






 本文详细介绍了使用Scrapy框架进行网站爬虫的全过程,包括项目的创建、定义item、编写spider以及数据的提取与保存。通过实例展示了如何从指定网站抓取新闻标题、链接和描述,并将数据存储至数据库。
本文详细介绍了使用Scrapy框架进行网站爬虫的全过程,包括项目的创建、定义item、编写spider以及数据的提取与保存。通过实例展示了如何从指定网站抓取新闻标题、链接和描述,并将数据存储至数据库。
创建一个scrapy 项目
定义提取的item
编写网站的spider 并提取item
提取数据保存到数据库
#创建项目 scrapy startproject bmlink
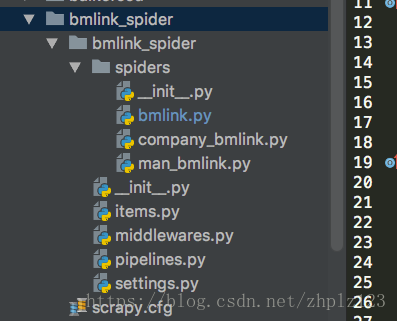
![会显示这样的,scrapy.cfg :项目的配置文件
bmlink :python 模块
items.py item 文件
pipelines.py 管道
#定义item
保存爬取数据的容器
import scrapy
class BmlinkSpiderItem(scrapy.Item):
title = scrapy.Field()
source_url = scrapy.Field()
desc = scrapy.Field()
#编写第一个spider
import hashlib
import re
import scrapy
from urlparse import urljoin
from bnlink_spider.items import BmlinkSpiderItem
class BmlinkSpider(scrapy.Spider):
name = 'bmlink'
cate1_id =1
cate2_id = 6
source = '中国建材网‘
allowed_domains =['bmlink.com']
start_urls = ['https://www.bmlink.com/news/']
def start_requests(self):
for i in range(302):
url = "https://www.bmlink.com/news/list-10-%s.html' % (str(i+1))
if url is not None:
yield scrapy.Request(url,callback=self.parse2)
def parse2(self,response):
url = response.xpath('//*[@class="news_list2"]/ul/li/a[1]/@href').extract()
for i in url:
Item = BmlinkSpiderItem()
source_url = urljoin("https://www.bmlink.com/",i)
Item ['table_num'] = num
if source_url is not None:
yield scrapy.Request(
source_url,
callback= self.parse3,
meta ={'Item':Item}
)
def parse3(self, response):
'''详情页信息'''
if response.status == 200:
try:
title = response.xpath('//h1[@class="c_red"]/text()').extract()[0]
desc = response.xpath('//div[@class="newsinfo_cont"]').extract()[0]
pattern = re.compile(r'【<strong>.*?</strong>】')
desc = pattern.sub('', desc)
desc = re.compile(r'<img .*?>')
desc = pattern.sub('', desc)
print (desc)
print(title)
except:
title = None
desc = None
pass
if title !=None:
title = str(title).strip()
Item = response.meta["Item"]
Item["title"] = title
Item["desc"] = desc
Item["cate1_id"] = self.cate1_id
Item["cate2_id"] = self.cate2_id
Item["source"] = self.source
Item["industry"] = 1
yield Item


















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











