






Hallo2 粗略阅读小记
逛网站的时候发现这篇文,10.10到现在已经3000星了,就浅浅了解了一下这个任务和所提出的网络。并记录复现的过程。
原文:HALLO2: LONG-DURATION AND HIGH-RESOLUTION AUDIO-DRIVEN PORTRAIT IMAGE ANIMATION
GitHub:Homepage
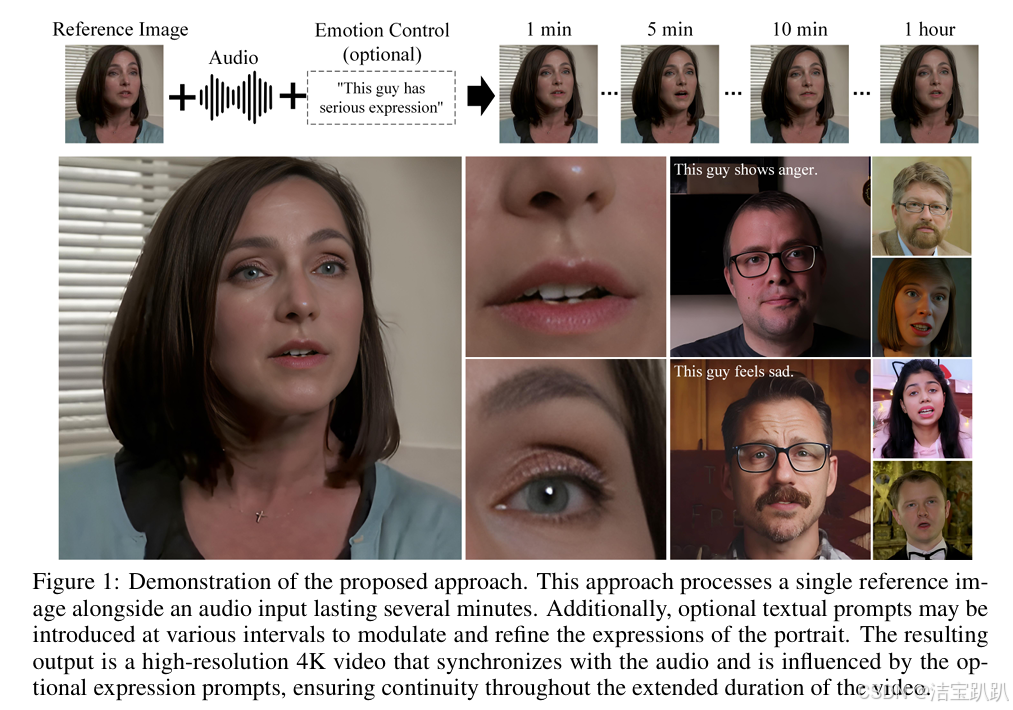
Hallo2是一种实现4K分辨率并长达一小时的音频驱动纵向图像动画方法,并通过文本提示进行增强。
当前先进的用于肖像图片动画的latent diffusion-based生成模型,像Hallo在短期视频生成上取得了不错的效果。
这篇文章的工作在Hallo上进行了加强和扩展。
试验数据集:HDTF、CelebV和作者提出的Wild数据集。
作者介绍了肖像图片动画(portrait image animation):
使用像语音、面部标志或者文本描述等多种输入信号根据一个参考肖像生成动画视频的过程。可以广泛应用于高质量的电影和动画制作、虚拟助手的开发、个性化的客户服务解决方案、交互式教育内容创建以及游戏行业的逼真角色动画。
介绍应用于肖像图片动画的模型:
VASA-1使用DiT作为扩散过程的一个降噪器。
EMO代表了第一个端到端系统,该系统能够使用基于U-Net的扩散模型来进行生成。
AniPortrait
EchoMimic
V-Express
Loopy
CyberHost
Hallo 使用分层音频驱动的视觉合成,实现了面部表情生成、头部姿势控制和个性化动作自定义
本文的主要贡献:
1、扩展了生成长视频的方法
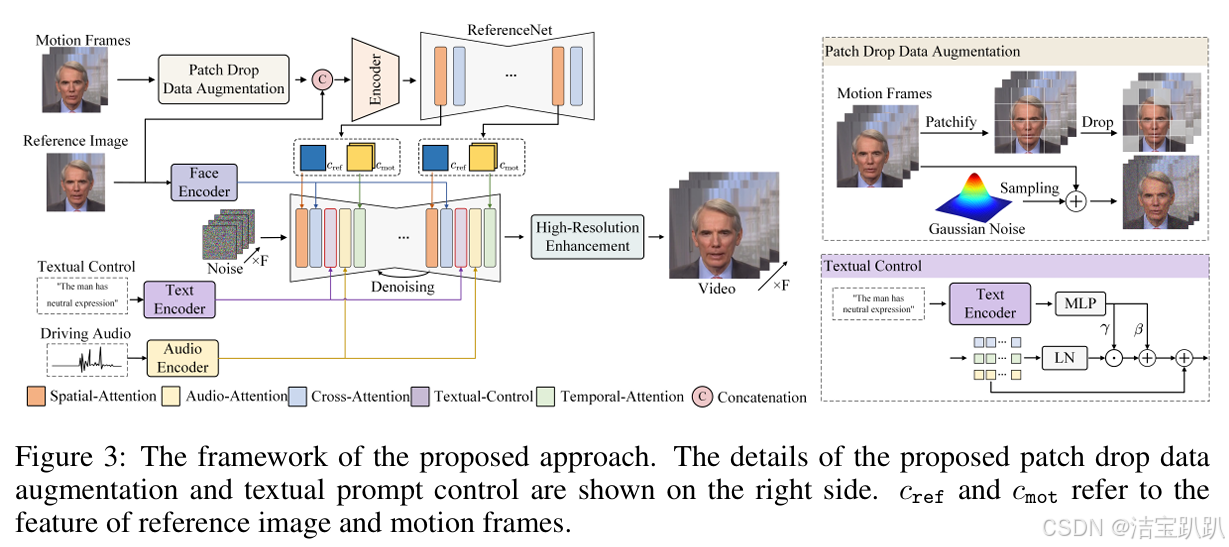
为了解决外观漂移和时间伪影(temporal artifacts)等重大挑战,作者研究了条件运动帧图像空间内的增强策略:一种用高斯噪声增强的patch-drop 技术以增强视觉一致性(visual consistency)和视频连贯性(temporal coherence)。
长期视频生成通常采用两种主要方法:并行和增量的diffusion-based ,前者会产生模糊和扭曲的表情和姿势并且动作会受到限制,幅度较小。后者允许连续运动,但容易产生误差积累,前一帧的扭曲和参照物的变形会影响到后续帧。
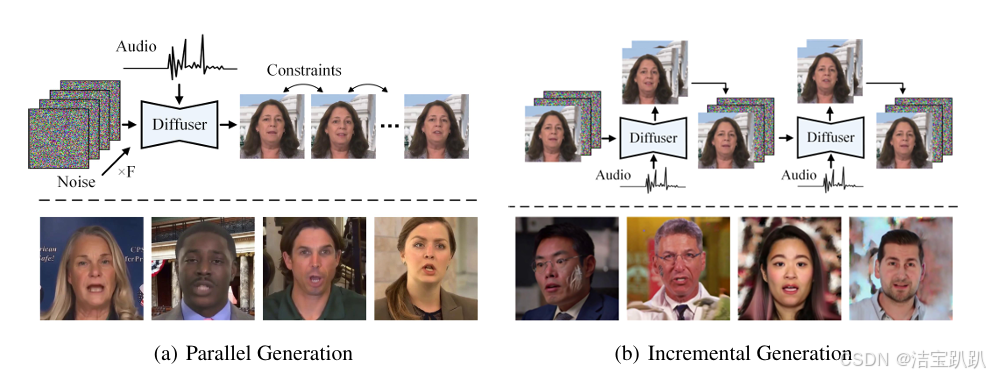
作者使用的是第二种方法。
为了防止来自前一帧的外观信息收到污染,试试了一种补丁式的数据增强技术,该技术在保留运动特征的同时,将受控损坏引入条件帧中的外观信息。
2、实现了4K分辨率肖像视频生成
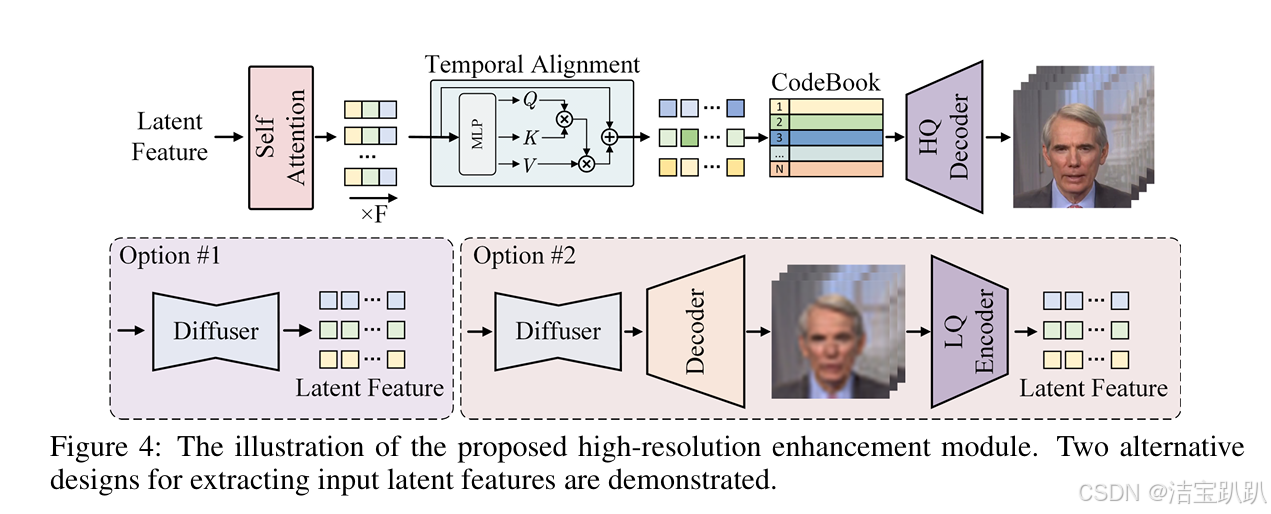
实现了潜在代码的向量量化,并应用时间对齐技术来保持整个时间维度的一致性。通过集成高质量的编码器,将用于代码序列预测任务的VQGAN(Vector Quantized Generative Adversarial Network)离散码簿空间方法扩展到时间维度,实现了4K分辨率的可视化合成。
3、将肖像表达式的可调整语义文本标签作为条件输入。
这超越了传统的音频提示,并增加了生成内容的多样性。为了增强语义控制,引入了调整合理的语义文本提示作为音频信号的条件输入,在不同时间间隔注入文本提示,用于调整面部表情和头部姿势,使得动画更加逼真和富有表现力。
论文复现(不含训练)
根据官网给出的流程依次进行,整体过程还是比较顺利的,除了下载权重的时候因为太大的原因需要自己下载三个不超过5G的权重。
配置相关环境
下载codes:
git clone https://github.com/fudan-generative-vision/hallo2
cd hallo2创建conda环境:
conda create -n hallo python=3.10
conda activate hallo安装包:
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt安装ffmpeg:
apt-get install ffmpeg下载预训练权重:
git lfs install
git clone https://huggingface.co/fudan-generative-ai/hallo2 pretrained_models运行以上代码之后除了以下三个权重没下好,其他的都下好了:stablediffusionv1.5、motion module、hallo下的net.pth 进入作者给的链接自己下载了一下

对比着作者给出的解构看了一下不差啥了,就可以进行下一步:
运行前的注意事项:
1、图片应该裁剪成正方形
2、人物面部占比要大
3、人物面部朝前,旋转角度小于30°(无侧面轮廓)
4、音频得是wav格式
5、音频得是英文,训练集只使用了这种语言
6、确保人声清晰,背景音乐是可以接受的
我第一次输入的图片中人物面部占比不大,导致效果不好。
音频的获取方式
我选择网页的在线转换:
ChatTTS:
ChatTTS Forge - a Hugging Face Space by lenML
但是有1说1:TTSMAKER更好用一些,出结果快,生成不会中断,选声音之前还可以试听:
非线上转换的:F5-TTS我还没尝试,感觉挺火的,过两天试试。
音频格式调整
生成的视频是.mp3格式的,我试图在存的时候直接转换成.wav,可以转换成功但是无法被Hallo2识别出来,所以还是找了一个在线的网站
代码分为两个部分:分别是生成视频和增加清晰度
生成长视频
python scripts/inference_long.py --config ./configs/inference/long.yaml
可以修改long.yaml中的source_image、driving_audio和save_path这三个内容
也可以在命令行里修改
python scripts/inference.py --audio_path audio.wav --image_path image.jpg
--face_mask_path face_mask.png --face_emb_path face_emb.pt --output_path output.mp4增加清晰度
把第一阶段得到的视频输入到第二阶段
python scripts/video_sr.py --input_path [input_video] --output_path [output_dir] --bg_upsampler realesrgan --face_upsample -w 1 -s 4
得到了的视频中,英文效果很好,中文的也还不错,这是因为她的训练过程都是使用的英文的相关数据集。
目前就探索到这里啦~

















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









