







一、MapReduce
1.1 MapReduce介绍
MapReduce是Hadoop框架的核心之一,它主要负责数据的分布式计算问题。MapReduce的核心思想是“分而治之”。“分”,即把一个复杂的任务分解成若干个简单任务来处理,但前提是这些任务是可以并行计算的。“合”,即对map阶段的结果进行全局汇总。
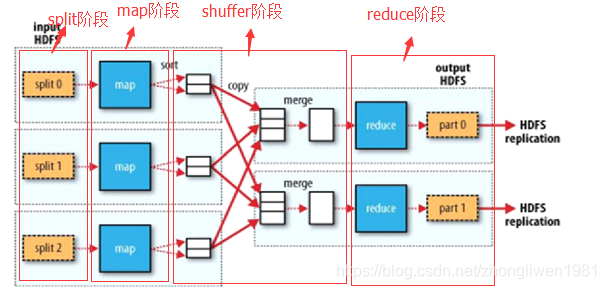
MapReduce将整个并行计算过程划分为三个阶段:
- Map:对一些独立元素组成的列表中的每个元素并行地执行指定操作;
- Shuffle:对Map阶段得到的数据进行清洗操作;
- Reduce:对Shuffle后的数据进行合并,得到最终结果;
1.2 MapReduce的开发步骤
MapReduce的开发一共分为八个步骤。其中,Map阶段分为2个步骤,Shuffle阶段分为4个步骤,Reduce阶段也分为2个步骤。
- Map阶段:
1)设置InputFormat类,将数据切分为Key-Value(K1和V1);
2)自定义Map逻辑,将第一个的结果转成K1和V2;
- Shuffle阶段:
1)对K2和V2进行分区;
2)对不同分区的数据按照相同的key进行排序;
3)对分组过的数据进行初步筛选,降低数据的网络拷贝;
4)对数据分组,相同Key的Value放入到Map集合中;
- Reduce阶段:
1)对多个Map任务的结果进行排序和合并,编写Reduce函数实现自己的业务逻辑,将输入的K2和V2转成K3和V3;
2)设置OutputFormat,输出K3和V3;
1.3 入门示例
需求:在给定文本文件中统计并输出每一个单词出现的次数。
实现步骤:
- 第一步:将文本文件上传到HDFS上;
cd /export/servers
# 创建文件
vim wordcount.txt
# 创建HDFS目录
hdfs dfs ‐mkdir /wordcount/
# 上传文件
hdfs dfs ‐put wordcount.txt /wordcount/
文件内容:
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
- 第二步:定义一个Mapper的子类,并重写map方法;
public class WordCountMapper extends
Mapper<LongWritable,Text,Text,LongWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws
IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
for (String word : split) {
context.write(new Text(word),new LongWritable(1));
}
}
}
- 第三步:定义一个Reducer的子类,并重写reduce方法;
public class WordCountReducer extends
Reducer<Text,LongWritable,Text,LongWritable> {
/**
* 自定义我们的reduce逻辑
* key代表需要统计的单词,values代表单词出现的次数
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count += value.get();
}
context.write(key,new LongWritable(count));
}
}
- 第四步:定义一个主类,负责定义和启动job任务;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(),
JobMain.class.getSimpleName());
//打包到集群上面运行时候,必须要添加以下配置,指定程序的main函数
job.setJarByClass(JobMain.class);
//第一步:读取输入文件解析成key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new
Path("hdfs://node01:8020/wordcount"));
//第二步:设置我们的mapper类
job.setMapperClass(WordCountMapper.class);
//设置我们map阶段完成之后的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//第三步:设置我们的reduce类
job.setReducerClass(WordCountReducer.class);
//设置我们reduce阶段完成之后的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第四步:设置输出类以及输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new
Path("hdfs://node01:8020/wordcount_out"));
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
/**
* 程序main函数的入口类
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Tool tool = new JobMain();
int run = ToolRunner.run(configuration, tool, args);
System.exit(run);
}
}
- 第五步:将工程打成jar包,然后提交到Yarn集群上运行;
可以在任意节点上执行如下命令:
# 命令格式: hadoop jar jar文件路径 主类完整路径
当把jar文件提交给Yarn集群后,Yarn集群会将该文件分发到其他节点上并发执行。执行完成后,最终计算结果会保存在HDFS上。
1.4 自定义分区
在实际应用中,我们可以把一批类似的数据放在同一个分区里面。在执行统计的时候,通过我们指定的分区,可以把同一个分区的数据发送给同一个Reduce进行处理。
Reduce默认只有一个分区。如果要定义多个分区,可以按照以下步骤来实现:
- 第一步:定义一个分区类,继承Partitioner,并重写getPartition方法;
/**
* 这里的输入类型与我们map阶段的输出类型相同
*/
public class MyPartitioner extends Partitioner<Text, LongWritable>{
/**
* text代表K2,longWritable代表V2,i代表reducetask个数
* 返回值只是一个分区的编号,用来标记所有相同的数据去到指定的分区
*/
@Override
public int getPartition(Text text, LongWritable longWritable , int i) {
// 如果单词长度大于等于5,则进入第一个分区
// 如果单词长度小于5,则进入第二个分区
if (text.toString().length() >= 5){
return 0;
}else{
return 1;
}
}
}
- 第二步:在Job类中设置分区类,以及指定reducetask的个数(必须要与分区数保持一致);
// 设置分区类
job.setPartitionerClass(MyPartitioner.class);
// 设置reducetask个数,与分区个数相同
job.setNumReduceTasks(2);
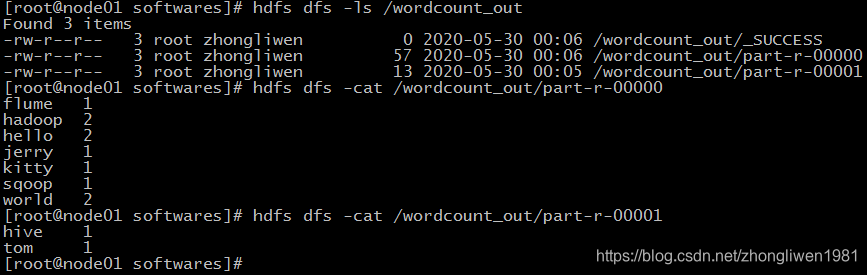
运行效果:
1.5 序列化和排序
Hadoop提供了Writable接口,用于实现序列化。另外,Writable接口有一个子接口WritableComparable,它既可以实现序列化,也可以通过自定义Key实现p排序功能。
假设需要对下面数据进行排序:
a 1
a 9
b 3
a 7
b 8
b 10
a 5
要求先对第一列按照字典进行排列,如果第一列相同时,再对第二列数字的升序排列。
解决思路:
- 因为需要同时对key和value进行排序,所以在map阶段将输入的key和value组成一个新的key作为k2,value作为v2;
- 对新的k2进行排序,如果k2中的key相同,再对k2中的value进行排序;
具体实现步骤:
- 第一步:自定义类型PairWritable,该类型继承了WritableComparable。该类用于封装了K2和V2。如果要实现排序,需要重写compareTo方法;
public class PairWritable implements WritableComparable<PairWritable> {
private String first; // 第一例数据
private Integer second; // 第二列数据
public PairWritable() {}
public PairWritable(String first, int second) {
this.set(first, second);
}
public void set(String first, int second) {
this.first = first;
this.second = second;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(first);
dataOutput.writeInt(second);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.first = dataInput.readUTF();
this.second = dataInput.readInt();
}
@Override
public int compareTo(PairWritable other) {
int res = this.first.compareTo(other.first);
if (res != 0) {
return res;
} else {
return this.second.compareTo(other.second);
}
}
}
- 第二步:实现Mapper;
public class SortMapper extends
Mapper<LongWritable,Text,PairWritable,IntWritable> {
private PairWritable mapOutKey = new PairWritable(); // K2
private IntWritable mapOutValue = new IntWritable(); // V2
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String lineValue = value.toString();
String[] strs = lineValue.split("\t");
//设置组合key和value ==> <(key,value),value>
mapOutKey.set(strs[0], Integer.valueOf(strs[1]));
mapOutValue.set(Integer.valueOf(strs[1]));
context.write(mapOutKey, mapOutValue);
}
}
- 第三步:实现Reducer;
public class SortReducer extends
Reducer<PairWritable,IntWritable,Text,NullWritable> {
private Text outPutKey = new Text(); // K3
@Override
public void reduce(PairWritable key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//迭代输出
for(IntWritable value : values) {
outPutKey.set(key.getFirst());
context.write(outPutKey, null);
}
}
}
- 第四步:定义主类;
public class SecondarySort extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
conf.set("mapreduce.framework.name","local");
Job job = Job.getInstance(conf,
SecondarySort.class.getSimpleName());
job.setJarByClass(SecondarySort.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/sort"));
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/sort_out"));
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration entries = new Configuration();
ToolRunner.run(entries, new SecondarySort(), args);
}
}
1.6 计数器
1.6.1 什么是计数器
MapReduce计数器是用于获取计算过程中的数据。计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助诊断系统故障。在实际应用中,可以使用计数器值来记录某一特定事件的发生,然后根据计数器值统计特定事件的发生次数。
hadoop内置的计数器:
| 计数器名称 | 计数器类型 |
|---|---|
| 任务计数器 | org.apache.hadoop.mapreduce.TaskCounter |
| 文件系统计数器 | org.apache.hadoop.mapreduce.FileSystemCounter |
| FileInputFormat计数器 | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| FileOutputFormat计数器 | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
| 作业计数器 | org.apache.hadoop.mapreduce.JobCounter |
1.6.2 自定义计数器
通过context上下文对象获取计数器;
// 自定义计数器,第一个参数代表计数器的分类名称,第二个参数代表计数器的名称,它们都可以任意起名
Counter counter = context.getCounter("MR_COUNT", "MapRecordCounter");
// 计数器的值加1
counter.increment(1L);
如果有多个计数器的话,可以使用一个枚举类来管理所有的计数器。
public static enum Counter {
REDUCE_INPUT_RECORDS,
REDUCE_INPUT_VAL_NUMS,
}
context.getCounter(Counter.REDUCE_INPUT_RECORDS).increment(1L);
例如:统计reduce阶段输入的key的数量,以及对应的value的数量。
public class SortReducer extends Reducer<PairWritable, IntWritable, Text, IntWritable> {
private Text outPutKey = new Text();
public static enum Counter {
REDUCE_INPUT_RECORDS,
REDUCE_INPUT_VAL_NUMS,
}
@Override
protected void reduce(PairWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
context.getCounter(Counter.REDUCE_INPUT_RECORDS).increment(1L);
for(IntWritable value : values) {
outPutKey.set(key.getFirst());
context.write(outPutKey, value);
}
}
}
1.7 Combiner规约
1.7.1 什么是规约
每一个 map 都可能会产生大量的本地输出,规约的作用就是对map阶段的输出先做一次合并,以减少在map和reduce之间的数据传输量,以提高网络IO 性能。Combiner组件的父类是Reducer,因此Combiner实际上也是Reduce。但是不同的是,Combiner是在每一个运行maptask任务的节点上运行,而Reducer是用于接收所有Mapper的输出结果。
1.7.2 实现步骤
- 第一步:自定义Combiner类,继承Reducer,重写reduce方法;
- 第二步:在job中设置Combiner;
job.setCombinerClass(CustomCombiner.class)
值的注意是,Combiner使用的前提是不能够影响的最终的业务逻辑。而且Combiner输出的kv应该跟reducer输入的kv类型要相匹配。
1.8 多文件的Join操作
如果数据是以多文件形式存放在HDFS中,例如:
- 存放订单数据的文件:
| id | date | pid | amount |
|---|---|---|---|
| 1001 | 20150710 | P0001 | 2 |
| 1002 | 20150710 | P0001 | 3 |
| 1002 | 20150710 | P0002 | 3 |
- 存放商品数据的文件:
| id | pname | category_id | price |
|---|---|---|---|
| P0001 | 小米10 | 1000 | 3000 |
| P0002 | 华为meta | 1000 | 3500 |
如果需要同时查询订单和商品的数据,我们的实现思路:
- 在map阶段判断数据是来自哪一个文件,不同文件的商品ID的位置不一样;
- 将商品ID作为map阶段输出的Key,文件每一个行的内容作为输出的Value;
- 在reduce阶段遍历Value,然后将订单和商品数据合并一起作为Value输出,Key保持不变;
实现步骤:
- map实现:
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//首先判断数据来自哪个文件
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
if(fileName.equals("orders.txt")){
//获取pid
String[] split = value.toString().split(",");
context.write(new Text(split[2]), value);
}else{
//获取pid
String[] split = value.toString().split(",");
context.write(new Text(split[0]), value);
}
}
}
- reduce实现:
public class ReduceJoinReducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String first = "";
String second = "";
for (Text value : values) {
if(value.toString().startsWith("p")){
first = value.toString();
}else{
second = value.toString();
}
}
if(first.equals("")){
context.write(key, new Text("NULL"+"\t"+second));
}else{
context.write(key, new Text(first+"\t"+second));
}
}
}
- 定义主类:
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//创建一个任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_reduce_join");
//打包放在集群运行时,需要做一个配置
job.setJarByClass(JobMain.class);
//第一步:设置读取文件的类: K1 和V1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8020/reduce_join"));
//第二步:设置Mapper类
job.setMapperClass(ReduceJoinMapper.class);
//设置Map阶段的输出类型: k2 和V2的类型
//k2为商品的ID,v2为商品或订单数据
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六步采用默认方式(分区,排序,规约,分组)
//第七步 :设置文的Reducer类
job.setReducerClass(ReduceJoinReducer.class);
//设置Reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
TextOutputFormat.setOutputPath(job, new
Path("hdfs://node01:8020/reduce_join_out"));
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









