



 本文探讨了在面对千万级数据时,MySQL数据库设计中的范式与反范式策略。传统范式设计可能导致查询效率低下,而反范式设计虽然能提升查询速度,但会带来冗余字段和维护难题。另外,文章提到了使用Redis缓存和MySQL的JSON字段存储方案。通过为JSON字段创建虚拟字段并建立索引,可以兼顾查询效率与数据结构的灵活性。这种方法在大数据查询中具有一定的实用性。
本文探讨了在面对千万级数据时,MySQL数据库设计中的范式与反范式策略。传统范式设计可能导致查询效率低下,而反范式设计虽然能提升查询速度,但会带来冗余字段和维护难题。另外,文章提到了使用Redis缓存和MySQL的JSON字段存储方案。通过为JSON字段创建虚拟字段并建立索引,可以兼顾查询效率与数据结构的灵活性。这种方法在大数据查询中具有一定的实用性。
千万级数据:
一般mysql采用范式设计会把文库拆分成多张表,例如:
文库的基本信息:标题,发布时间
文库的类型,不同的文库类型对应的字段属性还不相同,这样在进行查询的时候需要写多条sql进行组合,查询效率不高,
采取方案:
1.采用反范式设计,把多张表合并成一张表(冗余表字段方式),不同类型的文库,读取的字段可能不一样,这种设计方式需要把文库的所有类型的字段都列出来
这种方式的优点:一张表查询速度很快
缺点:冗余字段很多,难以维护,当增加一个新的文库类型,会产生新的相关联字段,同时增加列还会锁表,所以也不可取
2.采用redis缓存所有的属性,这种方式需要采用多种属性维度建立对应的索引数据,比较麻烦
3.采用mysql json格式存储,mysql5.7.7之后的版本支持字段的格式为json,也就是把这些不确定的属性采用json的格式保存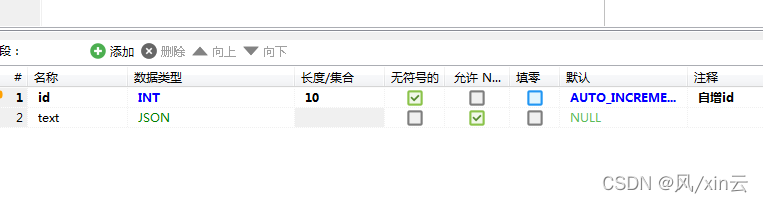
如上图为表结构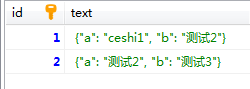
如上图所示的存储
插入数据的代码:#INSERT INTO test11(TEXT) VALUES('{"a":"测试2","b":"测试3"}')
进行json数据查询的时候需要如下方式
SELECT *, TEXT->'$.a' FROM test11 WHERE text->'$.a' = 'ceshi1';
text:字段,$.a是json里面的key:a
这种方式是用不到索引的,采用的是全表扫描,对于大数据量的查询速度是有很大影响
#ALTER TABLE test11
#ADD COLUMN `a` VARCHAR(32)
#GENERATED ALWAYS AS (JSON_UNQUOTE(json_extract(`text`,_UTF8MB4'$.a'))) VIRTUAL null
如上sql是给text字段里面的a绑定一个新的虚拟字段,这个字段在表结构里面是看不到的,sql查询可以看到,如果给这个虚拟字段建立索引就可以利用索引来查询了
CREATE INDEX index_a ON test11(a)
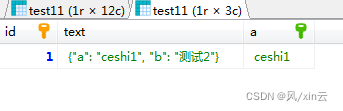

通过json字段方式解决了属性个数不固定的存储,通过给json字段里面的key绑定虚拟字段并给虚拟字段建立索引,解决了条件查询可以用上索引


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









