




 本文深入探讨机器学习的基础概念,包括监督学习、非监督学习等,并详细解析统计学习方法,如模型假设空间、策略与算法,以及输入、特征与输出空间的概念。此外,还介绍了回归、分类和标注问题,联合概率分布的重要性,以及模型选择的策略。
本文深入探讨机器学习的基础概念,包括监督学习、非监督学习等,并详细解析统计学习方法,如模型假设空间、策略与算法,以及输入、特征与输出空间的概念。此外,还介绍了回归、分类和标注问题,联合概率分布的重要性,以及模型选择的策略。
1.目前技能水平
已入门python,具备独立web开发能力,每天阅读技术书籍一章的习惯,现确定目标为机器学习算法方向。
2.统计学习
又称为统计机器学习
是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。
从数据出发,提取数据的特征,抽象出数据的模型,发现数据中的知识,又回到对数据的分析与预测中去。
3.监督学习
统计学习方法包括监督学习、非监督学习、半监督学习以及强化学习,本书主要讨论监督学习。
监督学习的统计学习方法的概述为:从给定的、有限的、用于学习的训练数据(training data)集合出发,假设数据是独立同发布产生的;并且假设要学习的模型属于某个函数的集合,称为假设空间(hypothesis space);应用某个评价准则(evaluation criterion),从假设空间中选取一个最优的模型,使它对已知训练数据及未知测试数据(test data)在给定的评价准则下有最优的预测;最优模型的选取由算法实现。
因此监督学习的统计学习方法包括模型的假设空间、模型选择的准则以及模型学习的方法,称其为统计学习方法的三要素,简称为模型(model)、策略(strategy)、算法(algorithm)。
4.输入空间、特征空间与输出空间
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示。
这时,所以特征向量存在的空间称为特征空间(feature space),特征空间的每一维对应一个特征。
模型实际上都是定义在特征空间上的。
输入、输出变量都用大写字母表示,分别是X/Y,输入、输出变量具体的值用小写字母表示,分别是x/y。(变量可以是标量或向量,本书的向量均为列向量)

5.监督学习的训练
监督学习从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测。训练数据由输入(或特征变量)与输出对组成,训练集通常表示为,
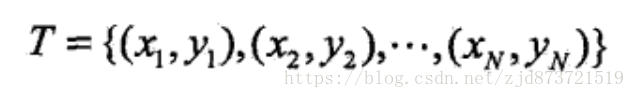
测试数据也由相应的输入与输出对组成。输入与输出对又称为样本(sample)或样本点。
6.回归、分类和标注
输入变量与输出变量均为连续变量的预测问题称为回归问题;
输出变量为有限个离散变量的预测问题称为分类问题;
输入变量与输出变量均为变量序列的预测问题称为标注问题。
7.联合概率分布
监督学习假设输入与输出的随机变量X和Y遵循联合概率分别P(X,Y),其中P(X,Y)表示分布函数,或分布密度函数。
统计学习假定数据存在一定的统计规律,X和Y具有联合概率分布的假设就是监督学习关于数据的基本假设。
在学习过程中,假设这一联合概率分布存在,但对学习系统来说,联合概率分布的具体定义是未知的,训练数据与测试数据被看作是依联合概率分布P(X,Y)独立同分布产生的。
8.假设空间
监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示。
模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间。假设空间的确定意味着学习范围的确定。
监督学习的模型可以是概率模型,也可以是非概率模型,由条件概率分布P(Y|X)或决策函数(decision function)Y=f(X)表示,随具体学习方法而定。对具体的输入进行相应的输出预测时,写作P(Y|X)或Y=f(X)。
9.问题的形式化
监督学习利用一个训练数据集学习一个模型,再用模型对测试样本集进行预测(prediction)。
由于这个过程中需要的训练数据集是人工给出的,所以称为监督学习。
监督学习分为学习和预测两个过程,由学习系统和预测系统完成,如下图,
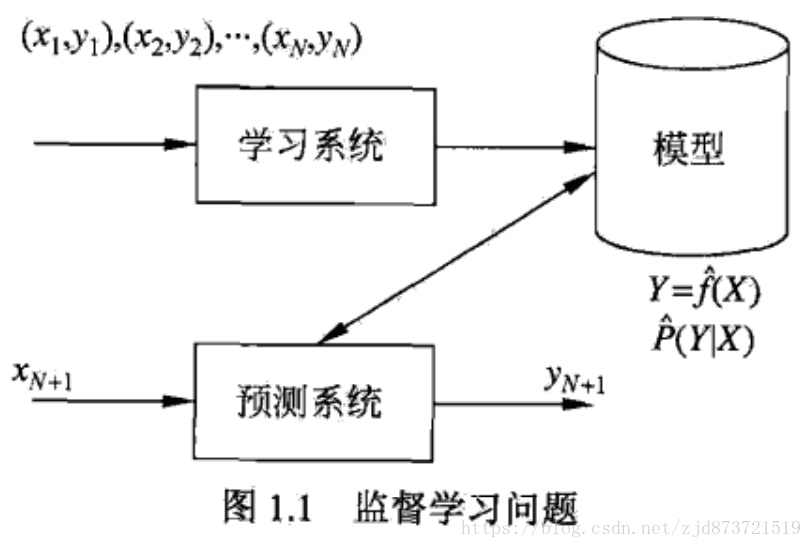
第一步:给出训练数据集
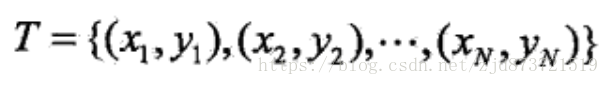
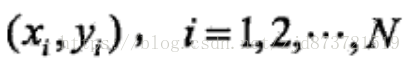 称为样本或样本点
称为样本或样本点
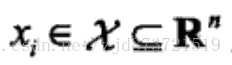 输入的观测值,也称为输入或实例
输入的观测值,也称为输入或实例
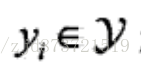 输出的观测值,也称为输出
输出的观测值,也称为输出
第二步,通过学习(或训练)得到一个模型
模型为条件概率分布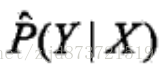
或者是决策函数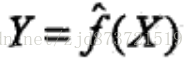
第三步,对测试样本集进行预测
(1)测试系统对于给定的测试样本集中的输入![]()
(2)由模型,如下,
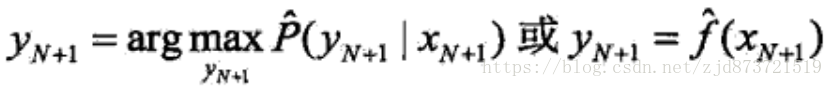
给出相应的输出![]()
(3)如果这个模型有很好的预测能力,训练样本集的输出![]() 和模型输出
和模型输出![]() 之间的差就应该足够小。
之间的差就应该足够小。
所以,学习系统需要不断的尝试,然后选取最好的模型,才能对测试数据集有更好的预测,对未知的测试数据集的预测有尽可能的推广。
10.模型(统计学习方法三要素之一)
模型的假设空间(hypothesis space)包含所有可能的条件概率分布或决策函数。假设空间的模型一般有无穷多个。
(1)假设空间可以定义为决策函数的集合,
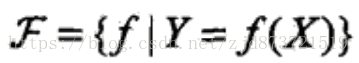
其中,X、Y是定义在输入空间x和输出空间y的变量,这时假设空间通常是由一个参数向量决定的函数簇,如,
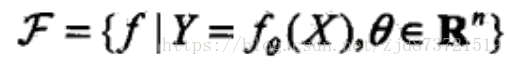
![]()
(2)假设空间也可以定义为条件概率的集合
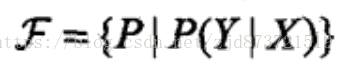
其中,X、Y也是定义在输入空间x和输出空间y的变量,这时假设空间通常是由一个参数向量决定的函数簇,如,
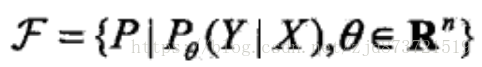
![]()
由决策函数表示的模型称为非概率模型,由条件概率表示的模型称为概率模型。
11.策略(统计学习方法三要素之一)
损失函数度量模型一次预测的好坏,风险函数度量平均意义下模型预测的好坏。
(1)损失函数(loss function)/代价函数(cost function)
用来度量预测值f(x)与真实值y的错误程度,有以下几种方法,

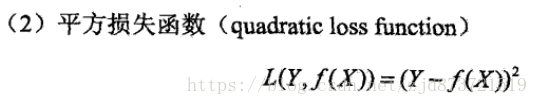
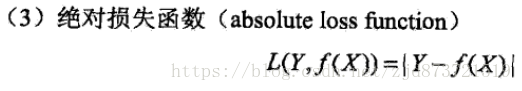
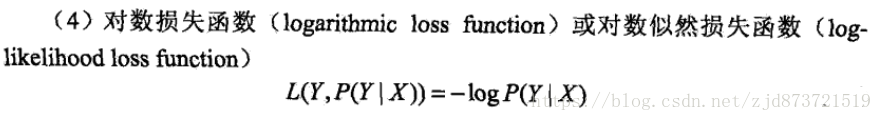
由于模型的输入输出(X、Y)是随机变量,遵循联合分布P(X,Y),所以损失函数的期望为,
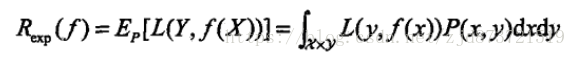
这是理论上模型f(x)关于联合分布P(X,Y)的平均意义下的损失,称为风险函数(risk function)或期望损失(expected loss)。(学习的目标就是选择期望风险最小的模型)
由于联合分布P(X,Y)是未知的,![]() 不能直接计算。实际上,如果知道联合分布P(X,Y),可以从联合分布直接求出条件概率分布P(X|Y),也就不需要学习了。这里就有一个病态问题(ill-formed problem),一方面根据期望风险最小学习模型要用到联合分布,另一方面联合发布又是未知的。
不能直接计算。实际上,如果知道联合分布P(X,Y),可以从联合分布直接求出条件概率分布P(X|Y),也就不需要学习了。这里就有一个病态问题(ill-formed problem),一方面根据期望风险最小学习模型要用到联合分布,另一方面联合发布又是未知的。
给定一个训练数据集,
![]()
模型f(x)关于训练数据集的平均损失称为经验风险(empirical risk)或经验损失(empirical loss),记作![]() ,公式如下,
,公式如下,
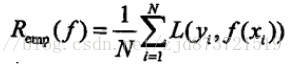
总结:
期望风险![]() 是模型关于联合分布的期望损失,经验风险
是模型关于联合分布的期望损失,经验风险![]() 是模型关于训练样本集的平均损失。
是模型关于训练样本集的平均损失。
根据大数定律,当样本容量N趋于无穷时,经验风险![]() 趋于期望风险
趋于期望风险![]() ,所以通常使用经验风险来估计期望风险。同时,由于训练样本数目有限,此时使用经验风险来估计期望风险的效果并不理想,就需要对经验风险进行一定的矫正,涉及到监督学习的两个基本策略:经验风险最小化和结构风险最小化。
,所以通常使用经验风险来估计期望风险。同时,由于训练样本数目有限,此时使用经验风险来估计期望风险的效果并不理想,就需要对经验风险进行一定的矫正,涉及到监督学习的两个基本策略:经验风险最小化和结构风险最小化。
(2)经验风险最小化和结构风险最小化
(1)经验风险最小化(empirical risk minimization,ERM)
它的策略认为,经验风险最小的模型是最优的模型。
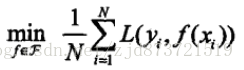

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









