






目录
1、urllib.parse.quote() 2、urllib.parse.urlencode()
目录
1、urllib.parse.quote() 2、urllib.parse.urlencode()
'''
urllib库使用 python自己带的
使用urllib来获取百度首页的源码
1、定义一个url 就是你要访问的地址
'''
import urllib.request
url = 'http://www.baidu.com'
# 2、模拟浏览器项服务器发送请求
# 请求要打开的url
response = urllib.request.urlopen(url)
# 3、获取响应中的页面的源码
# read() 返回的是字节形式的二级制数据 所以要将二进制数据转换成字符串的形式 如何转换 👇👇👇👇
# 将二级制的数据转换成字符串 二进制-》字符串 解码 decode('编码的形式/格式')
content = response.read().decode('utf-8')
# 4、打印数据
print(content)一个类型 六个方法
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response 是HTTPResponse的类型
# 1、read方法 是按照一个字节一个字节去读
# content = response.read()
# content = response.read(5) 里面的这个数字 代表的是读/返回多少个字节
# 2、按行读 只读一行 readline()
# content = response.readline()
# print(content)
# 3、radelines() 一行一行的读 直到读完为止
# 4、获取状态码 response.getcode()
# print(response.getcode())
# 5、返回url地址 response.geturl()
# 6、返回状态信息 请求头 response.getheaders()
import urllib.request
# 下载网页
# url_page = 'http://www.baidu.com'
# #urlretrieve(url,filename) url 是下载的路径 filename是文件的名字
# urllib.request.urlretrieve(url_page,'baidu.html')
# 下载图片
# url_image = 'https://img1.baidu.com/it/u=1021065414,520197269&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=500'
# urllib.request.urlretrieve(url_image,'lisa.jpg')
# 下载视频 后缀一般是.mp4
# url_redio = ''
# urllib.request.urlretrieve(url_redio,'xxx.mp4')
UA反扒
识别不了你是真正的浏览器 所以要加上一个user-agent

因为urlopen()不能识别字典类型的数据
只能识别字符类型或者是request对象的数据
所以要把字典类型的数据进行---请求对象定制
代码 response = urllib.request.Request(xxx) 在进行请求对象定制的时候 一定要使用关键字传参,因为顺序传参,形参实参对应的顺序位置可能不同,导致报错,所以要使用顺序传参。
请求对象定制之后再打开url
'''
# url 的组成
协议 http/https 主机 端口号
'''
import urllib.request
url = 'https://www.baidu.com'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}
# 因为urlopen方法中不能存放字典 所以header中不能传递进去
# 所以要请求对象的定制
# 注意 : 因为参数顺序的问题,不能直接写url和headers 中间还有data,所以我们需要关键字传参
# def __init__(self, url, data=None, headers={}) 这个Request中间还有一个data 不能顺序传参
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)请求对象定制 是为了应对UA反扒的手段
编解码
get请求方式
1、urllib.parse.quote() 2、urllib.parse.urlencode()
quote方法
如果在使用爬虫的过程中出现了ascii编码报错,需要将汉字等变成unicode编码格式
import urllib.parse
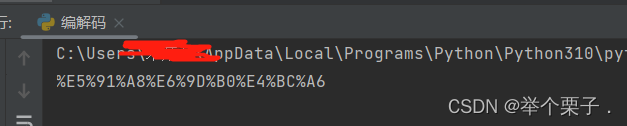
name = urllib.parse.quote('周杰伦') # 这段代码能将汉字变成unicode编码打印结果为
# 获取
# https://www.baidu.com/s?ie=UTF-8&wd=周杰伦的网页源码
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象定制
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}
# 将周杰伦三个字变成unicode编码的格式 需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦') # 这段代码能将汉字变成unicode编码
url = url + name
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# print(response)
# 获取相应内容
content = response.read().decode('utf-8')
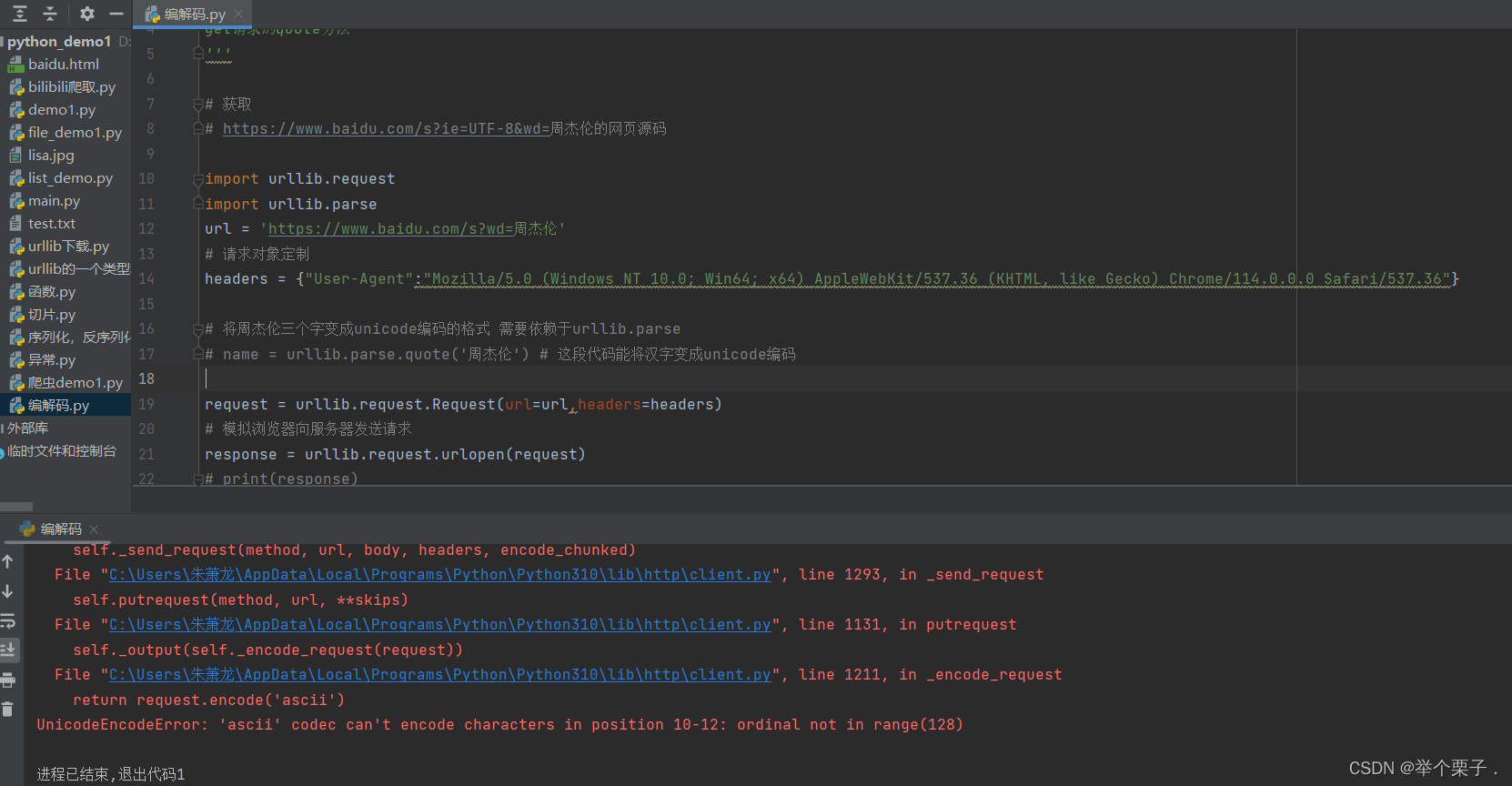
print(content)请求之后返回的是百度的安全验证
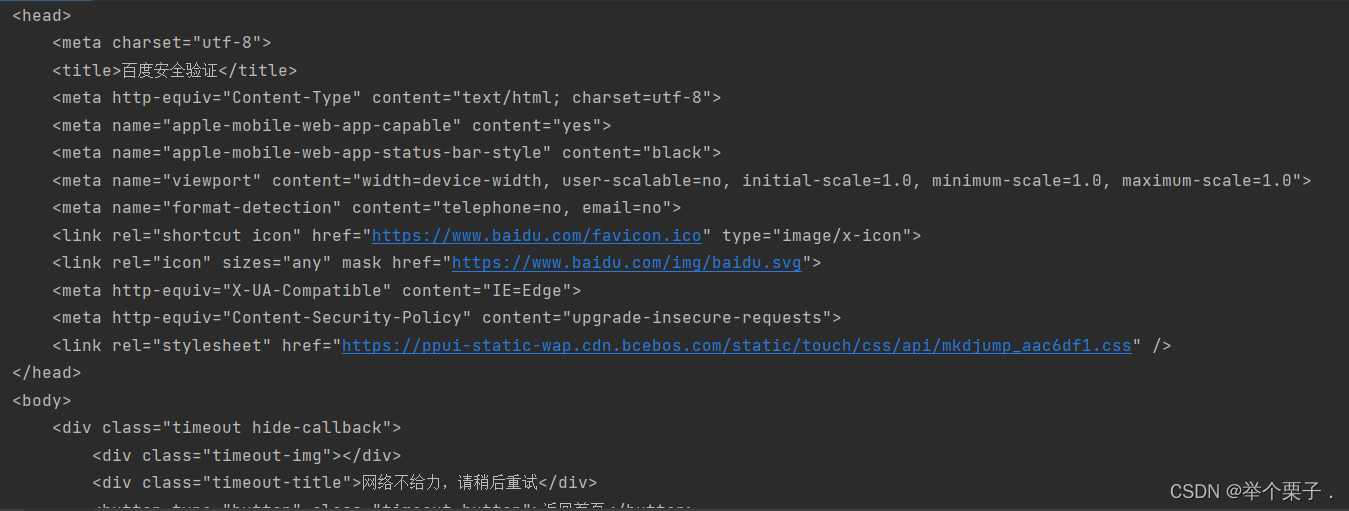
不知道为什么跟视频里面讲的不一样,是百度反扒加强了么???有知道的小伙伴可以给我留个言
urlencode 方法 可以将多个参数进行拼接
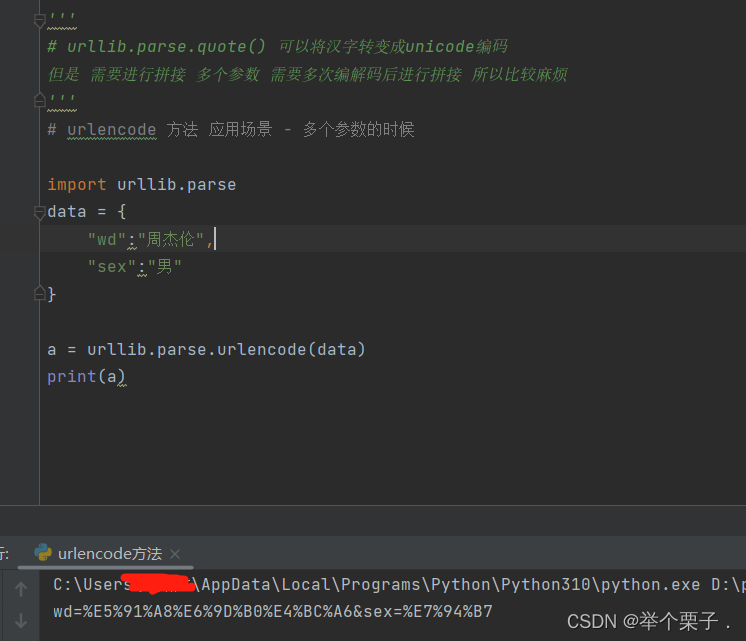
'''
# urllib.parse.quote() 可以将汉字转变成unicode编码
但是 需要进行拼接 多个参数 需要多次编解码后进行拼接 所以比较麻烦
'''
# urlencode 方法 应用场景 - 多个参数的时候
import urllib.request
import urllib.parse
base_url = "https://www.baidu.com/s?"
data = {
"wd":"周杰伦",
"sex":"男",
"location":"中国台湾省"
}
new_data = urllib.parse.urlencode(data)
url = base_url + new_data
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}
# 请求对象定制
request = urllib.request.Request(url=url,headers=headers)
# 把定制完了的数据 向浏览器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码数据
content = response.read().decode('utf-8')
print(content)当前小结 请求数据定制 + 编解码encode + 请求数据 👆👆👆👆
post请求方式
post 请求的时候 请求参数是放在请求体里面的 不是拼接在url后面的
所以用post请求方式的时候 需要进行编码 + 请求对象定制
import urllib.request
import urllib.parse
url = "https://fanyi.baidu.com/sug"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
data = {
"kw":"spider"
}
data = urllib.parse.urlencode(data).encode('utf-8')
# post请求的数据 必须要进行编码 encode 是进行编码的 decode是进行解码的
# 请求对象定制
request = urllib.request.Request(url=url,data=data,headers=headers)
# post 请求的参数 必须要进行编码 post 请求的参数是不混拼接在url后面的 而是需要放在请求对象定制的参数当中
# 模拟浏览器向服务器发送请求
responst = urllib.request.urlopen(request)
content = responst.read().decode("utf-8")
print(content)这样pring出来的是一个json数据对象

所以需要将所得的数据进行反序列化处理
json.loads() 将字符串 处理成json对象
import urllib.request
import urllib.parse
url = "https://fanyi.baidu.com/sug"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
data = {
"kw":"spider"
}
data = urllib.parse.urlencode(data).encode('utf-8')
# post请求的数据 必须要进行编码 encode 是进行编码的 decode是进行解码的
# 请求对象定制
request = urllib.request.Request(url=url,data=data,headers=headers)
# post 请求的参数 必须要进行编码 post 请求的参数是不混拼接在url后面的 而是需要放在请求对象定制的参数当中
# 模拟浏览器向服务器发送请求
responst = urllib.request.urlopen(request)
content = responst.read().decode("utf-8")
# print(content)
#
import json
print(json.loads(content))
'''
1、post 请求方式的参数 必须要编码 data = urllib.parse.urlencode(data)
编码之后 必须要调用encode方法 data = urllib.parse.urlencode(data).encode('utf-8')
2、参数是放在请求对象定制的方法中 request = urllib.request.Request(url=url,data=data,headers=headers)
'''反序列化处理后的json对象

import urllib.request
import urllib.parse
import json
url = "https://fanyi.baidu.com/v2transapi?from=en&to=zh"
headers = {
# 'Accept':'*/*',
# 'Accept-Encoding':'gzip, deflate, br',
# 'Accept-Language':'zh-CN,zh;q=0.9',
# 'Acs-Token':'1689079671703_1689079676313_c0R6pqMcj/CLy2J1UtOcO9Jq0lF5LKqbntNHyG7yiHGVHICTDOiBnX9XsWya/F6C+akhCChRQ0twgO3rFbehJazy30cqavTgUA6q3sLcyXztw20D74U7tQsk772OckE1iXTQuEK6rrlR2nu55FAaX3WLYgvvN0tZtps++SDR59t4ENu0C9ajtQKAjRlCbHXtoIjxZOQWKCXMXZd04AK8G7zIPu5WUDtJ/9tMY8p6ekJzYNPBCJVFoff7rFYZzypwEQHruyxG5Rl7oA15vHabEJxQufyunJJD9yf72LnkutKSQt1vmUW4WmmF0Xn7sIP6scKZgJw2lLoTGVeJX8RSncu8YJ/nAou5EIQt/c6jP0xslRBTaTrnrdqrs9bxsLqZ2gfPzLEenclJxV42kRcfmFHpIpXB2Uu0tATNimWSxGksvIPiw4thjGT75H4GtxR+Fq/gceD31dedYYsN6slgnoDuqT5HBfEmm0RFJi/fbQg=',
# 'Connection':'keep-alive',
# 'Content-Length':'152',
# 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'BIDUPSID=E13EFDCB41419228E81C1E955CFB1A2A; PSTM=1663555873; BAIDUID=E13EFDCB4141922811AB5CDB8A5060D4:FG=1; BDUSS=BuYkpab0N4ZVBPeUVsbmFNVnhscWh4eEI2WGdDQ1F1RHN1aGQybktLemptbXRqRVFBQUFBJCQAAAAAAAAAAAEAAABXmg-mzMbDxcenytYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOMNRGPjDURjej; BDUSS_BFESS=BuYkpab0N4ZVBPeUVsbmFNVnhscWh4eEI2WGdDQ1F1RHN1aGQybktLemptbXRqRVFBQUFBJCQAAAAAAAAAAAEAAABXmg-mzMbDxcenytYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOMNRGPjDURjej; H_WISE_SIDS=110085_204919_209307_211986_213032_213358_214802_215730_216847_219623_219943_219946_222216_222624_224267_226628_227870_228650_229154_229966_230584_230930_231979_232247_232356_232628_232777_233671_234044_234050_234208_234295_234426_234725_234835_234924_235174_235200_235442_235473_235512_235545_235979_236237_236242_236308_236515_236536_236614_236811_237240_237308_237837_237962_238203_238226_238313_238411_238506_238515_238629_238755_238804_238958_238961_239007_239098_239102_239281_239500_239540_239604_239705_239760_239875_239898_239948_240034_240225_240305_240342_240397_240408_240447_240592_240597_240649_240661_240783_240847_240890_241044_241048_241153_241177_241207_241232_241297_241326_241347_241433; H_WISE_SIDS_BFESS=110085_204919_209307_211986_213032_213358_214802_215730_216847_219623_219943_219946_222216_222624_224267_226628_227870_228650_229154_229966_230584_230930_231979_232247_232356_232628_232777_233671_234044_234050_234208_234295_234426_234725_234835_234924_235174_235200_235442_235473_235512_235545_235979_236237_236242_236308_236515_236536_236614_236811_237240_237308_237837_237962_238203_238226_238313_238411_238506_238515_238629_238755_238804_238958_238961_239007_239098_239102_239281_239500_239540_239604_239705_239760_239875_239898_239948_240034_240225_240305_240342_240397_240408_240447_240592_240597_240649_240661_240783_240847_240890_241044_241048_241153_241177_241207_241232_241297_241326_241347_241433; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; ZFY=rhVTfWeL2QEGJe:BTJ6aUXyQZbAj3:BAGNR:AyreanqiLI:C; BAIDUID_BFESS=E13EFDCB4141922811AB5CDB8A5060D4:FG=1; BA_HECTOR=212121al0k0k2h0480ak202f1iao4hb1o; delPer=0; PSINO=2; H_PS_PSSID=36549_38642_38831_39025_39024_38958_38920_38973_38807_38637_26350_39051_38950; BCLID=11150408007204506758; BCLID_BFESS=11150408007204506758; BDSFRCVID=pxtOJexroG0ZmSbfGtjrbZ8xeuweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKymOTHrIF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BDSFRCVID_BFESS=pxtOJexroG0ZmSbfGtjrbZ8xeuweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKymOTHrIF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tJkD_I_hJKt3j45zK5L_jj_bMfQE54FXKK_sbP0EBhcqEn6S0x7OeM4Bb4JJblTayJbO0R6cWKJJ8UbSh-v_hl_LMbAjLnDL02JpaJ5nJq5nhMJmb67JDMP0-4jnQpjy523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0DjJbDHKHJjna--oa3RTeb6rjDnCrKb7MXUI82h5y05OzaG7a0q322toDoCn9bJobbfbW-RORXRj4B5vvbPOMthRnOlRKQ4QOQxL1Db3Jb5_L5gTtsx8-Bh7oepvo2tcc3MkXytjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjW6LEK5r2SCD-fCbP; H_BDCLCKID_SF_BFESS=tJkD_I_hJKt3j45zK5L_jj_bMfQE54FXKK_sbP0EBhcqEn6S0x7OeM4Bb4JJblTayJbO0R6cWKJJ8UbSh-v_hl_LMbAjLnDL02JpaJ5nJq5nhMJmb67JDMP0-4jnQpjy523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0DjJbDHKHJjna--oa3RTeb6rjDnCrKb7MXUI82h5y05OzaG7a0q322toDoCn9bJobbfbW-RORXRj4B5vvbPOMthRnOlRKQ4QOQxL1Db3Jb5_L5gTtsx8-Bh7oepvo2tcc3MkXytjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjW6LEK5r2SCD-fCbP; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1689079656; APPGUIDE_10_6_2=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1689079669; ab_sr=1.0.1_MmZjNmJlNjMzZjlhODU1MTRiNzY2YTdmZWFjYjEwYmJjOTViOThkYzg5NjQxOTk5YTFkM2MzMDBkNDZjMGJmODZiY2ZkNTI0ZjVlNzE3MjEzODRmZGIwMTkwMTJlYjFjNDVmN2JmZmZjN2UxM2Y2MzRhNjdjMDg4M2Q1ODgyZTAyYjc0OThiNTUyMjg3OTdkZWU0NTNiYTNjZTQzNDVlYTQzMGQ2ZDIwNTFjNTA3N2RlYWM1ZDg2NzFhYzRkMjU3',
# 'Host':'fanyi.baidu.com',
# 'Origin:https': '//fanyi.baidu.com',
# 'Referer:https': '//fanyi.baidu.com/?aldtype=16047',
# 'Sec-Ch-Ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
# 'Sec-Ch-Ua-Mobile': '?0',
# 'Sec-Ch-Ua-Platform': '"Windows"',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
data = {
'from':'en',
'to':'zh',
'query':'love',
'transtype':'realtime',
'simple_means_flag':'3',
'sign':'198772.518981',
'token':'6e56e770d910a05c7186939b24c511ef',
'domain':'common',
}
# post请求需要进行编码 然后在使用encode
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象定制
request = urllib.request.Request(url = url,data = data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
content = response.readline().decode('utf-8')
# print(content)
print(json.loads(content))ajax - 练习-爬取豆瓣电影 -get请求
# get 请求
# 获取豆瓣电影第一页的数据 并且保存起来
import urllib.request
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
# 请求方法定制
request = urllib.request.Request(url=url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
f = open('douban.json','w')
f.write(content)这样运行程序会出现👇👇👇

open() 方法默认的编码格式是gbk 但是我们获取数据的编码格式是utf-8 如果我们想要保存汉字,就需要把open()的编码格式变成utf-8
# get 请求
# 获取豆瓣电影第一页的数据 并且保存起来
import urllib.request
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
# 请求方法定制
request = urllib.request.Request(url=url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
f = open('douban.json','w',encoding='utf-8')
f.write(content)
这样程序就运行起来,并且获得到的数据能够写入文件当中
爬取豆瓣电影 - 封装函数 -get请求
# @Time
'''
下载豆瓣电影前10页的数据
1、请求对象的定制
2、获取相应的数据
3、下载数据
'''
import urllib.parse
import urllib.request
def create_request(page):
base_url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
data = {
"start": (page - 1) * 20,
"limit": 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
request = urllib.request.Request(url = url,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
print(content)
return content
def down_load(content,page):
f = open('douban' + str(page) + '.json','w',encoding='utf-8')
f.write(content)
# 程序的入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页码'))
for page in range(start_page,end_page+1): # range函数 左闭右开
#每一页都有自己请求对象的定制
request = create_request(page)
# 获取相应的数据
content = get_content(request)
# # 下载数据
down_load(content,page)
ajax - post请求
# @Time
'''
post 请求 爬取肯德基北京地址
'''
import urllib.request
import urllib.parse
def get_request(page):
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
data = {
'cname': '北京',
'pid': '',
'pageIndex': page,
'pageSize': '10',
}
# post 请求必须要编码,并且还要用encode()
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url,data=data,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content,page):
f = open('KFC'+str(page)+'.json', 'w', encoding='utf-8')
f.write(content)
if __name__ == '__main__':
start_pahe = int(input('请输入开始地址'))
end_pahe = int(input('请输入结束地址'))
for page in range(start_pahe, end_pahe + 1):
request = get_request(page)
content = get_content(request)
down_load(content,page)get和post的区别:
get请求 需要进行url拼接 需要使用urlencode()之后 与url进行拼接 然后进行请求对象定制,get对象不需要传递data
post 在请求对象定制的时候 需要传递 data参数,并且post的请求参数存于请求体中,不需要进行url拼接
Cookie
# @Time
'''
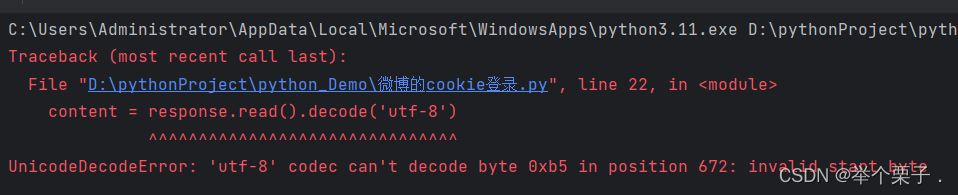
适用的场景,数据采集的时候,需要绕过登录,然后进入到某个页面
个人信息页面是utf-8 但是还是报了编码错误,因为并没有进入到个人信息页面,而是跳转到了登陆页面
登录页面的编码格式不是utf-8所以报错了
什么情况下访问不成功
大部分情况下 是因为请求头的信息不够 所以访问不成功
'''
import urllib.request
url = 'https://weibo.cn/7532959874/info'
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control':'max-age=0',
'Cookie':'SCF=AjXvBcUFQfgiNy-pVJOCQZjjIraJSLOouY-TVIpwCvyeBDgRE9k8191wy2euTBDP-3w6RoNf03cVM6wWVek3Fkw.; SUB=_2A25JqiGjDeRhGeFL6FAY9SfEzDiIHXVrVU_rrDV6PUNbktANLVXfkW1NQjoJCSCp98J6ctSGy8Yf7k2vaHP4eajR; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF_pyxfwYsSzugCfGP0Sfpw5JpX5KMhUgL.FoMfe0z4SK.RS0B2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMNSKeE1K-41hMX; SSOLoginState=1689145843; ALF=1691737843; _T_WM=ea2bb2192d6cce93f0a182820ed8a558',
'Sec-Ch-Ua':'"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'Sec-Ch-Ua-Mobile':'?0',
'Sec-Ch-Ua-Platform':'"Windows"',
'Sec-Fetch-Dest':'document',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'same-origin',
'Sec-Fetch-User':'?1',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
with open('weibo.htm','w',encoding='utf-8') as f:
f.write(content)
下面的运行结果是只进行了UA反扒的结果,只有User-Agent,没有其他的请求头参数
爬取个人详情页时,个人信息页面是utf-8 但是还是报了编码错误,因为并没有进入到个人信息页面,而是跳转到了登陆页面,登录页面的编码格式不是utf-8所以报错了
携带了cookie参数之后运行成功

起到主要作用的是cookie 里面包含着登录信息
referer 是防盗链 用来判断你当前的页面是否是从上一个页面进入的,一般用于图片的防盗
handler处理器

# @Time
# 使用handler来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# 1、获取handler对象
handler = urllib.request.HTTPHandler()
# 2、通过handler获取opener对象
opener = urllib.request.build_opener(handler)
# 3、调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)代理
可以改变请求的ip
# @Time
import urllib.request
url ='https://www.baidu.com/s?wd=ip'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie":'BIDUPSID=D9CD4E7F2D134EAC1A44227D8D90D05D; PSTM=1688002559; BAIDUID=D9CD4E7F2D134EACB0C8F1FF06C3E0A3:FG=1; BD_UPN=12314753; MCITY=-287%3A; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=D9CD4E7F2D134EACB0C8F1FF06C3E0A3:FG=1; ZFY=302drzdBxDc:Btg9BAou999hAIq4Ihi1oBKAI:BgCVsSg:C; RT="z=1&dm=baidu.com&si=184d4fb8-d21d-413e-83b5-6638c27ebc16&ss=ljxxx2fo&sl=4&tt=78v&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=6z9w&nu=1bk03f1ow&cl=6vi0&ul=73r0&hd=73tp"; B64_BOT=1; BDUSS=ZNMlRiN2VxYTFsZGE5QjJwUk1ORnV5NEJpTzMwYmZFeVNtZnVCdzVZSXhqdFZrRUFBQUFBJCQAAAAAAAAAAAEAAADtK3~xc2tkbnhiaGh6AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADEBrmQxAa5kb3; BDUSS_BFESS=ZNMlRiN2VxYTFsZGE5QjJwUk1ORnV5NEJpTzMwYmZFeVNtZnVCdzVZSXhqdFZrRUFBQUFBJCQAAAAAAAAAAAEAAADtK3~xc2tkbnhiaGh6AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADEBrmQxAa5kb3; BD_HOME=1; delPer=1; BD_CK_SAM=1; PSINO=5; shifen[2087047_91638]=1689125703; BCLID=10937604700000933348; BCLID_BFESS=10937604700000933348; BDSFRCVID=jA4OJexroG0ZmSbfGC6aUT2_5_weG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKymOTHrIF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BDSFRCVID_BFESS=jA4OJexroG0ZmSbfGC6aUT2_5_weG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKymOTHrIF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tRAOoC_-tDvDqTrP-trf5DCShUFsaf_JB2Q-XPoO3KJADfOPbxJTj4_A3a5dtlRf5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRih4r9QgbHalQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjA2D5oP; H_BDCLCKID_SF_BFESS=tRAOoC_-tDvDqTrP-trf5DCShUFsaf_JB2Q-XPoO3KJADfOPbxJTj4_A3a5dtlRf5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRih4r9QgbHalQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjA2D5oP; COOKIE_SESSION=9295_0_3_4_8_11_0_0_1_3_0_0_9295_0_1_0_1689142486_0_1689142485%7C9%230_0_1689142485%7C1; BA_HECTOR=2l24052ha42l202hah0l04201iaskb61p; H_PS_PSSID=36555_38643_39026_39023_38943_38958_38954_38985_38965_38916_38973_38820_39066_38988_26350; sugstore=0; H_PS_645EC=9804RiskFmI1bpRDQXXG%2BZP4OtvdsbTq7vAw6668czRXcqdvJAZlEcYNLZY'
}
request = urllib.request.Request(url=url,headers=headers)
# 代理
proxies = {
'http':'118.24.219.151:16817'
}
# response = urllib.request.urlopen(request)
# handler处理器 handler build_open open
handler = urllib.request.ProxyHandler( proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
f = open('baiduText.htm','w',encoding='utf-8')
f.write(content)
代理池
# @Time
# 使用代理池
import random
import urllib.request
url ='https://www.baidu.com/s?wd=ip'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
}
proxies_pool = [
{'http': 'http://127.0.0.1:8888'},
{'https': 'http://127.0.0.1:8821'}
]
proxies = random.choice(proxies_pool)
request = urllib.request.Request(url=url,headers=headers)
# 想用代理 必须用handler处理器
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode("utf")
print(content)
解析
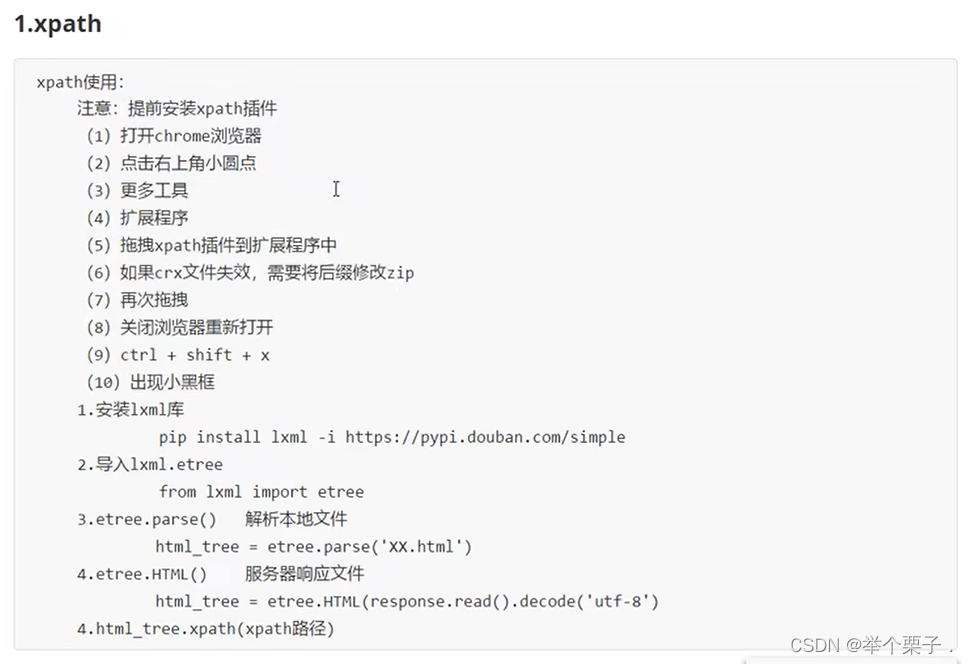
xpath 获取本地数据
首先引入etree
from lxml import etree
// 然后 解析本地文件
tree = etree.parse("xxxxxx")
// 语法查询
list = tree.xpath('xxxxxx')
# @Time
'''
获取网页源码中部分数据的一种方式 xpath
xpath 解析的两种方式
1、本地文件解析
解析本地文件 用的是etree.parse('xxx.html')
2、直接解析服务器响应文件 response.read().decode('utf-8')
解析服务器相应文件 用的是etree.HTML()
'''
from lxml import etree
# xpath 解析本地文件
tree = etree.parse("解析-xpath的基本使用.html")
print(tree)
'''
xpath 的基本语法
tree.xpath('xpath的路径')
'''

from lxml import etree
'''
解析本地文件
etree.parse
解析服务器相应的数据
response.read().decode('utf-8')
'''
# xpath 解析本地文件
tree = etree.parse('解析-本地文件.html')
'''
xpath的基本语法
tree.xpath('xpath路径')
1.路径查询
// : 查找所有子孙节点,不考虑层级关系
/ : 找直接子节点
2.谓词查询
//div[@id]
//div[@id="xxxxxx"]
3.属性查询
//@class
4.模糊查询
//div[contains(@id,"he")]
//div[starts-with(@id,"he")]
5.逻辑运算
//div[@id="head" and @class="s_down"]
//title | //price
'''
# 1、查找ul下面的li
# li_list = tree.xpath('//body//ul//li')
# print(li_list)
# 2、查找带有id属性的li标签 text()是获取标签中的内容
# li_list = tree.xpath("//body//ul/li[@id]/text()")
# print(li_list)
# 3、找到id为l1的id标签
# li_list = tree.xpath("//ul/li[@id='l1']/text()")
# print(li_list)
# 4、属性查询
# li_list = tree.xpath("//ul/li/@class")
# print(li_list)
#5 模糊查询 查询id中包含li的标签
# li_list = tree.xpath("//ul/li[contains(@id,'l')]/text()")
# print(li_list)
# start-with 以。。为开头
# 6.查询id值以l开头的li标签
# li_list = tree.xpath("//ul/li[starts-with(@id,'l')]/text()")
# print(li_list)
#7.逻辑运算 查询id为l1 和class为c3的
# li_list = tree.xpath("//ul/li[@id='l1' and @class='c3']/text()")
# print(li_list)
# 或
li_list = tree.xpath("//ul/li[@id='l1']/text() | //ul/li[@id='l2']/text()")
print(li_list)xpath获取服务器响应的数据
获取服务器相应的数据
1、先请求服务器,获取服务器响应的数据
import urllib.request
url = "xxxxxx"
header = {选填,没有UA校验就不用填,填不填都行}
// 填的话就需要 请求对象的定制
request = uellib.request.Request(url=url,headers=headers)
// 向服务器发起请求
response = urllib.request.urlopen(request)
// 获取响应数据
content = response.read().decode('utf-8')
// 蓝后。。。蓝后
解析服务器响应的数据
from lxml import etree
tree = etree.HTML(content)
list = tree.xpath('xxxxxx')
print(list)
============== 流程结束 ==============
'''
1、获取网页的源码
2、解析 解析的服务器相应的文件 etree.HTML
3、打印
'''
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器访问服务器
response = urllib.request.urlopen(url)
# 获取网页源码
content = response.read().decode('utf-8')
# print(content)
# 解析网页源码,来获取我们想要的数据
from lxml import etree
# 解析服务器相应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath 的返回值是一个列表类型的数据
result = tree.xpath("//input[@id='su']/@value")[0]
print(result)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









