







独立部署(Standalone)模式由Flink自身提供计算资源,无需其他框架提供资源,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是我们也要知道,Flink主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成更靠谱,所以接下来我们来学习在强大的Yarn环境中Flink是如何使用的。(其实是因为在国内工作中,Yarn使用的非常多)
一、Yarn模式配置
把Flink应用提交给Yarn的ResourceManager, Yarn的ResourceManager会申请容器从Yarn的NodeManager上面. Flink会创建JobManager和TaskManager在这些容器上.Flink会根据运行在JobManger上的job的需要的slot的数量动态的分配TaskManager资源
1. 复制flink-yarn
cp -r flink-1.13.1 flink-yarn
2.配置环境变量HADOOP_CLASSPATH, 如果前面已经配置可以忽略。
在/etc/profile.d/my.sh中配置并分发
export HADOOP_CLASSPATH=`hadoop classpath`
二、Yarn运行无界流WordCount
1.启动hadoop集群(hdfs, yarn)
2.运行无界流
bin/flink run -t yarn-per-job -c com.bigdata.flink.java.chapter_2.Flink03_WC_UnBoundedStream ./flink-prepare-1.0-SNAPSHOT.jar
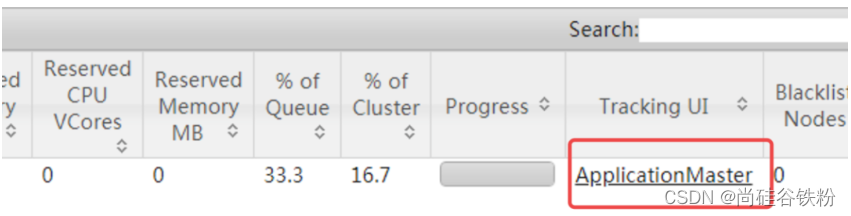
3.在yarn的ResourceManager界面查看执行情况
三、Flink on Yarn的3种部署模式
Flink提供了yarn上运行的3种模式,分别为Session-Cluster,Application Mode和Per-Job-Cluster模式。
1. Session-Cluster
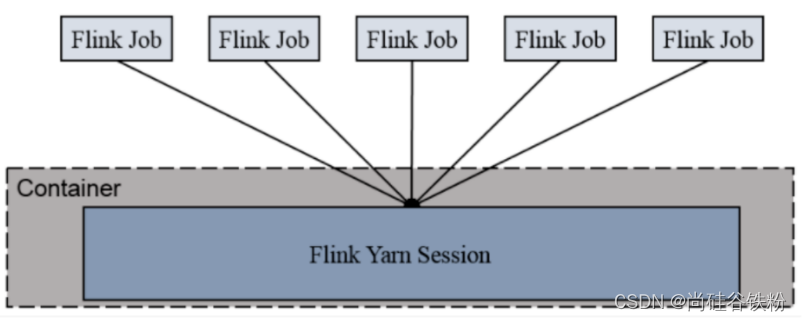
Session-Cluster模式需要先启动Flink集群,向Yarn申请资源。以后提交任务都向这里提交。这个Flink集群会常驻在yarn集群中,除非手动停止。
在向Flink集群提交Job的时候, 如果资源被用完了,则新的Job不能正常提交。
缺点: 如果提交的作业中有长时间执
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1541
1541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









