







Redis大家再熟悉不过,常用在频繁存取数据、实时排行榜等场景。
大部分人对Redis底层数据结构有些了解,掌握怎么样呢,以下几个问题,看你是否能解答清楚?
- Redis底层用到了哪些数据结构?redisObject结构体长啥样?
- Redis String 整数存储 VS 字符串存储,内存占用情况有什么差异?
- 1亿用户,计算连续10天登录的用户数,用Redis来支持,具体要怎么实现?
- 如果要实现查找附近的人,用Redis来支持,具体要怎么实现?
- 允许1%的误差情况下,怎么统计顶流页面的访问UV?
如果你答不上来,请继续跟上脚步,我们逐步剖析一下。
本文详细说明一下Redis 的String类型,解答下问题1、2、3。
(本文例子,使用redis_version:6.2.1)
一、认识Redis String底层数据结构
为了将性能优化到极致,redis 作者为每种数据结构提供了不同的实现方式,以适应特定应用场景,那么Redis String 类型作者做了哪些内存优化呢?
1. 请君一起入瓮
先看一个例子,存3个简单的数据
例1:
127.0.0.1:7002> set age 30
-> Redirected to slot [741] located at 127.0.0.1:7001
OK
127.0.0.1:7001> get age
30
127.0.0.1:7001> object encoding age
int
127.0.0.1:7001> debug object age
Value at:0x7fd9d0806770 refcount:2147483647 encoding:int serializedlength:2 lru:10316284 lru_seconds_idle:18
存的key是 age ,value是30,字符串长度为2,上次访问是18秒之前,编码方式是int.
tips: 0-9999 的整数,是共享内存,所以refcount 跟预期的1次有差异,小整数对象的引用计数字段的值恒定为 INT_MAX:2147483647
例2:
127.0.0.1:7002> set name angus
OK
127.0.0.1:7002> get name
angus
127.0.0.1:7002> debug object name
Value at:0x7fcd5c00c230 refcount:1 encoding:embstr serializedlength:6 lru:9798174 lru_seconds_idle:26
#修改后,注意encoding的变化
127.0.0.1:7002> append name -family
12
127.0.0.1:7002> get name
angus-family
127.0.0.1:7002> debug object name
Value at:0x7fcd2b704260 refcount:1 encoding:raw serializedlength:13 lru:10320554 lru_seconds_idle:28
可以看到存的key是 name ,value是angus,字符串长度为6,上次访问是26秒之前,编码方式是embstr.
append 后,length小于44,但encoding 为raw
例3:
127.0.0.1:7003> set p:15311111111:addr pinganFinanceCenter-fuhua3road-Futian-Shenzhen-China
OK
127.0.0.1:7003> get p:15311111111:addr
pinganFinanceCenter-fuhua3road-Futian-Shenzhen-China
127.0.0.1:7003> debug object p:15311111111:addr
Value at:0x7ff2fa730930 refcount:1 encoding:raw serializedlength:53 lru:10317779 lru_seconds_idle:21
存的key是 p:15311111111:addr ,value长度为53,上次访问是21秒之前,编码方式是raw.
通过列子,我们知道了Redis String至少有三种encoding方式:int、emstr、raw,实际也就这三种,以下为String encoding的规则:
- 当数据为long型整数时,使用int编码,LONG_MAX为2^63-1, LONG_MIN为-2^63
- 当存储字符串长度不超过44字节时,使用emstr编码
- 当存储字符串大于44字节时,使用raw编码
- 当对字符串进行修改时,会调整为raw编码(如例1)
为什么要String 的内部编码要有这么多种类型呢?
原因当然是为了更好的利用内存,减少内存碎片,减少内存分配次数,那是怎么实现的呢?
我们先看下Redis String的数据结构,它底层实现是简单动态字符串(SDS:Simple Dynamic String)数据结构。
SDS 结构体定义,主要看源码:sds.c sdshdrX 部分。
/*
* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings.
*/
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
结构体说明:
- len: 字符串已使用长度 ,最小1个字节
- alloc: 已分配的内存长度,最小1个字节
- flags:表示当前sdshdr的类型,声明为char 一共有1个字节(8位),仅用低三位就可以表示所有5种sdshdr类型,1个字节
- buf:字节数组,保存实际存储的字符串,结尾会自动加’\0’,会额外占用1个字节。
除了buf数组,其他部分至少需要开销3个字节。
为什么emstr 、raw 编码以44个字节作为分界点呢?我们接着往下分析。
2. Hello,RedisObject
要回答上一个小节的问题,我们先认识一下RedisObject。
在源码server.h文件,有redisObject的结构体定义:
typedef struct redisObject {
#类型长度为4bit
unsigned type:4;
#编码方式为4bit
unsigned encoding:4;
#redis用24个位来保存LRU和LFU的信息,当使用LRU时保存上次;读写的时间戳(秒),使用LFU时保存上次时间戳(16位 min级) 保存近似统计数,3个字节
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
#引用计数器,可以通过引用计数进行共享 32-bits,4个字节
int refcount;
#指向对象的值 64-bits,8个字节
void *ptr;
} robj;
挨个说明一下:
-
type : Redis 对象的数据类型,代表这条数据是什么类型,通过type 命令即可查看,目前Redis 有 7 种类型。分别为:
OBJ_STRING:字符串对象。
OBJ_LIST:列表对象。
OBJ_SET:集合对象。
OBJ_ZSET:有序集合对象。
OBJ_HASH:哈希对象。
OBJ_MODULE:模块对象。
OBJ_STREAM:消息队列/流对象。 -
encoding: Redis 对象的内部编码方式,即在Redis内部是以哪种数据结构存放的。源码目前有 11 种编码方式(有3种为旧的实现,新的不再使用),object encoding key 命令可以看到 ,具体如下:
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
-
lru:存储的是淘汰数据用的 LRU 时间或 LFU 频率及时间的数据。
-
refcount:记录引用计数,用来表示对象被共享的次数,共享使用时加 1,不再使用时减 1,当计数为 0 时表明该对象没有被使用,就会被释放,回收内存。
-
ptr: 是真实数据存储的引用,它指向对象的内部数据结构。比如一个 string 的对象,内部可能是 sds 数据结构,那么 ptr 指向的就是 sds,除此之外,ptr 还可能指向 ziplist、quicklist、skiplist。
当存储String数据类型时,*ptr是指向SDS的,了解了RedisObject 与SDS结构体,我们再了解下Redis分配内存的机制,就能找到字符串长度以44个字节为emstr、raw分水岭的原因。(encoding 为int 就相对比较简单,ptr 直接指向了具体的数据,如下源码createStringObjectFromLongLongWithOptions)
先粗略看下以下方法(源码 object.c):
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
/* Create a string object with EMBSTR encoding if it is smaller than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT, otherwise the RAW encoding is
* used.
*
* The current limit of 44 is chosen so that the biggest string object
* we allocate as EMBSTR will still fit into the 64 byte arena of jemalloc. */
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
/* Same as CreateRawStringObject, can return NULL if allocation fails */
robj *tryCreateRawStringObject(const char *ptr, size_t len) {
sds str = sdstrynewlen(ptr,len);
if (!str) return NULL;
return createObject(OBJ_STRING, str);
}
/* Same as createStringObject, can return NULL if allocation fails */
robj *tryCreateStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return tryCreateRawStringObject(ptr,len);
}
/* Create a string object from a long long value. When possible returns a
* shared integer object, or at least an integer encoded one.
*
* If valueobj is non zero, the function avoids returning a shared
* integer, because the object is going to be used as value in the Redis key
* space (for instance when the INCR command is used), so we want LFU/LRU
* values specific for each key. */
robj *createStringObjectFromLongLongWithOptions(long long value, int valueobj) {
robj *o;
if (server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS))
{
/* If the maxmemory policy permits, we can still return shared integers
* even if valueobj is true. */
valueobj = 0;
}
if (value >= 0 && value < OBJ_SHARED_INTEGERS && valueobj == 0) {
incrRefCount(shared.integers[value]);
o = shared.integers[value];
} else {
if (value >= LONG_MIN && value <= LONG_MAX) {
o = createObject(OBJ_STRING, NULL);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*)((long)value);
} else {
o = createObject(OBJ_STRING,sdsfromlonglong(value));
}
}
return o;
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
从源码,我们可以了解到以下点:
- OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44 为emstr 与raw 的分界点
- 值大于LONG_MIN,小于LONG_MAX,encoding 为OBJ_ENCODING_INT,*ptr直接指向long型整数,否则使用raw类型
- createEmbeddedStringObject方法,分配内存时,采用SDS sdshdr8,除了buf数组,其他部分至少需要开销3个字节
内存分配zmalloc方法有什么玄机?
源码zmalloc.c
/* Explicitly override malloc/free etc when using tcmalloc. */
#if defined(USE_TCMALLOC)
#define malloc(size) tc_malloc(size)
#define calloc(count,size) tc_calloc(count,size)
#define realloc(ptr,size) tc_realloc(ptr,size)
#define free(ptr) tc_free(ptr)
#elif defined(USE_JEMALLOC)
#define malloc(size) je_malloc(size)
#define calloc(count,size) je_calloc(count,size)
#define realloc(ptr,size) je_realloc(ptr,size)
#define free(ptr) je_free(ptr)
#define mallocx(size,flags) je_mallocx(size,flags)
#define dallocx(ptr,flags) je_dallocx(ptr,flags)
#endif
Redis在编译时,会先判断是否使用tcmalloc,如果是,会用tcmalloc对应的函数替换掉标准的libc中的函数实现。其次会判断jemalloc是否使得,最后如果都没有使用才会用标准的libc中的内存管理函数。
jemalloc作为Redis的默认内存分配器,在减小内存碎片方面做的相对比较好。jemalloc在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存储数据时,会选择大小最合适的内存块进行存储。jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。
当存储字符串长度以44个字节时,RedisObject与SDS可以一起一次分配连续内存,减少内存碎片,并减少分配次数。
以上作为基础,可以得出String 不同encoding的区别直接的区别,如下图。
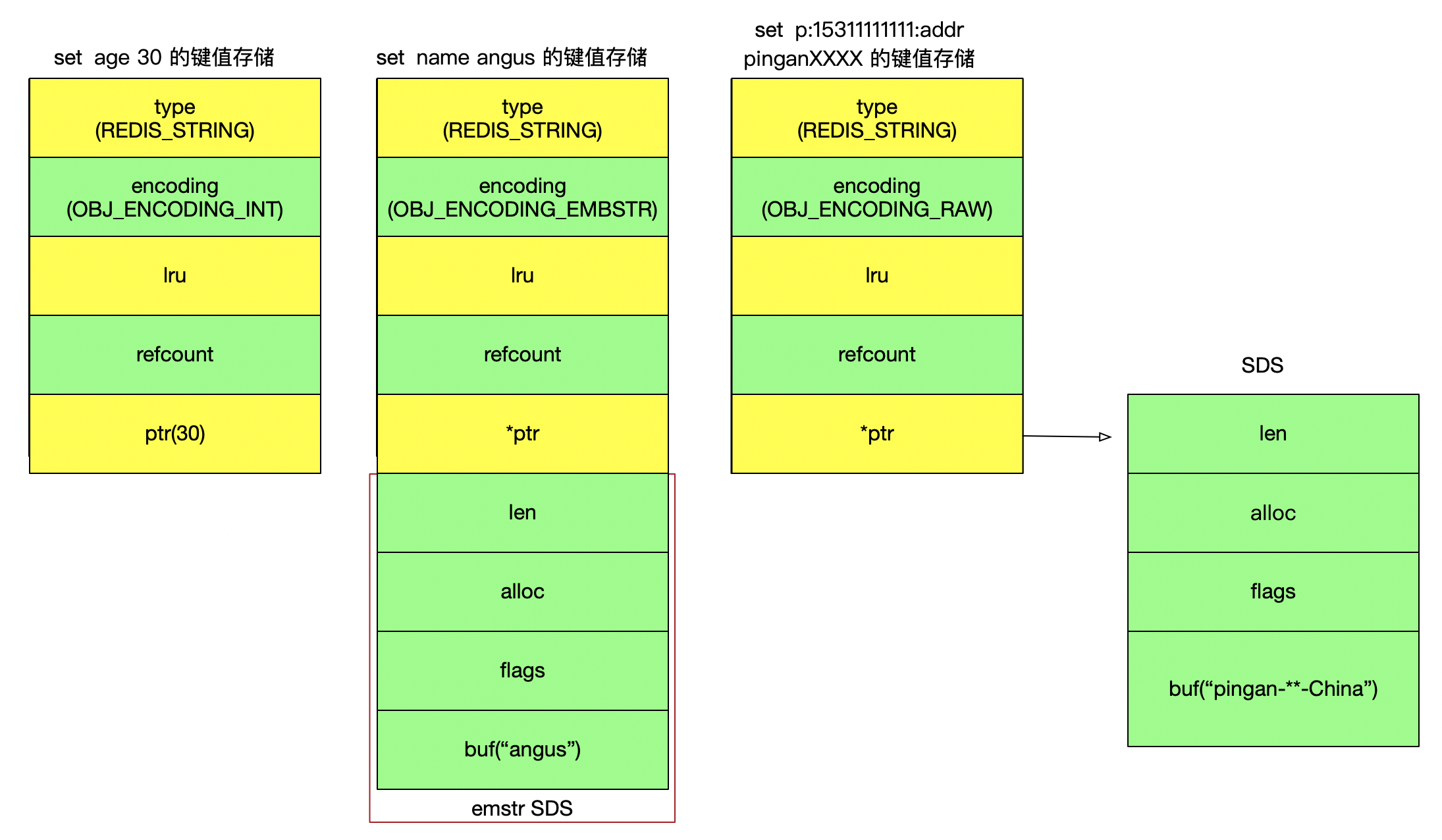
即:44个字节是按如下逻辑算出来的
-
redisObject占用空间16字节
4(type) + 4(encoding) + 24(lru) + 32(refcount) + 64(ptr) = 128bits = 16字节 -
sdshdr8占用空间4个字节
1(len) + 1(alloc)+ 1 (flag)+ 1(buf[]中结尾的’\0’字符)= 4字节
初始最小分配为64字节,所以只分配一次空间的embstr最大为 64 - 16- 4 = 44 字节。
回头看下开头提的问题2,相同数据量情况下,你能回答出 编码 int 与 raw 在内存占用上的差异吗?
encoding 为int 时,相比raw,1条记录至少可以节省16个字节,1亿条数据存在 Redis,可以节省 1.6GB内存
3. 久闻大名的BitMap、布隆过滤器
BITMAP
先看如下操作,Redis bitmap 的本质,底层使用String 类型来支持,并且encoding是raw
127.0.0.1:7003> setbit u:login:angus:2205 0 1
1
127.0.0.1:7003> getbit u:login:angus:2205 0
1
127.0.0.1:7003> type u:login:angus:2205
string
127.0.0.1:7003> object encoding u:login:angus:2205
raw
127.0.0.1:7003> debug object u:login:angus:2205
Value at:0x7ff2fb0044e0 refcount:1 encoding:raw serializedlength:2 lru:10416032 lru_seconds_idle:146
实操1:实现一个需求,一亿用户,连续10天登陆的用户有多少人?
实现思路
a. 每天为一个key ,每个 key 对应一个 1 亿位的 Bitmap,每一个 bit 对应一个用户当天的签到情况比
b. 通过bitop AND 命令求10 个key 的交集,只有 10 天都签到的用户对应的 bit 位上的值才会是 1
c. 通过bitcount 命令,则可以算出连续登录的用户数
扩展: 计算下内存开销
1亿个Bit位,100,000,000/(810241024) 约12M,再乘以10天,约120M,内存开销是比较小的。
实操2:求一个用户每月登录的天数
127.0.0.1:7002> setbit u:login:angus:2205 1 1
-> Redirected to slot [15068] located at 127.0.0.1:7003
0
127.0.0.1:7003> setbit u:login:angus:2205 0 1
0
127.0.0.1:7003> setbit u:login:angus:2205 2 1
0
127.0.0.1:7003> setbit u:login:angus:2205 3 1
0
127.0.0.1:7003> setbit u:login:angus:2205 4 1
0
127.0.0.1:7003> setbit u:login:angus:2205 5 1
0
127.0.0.1:7003> setbit u:login:angus:2205 6 1
0
127.0.0.1:7003> setbit u:login:angus:2205 7 1
0
127.0.0.1:7003> setbit u:login:angus:2205 8 1
0
127.0.0.1:7003> setbit u:login:angus:2205 9 1
0
127.0.0.1:7003> setbit u:login:angus:2205 10 1
0
127.0.0.1:7003> setbit u:login:angus:2205 12 1
0
127.0.0.1:7003> bitcount u:login:angus:2205
11
127.0.0.1:7003> bitfield u:login:angus:2205 get u31 0
2146697216
127.0.0.1:7003> bitpos u:login:angus:2205 0
11
127.0.0.1:7003> bitpos u:login:angus:2205 1
0
- 登录的天数设置为1,1~31日,登录则记录为1,即setbit key offset 1
- bitcount key 可算已经登录过的天数和
- bitfield 计算31位,结果为有符号数的计算十进制值2146697216 ,转二进制是:1111111111101000000000000000000 【31位】
即31天中,第11天以及13日后都没登录 - bitpos 计算出现第一个0或1的位置
Redis布隆过滤器
它是redis bitmap的一种应用场景,可以告诉你某样东西一定不存在或者可能存在
业务场景:防止没在缓存/DB内的数据查询请求打到Redis及数据库,造成Redis/DB的压力,可以用来解决缓存穿透问题。
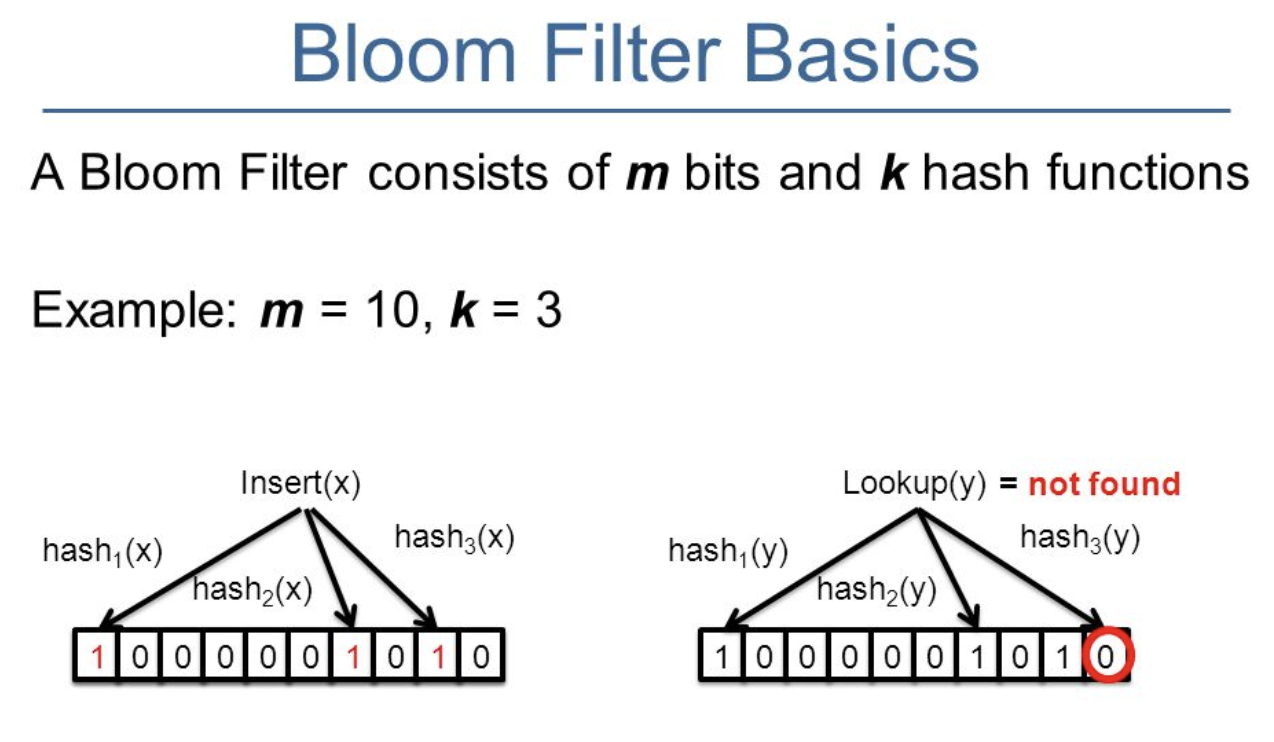
实现原理: 通过缓存数据多次hash,生成多个hashcode,将该hashcode与位数组长度做取余运算,最终得到一个位数组位置,并将该位置的值变为 1。每个 hash 函数都会计算出一个不同的位置,然后把数组中与之对应的位置变为 1。
借网上一幅图说明一下:
二、使用注意点
- Values can be strings (including binary data) of every kind, for instance you can store a jpeg image inside a value. A value can’t be bigger than 512 MB.(value的大小不能超过512MB)
三、总结
- 底层Redis String类型的编码有三种int、embstr、raw
- RedisObject 是所有底层编码类型的包装类型
- 目前redis中的共享对象只包括10000个整数(0-9999)【可配置调整】,是否能勾起你对Java 整数缓存区的记忆。
- bitmap 的 type 是String类型,encoding 是raw
- 布隆过滤器是借助redis bitmap 实现的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









