





一、概述
企业应用集成大语言模型(LLM)落地的两大痛点:
- 知识局限性:LLM依赖静态训练数据,无法覆盖实时更新或垂直领域的知识;
- 幻觉:当LLM遇到训练数据外的提问时,可能生成看似合理但错误的内容。
用最低的成本解决以上问题,需要使用 RAG 技术,它是一种结合信息检索技术与 LLM 的框架,通过从外部 知识库 动态检索相关上下文信息,并将其作为 Prompt 融入生成过程,从而提升模型回答的准确性;
本文将以AI智能搜索为场景,基于 Spring AI 与 RAG 技术结合,通过构建实时知识库增强大语言模型能力,实现企业级智能搜索场景与个性化推荐,攻克 LLM 知识滞后与生成幻觉两大核心痛点。
关于 Spring AI 与 DeepSeek 的集成,以及 API-KEY 的申请等内容,可参考文章《Spring AI与DeepSeek实战一:快速打造智能对话应用》
二、RAG数据库选择
构建知识库的数据库一般有以下有两种选择:
| 维度 | 向量数据库 | 知识图谱 |
|---|---|---|
| 数据结构 | 非结构化数据(文本/图像向量) | 结构化关系网络(实体-关系-实体) |
| 查询类型 | 语义相似度检索 | 多跳关系推理 |
| 典型场景 | 文档模糊匹配、图像检索 | 供应链追溯、金融风控 |
| 性能指标 | QPS>5000 | 复杂查询响应时间>2s |
| 开发成本 | 低(API即用) | 高(需构建本体模型) |
搜索推荐场景更适合选择 向量数据库
三、向量模型
向量模型是实现 RAG 的核心组件之一,用于将非结构化数据(如文本、图像、音频)转换为 高维向量(Embedding)的机器学习模型。这些向量能够捕捉数据的语义或结构信息,使计算机能通过数学运算处理复杂关系。
向量数据库是专门存储、索引和检索高维向量的数据库系统
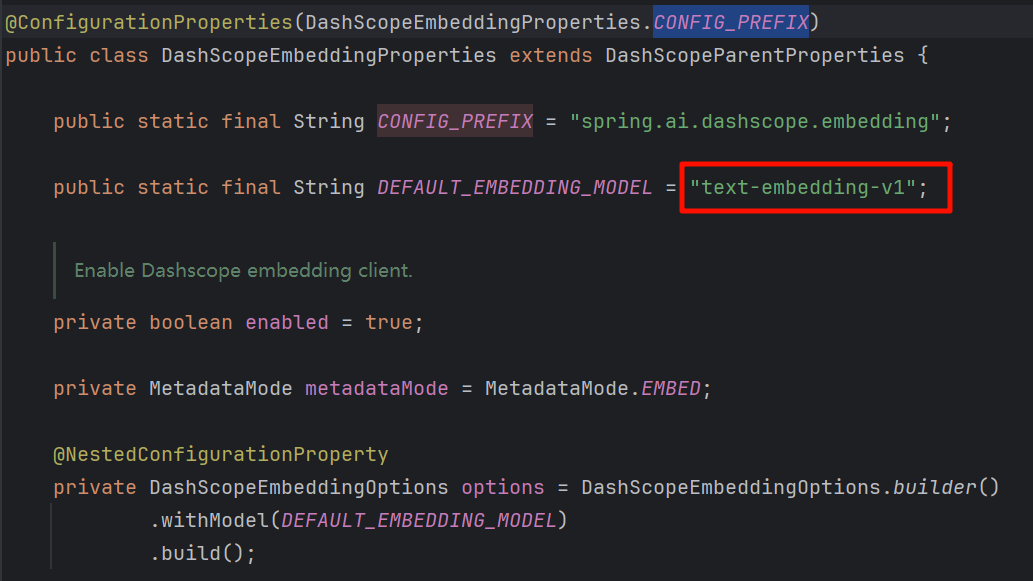
spring-ai-alibaba-starter 默认的向量模型为 text-embedding-v1
可以通过 spring.ai.dashscope.embedding.options.model 进行修改。
四、核心代码
4.1. 构建向量数据
创建 resources/rag/data-resources.txt 文件,内容如下:
1. {
"type":"api","name":"测试api服务01","topic":"综合政务","industry":"采矿业","remark":"获取采矿明细的API服务"}
2. {
"type":"api","name":"新能源车类型" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









