







1、SparkSQL是干嘛的?为什么会有SparkSQL?
对标hive 简化开发 和学习成本
![]()
2、SparkSQL底层有什么编程抽象?
DataFrame 和DataSet
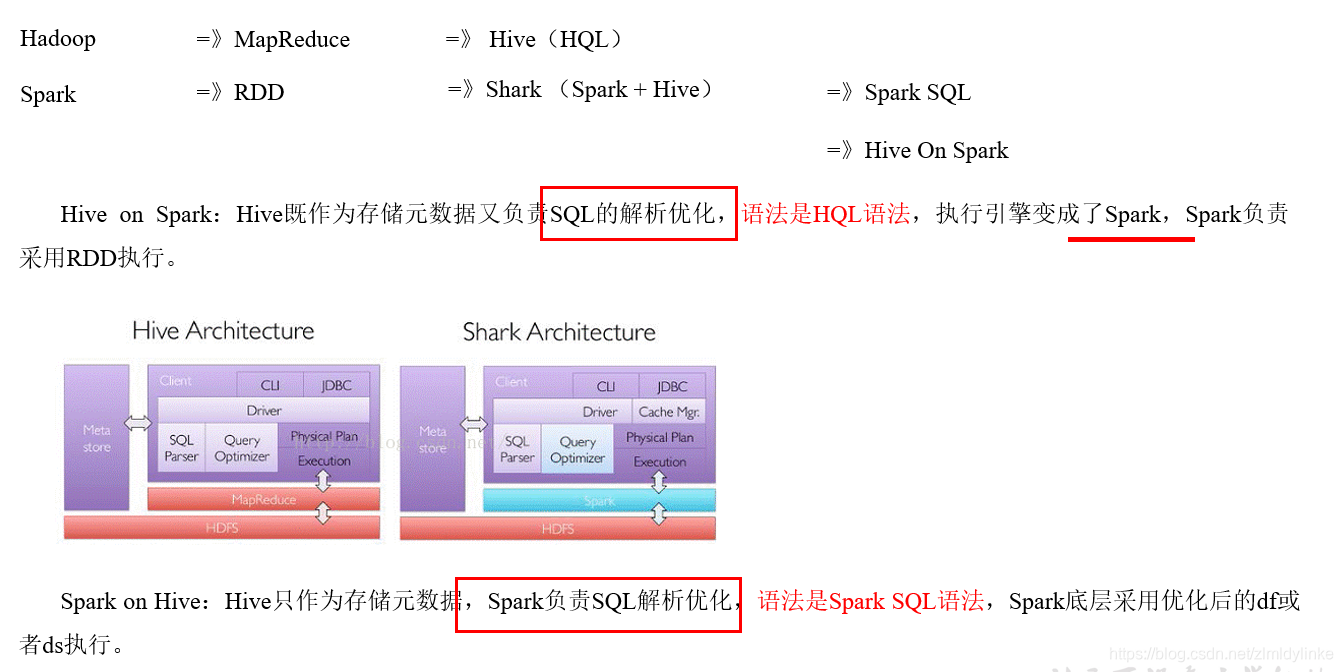
3、hive on spark 和 spark on hive区别?我们学的SparkSQL是什么?
语法不一样 谁负责SQL的解析优化
sparkSQL是 spark on hive 玩的spark
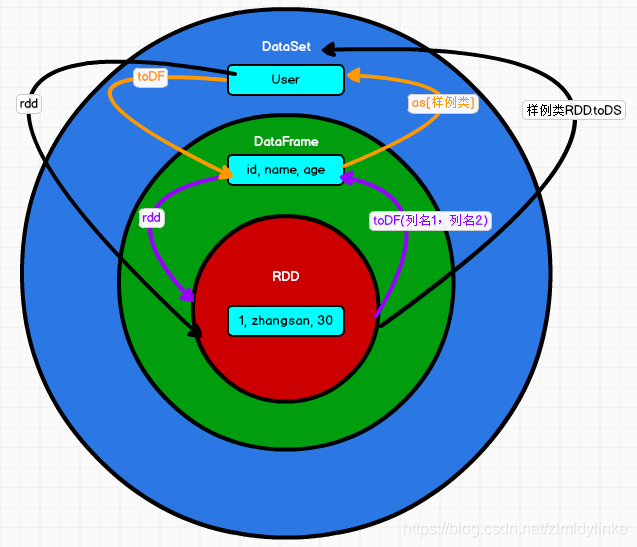
4、DF、DS、RDD三者之间的区别和联系?
只关心数据 =》 关心数据+数据结构(元数据) =》 关心数据+数据结构+记录一行数据的类型(强类型) 把每行数据当作一个对象
历史 1.0 1.3 1.6
DF是DS的一个特例 DataSet[Row]
![]()

5、DF、DS、RDD三者如何转换?(画图说明)
涉及转换 要有个 隐式转换
6、SparkSQL中有两种什么语法?简述这两种语法的区别和联系。
SQL风格语法 DSL风格语法
都是类sql语句 DSL不需要创建临时表
DSL 更 像函数方法的调用 把sql语句给拆分了


------------------------------上机---------------------------
7、SparkSQL中自定义UDAF实现求平均年龄。
关键是buff的属性
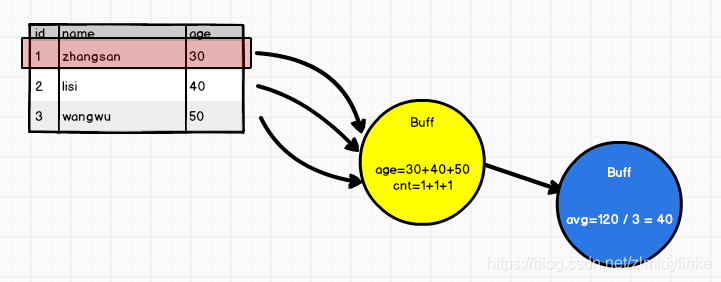
自定义 Aggregator 类继承 3个泛型(in out buff) 6个方法 (初始化+2个序列化)(分区内 分区间 聚合)
case class buff(var total:Long,var count:Long)
/*
自定义聚合函数类:计算年龄的平均值
1. 继承org.apache.spark.sql.expressions.Aggregator, 定义泛型
IN : 输入的数据类型 Long
BUF : 缓冲区的数据类型 Buff
OUT : 输出的数据类型 double
2. 重写方法(6)
*/
class myavg() extends Aggregator[Long,buff,Double]{
// 初始化缓冲区
override def zero: buff = {
buff(0L,0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: buff, in: Long): buff = {
buff.total = buff.total + in
buff.count = buff.count + 1
buff
}
// 多个缓冲区数据合并
override def merge(buff1: buff, buff2: buff): buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
// 完成聚合操作,获取最终结果
override def finish(buff: buff): Double = {
buff.total.toDouble / buff.count
}
// SparkSQL对传递的对象的序列化操作(编码)
// 自定义类型就是product 自带类型根据类型选择
override def bufferEncoder: Encoder[buff] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}主方法调用
// 5 注册UDAF
spark.udf.register("myAvg", functions.udaf(new MyAvgUDAF()))
// 6 调用自定义UDAF函数
spark.sql("select myAvg(age) from user").show()

















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









