







 本文介绍了一种利用模拟退火算法优化物理服务器上虚拟机部署的方法,旨在提高服务器资源利用率。通过引入随机性避免局部最优解,实现全局最优的虚拟机分布。
本文介绍了一种利用模拟退火算法优化物理服务器上虚拟机部署的方法,旨在提高服务器资源利用率。通过引入随机性避免局部最优解,实现全局最优的虚拟机分布。
模拟退火算法:物理服务器分配虚拟机Python实现
原理:
摘自模拟退火算法优快云博客
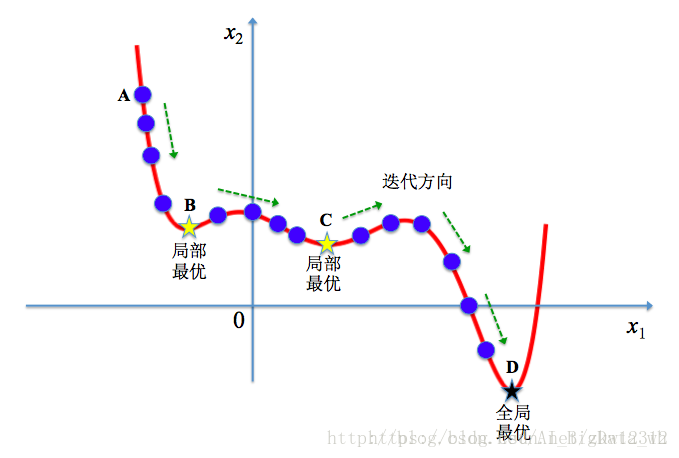
模拟退火其实也是一种贪心算法,但是它的搜索过程引入了随机因素。在迭代更新可行解时,以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。以下图为例,假定初始解为左边蓝色点A,模拟退火算法会快速搜索到局部最优解B,但在搜索到局部最优解后,不是就此结束,而是会以一定的概率接受到左边的移动。也许经过几次这样的不是局部最优的移动后会到达全局最优点D,于是就跳出了局部最小值。
代码片段
具体实例代码片,是将物理服务器按内存MEM和CPU核数分配虚拟机,已实现最大程度的利用率。
通过这个例子记录起来。
# coding=utf-8
import copy
import random
import math
class Device:
def __init__(self, device_cpu, device_mem):
self.load = [] #物理服务器已存放虚拟机列表
self.total_mem=device_mem #物理服务器总内存
self.total_cpu=device_cpu #物理服务器总CPU
self.free_mem=device_mem #物理服务器剩余可用内存
self.free_cpu=device_cpu #物理服务器剩余可用CPU
def load_flavor(self, flavor):
if self.free_cpu >= flavor.cpu and self.free_mem >= flavor.mem:
self.load.append(flavor.name)
self.free_cpu = self.free_cpu - flavor.cpu
self.free_mem = self.free_mem - flavor.mem
return True
print 'load in'
return False
#获取服务器CPU使用率
def get_cpu_usage_rate(self):
return 1-self.free_cpu/float(self.total_cpu)
#获取服务器内存使用率
def get_mem_usage_rate(self):
return 1-self.free_mem/float(self.total_mem)
class Flavors:
def __init__(self, name, amount_cpu, amount_mem):
self.name = name
self.cpu = amount_cpu
self.mem = amount_mem
def put_flavors_to_servers(count_predict, dict_cpu_mem, server_cpu, server_mem, CPUorMEM):
list_flavors=[] #用于存放所有预测出来的flavor
for i in count_predict.keys():
for j in range(count_predict[i]):
list_flavors.append(dict_cpu_mem[i])
# 模拟退火算法找最优解
min_device=len(list_flavors)
res_device=[] #用于存放最好结果(服务器使用数量最少)
T = 100.0 #模拟退火初始温度
Tmin = 1.0 #模拟退火终止温度
r = 0.999 #温度下降系数
dice=[] #骰子,每次随机投掷,取vector前两个变量作为每次退火需要交换顺序的虚拟机
for i in range(len(list_flavors)):
dice.append(i)
while T>Tmin:
# 投掷骰子,如vector前两个数为3和9,则把list_flavors[3]和list_flavors[9]进行交换作为新的flavors顺序
random.shuffle(dice)
new_list_flavors=copy.deepcopy(list_flavors)
new_list_flavors[dice[0]], new_list_flavors[dice[1]] = new_list_flavors[dice[1]], new_list_flavors[dice[0]]
# 把上一步计算出来的虚拟机尝试加入到服务器中
# 先使用一个服务器用于放置虚拟机
list_devices=[]
firstdevice=Device(server_cpu, server_mem)
list_devices.append(firstdevice)
# 放置虚拟机主要逻辑
# 如果当前所有服务器都放不下虚拟机,就新建一个服务器用于存放
for i in range(len(new_list_flavors)):
for j in range(len(list_devices)):
if list_devices[j].load_flavor(new_list_flavors[i]):
break
if j == len(list_devices)-1:
newdevice=Device(server_cpu, server_mem)
newdevice.load_flavor(new_list_flavors[i])
list_devices.append(newdevice)
# 计算本次放置虚拟机耗费服务器评价分数(float型)
# 如果使用了N个服务器,则前N - 1个服务器贡献分数为1,第N个服务器分数为资源利用率
# 模拟退火就是得到取得分数最小的放置方式
device_num=0.0
# 对于题目关心CPU还是MEM,需要分开讨论,资源利用率计算方法不同
if CPUorMEM=='CPU':
device_num=len(list_devices)-1+list_devices[len(list_devices)-1].get_cpu_usage_rate()
else:
device_num=len(list_devices)-1+list_devices[len(list_devices)-1].get_mem_usage_rate()
# 如果分数更低,则保存结果
if device_num < min_device:
min_device = device_num
res_device = copy.deepcopy(list_devices)
list_flavors = copy.deepcopy(new_list_flavors)
# 如果分数更高,则以一定概率保存结果,防止优化陷入局部最优解
else:
if math.exp((min_device-device_num)/T) > random.random():
min_device=device_num
res_device = copy.deepcopy(list_devices)
list_flavors=copy.deepcopy(new_list_flavors)
T=r*T
print 'temporary is '+str(T)
del list_devices
del firstdevice
return res_device
def distribute_SA(count_predict, dict_input_cpu, dict_input_mem, cpu_device, mem_device,target):
dict_cpu_mem={} #name cpu mem 使用实例: dict_cpu_mem["flavor1"] = Flavors("flavor1", 1, 4)
for i in dict_input_cpu.keys():
dict_cpu_mem[i] = Flavors(i,dict_input_cpu[i],dict_input_mem[i])
# 服务器资源相关信息
server_cpu = cpu_device
server_mem = mem_device
CPUorMEM = target
# 调用模拟退火算法找到最优放置方法
servers = put_flavors_to_servers(count_predict, dict_cpu_mem, server_cpu, server_mem, CPUorMEM)
# 输出各个服务器里面分别放置了哪些虚拟机
print 'end'
return servers
















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









