




AI Core的片上存储单元和相应的数据通路构成了存储系统。众所周知,几乎所有的深度学习算法都是数据密集型的应用。对于昇腾AI芯片来说,合理设计的数据存储和传输结构对于最终系统运行的性能至关重要。不合理的设计往往成为性能瓶颈,从而白白浪费了片上海量的计算资源。AI Core通过各种类型分布式缓冲区之间的相互配合,为深度神经网络计算提供了大容量和及时的数据供应,为整体计算性能消除了数据流传输的瓶颈,从而支撑了深度学习计算中所需要的大规模、高并发数据的快速有效提取和传输。
存储单元
芯片中的计算资源要想发挥强劲算力,必要条件是保证输入数据能够及时准确的出现在计算单元里。达芬奇架构通过精心设计的存储单元为计算资源保证了数据的供应,相当于AI Core中的后勤系统。AI Core中的存储单元由存储控制单元、缓冲区和寄存器组成,如图3-11中的加粗显示。存储控制单元通过总线接口可以直接访问AI Core之外的更低层级的缓存,并且也可以直通到DDR或HBM从而可以直接访问内存。存储控制单元中还设置了存储转换单元,其目的是将输入数据转换成AI Core中各类型计算单元所兼容的数据格式。缓冲区包括了用于暂存原始图像特征数据的输入缓冲区,以及处于中心的输出缓冲区来暂存各种形式的中间数据和输出数据。AI Core中的各类寄存器资源主要是标量计算单元在使用。
所有的缓冲区和寄存器的读写都可以通过底层软件显式的控制,有经验的程序员可以通过巧妙的编程方式来防止存储单元中出现读写冲突而影响流水线的进程。对于类似卷积和矩阵这样规律性强的计算模式,高度优化的程序可以实现全程无阻塞的流水线执行。
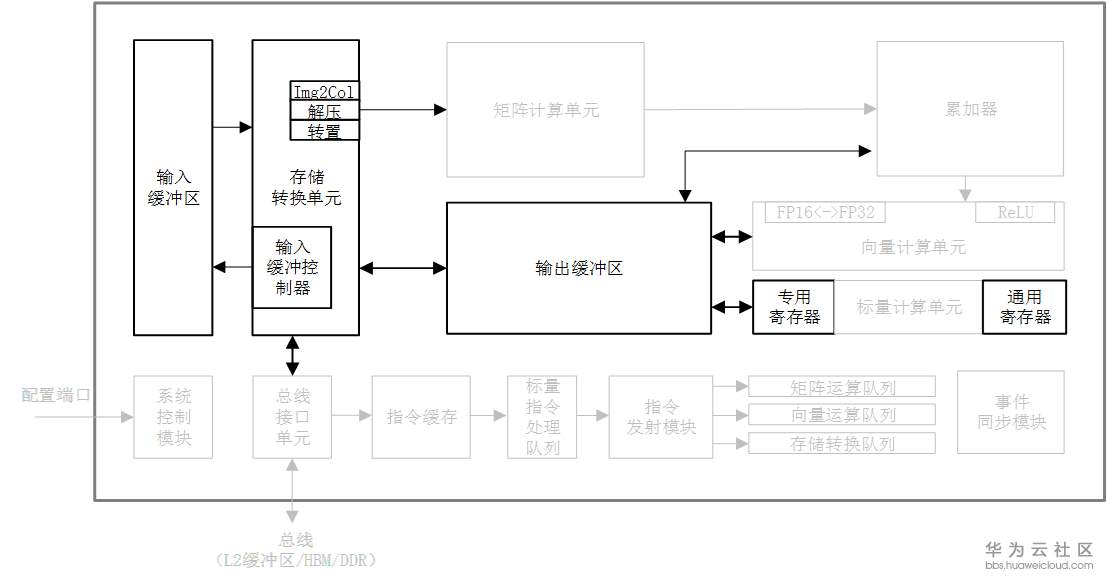
上图中的总线接口单元作为AI Core的“大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









