




scala基础语法
循环
1.for
常用方法:to(前后包含)、until(包左不包右)
单层循环for(变量名<-列表)
双层循环for (变量名<-列表 ;变量名<-列表 )
守卫 (变量名<-列表 if 布尔表达式 ;变量名<-列表 )
yeild 生成新的列表
方法定义
def methodName (参数名:参数类型, 参数名:参数类型) : [return type] = {
// 方法体:一系列的代码
}
scala> def add(a:Int, b:Int) : Int = a + b
m1: (x: Int, y: Int)Int
scala> add(1,2)
res10: Int = 3
示例
定义递归方法(求阶乘)
10 * 9 * 8 * 7 * 6 * … * 1
scala> def m2(x:Int):Int = {
| if(x<= 1) 1
| else(m2(x-1)*x)
| }
scala> def m2(x:Int):Int = {
| if(x<= 1) 1
| else m2(x-1)*x
| }
方法的书写规范
def methodName (参数名:参数类型, 参数名:参数类型) : [return type] = {
// 方法体:一系列的代码
}
对于非递归方法,方法的返回值可以省略
def 方法名 (参数名:参数类型…)={方法体}
如果方法体只有一行语句,()可以省略
def 方法名 (参数名:参数类型…)=方法体
方法没有返回值的时候,=可以省略
def 方法名 (参数名:参数类型…)方法体
如果方法没有参数,()可以省略
def 方法名={方法体}
def 方法名={方法体}递归的犯法,返回类型必须定义
def 方法名 (参数名:参数类型......):返回值类型 ={方法体}
方法参数可以设置默认值
def 方法名 (参数名:参数类型=默认值…):返回值类型 ={方法体}
可变参数的方法定义(可变参数放在参数列表的最后)
def 方法名 (参数名:参数类型,参数名:参数类型*…):返回值类型 ={方法体}
数组(可变数组,不可变数组)
创建空的ArrayBuffer变长数组,语法结构:
val/var a = ArrayBuffer[元素类型]()
取值方式 a(下标)
创建带有初始元素的ArrayBuffer
val/var a = ArrayBuffer(元素1,元素2,元素3....)
函数(函数可以作为方法的参数或者返回值,函数是对象,可以赋值给变量)
val 函数变量名 = (参数名:参数类型, 参数名:参数类型....) => 函数体
scala> val func=(x:Int,y:Int)=>x+y
func: (Int, Int) => Int = <function2>
scala> func(9,10)
res27: Int = 19
方法转换为函数
- 有时候需要将方法转换为函数,作为变量传递,就需要将方法转换为函数
- 使用_即可将方法转换为函数
scala> def add(x:Int,y:Int)=x+y
add: (x: Int, y: Int)Int
scala> val a = add _
a: (Int, Int) => Int = <function2>
元组
val/var 元组 = (元素1, 元素2, 元素3....)
val/var 元组 = 元素1->元素2
scala> val a = (1, "zhangsan", 20, "beijing")
a: (Int, String, Int, String) = (1,zhangsan,20,beijing)
访问元组 名称._
使用_1、_2、_3…来访问元组中的元素,_1表示访问第一个元素,依次类推
scala> val a = "zhangsan" -> "male"
a: (String, String) = (zhangsan,male)
// 获取第一个元素
scala> a._1
res41: String = zhangsan
// 获取第二个元素
scala> a._2
res42: String = male
列表List nil表示无值
列表是scala中最重要的、也是最常用的数据结构。List具备以下性质:
- 可以保存重复的值
- 有先后顺序
不可变列表就是列表的元素、长度都是不可变的。
val/var 变量名 = List(元素1, 元素2, 元素3...)
使用Nil创建一个不可变的空列表
val/var 变量名 = Nil
追加创建
val/var 变量名 = 元素1 :: 元素2 :: Nil
可变列表
val/var 变量名 = ListBuffer[Int]()
scala> val listbuffer = ListBuffer[Int]()
listbuffer: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
val/var 变量名 = ListBuffer(元素1,元素2,元素3...)
scala> val a = ListBuffer(1,2,3,4)
取值方式 a(下标)
可变列表操作
- 获取元素(使用括号访问(索引值))
- 添加元素(+=)
- 追加一个列表(++=)
- 更改元素(使用括号获取元素,然后进行赋值)
- 删除元素(-=)
- 转换为List(toList)
- 转换为Array(toArray)
- 压平操作 (flatten)
拉链与拉开 列表List (列表长度不一会取对应上的部分)
- 拉链:使用zip将两个列表,组合成一个元素为元组的列表
- 拉开:将一个包含元组的列表,解开成包含两个列表的元组
示例
- 有两个列表
- 第一个列表保存三个学生的姓名,分别为:zhangsan、lisi、wangwu
- 第二个列表保存三个学生的年龄,分别为:19, 20, 21
- 使用zip操作将两个列表的数据"拉"在一起,形成 zhangsan->19, lisi ->20, wangwu->21
参考代码
scala> val a = List("zhangsan", "lisi", "wangwu")
a: List[String] = List(zhangsan, lisi, wangwu)
scala> val b = List(19, 20, 21)
b: List[Int] = List(19, 20, 21)
scala> a.zip(b)
res1: List[(String, Int)] = List((zhangsan,19), (lisi,20), (wangwu,21))
示例
- 将上述包含学生姓名、年龄的元组列表,解开成两个列表
参考代码
scala> res1.unzip
res2: (List[String], List[Int]) = (List(zhangsan, lisi, wangwu),List(19, 20, 21))
List操作
生成字符串mkstring
获得两个列表的并集 union
获取交集intersect
去重 distinct
获取a列表中b列表没有的 a diff(b)
Set 集合 (元素不重复,无序)
导包后就是可变set
取值:set(加标)
不可变集
创建空的不可变集
var/val 变量名 = Set[类型]()
给定元素创建
var/val 变量名 = Set( 元素1,元素2,元素3.............)
scala> val set = Set(1,1,2,4,55,55,6,77)
set: scala.collection.immutable.Set[Int] = Set(1, 6, 77, 2, 55, 4)
scala> val set = Set[Int](10)
set: scala.collection.immutable.Set[Int] = Set(10)
映射 | map (导包后就可以变成可变MAP 不重复,无序)
取值: map.getOrElse(KEY,默认值)
不可变Map
val/var map = Map(键->值, 键->值, 键->值...) // 推荐,可读性更好
val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)
可变Map
定义
定义语法与不可变Map一致。但定义可变Map需要手动导入import scala.collection.mutable.Map
var map = Map[String,Int]("zhangsan"->30 ,"lisi"->20)
// 修改value
scala> map(“zhangsan”) = 20
列表迭代器 (迭代器有状态,(已经标记最后一个元素)用完需要重新获取)
scala> val a = List(1,1,2,5,6,7)
a: List[Int] = List(1, 1, 2, 5, 6, 7)
scala> val ite = a.iterator
ite: Iterator[Int] = non-empty iterator
scala> while(ite.hasNext){
| println(ite.next)
| }
1
1
2
5
6
7
函数式编程
我们将来使用Spark/Flink的大量业务代码都会使用到函数式编程。下面的这些操作是学习的重点。
- 遍历(foreach)
- 映射(map)
- 映射扁平化(flatmap)
- 过滤(filter)
- 是否存在(exists)
- 排序(sorted、sortBy、sortWith)
- 分组(groupBy)
- 聚合计算(reduce)
- 折叠(fold)
- 遍历(foreach)
方法签名
foreach(f: (A) ⇒ Unit): Unit
说明
| foreach | API | 说明 |
|---|---|---|
| 参数 | f: (A) ⇒ Unit | 接收一个函数对象 函数的输入参数为集合的元素,返回值为空 |
| 返回值 | Unit | 空 |
// 省略参数类型
scala> val a = List(1,2,3,4)
a: List[Int] = List(1, 2, 3, 4)
使用类型推断简化函数定义
a.foreach(x=>println(x))
- 如果方法参数是函数,如果出现了下划线,scala编译器会自动将代码封装到一个函数中
- 参数列表也是由scala编译器自动处理
a.foreach(println(_))
- 映射(map)
map方法接收一个函数,将这个函数应用到每一个元素,返回一个新的列表
方法签名
def map[B](f: (A) ⇒ B): TraversableOnce[B]
说明
| foreach | API | 说明 |
|---|---|---|
| 参数 | f: (A) ⇒ B | 传入一个函数对象 该函数接收一个类型A(要转换的列表元素),返回值为类型B |
| 返回值 | TraversableOnce[B] | B类型的集合 |
通过传入一个函数,对集合中的每一个元素进行函数计算
scala> a
res31: List[Int] = List(1, 1, 2, 5, 6, 7)
scala> a.map(x=>x+1)
res33: List[Int] = List(2, 2, 3, 6, 7, 8)
scala> a.map(_+1)
res34: List[Int] = List(2, 2, 3, 6, 7, 8)
- 映射扁平化(flatmap)
定义
可以把flatMap,理解为先map,然后再flatten
参数是一个函数,一个入参,出参是一个列表或者集合
应用场景是1对多
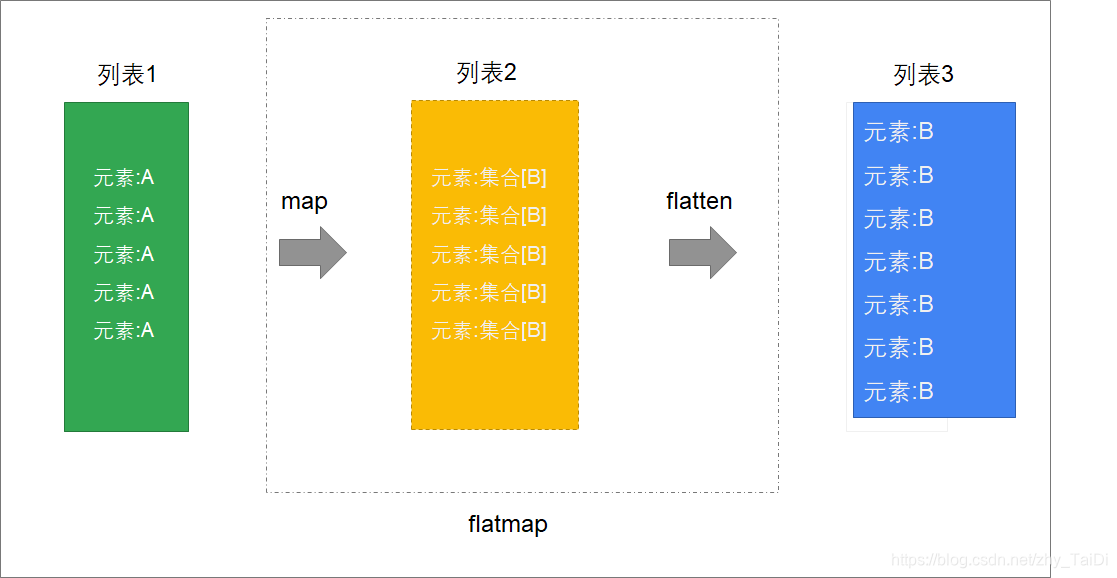
- map是将列表中的元素转换为一个List
- flatten再将整个列表进行扁平化
方法签名
def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): TraversableOnce[B]
说明
| flatmap方法 | API | 说明 |
|---|---|---|
| 泛型 | [B] | 最终要转换的集合元素类型 |
| 参数 | f: (A) ⇒ GenTraversableOnce[B] | 传入一个函数对象 函数的参数是集合的元素 函数的返回值是一个集合 |
| 返回值 | TraversableOnce[B] | B类型的集合 |
案例
案例说明
- 有一个包含了若干个文本行的列表:“hadoop hive spark flink flume”, “kudu hbase sqoop storm”
- 获取到文本行中的每一个单词,并将每一个单词都放到列表中
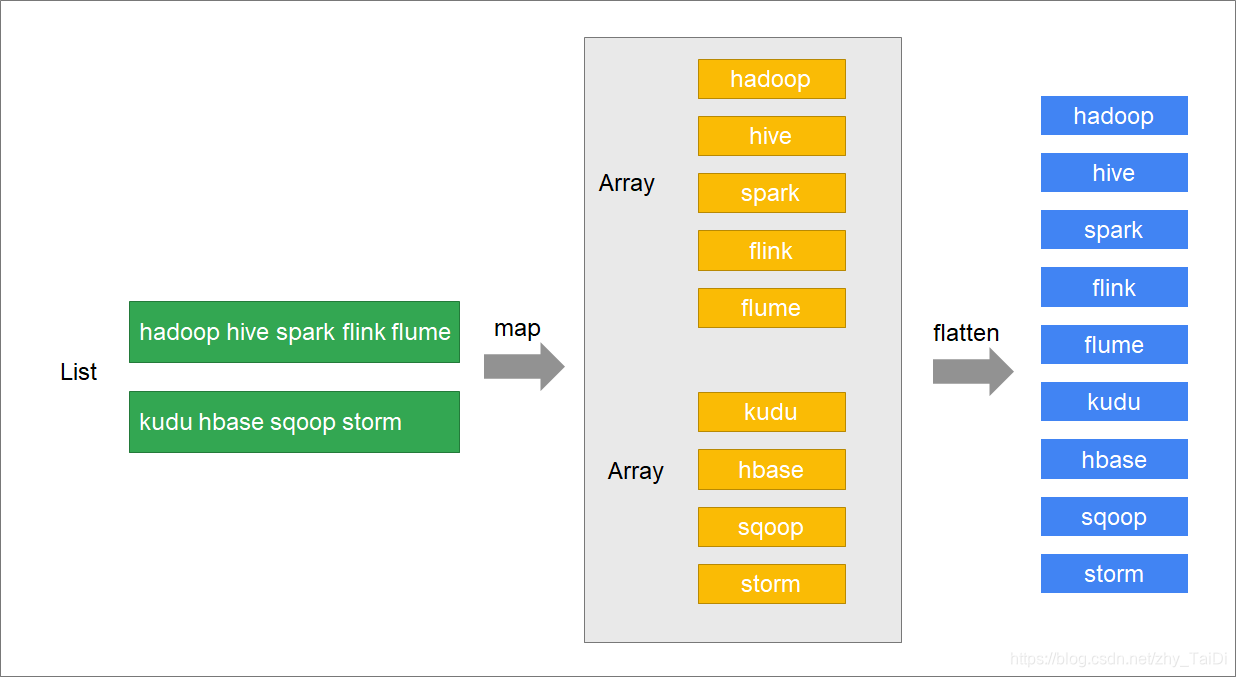 步骤
- 使用map将文本行拆分成数组
- 再对数组进行扁平化
scala> a.map(x=>x.split(" "))
res48: List[Array[String]] = List(Array(hadoop, hive, spark, flink, flume), Array(kudu, hbase, sqoop, storm))
scala> a.map(x=>x.split(" ")).flatten
res49: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm)
scala> a.flatMap(_.split(" "))
res52: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm)
过滤 | filter
def filter(p: (A) ⇒ Boolean): TraversableOnce[A]
说明
| filter方法 | API | 说明 |
|---|---|---|
| 参数 | p: (A) ⇒ Boolean | 传入一个函数对象 接收一个集合类型的参数 返回布尔类型,满足条件返回true, 不满足返回false |
| 返回值 | TraversableOnce[A] | 列表 |
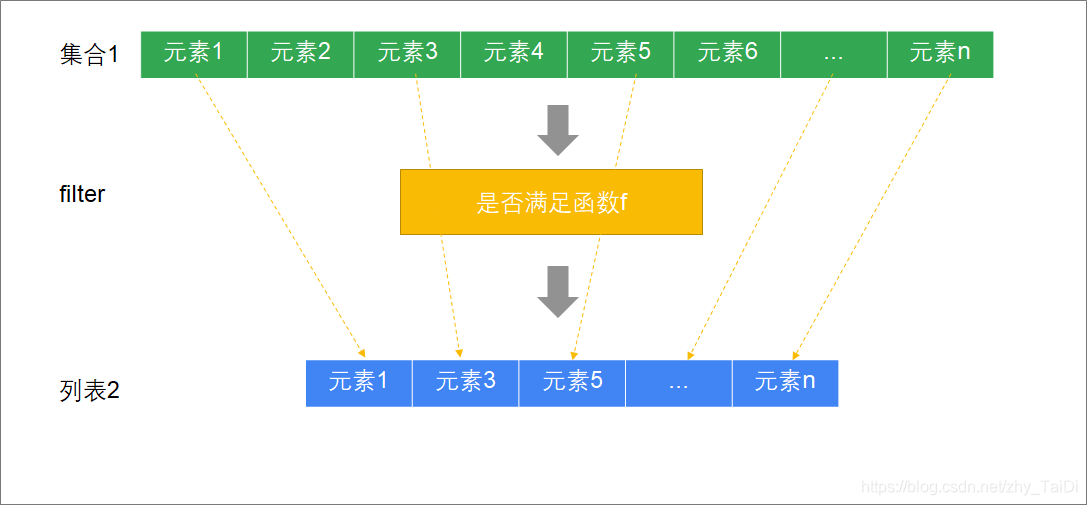
scala> List(1,2,3,4,5,6,7,8,9).filter(_ % 2 == 0)
res8: List[Int] = List(2, 4, 6, 8)
排序
在scala集合中,可以使用以下几种方式来进行排序
- sorted默认排序
- sortBy指定字段排序
- sortWith自定义排序
sortBy方法签名
def sortBy[B](f: (A) ⇒ B): List[A]
说明
| sortBy方法| API | 说明 |
|--|--|--|
| 泛型 | [B] | 按照什么类型来进行排序 |
| 参数 | f: (A) ⇒ B| 传入函数对象<br />接收一个集合类型的元素参数<br />返回B类型的元素进行排序 |
| 返回值 | List[A] | 返回排序后的列表 |
自定义排序 | sortWith
def sortWith(lt: (A, A) ⇒ Boolean): List[A]
说明
| sortWith方法 | API | 说明 |
|---|---|---|
| 参数 | lt: (A, A) ⇒ Boolean | 传入一个比较大小的函数对象 接收两个集合类型的元素参数 返回两个元素大小,小于返回true,大于返回false |
| 返回值 | List[A] | 返回排序后的列表 |
scala> val a = List(4,6,8,1,6,2,8,3)
a: List[Int] = List(4, 6, 8, 1, 6, 2, 8, 3)
scala> a.sortWith((x,y)=> if(x<y)true else false)
res53: List[Int] = List(1, 2, 3, 4, 6, 6, 8, 8)
scala> a.sortWith((x,y)=> if(x<y)false else true)
res54: List[Int] = List(8, 8, 6, 6, 4, 3, 2, 1)
scala> a.sortWith(_ < _).reverse
map和foreach的区别
map有返回值,foreach没有返回值
map和flatMap的区别
map针对列表的每一个元素,返回的是对应的转化之后的数据,长度一样
flatMap针对每一个元素,返回的是一个列别,最终生成列表的长度大于原来的
分组 | groupBy
def groupBy[K](f: (A) ⇒ K): Map[K, List[A]]
说明
| groupBy方法 | API | 说明 |
|---|---|---|
| 泛型 | [K] | 分组字段的类型 |
| 参数 | f: (A) ⇒ K | 传入一个函数对象 接收集合元素类型的参数 返回一个K类型的key,这个key会用来进行分组,相同的key放在一组中 |
| 返回值 | Map[K, List[A]] | 返回一个映射,K为分组字段,List为这个分组字段对应的一组数据 |
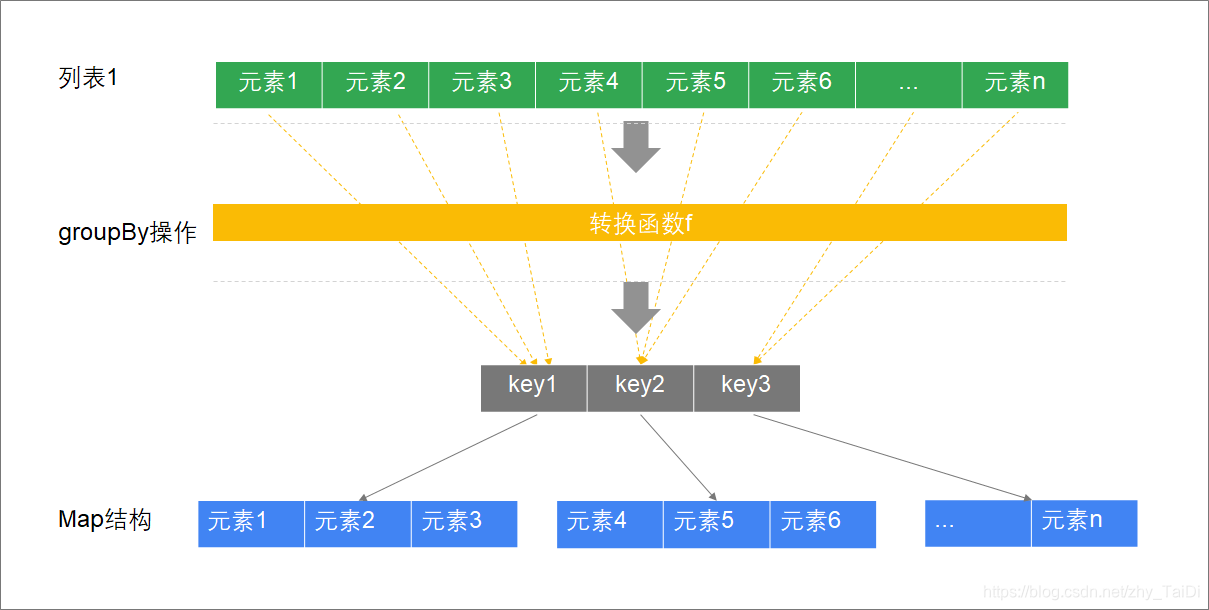
scala> val a = List("张三"->"男", "李四"->"女", "王五"->"男")
a: List[(String, String)] = List((张三,男), (李四,女), (王五,男))
// 按照性别分组
scala> a.groupBy(_._2)
res0: scala.collection.immutable.Map[String,List[(String, String)]] = Map(男 -> List((张三,男), (王五,男)),
女 -> List((李四,女)))
// 将分组后的映射转换为性别/人数元组列表
scala> res0.map(x => x._1 -> x._2.size)
res3: scala.collection.immutable.Map[String,Int] = Map(男 -> 2, 女 -> 1)
聚合方法 :reduce、fold
reduce
参数:上一次聚合结果,当前需要聚合的元素;=》U
fold(初始值)
参数:上一次聚合结果,当前需要聚合的元素;=》U

















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









