







 本文深入探讨了神经网络中常见的激活函数,包括二分类问题中的sigmoid函数和多分类问题中的softmax函数。详细解析了这两种函数的工作原理,以及如何在梯度下降过程中进行推导。适合对深度学习和神经网络感兴趣的读者。
本文深入探讨了神经网络中常见的激活函数,包括二分类问题中的sigmoid函数和多分类问题中的softmax函数。详细解析了这两种函数的工作原理,以及如何在梯度下降过程中进行推导。适合对深度学习和神经网络感兴趣的读者。
目录
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~
花书+吴恩达深度学习(一)前馈神经网络(多层感知机 MLP)
花书+吴恩达深度学习(二)非线性激活函数(ReLU, maxout, sigmoid, tanh)
0. 前言
在神经网络的输出单元,通常采用与隐藏单元不同的激活函数。
二分类中,通常采用 sigmoid 函数:
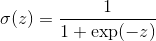
多分类中,通常采用 softmax 函数:
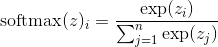
1. 二分类 sigmoid
在二分类中,最后一层网络仅有一个单元:
![\begin{align*} & Z^{[L]}=W^{[L]}A^{[L-1]}+B^{[L]} \\ & A^{[L]}=\sigma(Z^{[L]}) \end{align*}](https://i-blog.csdnimg.cn/blog_migrate/e31d4d3da94eab896c8a6bc6fed84c41.png)
因为 sigmoid 的值域为 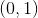 ,所以最后一个单元表示输出正类(反类)的概率。
,所以最后一个单元表示输出正类(反类)的概率。
在使用梯度下降时:
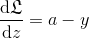
详细的推导可以移步我的博客。
2. 多分类 softmax
在多分类中,最后一层网络有 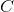 个单元( 表示类别数量):
个单元( 表示类别数量):
![\begin{align*} & Z^{[L]}=W^{[L]}A^{[L-1]}+B^{[L]} \\ & A^{[L]}_i=\frac{\exp(Z^{[L]}_i)}{\sum_{j=1}^C\exp(Z^{[L]}_j)} \end{align*}](https://i-blog.csdnimg.cn/blog_migrate/f35208ae8cc85e9940dc53b128e26efc.png)
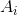 为最后一层网络第
为最后一层网络第 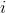 个单元的输出,这使得最后一层网络总和为
个单元的输出,这使得最后一层网络总和为 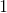 。
。
数值最大的单元,为最终类别,我们将类别向量化:
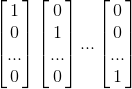
3. 多分类 softmax 梯度下降推导
在使用梯度下降时,与 sigmoid 相同,可以看作是 sigmoid 的多分类版本:
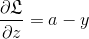
使用对数最大似然定义代价函数:
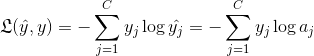
根据链式求导法则,梯度下降表示为:
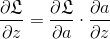
第一项的求导:
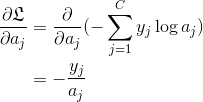
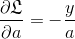
第一项的导数是一个 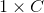 的向量:
的向量:
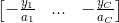
第二项的求导:
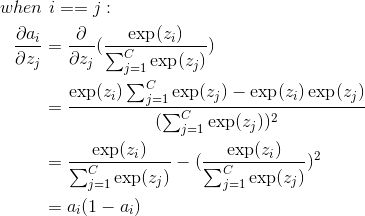
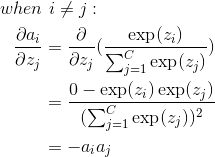
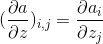
第二项的导数是一个  的 Jacobian 矩阵:
的 Jacobian 矩阵:
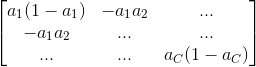
综上所述:
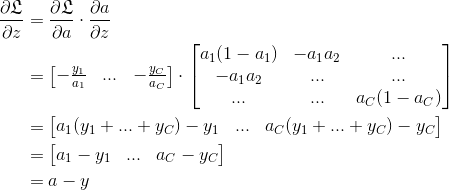
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









