







csdn排版丢失,建议原文查看:【源码分析】RAGFlow中偷偷调用的LLM和调优策略
最近RAGFlow交流群里,有群友发现chunk过程中,调用了LLM chat,本文就来分析一下,RAGFlow在知识库建立过程中,为什么调用了LLM chat,调用的位置,以及默认调用的参数如何调整。
本文针对0.16.0 branch
一、RAGFlow中定义的大模型类型
ragflow默认支持以下几类模型:
-
chat对话类模型:如Qwen2.5、DeepSeek V3、DeepSeek R1等
-
speech2text语音转文字类转录模型:如whisper等
-
rerank重排模型:如bge-reranker-v2-m3等,注:目前不支持Ollama导入rerank,隔壁dify也不支持
-
tts文本转语音模型:参考文章TTS模型汇总,强烈建议收藏,内推模型全部经过本人实测有效
# 在api\db\__init__.py中定义
class LLMType(StrEnum):
CHAT = 'chat'
EMBEDDING = 'embedding'
SPEECH2TEXT = 'speech2text'
IMAGE2TEXT = 'image2text'
RERANK = 'rerank'
TTS = 'tts'下面主要针对RAGFlow源码在执行知识库构建任务过程中,偷偷用到的LLM chat模型的地方进行解析。
二、知识库构建源码分析及知识库构建调优建议
RAGFlow 知识库构建的核心代码在rag\svr\task_executor.py中,其核心内容是知识库构建task的处理,即do_handle_task(task)这个函数中的逻辑。
-
该函数首先进行知识库初始化操作,注意,这里目前不支持进行table解析
Table parsing method is not supported by Infinity, please use other parsing methods or use Elasticsearch as the document engine. -
其次针对不同的知识库构建方法,分别进行处理,主要分为5类任务(RAPTOR、GraphRAG、GraphResolution、GraphCommunity、一般embedding任务等),如下图所示:
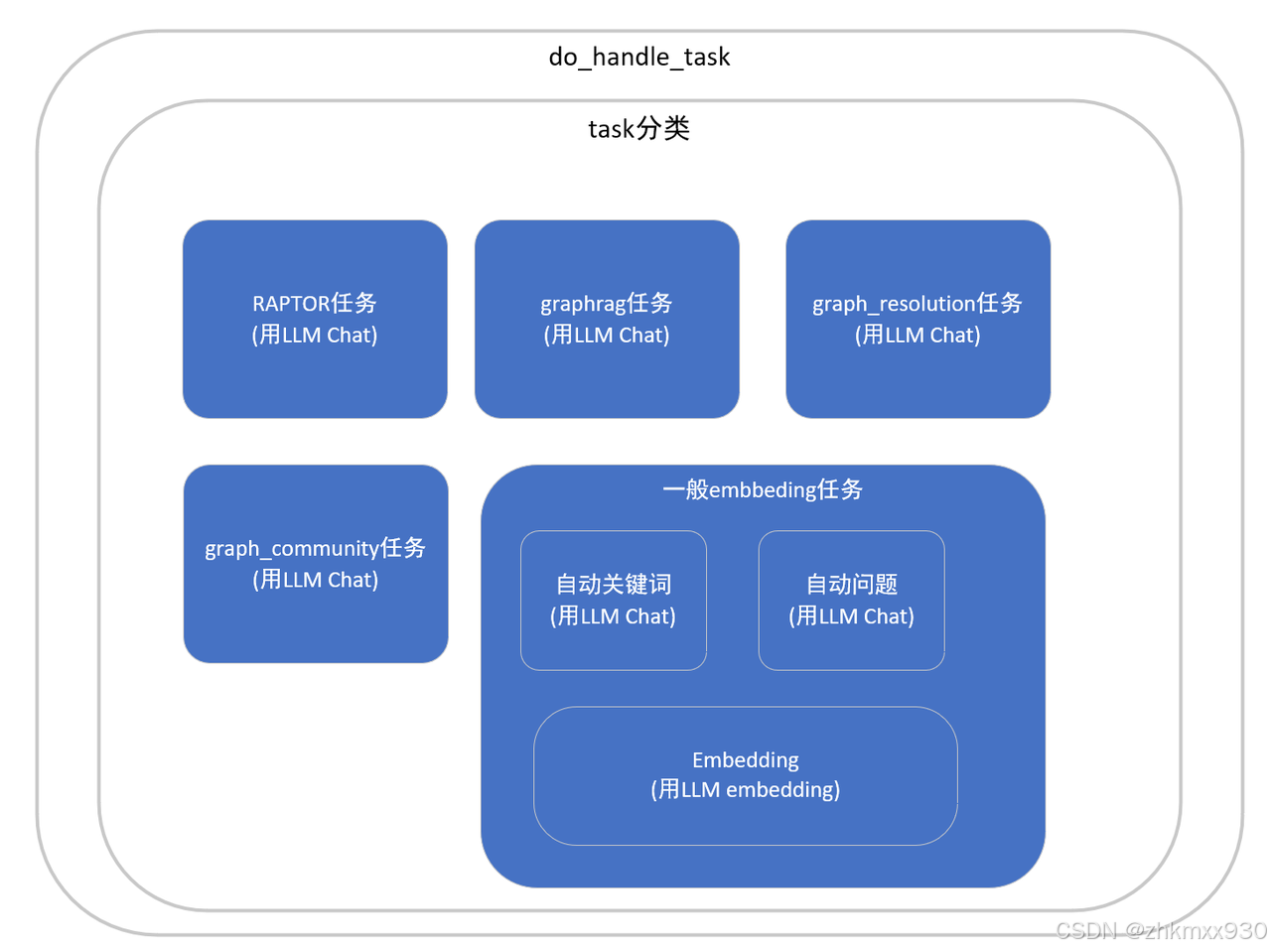
-
RAPTOR任务源码分析及优化建议:
RAGFlow中的RAPTOR运用LLM进行摘要summary的生成,具体代码块如下:RAPTOR的原理可以参考这篇文章长文本的高效处理:RAPTOR 检索技术及其在 RAG 中的应用。



-
rag\svr\task_executor.py的do_handle_task(task)函数中,raptor任务分支中定义了chat model -
随后在
rag\raptor.py中,调用了chat模型,生成response,并且过滤掉了推理模型的think标签。 -
最终,在
rag\raptor.py中,通过summarize调用chat model结果,注意这里的模型温度参数是固化的为0.3,有需要调整的,要在这里修改源码,然后重新启动ragserver的docker或者启动对应的nginx服务,以确保修改成功;或者选择用0.3 temp合理的llm chat模型作为系统模型,以达到更好的效果。 -
RAPTOR任务源码分析及优化建议:
-
-
-
GraphRAG任务源码分析及优化建议:
GraphRAG的原理可以参考这篇文章微软 GraphRAG :原理、本地部署与数据可视化揭秘——提升问答效率的图谱增强策略。
RAGFlow中的GraphRAG运用LLM,对抽取的实体关系图谱结果进行总结优化生成,具体代码块如下:
-
rag\svr\task_executor.py的do_handle_task(task)函数中,graphrag任务分支中定义了chat model

-
随后在
rag\svr\task_executor.py中的run_graphrag函数中,调用了Graphrag算法,若用户配置的为general方法,则调用微软的GraphRAG模型,否则调用的是Light RAG模型。

-
最终,在
graphrag\general\extractor.py中,通过_handle_entity_relation_summary调用chat model结果,注意这里的模型温度参数是固化的为0.8,有需要调整的,要在这里修改源码,然后重新启动ragserver的docker或者启动对应的nginx服务,以确保修改成功;或者选择用0.8 temp合理的llm chat模型作为系统模型,以达到更好的效果。

-
GraphResolution任务源码分析及优化建议:
GraphResolution任务实现了基于图结构的实体解析(Entity Resolution)方法,主要功能是识别图中的实体是否表示相同的对象,并合并重复的实体。原理可以参考这篇文章论文阅读:Robust Entity Resolution using Random Graphs
RAGFlow中的GraphResolution运用LLM,对实体解析结果进行总结优化生成,具体代码块如下:
-
rag\svr\task_executor.py的do_handle_task(task)函数中,graph_resolution任务分支中定义了chat model

-
随后在
graphrag\entity_resolution.py中的实体解析类EntityResolution中,继承Extractor类,该类定义了父类方法_chat,用于定义大模型,同样只收集大模型生成的结果,而去除了<think>标签。

-
最终,在
graphrag\entity_resolution.py中的实体解析类EntityResolution中,通过__call__,在实体解析完成后,调用chat model,优化生成实体解析结果,注意这里的模型温度参数是固化的为0.5,有需要调整的,要在这里修改源码,然后重新启动ragserver的docker或者启动对应的nginx服务,以确保修改成功;或者选择用0.5 temp合理的llm chat模型作为系统模型,以达到更好的效果。

-
GraphCommunity任务源码分析及优化建议:
GraphCommunity任务实现了图社区发现方法,主要功能是一种用于识别图(网络)中社区结构的算法。社区结构是指图中的节点(顶点)可以自然地划分为若干个子群体(社区),使得每个社区内部的节点之间连接紧密,而不同社区之间的连接相对稀疏。图社区检测算法的目标是自动发现这些社区结构,从而揭示图中的内在组织形式和潜在模式。原理可以参考这篇文章图机器学习(网络中的社区检测)
RAGFlow中的GraphCommunity运用LLM,对图社区检测算法结果进行总结优化生成,具体代码块如下:
-
rag\svr\task_executor.py的do_handle_task(task)函数中,graph_community任务分支中定义了chat model

-
随后在
graphrag\general\community_reports_extractor.py中的图社区检测类CommunityReportsExtractor中,继承Extractor类,该类定义了父类方法_chat,用于定义大模型,同样只收集大模型生成的结果,而去除了<think>标签。

-
最终,在
graphrag\general\community_reports_extractor.py中的图社区检测类CommunityReportsExtractor中,通过__call__,在图社区检测算法完成后,调用chat model,优化生成图社区检测结果,注意这里的模型温度参数是固化的为0.3,有需要调整的,要在这里修改源码,然后重新启动ragserver的docker或者启动对应的nginx服务,以确保修改成功;或者选择用0.3 temp合理的llm chat模型作为系统模型,以达到更好的效果。

-
一般Embbeding任务源码分析及优化建议:
一般embedding过程采用Naive RAG基本过程(参考:最优化大模型效果之 RAG(一):Naive RAG),先进行chunk生成文本块,再将分块进行embedding处理。
RAGFlow,在chunk配置的时候,可以配置自动关键词(Auto Keyword)、自动问题(Auto Question)。其取Top N,在界面可配置N值。

当用户启用这两个值后,系统后台也是默认调用了LLM Chat具体原理如下:
-
rag\svr\task_executor.py的do_handle_task(task)函数中,else分支中使用了chunk构建方法

-
在
rag\svr\task_executor.py中的build_chunks,看到自动关键词以及自动问题处理中,都调用了LLM Chat
-
其中自动关键词,通过在
api\db\services\dialog_service.py中,调用函数keyword_extraction,进行关键词总结与排序,完全通过llm实现,具体prompt见下面的代码。注意这里的模型温度参数是固化的为0.2,有需要调整的,要在这里修改源码,然后重新启动ragserver的docker或者启动对应的nginx服务,以确保修改成功;或者选择用0.2 temp合理的llm chat模型作为系统模型,以达到更好的效果。

-
其中自动问题,通过在
api\db\services\dialog_service.py中,调用函数question_proposal,进行关键词总结与排序,完全通过llm实现,具体prompt见下面的代码。注意这里的模型温度参数是固化的为0.2,有需要调整的,要在这里修改源码,然后重新启动ragserver的docker或者启动对应的nginx服务,以确保修改成功;或者选择用0.2 temp合理的llm chat模型作为系统模型,以达到更好的效果。

三、总结
本文详细分析了RAGFlow在知识库构建过程中调用LLM Chat模型的场景、位置及默认参数,并提供了优化建议。用户可以通过修改源码或选择合适的LLM模型来调整参数,以达到更好的效果。

















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









