










 pkuseg是一款由北京大学开发的中文分词工具包,具有高分词准确率,支持多领域分词模型,用户自训练模型等功能。相比结巴分词,pkuseg在多个数据集上表现更优,误差率显著降低。
pkuseg是一款由北京大学开发的中文分词工具包,具有高分词准确率,支持多领域分词模型,用户自训练模型等功能。相比结巴分词,pkuseg在多个数据集上表现更优,误差率显著降低。
pkuseg使用
- 简介
- 最近社区推了一些文章介绍了北大开源的一个新的中文分词工具包pkuseg。它在多个分词数据集上都有非常高的分词准确率。其中广泛使用的结巴分词(jieba)误差率高达18.55%和20.42%,而北大的pkuseg只有3.25%与4.32%。
- 在中文处理领域,特别是数据分析挖掘这个领域,数据预处理重要性不言而喻,那么分词的重要性也是不言而喻的。
- 简单使用pkuseg这个包,这是一个python语言写成的包,具体可以查看官方GitHub地址。
- 特点
- 多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。 目前支持了新闻领域,网络文本领域和混合领域的分词预训练模型,同时也拟在近期推出更多的细领域预训练模型,比如医药、旅游、专利、小说等等。
- 更高的分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
- 支持用户自训练模型。支持用户使用全新的标注数据进行训练。
- 安装
- 目前只支持python3,这点无伤大雅,越来越多的项目向3迁移了。
- 最新版本
- 2019-1-23
- pip安装
- pip install pkuseg
- 由于比较大,pip源下载可能比较慢,可以使用镜像源。
- pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pkuseg
- 源码安装
- 访问上面的官方地址,下载源码放到项目目录下。
- 使用
- 使用默认模型和默认字典
- 代码
-
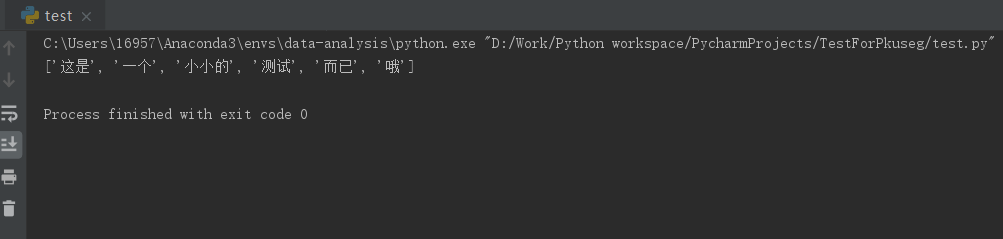
''' 使用默认模型和默认词典分词 :return: ''' # 创建分析对象 seg = pkuseg.pkuseg() rst = seg.cut("这是一个小小的测试而已哦") print(rst)
-
- 结果
- 出现错误
- ValueError: numpy.ufunc size changed, may indicate binary incompatibility. Expected 216 from C header, got 192 from PyObject
- 这是因为numpy版本过低,更新即可pip install --upgrade numpy。
- 代码
- 使用自定义字典
- 代码
-
''' 使用自定义词典,词典中存在的一定会单独成词 :return: ''' myDict = "dict.txt" seg = pkuseg.pkuseg(user_dict=myDict) rst = seg.cut("我是一个好好学生") print(rst)
-
- 结果
- 代码
- 使用其他模型
- 需要下载该模型
- 代码
-
''' 使用其他模型,不使用字典 :return: ''' # 必须下载这个模型且ctb8这个目录放在当前目录下 seg = pkuseg.pkuseg(model_name='models/ctb8', user_dict=None) rst = seg.cut('我是一个好学生') print(rst)
-
- 结果
- 对文件分词(使用默认模型,使用词典)
- 因为包括文件处理,这个过程比较慢,建议开多个线程。
- 代码
-
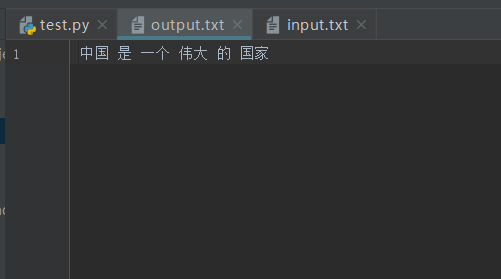
''' 对文件进行分词 :return: ''' # 对input.txt的文件分词输出到output.txt中 # 使用默认模型,使用词典,开20个进程 pkuseg.test('input.txt', 'output.txt', nthread=5)
-
- 结果
- 训练新模型
- 代码
-
''' 训练新模型 :return: ''' # 训练文件为'msr_training.utf8' # 测试文件为'msr_test_gold.utf8' # 训练好的模型存到'./models'目录下,开20个进程训练模型 # 训练模式下会保存最后一轮模型作为最终模型 # 目前仅支持utf-8编码,训练集和测试集要求所有单词以单个或多个空格分开 pkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', 'models/', nthread=20)
-
- 代码
- 参数说明
- 详见官方文档
- pkuseg.pkuseg(model_name=“default”, user_dict=“default”)
- model_name
- 模型路径。默认是"default"表示我们预训练好的模型(仅对pip下载的用户)。用户可以填自己下载或训练的模型所在的路径如model_name=’./models’。
- user_dict
- 设置用户词典。默认使用我们提供的词典。用户可以填自己的用户词典的路径,词典格式为一行一个词。填None表示不使用词典。
- model_name
- pkuseg.test(readFile, outputFile, model_name=“default”, user_dict=“default”, nthread=10)
- readFile
- 输入文件路径
- outputFile
- 输出文件路径
- model_name
- 模型路径。同pkuseg.pkuseg
- user_dict
- 设置用户词典。同pkuseg.pkuseg
- nthread
- 测试时开的进程数
- readFile
- pkuseg.train(trainFile, testFile, savedir, nthread=10)
- trainFile
- 训练文件路径
- testFile
- 测试文件路径
- savedir
- 训练模型的保存路径
- nthread
- 训练时开的进程数
- trainFile
- 使用默认模型和默认字典
- 关于预训练模型
- 官方提供了几种模型(文件均可以在我的GitHub找到)
- MSRA: 在MSRA(新闻语料)上训练的模型。
- CTB8: 在CTB8(新闻文本及网络文本的混合型语料)上训练的模型。
- WEIBO: 在微博(网络文本语料)上训练的模型。
- MixedModel: 混合数据集训练的通用模型。随pip包附带的是此模型。
- 其中,MSRA数据由第二届国际汉语分词评测比赛提供,CTB8数据由LDC提供,WEIBO数据由NLPCC分词比赛提供。
- 补充说明




















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











