







 struc2vec是一种网络表示学习模型,旨在捕捉节点的结构化角色相似度,而非仅仅依赖于近邻相似。通过构建层次带权图并采用随机游走策略,struc2vec能生成反映节点结构角色的表示。模型涉及相似度定义、顶点距离计算、图构造和优化方法,以提高效率和准确性。
struc2vec是一种网络表示学习模型,旨在捕捉节点的结构化角色相似度,而非仅仅依赖于近邻相似。通过构建层次带权图并采用随机游走策略,struc2vec能生成反映节点结构角色的表示。模型涉及相似度定义、顶点距离计算、图构造和优化方法,以提高效率和准确性。
题目:struc2vec: Learning Node Representations from Structural Identity
作者:Leonardo F. R. Ribeiro, Pedro H. P. Saverese, Daniel R. Figueiredo
来源:KDD 2017
传统的graph embedding方法如DeepWalk,LINE,SDNE等都是基于近邻相似假设的(Homohily,同质性),两个顶点的共同邻居越多则越相似。然而在一些场景中,两个不是近邻的顶点也可能拥有很高的相似性,可能这些节点在邻域中的角色相似,例如星型结构的中心节点,社区结构之间的桥接节点等。struc2vec就是针对捕捉节点的结构化角色相似度(structural role proximity)提出的模型。
模型
struc2vec总体流程如下:
(1)根据不同距离的邻居信息,分别计算计算节点对的结构相似度 f k ( u , v ) f_k(u,v) fk(u,v) (第k层u和v节点的结构相似度)
(2)构造多层带权有向图 M,其中每层都是带权无向图,层与层之间是有向的
(3)在M中随机游走,构造上下文序列
(4)skip-gram训练序列,得到每个节点的表示
相似度定义
struc2vec从空间结构相似性的角度定义顶点相似度。下图中如果在基于近邻相似的模型中,顶点u和顶点v是不相似的,第一他们不直接相连,第二他们不共享任何邻居顶点。
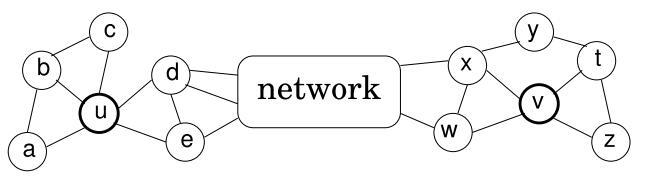
但是在struc2vec的假设中,顶点u和顶点v是具有空间结构相似的。他们的度数分别为5和4,分别连接3个和2个三角形结构,通过2个顶点(d,e;x,w)和网络的其他部分相连。
直观来看,如果两个顶点的度相同,那么这两个顶点的结构是相似的,若各自邻接顶点仍然具有相同度数,那么他们的相似度就更高。
顶点对距离定义
令  表示到顶点u距离为k的顶点集合,则
表示到顶点u距离为k的顶点集合,则  表示是u的直接相连近邻集合。
表示是u的直接相连近邻集合。
令  表示顶点集合S的有序度序列。
表示顶点集合S的有序度序列。
通过比较两个顶点之间距离为k的环路上的有序度序列可以推出一种层次化衡量结构相似度的方法。
令  表示顶点u和v之间距离为k(这里的距离k实际上是指距离小于等于k的节点集合)的环路上的结构距离(注意是距离,不是相似度)。
表示顶点u和v之间距离为k(这里的距离k实际上是指距离小于等于k的节点集合)的环路上的结构距离(注意是距离,不是相似度)。

其中  是衡量有序度序列
是衡量有序度序列  和
和  的距离的函数,并且
的距离的函数,并且  。
。
注意到的计算是在 上加上一个非负的值,因此该函数关于k是一个单调不降的函数。并且这个函数只有在两个节点同时存在k跳邻域的时候才有定义。
上加上一个非负的值,因此该函数关于k是一个单调不降的函数。并且这个函数只有在两个节点同时存在k跳邻域的时候才有定义。
下面给出一个具体例子:

下面就是如何定义有序度序列之间的比较函数了,由于  和
和  的长度不同,并且可能含有重复元素。所以文章采用了**Dynamic Time Warping(DTW)**来衡量两个有序度序列。
的长度不同,并且可能含有重复元素。所以文章采用了**Dynamic Time Warping(DTW)**来衡量两个有序度序列。
一句话,DTW可以用来衡量两个不同长度且含有重复元素的的序列的距离(距离的定义可以自己设置)。
基于DTW,定义元素之间的距离函数 
至于为什么使用这样的距离函数,这个距离函数实际上惩罚了当两个顶点的度数都比较小的时候两者的差异。举例来说,  情况下的距离为1,
情况下的距离为1,  情况下的距离差异为0.0099。这个特性正是我们想要的。
情况下的距离差异为0.0099。这个特性正是我们想要的。
构建层次带权图
根据上一节的距离定义,对于每一个  我们都可以计算出两个顶点之间的一个距离,现在要做的是通过上一节得到的顶点之间的有序度序列距离来构建一个层次化的带权图(用于后续的随机游走)。
我们都可以计算出两个顶点之间的一个距离,现在要做的是通过上一节得到的顶点之间的有序度序列距离来构建一个层次化的带权图(用于后续的随机游走)。
每一层是一个带权完全图(任意两个节点都有边相连),因此有 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1) 条边
我们定义在某一层k中两个顶点的边权为 
这样定义的边权都是小于1的,当且仅当距离为0的是时候,边权为1。

通过有向边将属于不同层次的同一顶点连接起来,具体来说,对每个顶点,都会和其对应的上层顶点还有下层顶点相连。边权定义为


其中  是第k层与u相连的边的边权大于平均边权的边的数量。
是第k层与u相连的边的边权大于平均边权的边的数量。 ,
,  就是第k层所有边权的平均值。
就是第k层所有边权的平均值。
 第k层所有边权的平均值。 实际上表示了第k层中,有多少节点是与节点u相似的,如果u与很多节点都相似,说明此时一定处于低层次,考虑的信息太少,那么将会很大,即
第k层所有边权的平均值。 实际上表示了第k层中,有多少节点是与节点u相似的,如果u与很多节点都相似,说明此时一定处于低层次,考虑的信息太少,那么将会很大,即 ,对于这种情况,就不太适合将本层中的节点作为上下文了,应该考虑跳到更高层去找合适的上下文,所以高层的权重更大。
,对于这种情况,就不太适合将本层中的节点作为上下文了,应该考虑跳到更高层去找合适的上下文,所以高层的权重更大。

采样获取顶点序列
使用有偏随机游走在构造出的图  中进行顶点序列采样。 每
中进行顶点序列采样。 每
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









