






 文章探讨了内存与磁盘I/O的关系,重点介绍了数据库中的聚簇索引和非聚簇索引,解释了它们的物理存储、更新操作影响以及查询性能差异。通过优化I/O操作和利用多叉树结构提升查询效率。
文章探讨了内存与磁盘I/O的关系,重点介绍了数据库中的聚簇索引和非聚簇索引,解释了它们的物理存储、更新操作影响以及查询性能差异。通过优化I/O操作和利用多叉树结构提升查询效率。
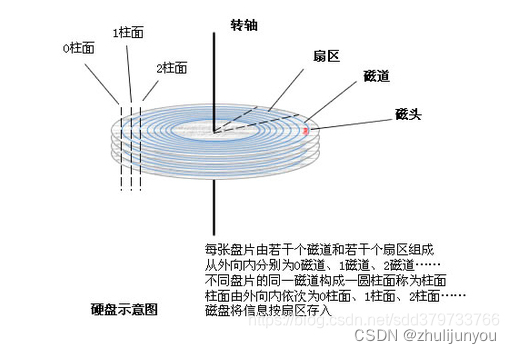
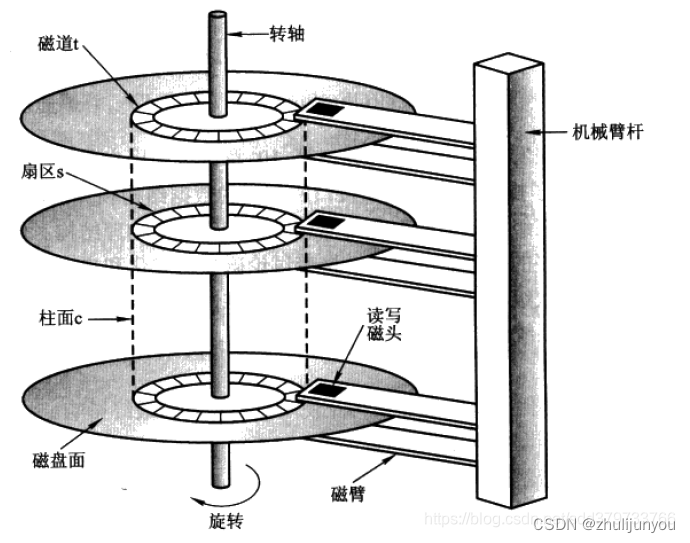
计算机对内存比磁盘的读写速度要快很多,但内存容量要远小于磁盘,而数据、程序的执行要调入内存后才能执行,所以内存和磁盘要经常进行I/O操作,I/O操作是个费事的过程,虽然现代系统已经有了通道(I/O处理机)技术的支持,但这远远不够(CPU的处理速度远远大于磁盘I/O的速度)
当计算机需要读取磁盘数据时,首先会检查磁盘缓存中是否已经存在所需数据,如果存在,则直接从缓存中读取数据,避免磁盘寻道时间的浪费。如果缓存中不存在所需的数据,则会从磁盘中读取,并将相邻的数据一起预读到缓存中,已备后续使用。聚簇索引利用这个原理,尽可能多的利用磁盘的IO,让一次IO能够获取更多的有效数据
mysql索引按照物理分类可分为聚簇索引 和 非聚簇索引
聚簇索引
将数据存储与索引放到了一块,找到索引也就找到了数据,索引结构的叶子节点保存了行数据(一个表中只有一个聚簇索引)。
在Innodb引擎中,聚簇索引默认就是主键索引,如果表中没有定义主键,那么该表的第一个唯一非空索引被作为聚集索引。如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。查询数据时,要先把磁盘中的数据加载到内存里,然后再经过逻辑处理,返回给用户结果。其中磁盘IO操作是非常耗时的,我们查询效率的重点就是尽量减少磁盘IO操作。
InnoDB引擎一次IO会读取的一页数据(page 默认一页16K),而二叉树一次IO有效数据量只有16字节,空间利用率极低。为了最大化利用一次IO空间,一个简单的想法是在每个节点存储多个元素,在每个节点尽可能多的存储数据。每个节点可以存储1000个索引(16k/16=1000),这样就将二叉树改造成了多叉树,通过增加树的叉树,将树从高瘦变为矮胖。构建1百万条数据,树的高度只需要2层就可以(1000*1000=1百万),也就是说只需要2次磁盘IO就可以查询到数据。磁盘IO次数变少了,查询数据的效率也就提高了。
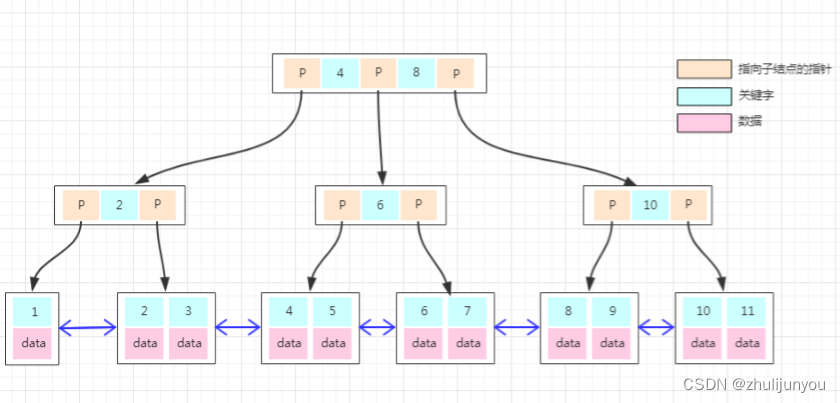
因为聚簇索引在物理地址上是连续的,所以有时候若想要向已经连续存在的一组数据中新插入数据,则可能会耗费更大的资源(类似 向list 中间添加数据),需要把已经写到磁盘的数据读出来重新排序在写进去。若果已经写到磁盘的数据不是完全连续,中间有间隙,则可以避免这种情况发生(通常情况下msyql有自己的算法)
非聚簇索引
将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置;
非聚集索引可以提高查询效率,且对数据表的插入、删除和更新操作的影响较小,因此在实际应用中,根据查询和修改操作的特点,结合查询和修改操作的比重及数据表的大小等因素,可以考虑使用非聚集索引来优化数据库性能。
聚簇索引的非聚簇索引的区别
物理存储方式不同:
聚簇索引数据行的物理存储顺序连续,每张表只能有一个聚簇索引;非聚簇索引数据行的物理存储顺序与索引排序顺序无关,每张表可以有多个非聚簇索引。
更新,插入,删除操作时的影响不同:
聚簇索引,由于数据行的物理存储顺序连续,因此在进行插入、删除和更新操作时可能需要对数据行的物理位置进行调整,这会对性能造成一定的影响。非聚簇索引,它只存储了索引值和记录指针之间的映射关系,因此在进行插入、删除和更新操作时,只需要修改非聚集索引中的映射关系即可,对数据表的性能影响相对较小。
查询时的性能不同:
聚簇索引可以直接定位到数据行,因此在查询单条记录时有较好的性能表现。而非聚簇索引需要先定位到索引,然后再通过记录指针查找数据行,因此在查询多条记录时会有一定的性能损失。

















 5918
5918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









