







本案例介绍如何在MNIST手写数字分类场景中,使用名为MistNet的聚合算法训练联邦学习作业。数据分散在不同的地方(如边缘节点、摄像头等),由于数据隐私和带宽的原因,无法在服务器上聚合。因此,我们不能将所有数据都用于训练。在某些情况下,边缘节点的计算资源有限,甚至没有训练能力。边缘无法从训练过程中获取更新的权重。因此,传统算法(例如,联合平均算法)通常聚合由不同边缘客户端训练的更新权重,在这种情况下无法工作。MistNet 被提议解决这个问题。
MistNet 将 DNN 模型分为两部分,边缘侧的轻量级特征提取器用于从原始数据生成有意义的特征,以及包含云中最多模型层的分类器,用于针对特定任务进行迭代训练。MistNet 实现了可接受的模型效用,同时大大减少了已发布的中间功能造成的隐私泄露。
物体检测实验
假设有两个边缘节点和一个云节点。由于隐私问题,边缘节点上的数据无法迁移到云中。基于此场景,我们将演示mnist示例
安装Sedna
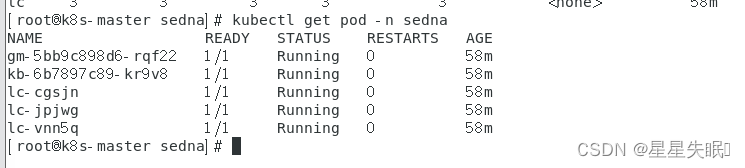
准备数据集
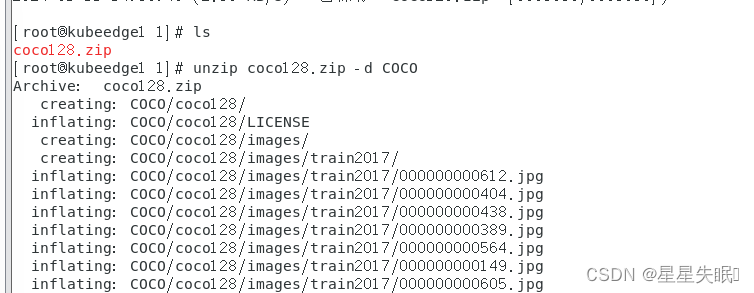
Create data interface for EDGE1_NODE.
mkdir -p /data/1
cd /data/1
wget https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
unzip coco128.zip -d COCO
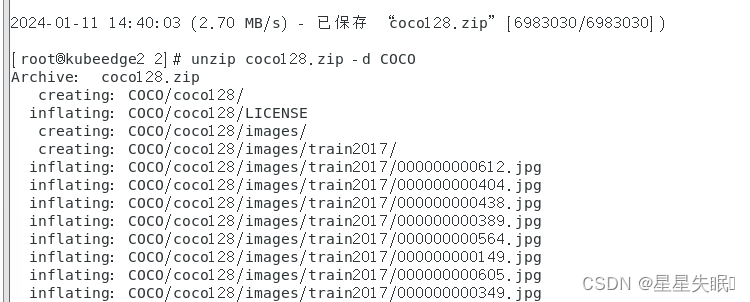
Create data interface for EDGE2_NODE.
准备镜像
此示例使用以下映像:
聚合工作器:kubeedge/sedna-example-federated-learnin
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











