







MapReduce: Simplified Data Processing on Large Clusters
MapReduce是一个用于处理和生成大型数据集的编程模型和相关实现。用户指定处理键/值对的map函数来生成一组中间键/值对,以及合并与同一中间键相关的所有中间值的reduce函数。如本文所示,该模型可以表达许多现实世界中的任务。
用这种函数式风格编写的程序可以自动并行化,并在大型的商品机器集群上执行。运行时系统负责对输入数据进行分区、跨一组机器调度程序执行、处理机器故障和管理所需的机器间通信等细节。这使得没有任何并行和分布式系统经验的程序员可以轻松地利用大型分布式系统的资源。
我们的MapReduce实现运行在一个大型的商品机器集群上,并且具有高度的可伸缩性:一个典型的MapReduce计算在数千台机器上处理许多tb的数据。程序员发现这个系统很容易使用:已经实现了数百个MapReduce程序,每天在谷歌的集群上执行超过1000个MapReduce任务。
1 Introduction
输入数据通常很大,为了在合理的时间内完成计算,必须将计算分布到数百或数千台机器上。如何并行化计算、分发数据和处理故障等问题使得原本简单的计算变得晦涩难懂,需要大量复杂的代码来处理这些问题。
作为对这种复杂性的反应,我们设计了一个新的抽象,它允许我们表达我们试图执行的简单计算,但隐藏了库中并行化、容错、数据分布和负载平衡的混乱细节。我们的抽象受到了Lisp和许多其他函数式语言中的map和reduce原语的启发。我们意识到我们的大部分计算应用操作映射到每个逻辑记录参与我们的输入来计算一组中间键/值对,然后将减少操作应用于所有共享同一密钥的值,为了结合适当的导出数据。我们使用带有用户指定映射和reduce操作的函数模型,使我们能够轻松地将大型计算并行化,并使用重新执行作为容错的主要机制。
这项工作的主要贡献是一个简单而强大的接口,它可以实现大规模计算的自动并行化和分布,结合这个接口的实现,可以在大型集群的商用pc上实现高性能。
2 Programming Model
计算接受一组输入键/值对,并产生一组输出键/值对。MapReduce库的用户将计算表示为两个函数:Map和Reduce。
Map由用户编写,它接受一个输入对并生成一组中间键/值对。MapReduce库将与同一个中间键I相关联的所有中间值组合在一起,并将它们传递给Reduce函数。
Reduce函数(也是由用户编写的)接受一个中间键I和该键的一组值。它将这些值合并在一起,形成一个可能更小的值集。通常,每次Reduce调用只产生0或1个输出值。中间值通过迭代器提供给用户的reduce函数。这使我们能够处理过大而无法放入内存的值列表。
3 Implementation
MapReduce接口有很多不同的实现。正确的选择取决于环境。例如,一种实现可能适用于小型的共享内存机器,另一种适用于大型NUMA多处理器,而另一种适用于更大的联网机器集合
3.1 Execution Overview
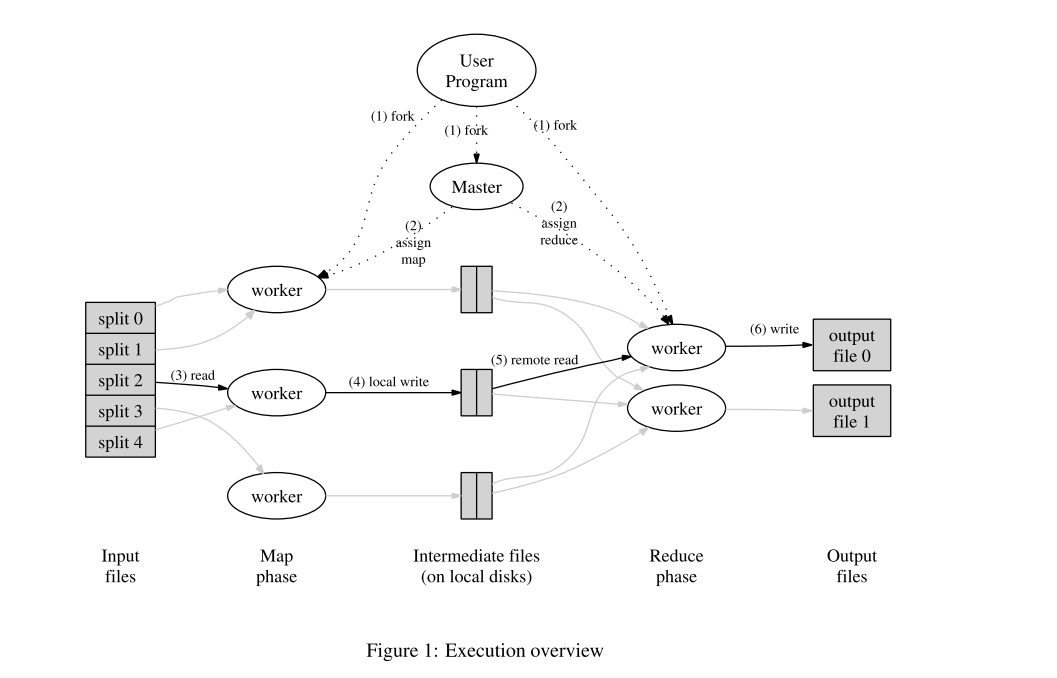
通过自动划分输入数据,Map调用分布在多台机器上形成一组M分割。输入分块可以由不同的机器并行处理。减少调用是通过使用分区函数(例如,hash(key) mod R)将中间键空间划分为R块来分配的。分区的数量(R)和分区函数由用户指定。
成功完成后,mapreduce执行的输出在R输出文件中可用(每个reduce任务一个,文件名由用户指定)。通常,用户不需要将这些R输出文件合并到一个文件中,他们通常将这些文件作为输入传递给另一个MapReduce调用,或者从另一个分布式应用程序中使用它们,该应用程序能够处理划分为多个文件的输入
后面跳过了...................................................................

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









