



相关资料以及下载
代码地址:https://github.com/ruotianluo/pytorch-faster-rcnn.git
原理参考:https://blog.youkuaiyun.com/zm147451753/article/details/88218619
代码编译和运行
代码使用方法,暂时没找到win系统下的方法,为此,我安装了unbuntu,还是蛮好用的。
代码的编译运行准备https://blog.youkuaiyun.com/xzy5210123/article/details/81530993
偷懒了一下,直接在/tools/trainval_net.py里面改了些配置,使得直接可以运行改文件作为调试
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument(
'--cfg',
dest='cfg_file',
help='optional config file',
default='/media/5D2B2DF318675C02/pytorch-faster-rcnn/experiments/cfgs/vgg16.yml',
type=str)
parser.add_argument(
'--weight',
dest='weight',
help='initialize with pretrained model weights',
default='/media/5D2B2DF318675C02/pytorch-faster-rcnn/data/imagenet_weights/vgg16_caffe.pth',
type=str)
parser.add_argument(
'--imdb',
dest='imdb_name',
help='dataset to train on',
default='voc_2007_trainval',
type=str)
parser.add_argument(
'--imdbval',
dest='imdbval_name',
help='dataset to validate on',
default='voc_2007_test',
type=str)
parser.add_argument(
'--iters',
dest='max_iters',
help='number of iterations to train',
default=70000,
type=int)
parser.add_argument(
'--tag', dest='tag', help='tag of the model', default=None, type=str)
parser.add_argument(
'--net',
dest='net',
help='vgg16, res50, res101, res152, mobile',
default='vgg16',
type=str)
parser.add_argument(
'--set',
dest='set_cfgs',
help='set config keys',
default=None,
nargs=argparse.REMAINDER)
# if len(sys.argv) == 1:
# parser.print_help()
# sys.exit(1)
args = parser.parse_args()
return args下一步开始解释代码
整体逻辑
流程如下图

图1:整体架构
图1展示了Python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成foreground anchors与bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
第一步:卷积层
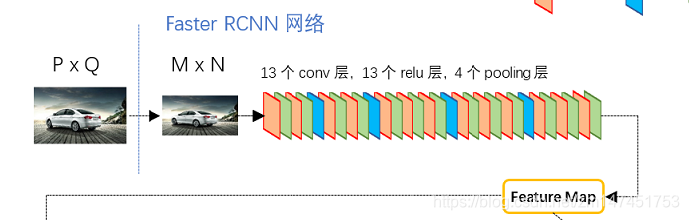
图2:vgg16架构
使用vgg16对数据进行一系列卷积操作。
相关说明:
卷积层部分共有13个conv层,13个relu层,4个pooling层。在Conv layers中:
- 所有的conv层都是:kernel_size=3,pad=1,导致经过变换的图片大小不变
- 所有的pooling层都是:kernel_size=2,stride=2 导致经过变换的图片大小减半
所以经过4个pooling层,图片大小为原始大小的1/16..
第二步:区域提取(Region Proposal Networks(RPN))
构造anchors
1.使用 anchor_scales=(8, 16, 32)和anchor_ratios=(0.5, 1, 2))以及16来构造一个矩阵
经过卷积层后的每一个点对应于16*16的区域,anchor_ratios为高宽比,anchor_scales为长宽缩放比例,所以对于一个点,对应区域为[0,0,15,15],w=h=16,为了实现设定的高宽比,h1=anchor_ratios*w1, 且h1*w1=h*w,得到w1=sqrt(h*w/anchor_ratios),h1=anchor_ratios*sqrt(h*w/anchor_ratios),再对w1,h2使用anchor_scales,最后得到矩阵
anchors = [[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]] 即在原点的点对应于9个box,每一行表示[x起点,y起点,x终点,y终点]
最后对每一个点进行偏移,得到所有的box
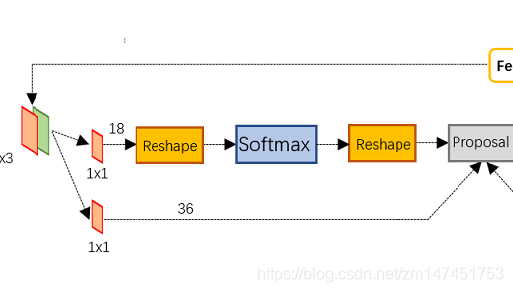
为什么要reshape
在softmax中,需要先reshape再softmax,这个通过 的计算,得到的shape为[1,18,h(37),w(50)],其中18是9*2(9个box,2是前景还是背景各自的数值)。需要reshape为[1,2,9*h(333), w(50)],然后进行softmax再reshape回[1,18,h(37),w(50)],最后在把1维和3维(w(50))的数据交换得到结果[1,h(37),w(50),18]
的计算,得到的shape为[1,18,h(37),w(50)],其中18是9*2(9个box,2是前景还是背景各自的数值)。需要reshape为[1,2,9*h(333), w(50)],然后进行softmax再reshape回[1,18,h(37),w(50)],最后在把1维和3维(w(50))的数据交换得到结果[1,h(37),w(50),18]
第三步 挑选box
- 生成anchors,利用[dx(A),dy(A),dw(A),dh(A)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
- 利用im_info将fg anchors从MxN尺度映射回PxQ原图,判断fg anchors是否大范围超过边界,剔除严重超出边界fg anchors。
- 进行nms(nonmaximum suppression,非极大值抑制)
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
之后输出proposal=[x1, y1, x2, y2],注意,由于在第三步中将anchors映射回原图判断是否超出边界,所以这里输出的proposal是对应MxN输入图像尺度的,这点在后续网络中有用。另外我认为,严格意义上的检测应该到此就结束了,后续部分应该属于识别了~
第四步 RoI
1、为何需要RoI
- 从图像中crop一部分传入网络
- 将图像warp成需要的大小后传入网络

图13 crop与warp破坏图像原有结构信息
两种办法的示意图如图13,可以看到无论采取那种办法都不好,要么crop后破坏了图像的完整结构,要么warp破坏了图像原始形状信息。回忆RPN网络生成的proposals的方法:对foreground anchors进行bound box regression,那么这样获得的proposals也是大小形状各不相同,即也存在上述问题。所以Faster RCNN中提出了RoI Pooling解决这个问题
2。怎么搞?
RoI Pooling layer forward过程:在之前有明确提到:proposal=[x1, y1, x2, y2]是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature maps尺度(这里来回多次映射,是有点绕);之后将每个proposal水平和竖直都分为7份,对每一份都进行max pooling处理。这样处理后,即使大小不同的proposal,输出结果都是7x7大小,实现了fixed-length output(固定长度输出)。

第五步 分类
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。Classification部分网络结构如图15。

从PoI Pooling获取到7x7=49大小的proposal feature maps后,送入后续网络,可以看到做了如下2件事:
- 通过全连接和softmax对proposals进行分类,这实际上已经是识别的范畴了
- 再次对proposals进行bounding box regression,获取更高精度的rect box

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









