







离散特征处理
前面介绍了三种协同过滤召回,后面会介绍向量召回。在谈到向量召回之前,先熟悉一下离散特征的处理(ps:有机器学习基础的同学可以跳过本篇)
什么是离散特征
- 性别: 男,女
- 国籍:中国,美国,日本等
- 英文单词: 常见几万个
- 物品ID:电商平台有几亿个商品,每个商品有一个ID
- 用户ID:电商平台有几亿个用户,每个用户有一个ID
上述这些都是离散特征
离散特征处理
离散特征的处理分两步
-
建立字典:把类别映射为序号
-
中国 -> 1
-
美国 -> 2
-
日本 -> 3
-
-
向量化:把序号映射成向量,可采用以下方式
- One-hot编码:把序号映射成高维稀疏向量(比如有200个国家,每个国家被映射为一个200维的向量,序号对应的位置元素是1,其他位置均为0)
- Embedding :把序号映射成低维稠密向量(比如有200个国家,每个国家被映射成一个8维的稠密向量)
One-hot编码
例1 性别特征

例2 国籍特征

One-Hot编码的局限
比如,在自然语言处理中,对单词做编码
- 英文有几万个单词
- 则one-hot向量的维度是几万
又比如,电商推荐系统中,对物品ID做编码
- 电商平台有几亿个商品
- 则one-hot向量的维度是几亿
故在实践中,对于性别这种类别数量小适合用one-hot编码,但对于单词,物品Id这样的离散特征,其类别数量巨大,一般不用one-hot编码,而是用Embedding把每个类别映射成一个低维的稠密向量。
Embedding(嵌入)
在训练神经网络时,会自动做反向传播,学习embedding层的参数。
例1 对国籍做Embedding
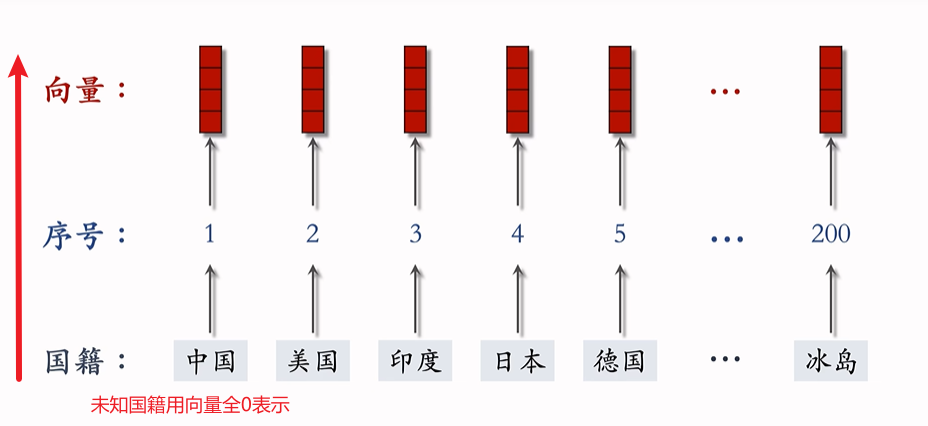
参数数量:向量维度 x 类别数量
参数矩阵:向量维度(行) x 类别数量(列),可理解为:类别数量个embedding向量
- 若embedding得到的向量是4维的
- 一共有200个国籍
- 参数数量 = 4 x 200 = 800
编程实现:Pytorch,TensorFlow提供的 embedding 层
-
embedding层参数是一个矩阵,矩阵大小是
向量维度(行) x 类别数量(列) -
embedding层输入是序号,比如“美国”的序号是2
-
embedding层输出是向量,比如“美国”对应参数矩阵的第2列
例2 物品ID的Embedding
前提如下:
- 数据库里一共有10,000部电影
- 设embedding向量的维度是16
- 你的任务是给用户推荐电影
请问Embedding层有多少参数? 16 x 10,000
- 参数数量 = 向量维度(行) x 类别数量(列) = 160,000
- 参数矩阵,16行 10000列,即10000个16维向量组合
如果类别数量不大只有几百万,这时Embedding层实现是比较容易的,pytorch和tensorFlow都能处理的很好。
但如果类别数量特别大(比如推荐系统中物品有几十亿),那么Embedding层特别大,一个神经网络绝大多数参数都在Embedding层。
工业界深度学习系统会对Embedding层做优化(这是存储和计算效率的关键)
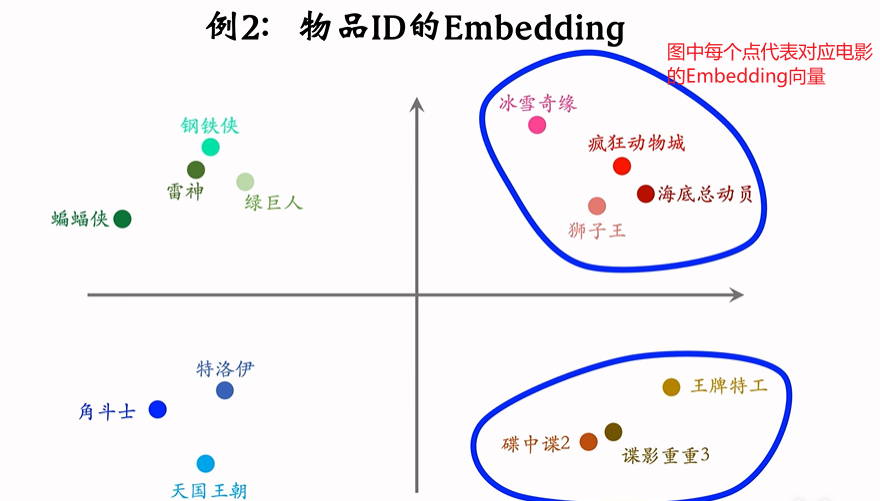
如上图,做的好的Embedding会让同类离得比较近,不同类离得比较远。比如冰雪奇缘,疯狂动物城二者都是动画片离得近;冰雪奇缘是动画片,碟中谍是谍战片二者类别不同所以离得比较远。
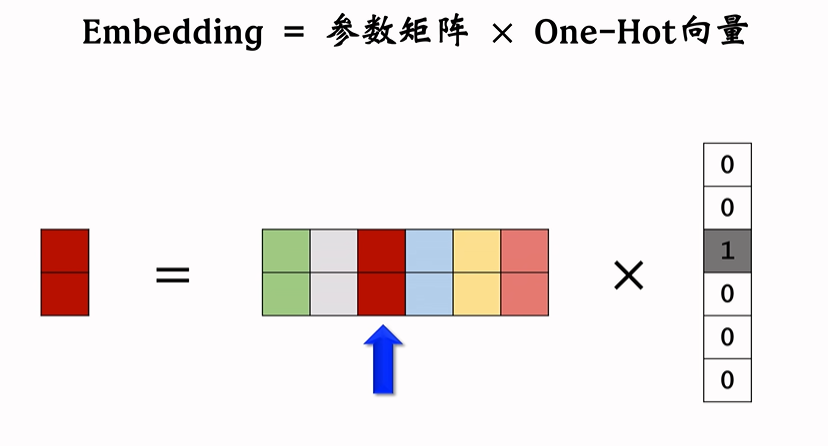
Embedding 与 One-Hot关系
Embedding = 参数矩阵 x One-Hot向量
总结
-
离散特征处理方法:one-hot编码,embedding
-
类别数量很大时,用embedding,类别数量特别大(比如推荐系统中物品有几十亿),需要对embedding做优化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









