







为了防止数据丢失情况,做高可用,我们可以将namenode的元数据放到多个磁盘中,
那么我们该怎么办呢
步骤:
1关闭hadoop
2修改配置
cd /home/hadoop/apps/hadoop-2.6.4/etc/hadoop
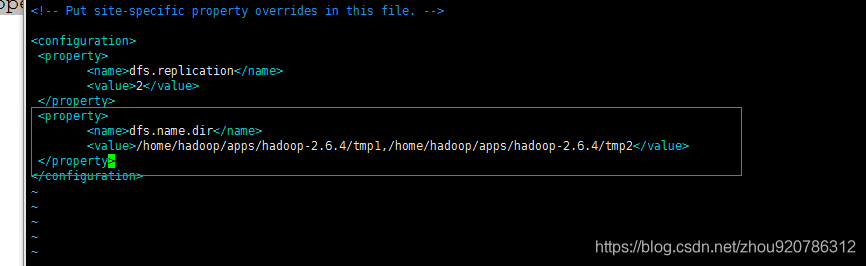
[hadoop@mini-yum hadoop]$ vi hdfs-site.xml
<property>
<name>dfs.name.dir</name>元数据保存目录,可以写多个
<value>/home/hadoop/apps/hadoop-2.6.4/tmp1,/home/hadoop/apps/hadoop-2.6.4/tmp2</value>
</property>
3重启hadoop
start-dfs.sh
start-yarn.sh
报错
[hadoop@mini-yum hadoop]$ hadoop fs -ls /
ls: Call From mini-yum/192.168.232.128 to mini-yum:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
原因:原有的数据是有工作目录的,现在添加进去新的工作目录造成冲突,我的解决方法:就是重新格式化。
4格式化
hdfs namenode -format
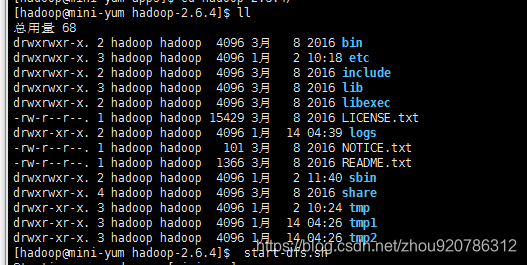
5查看
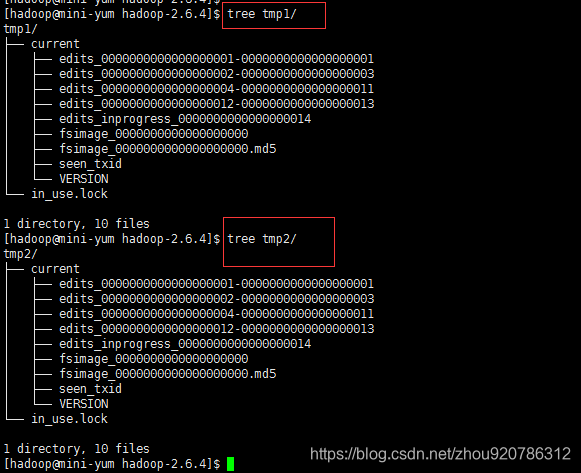
如下图所示,新生成2个目录temp1和temp2,以后元数据就会同时保存在这2个目录。
6测试
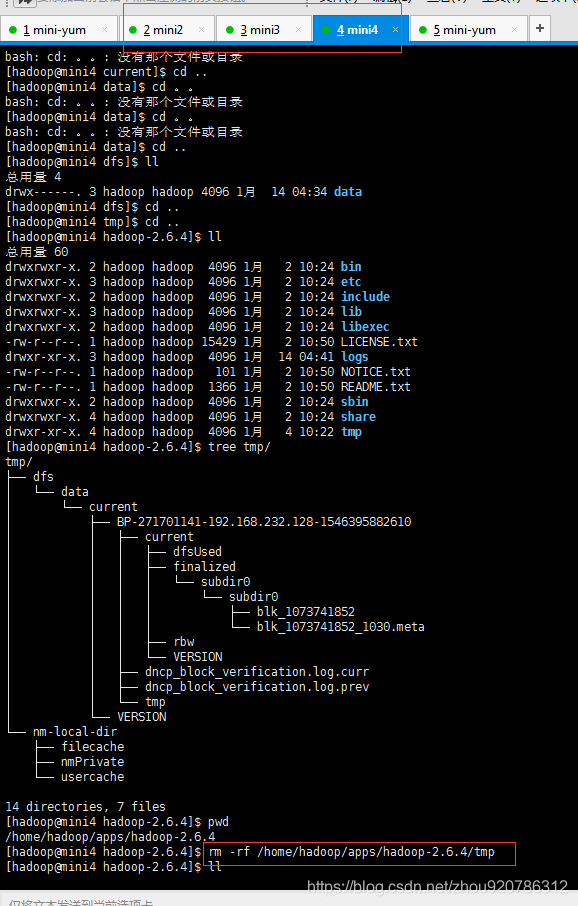
由于各个namenode格式化过了,所以我们需要将datanode的数据删除掉,为什么要删除,简单来说版本问题。(具体看上一编)
mini2和mini3也要删除
接下来开始测试
重启hadoop
start-dfs.sh
上传文件测试
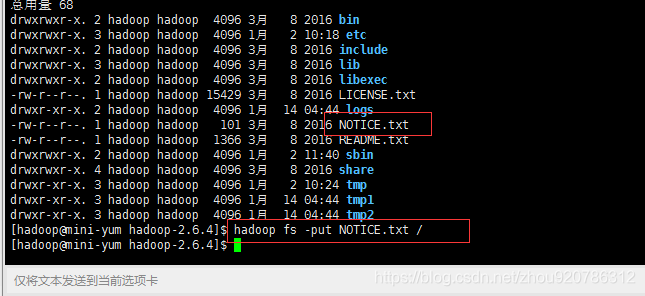
查看temp1,temp2,可以发现2个保存的数据相同,也就是说当temp1数据丢了,我们可以使用temp2的数据。
做到(HA)
扩展
查看temp
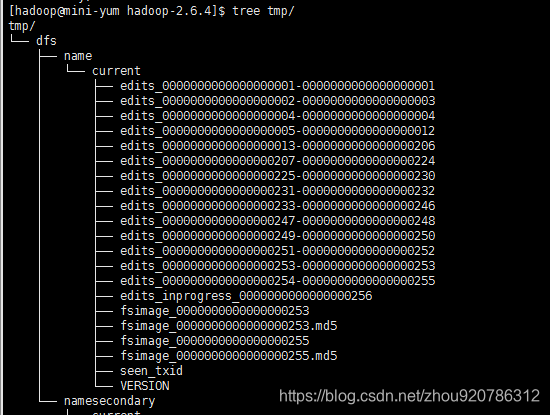
扩展:datanode数据也可以保存在多个磁盘上


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









