




堆栈数据结构
在计算机科学中,堆栈是一种抽象数据类型,用作元素的集合,具有两个主要的操作;
- PUSH:将元素添加到集合
- POP:删除最近添加但尚未删除的元素
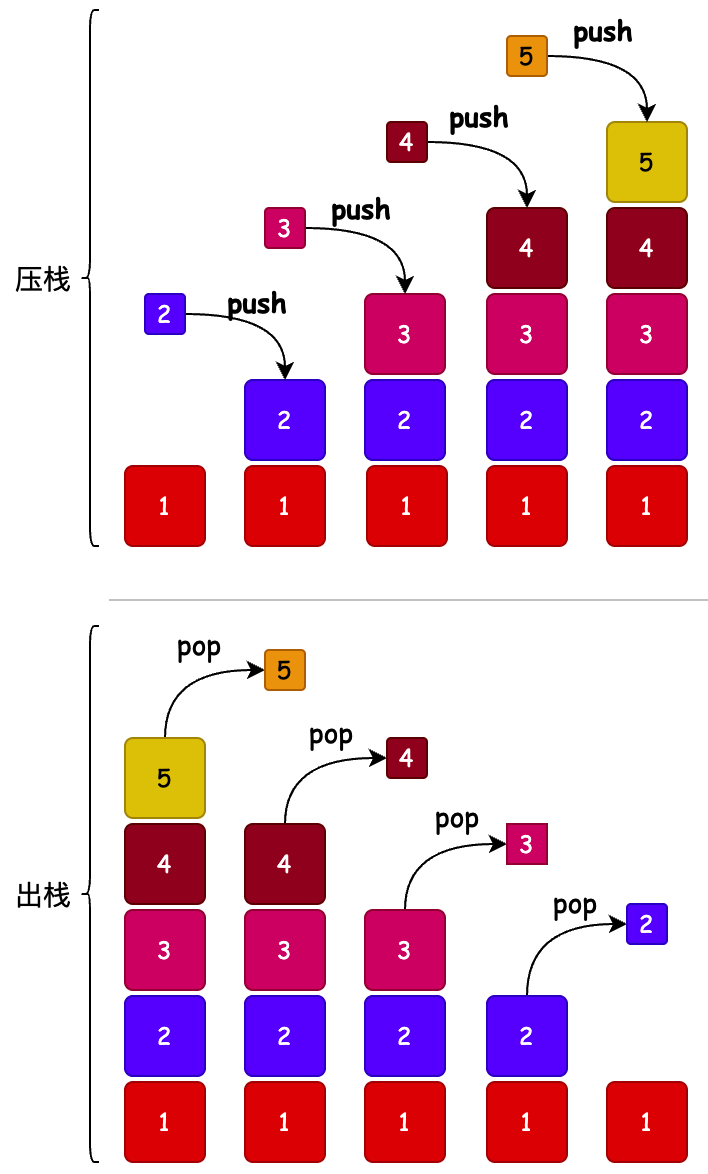
堆栈是一种 LIFO(后进先出)的线性的数据结构,或者更抽象说是一种顺序集合,push 和 pop 操作只发生在结构的一端,称为栈顶。这种结构可以很容易地从堆栈顶部取出一个项目,而要到达堆栈更深处的一个项目可能需要先取出多个其他项目。例如;我们经常看到的浏览器访问记录,总是把最近记录展示给你。还包括:一摞书、一叠盘子、一脑瓜子生活琐事。
实现堆栈结构
当你真的有场景需要使用后进先出堆栈时,一定是不能使用 Java 提供的 Stack 的。因为这个工具类是在 JDK 1.0 阶段开发的,实现的特别粗糙,包括像 synchronized 锁也是直接加到方法上。同时 JDK Stack 类的注解也提醒,使用 ArrayDeque 替代;

- Deque 接口及其实现提供了一组更完整和一致的 LIFO 堆栈操作,应优先使用此类。所以我们本章也是以 ArrayDeque 为原型做代码实现。
1. ArrayDeque 介绍
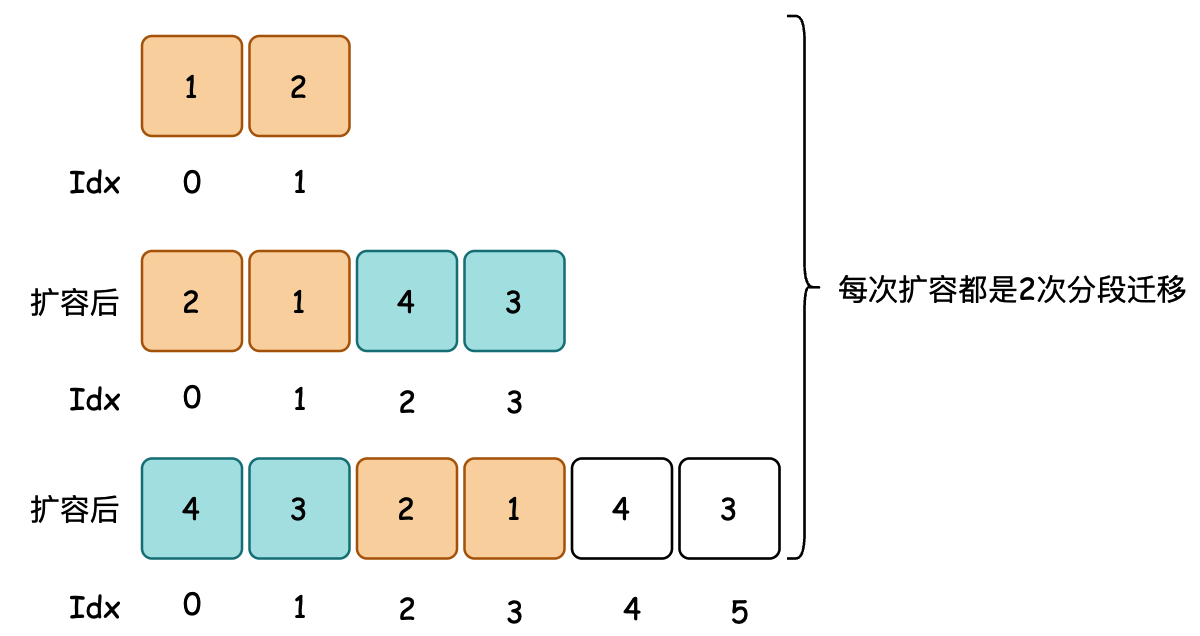
ArrayDeque 是一个基于数组实现的堆栈数据结构,在数据存放时元素通过二进制与运算获取对应的索引存放元素。当数组长度超过初始空间后,进行2的n次幂左移一位扩容,并将数组内容的元素按照分半分别进行迁移。
- 堆栈的数据结构是以2的次幂进行初始化,扩容时候为2的倍数。它之所这样是因为保证了在后续计算元素索引位置时,可以进行与运算。也就说 2的n次幂-1 得到的值是一个011111的范围,在与元素索引位置计算时候,找到两个值之间1的位置即可。
- 数据的压栈,压栈是一个在数组中倒放的方式,通过与运算得到索引值。当发生空间不足时扩容迁移数据,会有2次操作。一次是空间的前半段复制,另外一次是后半段复制。
- 最后在数据弹出时,按照空间的元素数量总数开始,同样通过与运算计算索引值。分为弹出队列中未发生迁移的数据,和已经完全迁移好的数据。凡是迁移的数据,都是保证了一个顺序。
添加元素
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
logger.info("push.idx head:{}", head);
if (head == tail)
doubleCapacity();
}
- 首先,代码检查传入的元素
e是否为null。如果是null,则抛出NullPointerException,这是合理的,因为大多数栈结构不允许null元素。 - 然后,通过
head = (head - 1) & (elements.length - 1)来计算新的head位置。这里使用了位运算,(head - 1) & (elements.length - 1)实际上是在实现一个循环数组的索引计算。假设elements.length是 2 的幂次方(比如 4、8、16 等),这种位运算等同于(head - 1) % elements.length,但位运算效率更高。它把head指针向前移动一位(循环移动),并将元素e放入新的head位置。 - 接着,代码记录新的
head索引值到日志中。 - 最后,如果
head等于tail,说明栈满了,调用doubleCapacity方法将栈的容量翻倍。
扩容空间
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p;
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
/*
* src - 源数组
* srcPos – 源数组中的起始位置
* dest - 目标数组
* destPos – 目标数据中的起始位置
* length – 要复制的数组元素的数量
*/
// 第一次拷贝元素:[2、1、4、3] 将数组中的扩容后一半元素拷贝到新数组0开始往后的位置。拷贝4、3
System.arraycopy(elements, p, a, 0, r);
// 第二次拷贝元素:[2、1、4、3] 将数组中的前面一半数量的元素,拷贝到新数组后一半开始的位置往后。拷贝2、1
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
assert head == tail;:这是一个断言语句,用于确保调用这个方法时,head和tail确实相等,意味着当前存储结构已满。在生产环境中,如果断言被禁用,这行代码不会执行,所以它主要用于开发和调试阶段来验证逻辑。int p = head;和int n = elements.length;:分别获取当前头指针的位置p和数组当前的长度n。int r = n - p;:计算头指针p右边元素的数量。这里的 “右边” 是基于循环数组的逻辑,因为是循环结构,所以头指针右边的元素数量对于重新分配数组很重要。int newCapacity = n << 1;:将数组的容量翻倍,使用左移运算符<<相当于乘以 2,这是一种高效的翻倍操作。if (newCapacity < 0):检查新的容量是否溢出。如果newCapacity < 0,说明发生了溢出,抛出IllegalStateException异常。Object[] a = new Object[newCapacity];:创建一个新的更大容量的数组a。System.arraycopy(elements, p, a, 0, r);:将原数组中从p位置开始到数组末尾的元素复制到新数组a的起始位置。System.arraycopy(elements, 0, a, r, p);:将原数组中从起始位置到p位置的元素复制到新数组a中紧接在前面复制元素的后面。elements = a;:将新数组a赋值给原来存储数据的数组elements。head = 0;和tail = n;:重新设置头指针head为 0,尾指针tail为原数组的长度n,这样就完成了数组的扩容和指针的调整。
循环数组是一种数据结构,它通过将数组看作是首尾相连的方式,充分利用数组空间,避免频繁的内存分配和释放。在这个场景下,elements 是原循环数组,a 是扩容后的新数组。
- 第一次
System.arraycopy:
-
System.arraycopy(elements, p, a, 0, r);elements是原数组,p是原数组中开始复制的位置(也就是head的位置)。a是目标新数组,0是新数组中开始粘贴的位置。r是要复制的元素个数,它等于原数组长度n减去p,也就是从p位置到原数组末尾的元素个数。- 逻辑作用:想象原数组是一个环形队列,从
head(p)位置开始,把这部分元素按顺序复制到新数组的开头部分。例如,原数组[1, 2, 3, 4],p = 2(对应元素3),r = 2(元素3和4),那么新数组开头部分就会变成[3, 4]。这一步先把原数组中head右侧(循环意义上)的元素复制到新数组的起始位置。
- 第二次
System.arraycopy:
-
System.arraycopy(elements, 0, a, r, p);- 这里
elements还是原数组,0表示从原数组的起始位置开始复制。 a依旧是目标新数组,r是新数组中开始粘贴的位置,这个位置刚好是第一次复制结束的位置。p是要复制的元素个数,它是从原数组起始位置到head(p)位置的元素个数。- 逻辑作用:接着第一次复制,这一步把原数组中从起始位置到
head位置(不包含第一次已经复制的部分)的元素,复制到新数组中紧挨着第一次复制元素的后面。继续上面的例子,原数组剩下的元素是[1, 2],现在把它们复制到新数组[3, 4]的后面,新数组就变成[3, 4, 1, 2]。这样就完整地把原循环数组中的所有元素,按照它们在循环数组中的顺序,复制到了新的扩容数组中。
总结:
-
- 这两次
System.arraycopy操作的逻辑是为了在扩容循环数组时,保持元素的原有顺序。先复制head右侧(循环意义)的元素到新数组开头,再复制原数组起始到head位置的元素到新数组第一次复制元素之后,从而完成整个循环数组的复制和扩容。
- 这两次
弹出元素
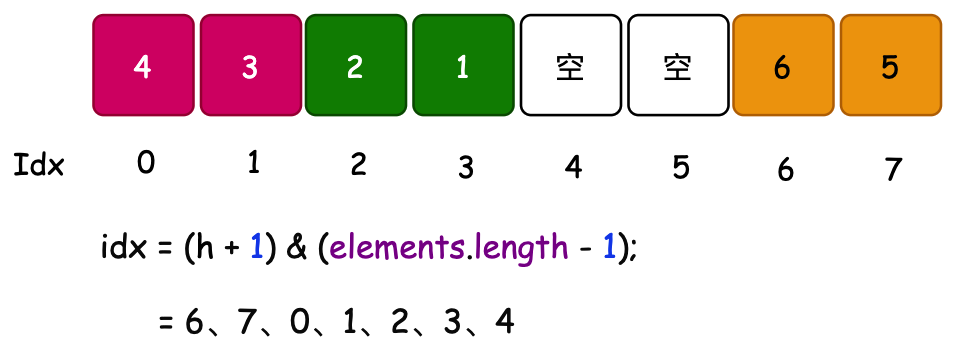
- 按照索引的计算,以此是弹出索引为:6、7、0、1、2、3、4 对应的元素。head 的值从扩容的长度添加元素后逐步减小,所以当前最开始弹出的元素是6索引对应的值。
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
if (result == null) {
return null;
}
elements[h] = null;
head = (h + 1) & (elements.length - 1);
logger.info("pop.idx {} = {} & {}", head, Integer.toBinaryString(h + 1), Integer.toBinaryString(elements.length - 1));
return result;
}
- 这段代码看起来是一个双端队列(Deque)实现中的
pollFirst方法,用于从队列头部取出并移除一个元素。 int h = head;:首先获取当前队列头部的索引h,这里head应该是类中的一个成员变量,表示队列头部的位置。E result = (E) elements[h];:从elements数组(这应该是存储队列元素的数组)的头部位置h取出元素,并进行类型转换。if (result == null) return null;:如果取出的元素为null,说明队列为空,直接返回null。这是合理的,因为空队列没有元素可取出。elements[h] = null;:将数组中原来头部位置的元素设置为null,这样做有助于垃圾回收,释放不再使用的对象所占用的内存。head = (h + 1) & (elements.length - 1);:通过这行代码更新头部位置。(h + 1) & (elements.length - 1)这种写法通常用于在循环数组中移动索引。如果elements.length是 2 的幂次方,这个操作等同于(h + 1) % elements.length,但位运算效率更高。它将头部索引移动到下一个位置,实现了从队列头部移除元素的逻辑。return result;:最后返回取出的元素。
head 位置变化描述
- 初始状态:
head和tail都为0,数组容量为4。 - addFirst(1):
-
- 计算新的
head位置:(head - 1) & (elements.length - 1) = (0 - 1) & 3 = 3。 head变为3,并将1放入elements[3]。
- 计算新的
- addFirst(2):
-
- 再次计算新的
head位置:(3 - 1) & 3 = 2。 head变为2,并将2放入elements[2]。
- 再次计算新的
- addFirst(3):
-
- 计算新的
head位置:(2 - 1) & 3 = 1。 head变为1,并将3放入elements[1]。
- 计算新的
- addFirst(4):
-
- 计算新的
head位置:(1 - 1) & 3 = 0。 head变为0,并将4放入elements[0]。
- 计算新的
- addFirst(5):
-
- 检查到
(head - 1) & (elements.length - 1) == tail,触发doubleCapacity。 - 在
doubleCapacity方法中,head被重置为0,数组容量翻倍为8。 - 然后新的
head计算为(0 - 1) & 7 = 7,并将5放入elements[7]。
- 检查到
- pollFirst():
-
- 取出
elements[head](即elements[7])的值5。 - 更新
head:(7 + 1) & 7 = 0,head变为0。
- 取出
- 再次 pollFirst ():
-
- 取出
elements[head](即elements[0])的值4。 - 更新
head:(0 + 1) & 7 = 1,head变为1。
- 取出

















 3827
3827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









