







在开始 Go 语言并发编程之前,我们先简单地了解一些概念:
- 1、进程和线程:
- 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
- 线程是进程的一个执行实例,是 CPU 调度和分派的基本单位。
- 一个进程可以创建和撤销多个线程;同一个进程中的多个线程之间可以并发执行。
- 2、协程和线程:
- 协程,独立的栈空间,共享堆空间,调度由用户自己控制。
- 线程,在一个线程上可以跑多个协程,就是说协程是轻量级的线程。
- 3、并发和并行:
-
多线程程序在一个核心的 CPU 上运行,就是并发,并发主要由切换时间片来实现"同时"运行。

-
多线程程序在多个核心的 CPU 上运行,就是并行,并行是直接利用多核实现多线程的运行。
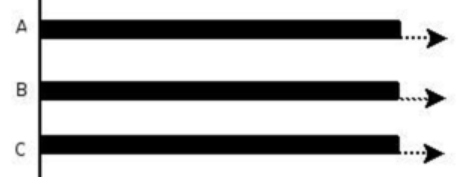
-
Go 语言中的并发其实就是能让某个函数独立于其他函数运行的能力。当一个函数创建为 goroutine 时,Go 会将其视为一个独立的工作单元,这个单元会被调度到可用的逻辑处理器上执行。
1.goroutine
golang runtime GPM 调度机制
调度器历史
(1)单进程时代
早期的操作系统,每个程序就是一个进程,只有当一个程序运行完毕才能进行下一个进程。当然这样的系统并不高效,我们都直到它的缺点:
- 只能一个一个任务处理,速度很慢;
- 如果有进程被阻塞在读磁盘文件的时候,CPU 就完全空闲,而后面的任务只能干等。

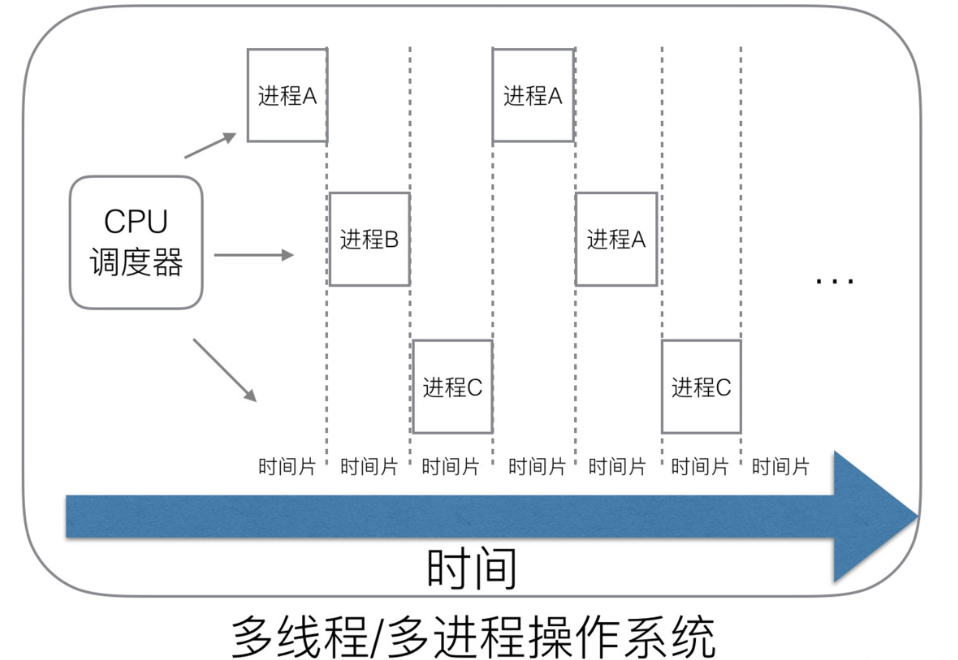
(2)多进程/线程时代
在多进程/线程的操作系统中,把每个任务都切成好几片,用一个 CPU 调度器去管理。这样做的好处是,当其中一个进程阻塞的时候,我们可以安排其他进行去执行,这样我们的 CPU ‘帕鲁’ 就能不间断地干活了。
但是,聪明的我们又发现问题了:每个进程的创建、切换、销毁等等也是占用时间的,要是任务特别多的话,CPU 就又要花很多时间在处理进程的调度,并没有在正在地干活。
(3)协程时代
线程其实分有“内核态线程”和“用户态线程”,而且一个“用户态线程”必须要绑定一个“内核态线程”。
话是这么说的,但实际上 CPU 并不真知道“用户态线程”,它只明白它要运行的是一个“内核态线程”,在 Linux 中就是一个进程控制模块,PCB。
于是,我们就想能不能让多个“用户态线程”绑定一个“内核态线程”呢?
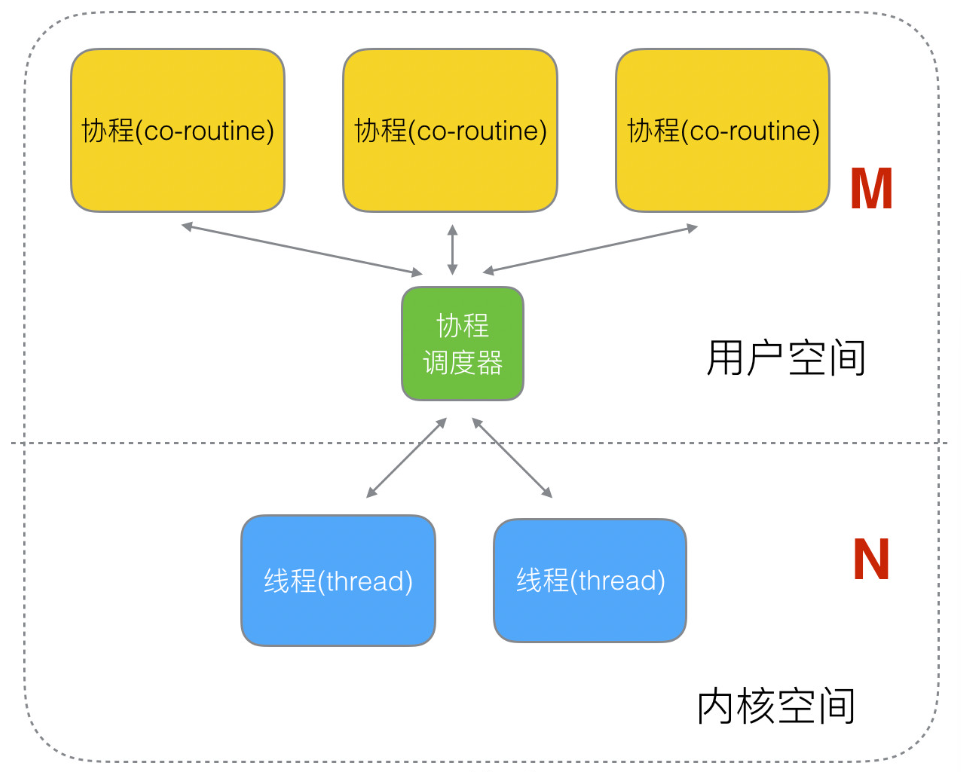
所以,我们就有了协程(co-routine),协程就是“用户态线程”,而线程(thread) 就是“内核态线程”。
协程通过协程调度器给到线程,而线程通过 CPU 调度器给到 CPU 去执行。协程的调度是协作式的,就是只有当一个协程选择放弃对 CPU 的控制时,才会被切换;而线程的调度是抢占式的,如果有一个线程比当前执行的线程优先级高,那么当前线程就会被掐断,要乖乖把 CPU 让给优先级高的线程去执行。
这里可以根据协程与线程的映射关系,可以分为:N对1、1对1、N对M。
N对1的情况:N个协程与1个线程绑定,好处是协程之间的切换不用切换到内核态去,缺点就是阻塞后其他协程只能等待。
1对1的情况:实际就像是线程的执行,完全没有协程的优势了。
N对M的情况:这种情况是比较好的,但是怎么去调度就是一个问题了。
Goroutine 调度器
现在,我们对协程、线程和调度器有一定的认识了。接下来,在学习 Go 的协程调度之前,我们先看看线程池。
线程池是这样设计的,我们把每个 任务G(通常是个函数,注意这不是协程)发布到任务队列中,然后让线程池中的 线程woker 去把任务从队列中取出执行,当然 线程woker 的调度是由操作系统去做的。
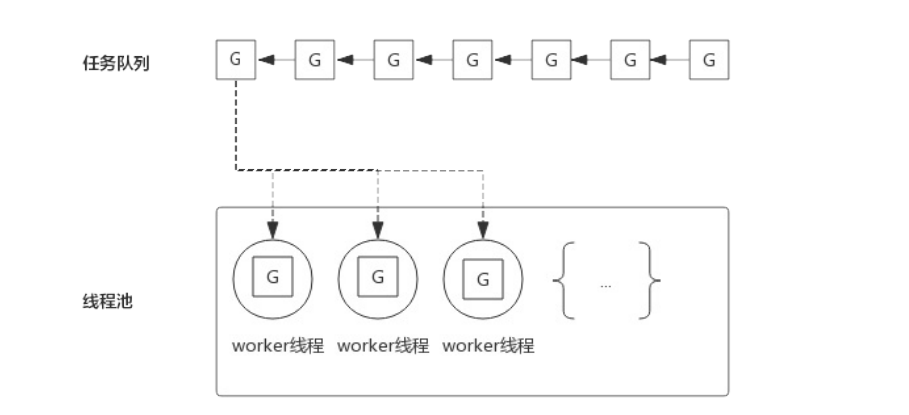
通过线程池,我们规定只创建一定数量的线程,每个线程一次携带一个任务去执行,执行完后再回来携带另一个任务。
因为线程是固定数量的,要是这些线程都被阻塞,那么整个任务队列就会停摆。当然我们也可以增加线程池中的线程数量,但是数量多的话,就会由很多个线程去争抢 CPU,反而不一定能提高消费能力。
那么,我们看一下 Go 是怎么做的吧。首先我们要了解一些概念:
- G(Goroutine):就是 Go 协程,每个 go 关键字都会创建一个协程。
- M(Machine):工作线程,在 Go 中称为 Machine。
- P(Processor):逻辑处理器,包含运行 Go 代码的必要资源,也由调度 goroutine 的能力。
规则是:每个工作线程(M)需要协程(G)才能执行,而且逻辑处理器§有一个包含多个协程(G)的队列,然后逻辑处理器§可以调度协程(G)给工作线程(M)执行。
逻辑处理器§的个数是在程序启动时决定的,默认情况下等同于 CPU 的核数,而且一个逻辑处理器§只绑定一个工作线程(M),所以线程个数默认等同于 CPU 的个数。
Goroutine 调度策略
我们知道了 Goroutine 的调度是通过逻辑处理器§去调度的,那么具体是怎么做的呢?
队列轮转
在逻辑处理器§自己维护的队列上,如果协程(G)没有被阻塞,那么就将其执行一段时间后终止,将上下文保存下来后放到队列的尾部,然后从队列中重新取出一个协程(G)进行调度。
除了每个逻辑处理器§上的协程(G)队列外,运行时还有一个全局的队列。全局的队列是用来收留那些从系统调用中回复的协程(G)的。
所以,每个逻辑处理器§除了要调度自己的队列外,还要看看全局队列中是否有协程(G),有的话就把它调度到自己维护的队列上。
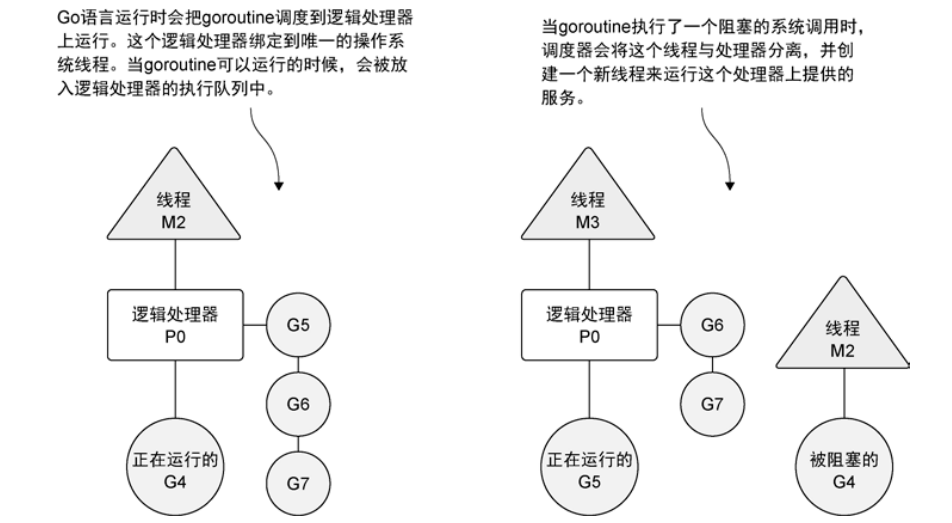
系统调用
那么发生系统中断的时候会发生的事情就是,逻辑处理器§会将当前这个工作线程(M)与当前执行的协程(G)脱离。
脱离的线程(M)就在一遍等待系统的调用,而逻辑处理器§会新建立一个线程,继续执行它自己维护队列里的协程(G)。
工作量窃取
当某个逻辑处理器§自己队列上的协程(G)都处理完了后,除了去看全局队列,它还会去看别的逻辑处理器§是否把它们的协程(G)都处理完了。
如果发现其他逻辑处理器§的队列上还有协程(G),那么它就会窃取一部分协程(G)过来执行,一般每次偷取一半。
一般来讲,程序运行时就将 GOMAXPROCS 大小设置为 CPU 核数,可让 Go 程序充分利用 CPU。在某些 IO 密集型的应用里,这个值可能并不意味着性能最好。理论上当某个 Goroutine 进入系统调用时,会有一个新的 M 被启用或创建,继续占满 CPU 、。但由于 Go 调度器检测到 M 被阻塞是有一定延迟的,也即旧的 M 被阻塞和新的 M 得到运行之间是有一定间隔的,所以在 IO 密集型应用中不妨把 GOMAXPROCS 设置的大一些,或许会有好的效果。
goroutine 同步与通信
Go 的运行时(runtime)是 Go 的核心部分,负责管理内存分配、垃圾回收、并发调度等底层任务。
我们的协程 goroutine 是由运行时管理的,就连 main 函数也都是运行在 goroutine 上的。
package main
import (
"fmt"
"time"
)
func test(){
fmt.Println("I am work in a single goroutine")
}
func main(){
// 把函数 test() 给到 goroutine
go test()
// 在 main 的 goroutine 上休眠一下
time.Sleep(time.Second)
}
上面的代码,假设我们不进行休眠的话,那么 main 执行完 go test() 就会马上结束,而 go test() 可能还没开始执行,所以可能什么都没返回。
此外,和其他编程语言一样,Go 不同 goroutine 间的代码次序并不能代表真正的执行顺序。
package main
import "fmt"
func setVTo1(v *int){
*v = 1
}
func setVTo2(v *int){
*v = 2
}
func main(){
v := new(int)
go setVTo1(v)
go setVTo2(v)
fmt.Println(*v)
}
上面代码的执行结果可能为 0、1或2,但最有可能的情况是 0,这取决于调度器的调度情况。
为了能够按照我们想要的顺序去执行 goroutine ,就需要用到 同步与通信 的一些方法去执行并发:
- channel:提供一种安全且同步的方式来发送和接收值。
- select:用于同时等待多个
channel操作,处理第一个可用的channel。 - sync.WaitGroup:提供一种简单的方法来等待一组 goroutine 完成执行。
- sync.Mutex:提供了一种锁机制来保护共享资源,防止并发访问导致的数据竞争。
- sync.RWMutext:读写锁,允许多个读操作同时进行,但写操作需要独占锁。
2.channel
Go 语言中倡导用 channel 作为 goroutine 之间同步和通信的手段。
channel 类型属于引用类型,而且每个 channel 只能传递固定类型的数据。
// 声明 channel 并指定传递类型为 T
var channelName chan T
// make 初始化 channel,sizeOfChan 为缓冲
ch := make(chan T, sizeOfChan)
其中,默认不带缓冲的 channel 也叫 同步 channel,收发数据的操作都会被阻塞;带缓冲的 channel 叫 异步 channel 收发数据时,如果 channel 未达到阻塞条件则不会被阻塞。
channel 的发送与接收
channel 作为一个队列,它总是保证数据收发顺序总是遵循先入先出的原则,同时也保证同一时刻只有一个 goroutine 访问 channel 来发送和获取数据。
此外,如果不用 defer 语句关闭 channel 或者用 sync.WaitGroup 的 Done 方法关闭 goroutine 的话,可能会导致 goroutine 泄露。
channel <- val 表示数据 val 将被发送到 channel 中;如果 channel 被填满之后,再向通道发送数据,则会阻塞当前的 goroutine。
val := <- channel 表示从 channel 中读取值并赋值到 val;如果 channel 没有数据,那么就阻塞要读取数据的 goroutine 直到有数据进入 channel。
如果想在读 channel 时返回,可以写成 val, ok := <- channel 只要检查一下 ok 就能判断是否读到了有效数据。
package main
import (
"bufio"
"fmt"
"os"
)
func printInput(ch chan string){
// for 循环从 channel 中读取数据
for val := range ch{
if val == "EOF"{
break
}
fmt.Printf("Input is %s \n", val)
}
}
func main(){
// 无缓冲 channel
ch := make(chan string)
// 启动协程,因为 chan 无数据先被阻塞
go printInput(ch)
// 从命令行读取输入发给 goroutine
scanner := bufio.NewScanner(os.Stdin)
// 阻塞,等待命令行输入
for scanner.Scan(){
val := scanner.Text()
ch <- val
if val == "EOF"{
fmt.Println("End the game!")
break
}
}
// 最后关闭 chan
defer close(ch)
}
带缓冲的 channel
如果创建 channel 时指定了 channel 长度,那么 channel 就会拥有缓冲区,goroutine 在缓冲区未填满时往 channel 发送数据将不会被阻塞。
package main
import (
"fmt"
"time"
)
func consume(ch chan int){
// 线程休息 3s 后再开始读数据
time.Sleep(time.Second * 3)
<- ch
}
func main(){
// 长度为 2 的 channel
ch := make(chan int, 2)
// 启动线程
go consume(ch)
ch <- 0
ch <- 1
fmt.Println("I am free!")
ch <- 2 // 阻塞,等待 goroutine 读取数据
fmt.Println("I can not go there within 3s!")
time.Sleep(time.Second)
}
此外,我们可以声明单向的 channel,就是只能从 channel 发送数据或者只能从 channel 中读取数据,一般用于在传递 channel 时作为函数的参数,保证代码接口的严谨,避免进行越界操作。
ch := make(chan T)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









