







 本文介绍了Java垃圾收集器常用算法。包括用于标记对象是否存活的引用计数算法、可达性分析算法,以及回收对象的标记 - 清除算法、复制算法、标记 - 整理算法和分代收集算法,还分析了各算法的特点和适用场景。
本文介绍了Java垃圾收集器常用算法。包括用于标记对象是否存活的引用计数算法、可达性分析算法,以及回收对象的标记 - 清除算法、复制算法、标记 - 整理算法和分代收集算法,还分析了各算法的特点和适用场景。
Java垃圾收集器常用算法:
1、引用计数算法
引用计数算法用于标记对象是否存活,严格来说它并不属于垃圾收集算法,只是垃圾收集的辅助算法。它是通过给对象添加一个引用计数器,每当有一个地方引用它时,计数器加1;当引用失效时,计数器减1;任何时刻计数器为0的对象就是不可再被使用的。
引用计数算法,实现简单,判定效率高,大部分情况下比较适用,但在一些特殊引用计数算法不在适用,如:
public static void main(String[] args){
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
System.gc();
}
objA 和 objB相互引用,但是他们在其他地方实际上没有任何引用,也就是说他们应该被回收。而从引用计数算法来看,他们的计数器永远都不会是0,所以如果用引用计数算法,他们永远不会被回收。可达性分析算法为此产生。
2、可达性分析算法
可达性分析算法也是用来计算对象是否存活、是否可被回收。该算法的基本思想是:通过一些列称为“GC Roots” 的对象作为起始点,从这些节点开始向下搜索,搜索锁经过的路径称为引用链,当一个对象到GC Roots没有任何引用链时,则证明此对象是不可用的。如下图:
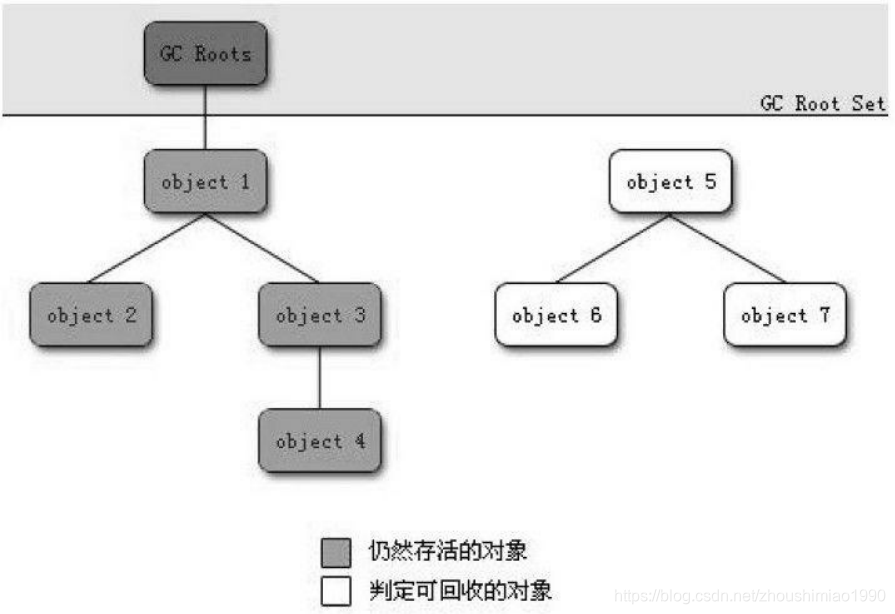
上图中,Object5、Object6、Object7虽然相互关联,但是他们到GC Roots是不可达的,所以他们会被判定为可回收对象。
在Java语言中,可作为GC Roots的对象包括下面几种:
- 栈帧中的局部变量表中的reference引用所引用的对象
- 方法区中static静态引用的对象
- 方法区中final常量引用的对象
- 本地方法栈中JNI(Native方法)引用的对象
- Java虚拟机内部的引用, 如基本数据类型对应的Class对象, 一些常驻的异常对象(比如 NullPointExcepiton、 OutOfMemoryError) 等, 还有系统类加载器。
- 所有被同步锁(synchronized关键字) 持有的对象。
以上两种算法都是用于计算对象是否可被回收的算法,下面开始介绍回收对象的算法:
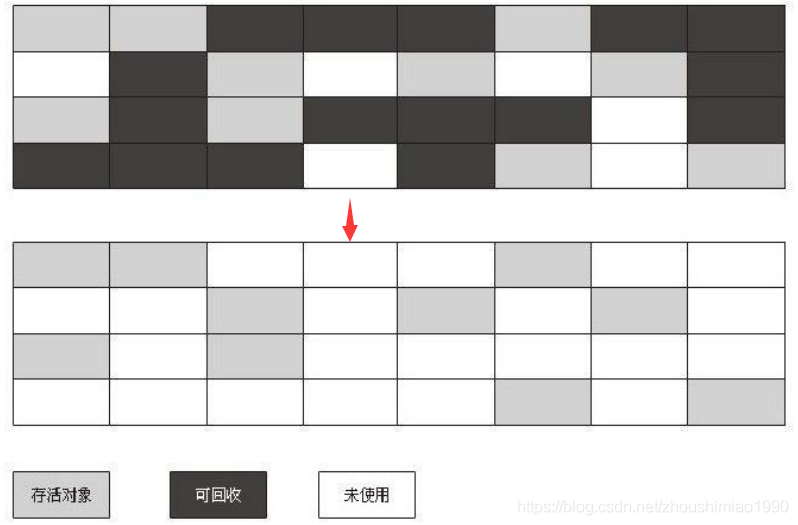
3、标记--清除算法
标记—清除算法分为“标记”和“清除”两个阶段:首先标记处所有需要回收的对象,在标记完成后统一回收所有被标记的对象。标记过程就是上面介绍的判断对象是否可回收的过程。标记—清除算法是最基础的算法,主要有两点不足:
- 效率问题,标记和清除两个过程的效率都不高
- 空间问题,标记清除之后会产生大量不连续的内存碎片。
标记清除算法执行过程:
4、复制算法
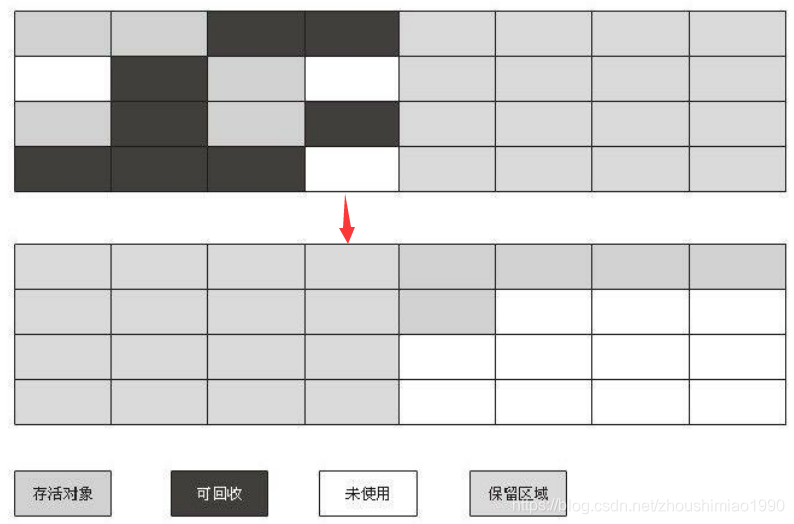
复制算法主要解决了标记清除算法中的效率问题,它将可用的内存按容量划分为大小相等的两块,每次只能使用其中的一块。当其中一块内存空间不足,就将还存活的对象复制到另一块内存中,再讲已使用的内存空间清理掉。这样使得每次都是对整个半区进行内存回收,内存分配也不需要考虑碎片空间问题,只需要移动堆顶指针,按顺序分配内存即可。但是这种算法的代价是将内存缩小为原来的一半,且在对象存活率较高时,要进行较多的赋值操作,效率将会降低。Java堆中的Survivor区就是使用的赋值算法。
赋值算法的执行流程:
5、标记--整理算法
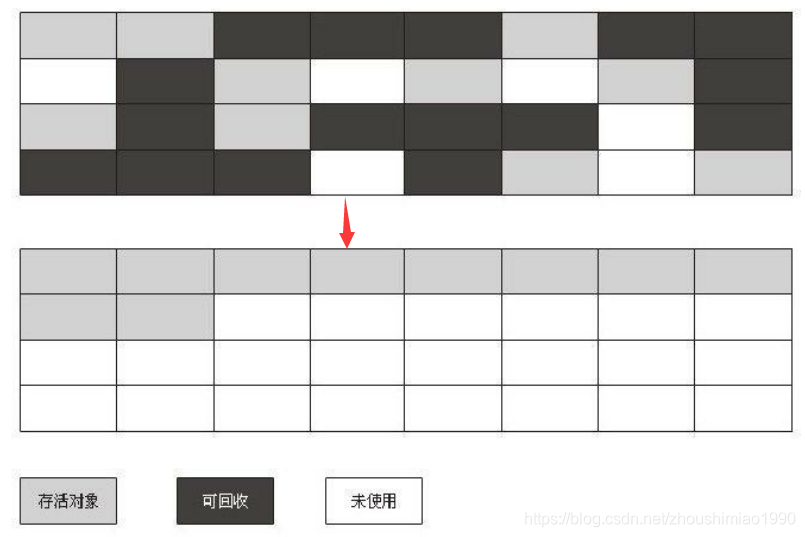
标记整理算法适用于java堆中的老年代垃圾回收,因为老年代的对象存活效率较高,使用复制算法效率较低。标记整理算法分为标记和整理两步,其中标记步骤与标记清除算法中的标记步骤一样,标记可被回收的对象;整理步骤,则是将所有存活的对象都向一端移动,然后清理掉端边界以外的内存。这样,不会浪费内存空间,也不会产生空间碎片,只是在将存活对象向一端移动时,如果对象存活率较低,效率会比较低。
标记整理算法的示意图:
6、分带收集算法
分带收集算法,并没有产生什么新的算法思想,只是根据对象存活周期的不同将内存划分为几块,根据内存块的不同使用不同的算法。如将java堆分为新生代和老年代,新生代中使用复制算法,因为新生代中对象存活率比较低,只需要付出少量存活对象的复制成本就能完成收集;老年代使用标记整理算法,因为老年代对象存活率高,没有额外额空间对它进行分配担保。
















 1682
1682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









