 使用sklearn+jieba构建文档分类器
使用sklearn+jieba构建文档分类器







 本文介绍如何使用sklearn和jieba完成一个文档分类器,涉及文档标注、格式转换、中文分词、TF-IDF计算、构建朴素贝叶斯分类器以及预测准确性评估。
本文介绍如何使用sklearn和jieba完成一个文档分类器,涉及文档标注、格式转换、中文分词、TF-IDF计算、构建朴素贝叶斯分类器以及预测准确性评估。
“ 最近在学习数据分析的知识,接触到了一些简单的NLP问题,比如做一个文档分类器,预测文档属于某类的准确率,应该怎么做呢 ”
”
从头一起做一个吧
01.文档分类原理
文本分类是自然语言处理领域比较常见的一类任务,一般是给定多个文档类别,将文档或语句归类到某个类别中。其本质是文本特征提取+机器学习的多分类问题。
好的,这就是基本概念了,再来看看几个重要的步骤。
1.文档标注
就是要把样本文档分类,我们首先是要知道我们要把文档分为哪几类,这样才能有依据的构建模型,进而预测其他文档类型。
2.格式转换
为了方便后面的数据处理,一般是要把非txt文本,如word,excel,pdf等转换为txt格式,保证文档中不包含图片,不包含任何文档格式。
3.中文分词
这里就使用jieba了,很流行的工具,同时还要给文档加上标签,其实就是分类的数值化,后面具体说。
4.计算词语权重
如果某个词或短语在一篇文章中出现的频率很高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。通过计算词语的权重,可以找出文档中的关键词,从而确定分类的依据。常用的词语权重计算方法为TF-IDF算法,公式如下
TF-IDF = 词频(TF) * 逆文档频率(IDF)
词频(TF) = 某个词在文档中的出现次数/文章的总词数
逆文档频率(IDF) = log(语料库的文档总数/(包含该词的文档数+1))
sklearn支持该算法,使用TfidfVectorizer类,就可以帮我们计算单词的TF-IDF。
5.构建朴素贝叶斯分类器
sklearn提供的多项式朴素贝叶斯,类MultinomialNB,以单词为粒度,会计算单词在某个文件中的具体次数,用于文档分类很适合。
6.预测准确性
最后就是使用训练的模型来预测未知的文档类型了,当然这之前还要经过准确率的测试。
02.Coding
话不多说,show me the code!
本次是使用的如下数据集,stop目录放置停用词,train目录是训练使用的数据,test目录数据用来做测试准确性的,两个数据集下都有数百个txt文件。
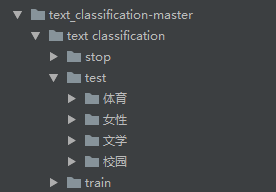
1.获取数据,并打上标签
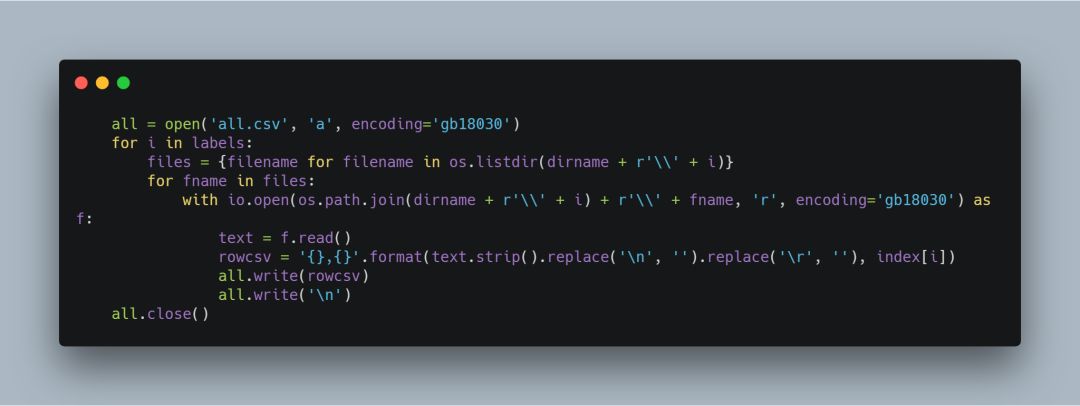
我这里的思路是循环获取到对应目录下的txt文件内容后,保存到一个总的文件中,用于后面使用,并增加一列,保存标签
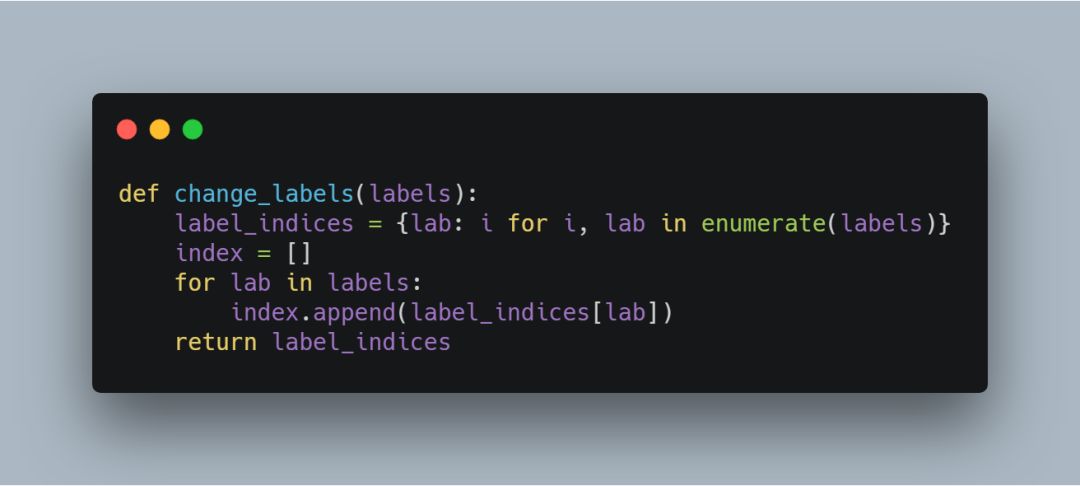
2.生成训练数据
使用jieba工具,做中文分词,并且加载停用词,最后返回训练feature和label
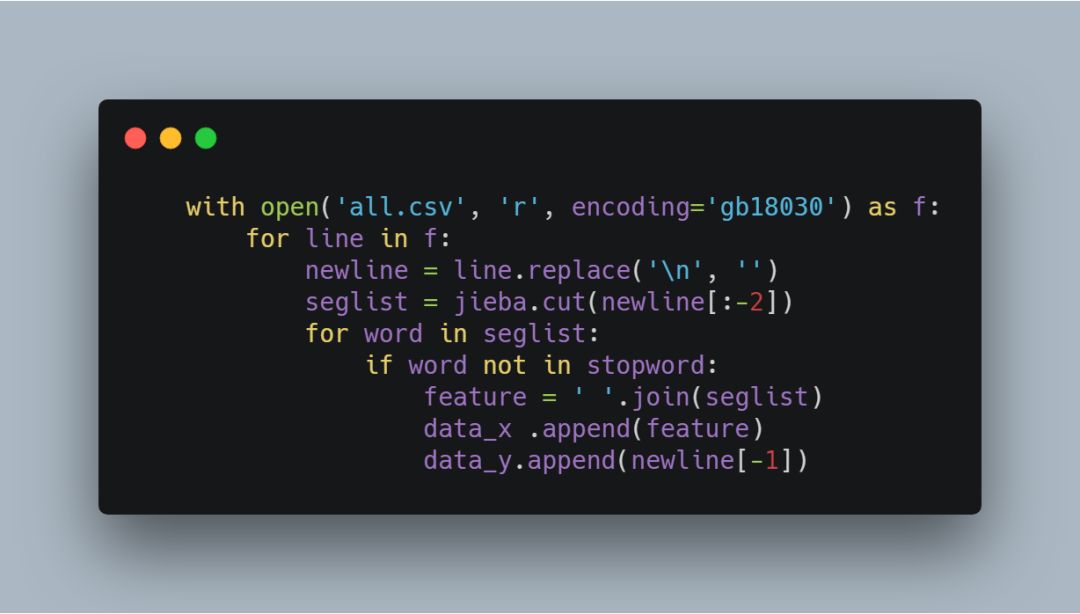
3.同理,处理测试数据
直接给出完整代码
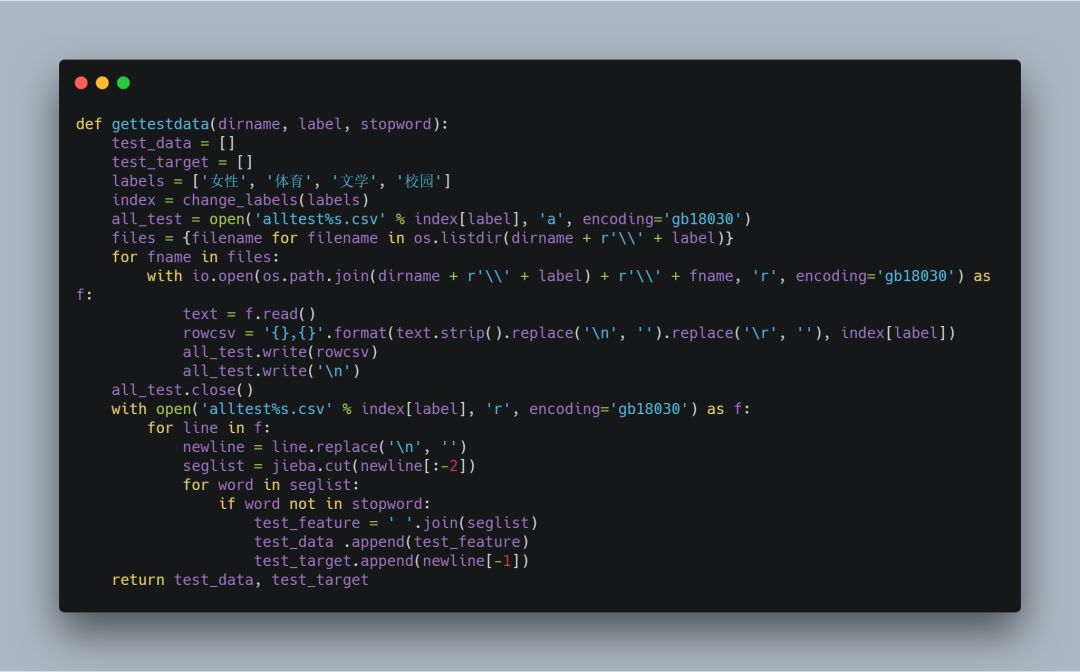
4.构建模型
调用TfidfVectorizer类,使用TF-IDF算法拟合训练数据,再使用MultinomialNB类,生成训练模型,即朴素贝叶斯分类器
![]()
5.使用生成的分类器做预测
同样,使用训练集的分词创建一个TfidfVectorizer类,然后用TfidfVectorizer类对测试集的数据进行fit_transform拟合,即可以得到测试集的特征矩阵,然后再使用MultinomialNB类的predict函数,找出后验概率最大的label,最后使用accuracy_score函数对比实际结果和预测结果。
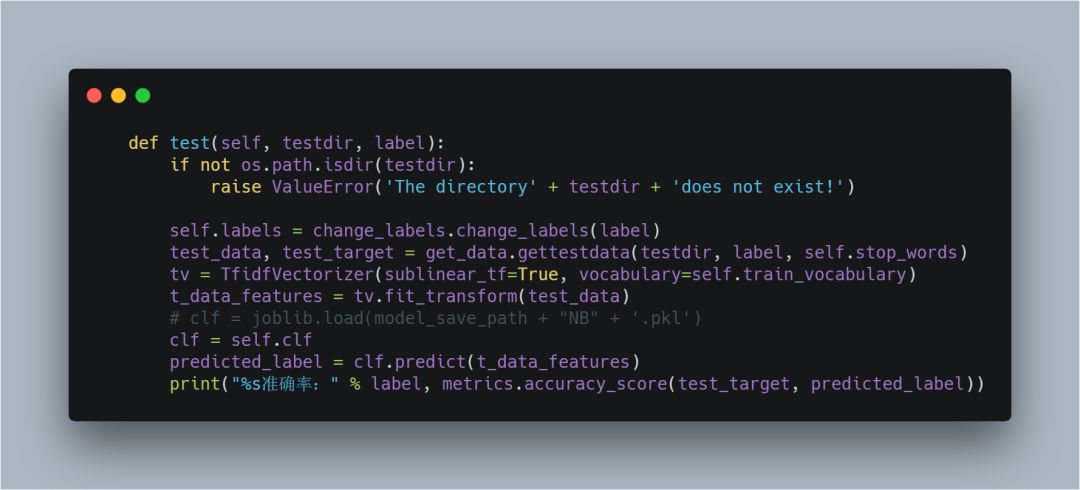
6.准确性验证
我做了初步的验证,不同标签,准确率差别还是挺大的
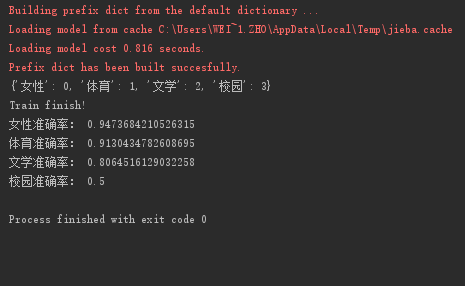
到这,一个简单的文档分类器就完成了,是不是也不是很难呢 ,代码还要很多有待完善的地方,有兴趣的同学一起加油喽!
,代码还要很多有待完善的地方,有兴趣的同学一起加油喽!
还可以关注我的微信公众号“萝卜大杂烩”,获取更多原创内容,或者加入Python入门实战QQ交流群:617870323



















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











