






 InfluxDB是一款开源的时序型数据库,适用于存储带时间戳的大量数据,尤其适合监控和日志场景。其特点包括无模式、支持多种聚合函数和类SQL查询。本文介绍了InfluxDB的名词解释,如database、measurement、point等,详细讲解了存储组件如Cache、WAL、TSM File和Compactor的工作原理,以及安装、操作命令、JAVA API使用和数据保留策略等内容。
InfluxDB是一款开源的时序型数据库,适用于存储带时间戳的大量数据,尤其适合监控和日志场景。其特点包括无模式、支持多种聚合函数和类SQL查询。本文介绍了InfluxDB的名词解释,如database、measurement、point等,详细讲解了存储组件如Cache、WAL、TSM File和Compactor的工作原理,以及安装、操作命令、JAVA API使用和数据保留策略等内容。
简介
InfluxDB是用Go语言编写的一个开源时序型数据库,使用时无需外部依赖,用于存储大量带有时间戳的数据。特别适合大型分布式系统的监控系统,存储日志和监控数据,简单理解为按时间序列记录一些数据(常用的指标数据、统计数据等)。
主要特点
- 数据无结构(无模式):列的数量可以任意
- 支持min, max, sum, count, mean, median等一系列聚合函数
- 原生的HTTP支持,内置HTTP API
- 强大的类SQL语法
- 自带管理界面,方便使用
注意:自带管理界面与集群功能在1.2版之后,将不再提供。
名词解释
- database — 数据库,同传统数据库中的数据库概念
- measurement — 数据表,同传统数据库中的table概念
- point — 数据表里的一行数据,由time(时间戳)、tag(标签)、field(数据)组成。详细如下表:
time(时间戳) 每条数据的记录时间,是数据库中的主索引(可以自动生成)
tag(标签) 有索引的值:如系统名称、服务名称等,”key-value”形式。其中表名+tag构成索引。
field(字段、数据) 没有索引的记录值:如耗时,是否成功等,”key-value”形式。
注意:
- 在influxdb中,field字段必须存在。field是没有索引的,如果使用field中字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。
- tag是可选的,但是强烈建议适度使用,因为tag是有索引的,tag相当于SQL中的有索引的列。tag value只能是string类型。
- series — 序列,一些数据的集合。在同一个 database 中,retention policy、measurement、tags完全相同的数据同属于一个 series,同一个 series的数据在物理上会按照时间顺序排列存储在一起。
举个简单的例子,service_record的数据如下:

service_record的series如下:

- retention policy — 数据保留策略,定义数据保留的时长,可以当作清理策略使用。每个数据库可以有多个数据保留策略,但只能有一个默认策略。
- shard
shard 和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复;
例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。
存储组件
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
Cache
cache 相当于是 LSM Tree 中的 memtable。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
WAL
wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
TSM File
单个 tsm file 大小最大为 2GB(默认值),用于存放数据。
Compactor
compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。主要进行两种操作:
- cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
- 合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大容量,减少文件的数量,并且数据的清理操作也同时完成。
安装
InfluxDB不需要安装。下载好InfluxDB程序包,解压后配置好即可使用。我使用的是1.7.8版本,解压后生成etc、usr、var 3个目录,主要目录解析如下:
/usr/bin下文件
文件名 文件解析
influxd influxdb服务端命令
influx influxdb客户端命令
influx_inspect 查看工具
influx_stress 压力测试工具
influx_tsm 数据库转换工具(将数据库从b1或bz1格式转换为tsm1格式)
/var/lib/influxdb下文件夹
文件夹 文件夹解析
data 存放最终存储的数据,文件以**.tsm**结尾
meta 存放数据库元数据
wal 存放预写日志文件
注:/var/lib/influxdb为默认路径,data,meta,wal文件路径可在influxdb配置文件中自行配置。
/etc/influxdb下文件
文件 文件解析
influxdb.conf influxdb配置文件
操作命令
启动服务
cd /usr/bin
./influxd –config {$INFLUXDB_PATH}/etc/influxdb/influxdb.conf &
其中{$INFLUXDB_PATH}为influxdb安装路径。
通过查看服务对应进程查看服务是否正常启动:

数据库操作
进入/usr/bin目录,运行 ./influx 进入InfluxDB客户端运行命令模式:

显示数据库:show databases
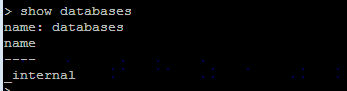
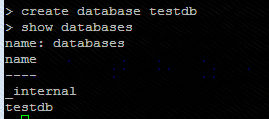
新建数据库 create database <db_name>
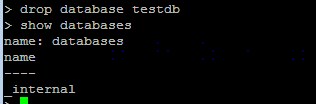
删除数据库 drop database <db_name>
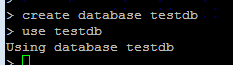
使用数据库 use < db_name>
数据表操作
InfluxDB中没有表(table)这个概念,取而代之的是measurement,measurement的功能与传统数据库中的表一致,因此我们也可以将measurement称为InfluxDB中的表。
显示所有表 show measurements
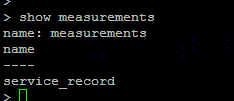
写入数据
InfluxDB中没有创建表的语句,只能通过insert数据的方式来建立新表。写入数据格式如下:
insert <measurement>,tag_key=tag_value[,…] filed_key=field_value[,…]
其中 是表名,表名与数据之间用逗号(,)分割,tag与field之间用空格分隔,多个tag或者多个field之间用逗号(,)分隔。其中tag与field格式为key=value格式。如下:
insert "service_record","service_id"=8 "end_time"=1571731168085,"endpoint_id"=3,"latency"=4

上图中service_record是表名,service_id=是索引(tag),“end_time”=,“endpoint_id”=,“latency”=,… 是记录值(field)。添加数据时,时间戳可以自己指定,也可以系统自动生成。
删除表
drop measurement <measurement>
数据保存策略(Retention Policies)
InfluxDB 是没有直接删除数据记录的方法,但是提供了数据保存策略,主要用于指定数据保留时间,超过指定时间,就清理掉过期数据。
查看当前数据库所有的保存策略
show retention policies on <db_name>
<db_name>是数据库名称。

其中,
name:名称,此示例名称为 default。
duration:持续时间,0代表无限制。
shardGroupDuration:shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。
replicaN:全称是replication,副本个数。
default:是否是默认策略。
创建新的Retention Policies
create retention policy <rp_name> on <db_name> duration <time> replication * default
<rp_name>:策略名。
<db_name>:数据库名。
修改Retention Policies
alter retention policy <rp_name> on <db_name> ****
删除Retention Policies
drop retention policy <rp_name> on <db_name>
连续查询(Continuous Queries)
InfluxDB 的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 select 关键字 和 group by time() 关键字。InfluxDB 会将查询结果放在指定的数据表中。
使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低 InfluxDB 的存储占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
新建连续查询
create continuous query <cq_name> ON <database_name>
[RESAMPLE [EVERY <interval>] [FOR <interval>]]
begin
select <function>(<stuff>)[,<function>(<stuff>)] INTO <new_measurement>
from <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>]
end

在 ** 库中新建了一个名为 wj_1h 的连续查询,每一个小时取service_record表中字段latency的平均值、字段endpoint_id的个数存入 service_hour 表中。使用的数据保留策略都是“default”。
显示所有已存在的连续查询
show continuous queries
删除Continuous Queries
drop continuous query <cq_name> on <database_name>
JAVA API操作
1. pom.xml中导入jar包依赖
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>${influxdb.version}</version>
</dependency>
2. 创建连接
/*创建连接,获得InfluxDB**/
public InfluxDB influxDbBuild(){
if(influxDB == null){
influxDB = InfluxDBFactory.connect(openurl, username, password);
influxDB.createDatabase(database);
}
return influxDB;
}
3. 设置数据保存策略
/**
* 设置默认数据保存策略
* name 策略名
* database 数据库名
* duration 数据保存时限,0代表无限制
* replicaN 副本个数
*/
public void createRetentionPolicy(String name, String database, String duration,int replicaN){
String command = String.format("CREATE RETENTION POLICY \"%s\" ON \"%s\" DURATION %s REPLICATION %s DEFAULT", name, database, duration, replicaN);
this.query(command);
}
4. 查询记录
/**
* 查询
* @param command 查询语句
* @return
*/
public QueryResult query(String command){
return influxDB.query(new Query(command, database));
}
5. 插入数据
/**
* 插入
* @param tags 标签
* @param fields 字段
* @param time 时间戳,可不输
*/
public void insert(Map<String, String> tags, Map<String, Object> fields, long time){
Builder builder = Point.measurement(measurement);
builder.tag(tags);
builder.fields(fields);
if (time != 0l) {
builder.time(time, TimeUnit.MILLISECONDS);
}
influxDB.write(database, "", builder.build());
}
总结
综上,总结了以下InfluxDB的使用心得:
- 类SQL操作,简单方便,易于学习与操作。
- 没有细分表的概念,在插入数据时自动创建measurement.
- 数据没有更新操作,只支持新增与查询,效率高。
- 默认配置不开启用户认证,可在创建用户后开启认证。
- 提供丰富的聚合查询功能。GroupBy time按时间段查询,特别适合监控系统。
- 提供连续查询和数据保留功能,可以保存近期高精度数据和长期低精度数据。无需另行清理历史数据。
- 1.0版本后只有单机版免费,集群版需要收费。
以上为个人观点,仅供参考,谢谢。

















 8274
8274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









