍然在继续,以适应日益复杂的计算需求。
本文主要对新一代调度器CFS进行学习:
二、 调度器CFS
2.1、 楼梯调度算法staircase scheduler
楼梯算法(SD)在思路上和O(1)算法有很大不同,它抛弃了动态优先级的概念。而采用了一种完全公平的思路。前任算法的主要复杂性来自动态优先级的计算,调度器根据平均睡眠时间和一些很难理解的经验公式来修正进程的优先级以及区分交互式进程。这样的代码很难阅读和维护。楼梯算法思路简单,但是实验证明它对应交互式进程的响应比其前任更好,而且极大地简化了代码。
和O(1)算法一样,楼梯算法也同样为每一个优先级维护一个进程列表,并将这些列表组织在active数组中。当选取下一个被调度进程时,SD算法也同样从active数组中直接读取。与O(1)算法不同在于,当进程用完了自己的时间片后,并不是被移到expire数组中。而是被加入active数组的低一优先级列表中,即将其降低一个级别。不过请注意这里只是将该任务插入低一级优先级任务列表中,任务本身的优先级并没有改变。当时间片再次用完,任务被再次放入更低一级优先级任务队列中。就象一部楼梯,任务每次用完了自己的时间片之后就下一级楼梯。任务下到最低一级楼梯时,如果时间片再次用完,它会回到初始优先级的下一级任务队列中。比如某进程的优先级为1,当它到达最后一级台阶140后,再次用完时间片时将回到优先级为2的任务队列中,即第二级台阶。不过此时分配给该任务的time_slice将变成原来的2倍。比如原来该任务的时间片time_slice为10ms,则现在变成了20ms。基本的原则是,当任务下到楼梯底部时,再次用完时间片就回到上次下楼梯的起点的下一级台阶。并给予该任务相同于其最初分配的时间片。总结如下:设任务本身优先级为P,当它从第N级台阶开始下楼梯并到达底部后,将回到第N+1级台阶。并且赋予该任务N+1倍的时间片。
以上描述的是普通进程的调度算法,实时进程还是采用原来的调度策略,即FIFO或者Round Robin。
楼梯算法能避免进程饥饿现象,高优先级的进程会最终和低优先级的进程竞争,使得低优先级进程最终获得执行机会。对于交互式应用,当进入睡眠状态时,与它同等优先级的其他进程将一步一步地走下楼梯,进入低优先级进程队列。当该交互式进程再次唤醒后,它还留在高处的楼梯台阶上,从而能更快地被调度器选中,加速了响应时间。
楼梯算法的优点:从实现角度看,SD基本上还是沿用了O(1)的整体框架,只是删除了O(1)调度器中动态修改优先级的复杂代码;还淘汰了expire数组,从而简化了代码。它最重要的意义在于证明了完全公平这个思想的可行性。
2.2、 RSDL(Rotating Staircase Deadline Scheduler)
RSDL(Rotating Staircase Deadline Scheduler,旋转楼梯截止时间调度器)是一种实时调度算法,旨在高效地管理具有硬实时要求的任务。RSDL 结合了 楼梯调度(Staircase Scheduling) 和 截止时间调度 的概念,特别适用于对时间要求严格的系统,比如多核处理器或多任务系统中的实时任务调度。
核心的思想还是”完全公平”。没有复杂的动态优先级调整策略。RSDL重新引入了expire数组。它为每一个优先级都分配了一个 “组时间配额”,记为Tg;同一优先级的每个进程都拥有同样的”优先级时间配额”,用Tp表示。当进程用完了自身的Tp时,就下降到下一优先级进程组中。这个过程和SD相同,在RSDL中这个过程叫做minor rotation(次轮询)。请注意Tp不等于进程的时间片,而是小于进程的时间片。下图表示了minor rotation。进程从priority1的队列中一步一步下到priority140之后回到priority2的队列中,这个过程如下图左边所示,然后从priority 2开始再次一步一步下楼,到底后再次反弹到priority3队列中,如下图所示。

在SD算法中,处于楼梯底部的低优先级进程必须等待所有的高优先级进程执行完才能获得CPU。因此低优先级进程的等待时间无法确定。RSDL中,当高优先级进程组用完了它们的Tg(即组时间配额)时,无论该组中是否还有进程Tp尚未用完,所有属于该组的进程都被强制降低到下一优先级进程组中。这样低优先级任务就可以在一个可以预计的未来得到调度。从而改善了调度的公平性。这就是RSDL中Deadline代表的含义。
进程用完了自己的时间片time_slice时(下图中T2),将放入expire数组指向的对应初始优先级队列中(priority 1)。
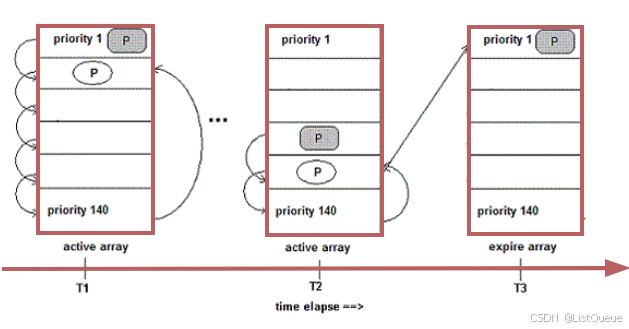
当active数组为空,或者所有的进程都降低到最低优先级时就会触发主轮询major rotation。Major rotation交换active数组和expire数组,所有进程都恢复到初始状态,再一次从新开始minor rotation的过程。
RSDL对交互式进程的支持:和SD同样的道理,交互式进程在睡眠时间时,它所有的竞争者都因为minor rotation而降到了低优先级进程队列中。当它重新进入RUNNING状态时,就获得了相对较高的优先级,从而能被迅速响应。
2.3、 完全公平的调度器CFS
CFS是最终被内核采纳的调度器。它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。
CFS百分之八十的工作可以用一句话概括:CFS在真实的硬件上模拟了完全理想的多任务处理器。在真空的硬件上,同一时刻我们只能运行单个进程,因此当一个进程占用CPU时,其它进程就必须等待,这就产生了不公平。但是在“完全理想的多任务处理器 “下,每个进程都能同时获得CPU的执行时间,即并行地每个进程占1/nr_running的时间。例如当系统中有两个进程时,CPU的计算时间被分成两份,每个进程获得50%。假设runqueue中有n个进程,当前进程运行了10ms。在“完全理想的多任务处理器”中,10ms应该平分给n个进程(不考虑各个进程的nice值),因此当前进程应得的时间是(10/n)ms,但是它却运行了10ms。所以CFS将惩罚当前进程,使其它进程能够在下次调度时尽可能取代当前进程。最终实现所有进程的公平调度。
与之前的Linux调度器不同,CFS没有将任务维护在链表式的运行队列中,它抛弃了active/expire数组,而是对每个CPU维护一个以时间为顺序的红黑树。
该树方法能够良好运行的原因在于:
-
红黑树可以始终保持平衡,这意味着树上没有路径比任何其他路径长两倍以上。
-
由于红黑树是二叉树,查找操作的时间复杂度为O(log n)。但是除了最左侧查找以外,很难执行其他查找,并且最左侧的节点指针始终被缓存。
-
对于大多数操作(插入、删除、查找等),红黑树的执行时间为O(log n),而以前的调度程序通过具有固定优先级的优先级数组使用 O(1)。O(log n) 行为具有可测量的延迟,但是对于较大的任务数无关紧要。Molnar在尝试这种树方法时,首先对这一点进行了测试。
-
红黑树可通过内部存储实现,即不需要使用外部分配即可对数据结构进行维护。
要实现平衡,CFS使用”虚拟运行时”表示某个任务的时间量。任务的虚拟运行时越小,意味着任务被允许访问服务器的时间越短,其对处理器的需求越高。CFS还包含睡眠公平概念以便确保那些目前没有运行的任务(例如,等待 I/O)在其最终需要时获得相当份额的处理器。
在 Linux 的 CFS (Completely Fair Scheduler) 中,pick_next_task() 是调度器的核心函数之一,它负责选择下一个要运行的任务。CFS 调度器的设计理念是尽量公平地分配 CPU 时间,确保每个进程根据它的虚拟运行时间(vruntime)获得相对公平的 CPU 时间。
pick_next_task() 的实现
在 CFS 中,pick_next_task() 的主要目的是从就绪队列中选择下一个要执行的任务。CFS 使用一个基于红黑树的数据结构来存储就绪队列,并以虚拟运行时间(vruntime)作为任务排序的关键。任务的 vruntime 会随着任务的运行不断更新,并且会决定它在调度队列中的顺序。
1. 虚拟运行时间(vruntime)
vruntime 是 CFS 中一个非常重要的概念。它表示每个任务运行的“虚拟时间”,并根据任务的权重来调整。权重较高的任务(如具有较高优先级的任务)会更频繁地被调度,虚拟运行时间的增长速度会相对较慢,而权重较低的任务(如具有较低优先级的任务)会较慢地获得 CPU 时间。
vruntime 的变化方式如下:
- 任务每执行一段时间,它的
vruntime会增加。 - 每个任务的
vruntime增长速度是与任务的权重(load_weight)成反比的。权重越大,vruntime增长越慢,意味着这个任务会比低权重的任务更频繁地被调度。
2. 就绪队列的管理
CFS 使用红黑树来管理就绪队列,红黑树是一个自平衡的二叉查找树。在这个树中,每个节点对应一个就绪任务,节点按照任务的 vruntime 值进行排序。每当一个任务的 vruntime 改变时,调度器会通过红黑树来重新排列任务的位置。
3. pick_next_task() 的流程
pick_next_task() 主要完成从 CFS 的就绪队列中选择下一个任务的工作。下面是 pick_next_task() 的基本实现流程:
-
查找最小的
vruntime: 调度器会查找就绪队列中vruntime最小的任务,即虚拟运行时间最小的任务。由于任务是按照vruntime排序的,因此树的最左边(最小vruntime)的节点对应的就是下一个要执行的任务。 -
从红黑树中提取任务: 一旦找到最小
vruntime的任务,调度器会将该任务从红黑树中移除,并准备将其调度到 CPU 上执行。 -
更新任务的运行状态: 一旦选中了任务,CFS 会更新其状态,将该任务标记为运行状态,并将其从就绪队列中移除。
-
插入新任务: 如果当前的任务时间片用完,或者出现了新的就绪任务,那么
pick_next_task()会将新的任务加入红黑树,并且会根据它的vruntime来决定它在树中的位置。
下图是一个红黑树的例子。
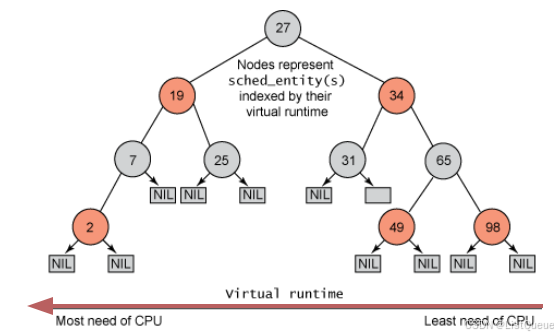
所有可运行的任务通过不断地插入操作最终都存储在以时间为顺序的红黑树中(由 sched_entity 对象表示),对处理器需求最多的任务(最低虚拟运行时)存储在树的左侧,处理器需求最少的任务(最高虚拟运行时)存储在树的右侧。 为了公平,CFS调度器会选择红黑树最左边的叶子节点作为下一个将获得cpu的任务。这样,树左侧的进程就被给予时间运行了。
在CFS中,tick中断首先更新调度信息。然后调整当前进程在红黑树中的位置。调整完成后如果发现当前进程不再是最左边的叶子,就标记need_resched标志,中断返回时就会调用scheduler()完成进程切换。否则当前进程继续占用CPU。从这里可以看到 CFS抛弃了传统的时间片概念。Tick中断只需更新红黑树,以前的所有调度器都在tick中断中递减时间片,当时间片或者配额被用完时才触发优先级调整并重新调度。
理解CFS的关键就是了解红黑树键值的计算方法。该键值由三个因子计算而得:一是进程已经占用的CPU时间;二是当前进程的nice值;三是当前的cpu负载。进程已经占用的CPU时间对键值的影响最大,其实很大程度上我们在理解CFS时可以简单地认为键值就等于进程已占用的 CPU时间。因此该值越大,键值越大,从而使得当前进程向红黑树的右侧移动。另外CFS规定,nice值为1的进程比nice值为0的进程多获得10%的 CPU时间。在计算键值时也考虑到这个因素,因此nice值越大,键值也越大。
CFS为每个进程都维护两个重要变量:fair_clock和wait_runtime。这里我们将为每个进程维护的变量称为进程级变量,为每个CPU维护的称作CPU级变量,为每个runqueue维护的称为runqueue级变量。进程插入红黑树的键值即为fair_clock – wait_runtime。其中fair_clock从其字面含义上讲就是一个进程应获得的CPU时间,即等于进程已占用的CPU时间除以当前 runqueue中的进程总数;wait_runtime是进程的等待时间。它们的差值代表了一个进程的公平程度。该值越大,代表当前进程相对于其它进程越不公平。对于交互式任务,wait_runtime长时间得不到更新,因此它能拥有更高的红黑树键值,更靠近红黑树的左边。从而得到快速响应。
红黑树是平衡树,调度器每次总最左边读出一个叶子节点,该读取操作的时间复杂度是O(LogN)O(LogN)。
为了支持实时进程,CFS提供了调度器模块管理器。各种不同的调度器算法都可以作为一个模块注册到该管理器中。不同的进程可以选择使用不同的调度器模块。2.6.23中,CFS实现了两个调度算法,CFS算法模块和实时调度模块。对应实时进程,将使用实时调度模块。对应普通进程则使用CFS算法。CFS 调度模块(在 kernel/sched_fair.c 中实现)用于以下调度策略:SCHED_NORMAL、SCHED_BATCH 和 SCHED_IDLE。对于 SCHED_RR 和 SCHED_FIFO 策略,将使用实时调度模块(该模块在 kernel/sched_rt.c 中实现)。
CFS组调度是另一种为调度带来公平性的方式,尤其是在处理产生很多其他任务的任务时。 假设一个产生了很多任务的服务器要并行化进入的连接(HTTP 服务器的典型架构)。不是所有任务都会被统一公平对待, CFS 引入了组来处理这种行为。产生任务的服务器进程在整个组中(在一个层次结构中)共享它们的虚拟运行时,而单个任务维持其自己独立的虚拟运行时。这样单个任务会收到与组大致相同的调度时间。您会发现 /proc 接口用于管理进程层次结构,让您对组的形成方式有完全的控制。使用此配置,您可以跨用户、跨进程或其变体分配公平性。
考虑一个两用户示例,用户 A 和用户 B 在一台机器上运行作业。用户 A 只有两个作业正在运行,而用户 B 正在运行 48 个作业。组调度使 CFS 能够对用户 A 和用户 B 进行公平调度,而不是对系统中运行的 50 个作业进行公平调度。每个用户各拥有 50% 的 CPU 使用。用户 B 使用自己 50% 的 CPU 分配运行他的 48 个作业,而不会占用属于用户 A 的另外 50% 的 CPU 分配。
CFS(Completely Fair Scheduler)组调度是 Linux 内核在调度多个进程组(或称为 "cgroup")时的一种机制。它使得 CFS 调度器不仅关注单个任务的调度,也能够公平地管理多个任务组(如用户组、资源组等)之间的资源分配。
CFS 组调度背景
在传统的 CFS 调度器中,任务(task_struct)的调度是基于每个任务的虚拟运行时间(vruntime)来决定的。每个任务的 vruntime 是其已使用的 CPU 时间的一个抽象,调度器总是选择 vruntime 最小的任务进行执行。然而,当你有多个任务组时,你希望能够公平地分配 CPU 时间给这些任务组,而不是仅仅考虑单个任务的公平性。这就引出了 CFS 组调度。
CFS 组调度的目标是:当系统中有多个任务组时,如何将 CPU 时间在这些任务组之间公平地分配,而不是仅仅对每个单独的任务进行调度。通过 CFS 组调度,可以保证任务组间的资源分配更具公平性。
CFS 组调度的工作原理
在 CFS 组调度中,任务组是作为一种调度实体存在的,它们通常被组织成一个或多个 cgroup。这些 cgroup 中的任务会被调度器当作一个整体来调度,而不是单独对每个任务进行调度。每个 cgroup(调度组)都会有一个代表它的调度实体(sched_entity)。CFS 调度器会对这些调度实体进行管理,并在 cgroup 之间进行公平的 CPU 时间分配。
1. 任务组的调度实体
在 CFS 中,每个任务(task_struct)都有一个与之对应的调度实体(sched_entity)。任务组的调度实体则是该组中所有任务调度实体的集合。例如,CFS 通过红黑树来管理调度实体,每个任务的 sched_entity 都有一个虚拟运行时间(vruntime)。
任务组调度时,每个组都会有一个 vruntime,表示该组已消耗的 CPU 时间。CFS 会根据任务组的 vruntime 来决定哪个组获得 CPU 时间。
2. CFS 组调度的调度器入口
CFS 组调度的调度器入口函数与普通的 CFS 调度类似。关键点在于,它首先会选择哪个任务组(而不是哪个单独任务)应该被调度执行。
例如,CFS 调度器会调用一个函数来获取下一个要执行的任务组:
struct sched_entity *pick_next_task_group(struct rq *rq)
{
struct sched_entity *next = NULL;
struct cgroup_sched_entity *cse;
/* 遍历 cgroup 列表,找到 vruntime 最小的任务组 */
next = pick_next_task_from_cgroups(rq);
return next;
}
此函数的作用是根据每个任务组的 vruntime 值来选择下一个任务组。任务组的调度策略和任务的调度策略相似,但调度单位变成了任务组,而不是单个任务。
3. CFS 组调度的虚拟运行时间(vruntime)
与传统的 CFS 调度类似,CFS 组调度也依赖于 vruntime 来进行公平性管理。每个任务组都有一个虚拟运行时间,它会随着该组中任务的 CPU 时间消耗而增加。
为了让组调度尽可能公平,CFS 组调度会对每个任务组的 vruntime 进行调整,使得每个组的调度优先级与该组的实际 CPU 使用情况成比例。CFS 会确保在所有任务组之间公平地分配 CPU 时间,以防止某些任务组因资源过度消耗而导致其他任务组长时间得不到调度。
4. 任务组的 sched_entity
每个任务组都有一个 sched_entity 结构,表示该组的调度信息。任务组中的所有任务共享这个调度实体,并根据 sched_entity 中的 vruntime 来进行调度。每个任务(task_struct)都拥有一个指向其父调度实体的指针。
例如,sched_entity 中的字段包括:
struct sched_entity {
struct rb_node run_node; // 红黑树节点,用于维护就绪队列
u64 vruntime; // 虚拟运行时间
u64 load_weight; // 负载权重,用于调度决策
struct cgroup *cgroup; // 对应的 cgroup
};
其中,vruntime 反映了组内任务的虚拟运行时间,load_weight 反映了该任务组的负载权重。权重越大,表示该任务组对 CPU 的需求越大。
5. 公平性与优先级
CFS 组调度的公平性依赖于各个任务组的 vruntime。每个任务组的调度优先级是由它的 vruntime 决定的。CFS 调度器会选择 vruntime 最小的任务组进行调度,而每个任务组的 vruntime 是根据它下属任务的 CPU 使用情况动态调整的。
为了防止某些任务组长时间不被调度,CFS 组调度还会确保组之间的调度是平衡的。如果某个组的 vruntime 长时间偏大,CFS 会通过增加其他组的权重或者其他机制来重新调整调度优先级。
CFS 组调度的调度流程
CFS 组调度的具体流程类似于传统 CFS 调度的流程,但增加了任务组层级的处理:
-
任务提交和 cgroup 管理: 当一个任务进入系统并被调度时,调度器会将它加入到适当的 cgroup 中。每个 cgroup 代表一个任务组。
-
任务组的虚拟运行时间更新: 任务在运行时,其虚拟运行时间(
vruntime)会被更新。任务组的vruntime会根据其组内任务的vruntime综合计算而来。 -
任务组选择: 在进行调度时,CFS 会选择
vruntime最小的任务组进行调度。如果一个任务组的所有任务都已完成,它会被从调度队列中移除。 -
任务调度: CFS 调度器会在选定的任务组中选择一个具体的任务进行调度,通常是选择
vruntime最小的那个任务。
CFS 组调度的优势
-
资源公平性:通过任务组调度,CFS 可以更好地确保各个 cgroup 之间的 CPU 资源公平分配,避免单个任务占用过多的 CPU 时间而导致其他任务组饥饿。
-
支持复杂的资源管理:在现代数据中心和容器化环境中,任务常常被组织到多个任务组中,CFS 组调度可以有效地为每个 cgroup 分配 CPU 时间,支持多级资源管理策略。
-
灵活性:通过动态调整各个任务组的调度优先级,CFS 可以更灵活地应对系统负载变化和任务需求的不同。

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









