







 本文详细介绍了Spark SQL中各种数据源的使用方法,包括Parquet、Hive、JDBC等,并探讨了性能优化技巧和自定义数据源的方法。
本文详细介绍了Spark SQL中各种数据源的使用方法,包括Parquet、Hive、JDBC等,并探讨了性能优化技巧和自定义数据源的方法。
第一章:上次课回顾
第一章:上次课回顾
https://blog.youkuaiyun.com/zhikanjiani/article/details/95337745
从源端把数据加载进来,不管是采用Map Reduce、Hive、Spark计算引擎,把数据加载至目标端

1)数据文件格式
2)数据可能在本地/HDFS/S3
eg:源端JSON格式,解析出来变成文本,借助于JSON的工具进行JSON的处理,比如JSON今天有10个字段,明天有11个字段,后天有13个字段,由于JSON是key、value存储,还真不一定。这种场景工作中比较多;处理麻烦。
load data ==>… ==>save data
在Spark中外部数据源就出生了,Spark1.2版本中出现。
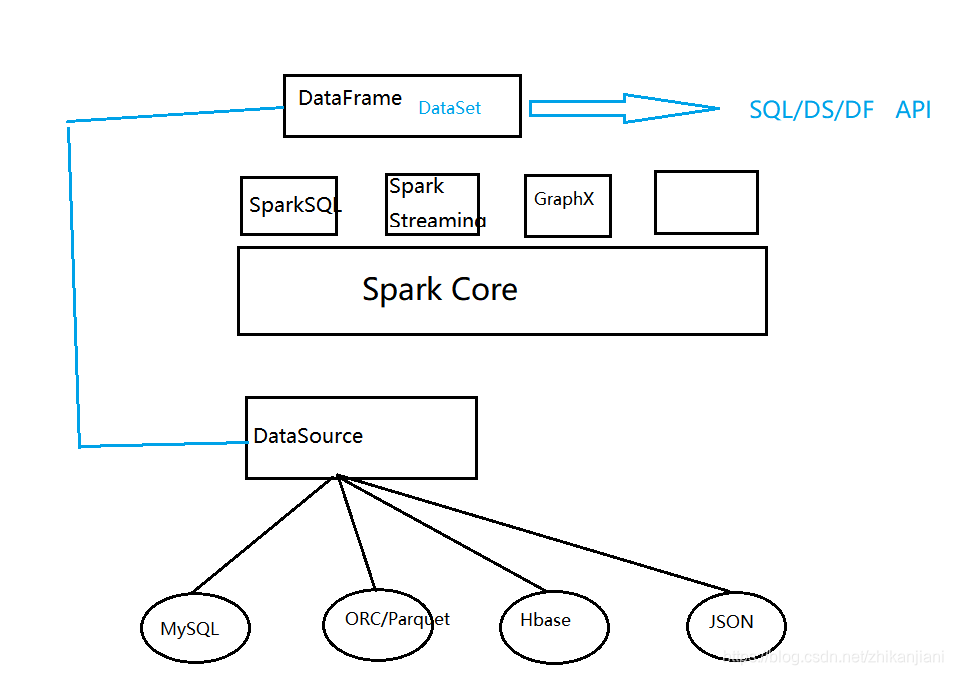
DataSource:
1、Spark SQL supports operating on a variety of data sources through the DataFrame interface.
译:Spark SQL支持通过DataFrame接口来操作各种外部数据源。
2、A DataFrame can be operated on using relational transformations and can also be use to create a temporary view.
译:一个DataFrame能够使用关系型转换、创建一个临时视图。
3、Registering a DataFrame as a temporary view allows you to run SQL queries over its data.
译:以临时视图的方式注册成一个DataFrame后允许你跑SQL在这个数据上。
4、This section describes the general methods for loading and saving data using the Spark Data Sources and then goes into specific options that are available for the built-in data sources.
本节描述的是加载数据的两种方式:外部数据源和内置的数据源
一、Parquet Files:
概念:Parquet is a columnar format that is supported by many other data processing systems. Spark SQL provides support for both reading and writing Parquet files that automatically preserves the schema of the original data. when writing Parquet files, all columns are automatically converted to be nullable for compatibility reasons.
Parquet是一种列式格式能够被支持在很多其他的数据处理系统上,Spark SQL提供了两种读写的Parquet,它能够自动保存原始数据的schema信息。
在spark-shell下测试操作:
1、val peopleDF = spark.read.format(“json”).load(“file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json”)
2、peopleDF.show
3、要把json格式转换成parquet格式,先把这数据写出去,
官网写法:peopleDF.write.parquet(“people.parquet”)
我们自己写如下写法:
peopleDF.write.format(“parquet”).save(“file:///home/hadoop/data/df/people.parquet”)
4、我们此时看不见parquet这个数据,我们再读出来
spark.read.format(“parquet”).load(“file:///home/hadoop/data/df/peopleparquet”).show 再读出来
5、注册成视图:peopleDF.createOrReplaceTempView(“people”) 注册成视图后要重命名一下。
6、执行:spark.sql(“select * from people”).show
也可以执行符合语句:spark.sql(“select name from people where age between 15 and 20”)
scala> spark.sql("select name from person where age between 15 and 20")
res10: org.apache.spark.sql.DataFrame = [name: string]
scala> spark.sql("select name from person where age between 15 and 20").show
+------+
| name|
+------+
|Justin|
+------+
报错:./spark-shell --jars ~/software/mysql-jar包所在路径
再一次把DF加载进来。
二、Partition Discovery(分区探测):
1、Table partitioning is a common optimization approach used in systems like Hive.
译:表分区是一种常见的优化方式在系统中使用如Hive.
2、In a partitioned table, data are usually stored in different directories,with partitioning column values encoded in the path of each partition directory.
译:在一个分区表中,数据通常被存储在不同的目录中,在每个分区目录的路径中编码分区列的值。
自行到hdfs上查看分区信息,找一个分区表,分区表的目录:/XX.db/table/day=20190722/hour=1630
3、All built-in file sources(including text/CSV/JSON/ORC/Parquet) are able to discover and infer partitioning information automatically. For example, we can store all our previously used population data into a partitioned table using following directory structure, with two extra columns, gender and country as partitioning columns.
译:所有内置的这些格式的source都能够被探测到然后能够自动搞得推测出分区信息。
举例:我们可以使用如下的目录结构来存储所有我们以前的人口数据在一个分区表中,使用额外的两列,姓名和国家作为分区列。

By passing path/to/table to either SparkSession.read.parquet or SparkSession.read.load, Spark SQL will automatically extract the partitioning information from the paths. Now the schema of the returned DataFrame becomes:
我们使用sparksession.read.parquet或者SparkSession.read.load这两种方式到path/to/table这个路径,SparkSQL会自动的从路径上把分区信息赶过来。
实际测试:hdfs上创建这三个目录:
hadoop fs -mkdir -p /sql/table/gender=male/country=US
hadoop fs -mkdir -p /sql/table/gender=male/country=CN
hadoop fs -mkdir -p /sql/table/gender=female/country=US
进入到如下目录:cd $SPARK_HOME/examples/src/main/resources
上传文件:hadoop fs -put users.parquet /sql/table/gender=male/country=US
在启动的spark-shell中指定如下格式:打印出它的数据结构信息
spark.read.format(“parquet”).load(“hdfs://hadoop002:9000/sql/table”).printschema
我们注意到数据类型在分区列中能够被自动推导出,目前,numeric data types,date,timestamp,和String type被支持。有时候用户可能不想分区列中的数据类型被自动推导出,可以通过如下设置:spark.sql.sources.partitionColumnTypeInference.enabled,which is default to true
## Schema Merging(不是很重要)
概念:schema merge是一个成本非常高的操作,从1.5.0开始默认是关的;不建议使用
三、ORC Files
直接在Spark-shell中测试:
spark.read.format(“orc”).load(“hdfs://hadoop002:9000/user/hive/warehouse/page_orc”).show(10)
spark.sql(“select * from page_orc limit 10”).show
spark.sql(“show tables”).show(false)
注意:打印的表中有一个是临时表,表名是people,是我们使用json转换为parquet时注册的一个临时表,我们把当前客户端关掉,这张表就会没有的。
四、Hive Tables:
1、Spark SQL also supports reading and writing data stored in Apache Hive.
Spark SQL对于存储在Hive上的数据支持读和写。
2、However,Since Hive has a large number of dependencies, these dependencies are not included in the default Spark distribution
但是,Hive有很多的依赖,这些依赖并不一定都包含在默认的Spark安装包中。
3、If Hive dependencies can be found on the classpath, Spark will load them automatically.
如果Hive的依赖能够在classpath中被找到,spark将会自动加载他们。
4、Note that these Hive dependencies must also be present on all of the worker nodes, as they will need access to the Hive serilaization and deserialization libraries(SerDes) in order to access data stored in Hive.
我们注意到这些Hive依赖一定要存在于这些worker节点,他们需要获取到hive的序列化和反序列化的libraries为了得到存储在Hive中的数据。
5、Configuration of Hive is done by placing your hive-site.xml, core-site.xml,hdfs-site.xml
file in conf/ 扩充一个概念:gateway,gateway里都有core-site.xml和hdfs-site.xml
6、When working with Hive. one must instantiate SparkSession with Hive support, including connectivity to a persistent Hive metastore, support for Hive serdes, and Hive user-defined functions.
Users who do not have an existing Hive deployment can still enable Hive support when not configured by the hive-site.xml , the context automatically creates metastore_db in the current directory and creates a directory configured by spark.sql.warehouse.dir
翻译:用户并不需要一个已经存在的HIve部署,如果你想要去开启;如果配置没有Hive-site.xml,会在当前目录下自动刚创建一个metastore_db。
要访问Hive,必须在上面添加一个
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("")
.appName("")
.enableHiveSupport() //这个必须要开启
.getOrCreate
}
实际测试在spark-shell中:
1、导入隐式转换和SPARK-SQL:
import spark.implicits._
import spark.sql
注意此处启动spark-shell时驱动既要指定到path也要指定到ClassPath中,使用如下命令。
spark-shell --jars /home/hadoop/lib/mysql-connector-java-5.1.46-bin.jar --driver-class-path /home/hadoop/lib/mysql-connector-java-5.1.46-bin.jar
2、sql(“CREATE TABLE IF NOT EXISTS src (key INT, value String) using hive”)
创建了src表,会自动找到 /user/hive/warehouse这个目录
scala> sql("CREATE TABLE IF NOT EXISTS src (key INT, value String) using hive")
19/07/19 15:04:31 WARN metastore.HiveMetaStore: Location: hdfs://10.0.0.132:9000/user/hive/warehouse/src specified for non-external table:src
res0: org.apache.spark.sql.DataFrame = []

使用HIVE中的语句加载数据进入src表
3、sql(“LOAD DATA LOACL INPATH ‘/home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/kv1.txt’ INTO TABLE src”)
4、直接查询数据
sql(“select * from src”).show()
sql(“show tables”).show(false) //这是一个物理表

1、导入列:
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
2、SQL查询的结果本身就是DataFrame,支持所有正常的功能
val sqlDF = sql(“select key,value from src where key < 10 order by key”)

3、the items in DataFrames are of type Row, which allows you to access each column by
DataFrame中的项是ROW类型的,它允许你按序号访问每一列
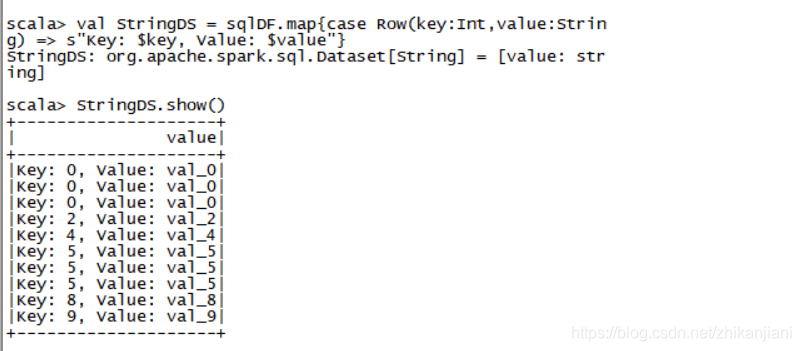
val StringDS = sqlDF.map{
case Row(key:Int,value:String) => s"Key: $key, Value: $value"
}
4、把数据show出来
StringDS.show()
# JDBC To Other Databases***
概述:Spark SQL also includes a data source that read data from other databases using JDBC. This functionality should be preferred over using JdbcRDD. This is because the resullts are returned as a DataFrame and they can easily be processed in Spark SQL or Joined with other data sources. The JDBC data source is also easier to use from Java or Python as it does not require the user to provide a classTag.
(Note that this is different than the Spark SQL JDBC server, which allows other applications to run queries using Spark SQL)
翻译:Spark SQL 同样支持数据源能够通过JDBC去读取其它数据库的数据(MySQL、Oracle)。这个方式应该被首选通过使用JdbcRDD,这是因为这个结果被返回成为一个DataFrame和我们能够很容易的在Spark SQL中操作、可以和其它数据源进行各种join。这种JDBC的数据源很容易使用Java或者Python正如它允许用户提供一个ClassTag.
注意:这与Spark SQL JDBC服务不同,它允许其它应用使用Spark SQL查询
直接使用官网例子:
1、// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
object DataSourceApp{
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master(“local[2]”)
.appName(“DataSourceApp”)
.getOrCreate()
val TBLS = spark.read
.format(“jdbc”)
.option(“url”, “jdbc:mysql://10.0.0.132:3306/ruoze_d6”)
.option(“dbtable”, “tbls”)
.option(“user”, “root”)
.option(“password”, “960210”)
.load()
spark.stop
}
}
2、val DBS = spark.read
.format(“jdbc”)
.option(“url”, “jdbc:mysql://10.0.0.132:3306/ruoze_d6”)
.option(“dbtable”, “DBS”)
.option(“user”, “root”)
.option(“password”, “960210”)
.load()
3、写出SQL语句:
select DB_LOCATION_URI,NAME,TBL_TYPE from dbs a join tbls b on a.DB_ID = b.DB_ID;
仿照着上面写一遍TBLS = ???
4、DBS.join(TBLS,DBS(“DB_ID”) === TBLS(“DB_ID”)).select(“DB_LOCATION_URI”,“NAME”,“TBL_TYPE”).show(false);

我们可以拿关系型数据库、HIve和其它数据源的数据进行操作,此时多个不同数据源来的DF就可以做相应的关联操作。
还可以使用另外一种方式:
> 不建议使用JDBC.write的方式写,会产生各种问题
## 同样也可以在spark-shell中操作:
1、加入mysql驱动包
2、执行如下语句:
val jdbcDF = spark.read
.format(“jdbc”)
.option(“url”, “jdbc:mysql://10.0.0.132:3306/ruoze_d6”)
.option(“dbtable”, “TBLS”)
.option(“user”, “root”)
.option(“password”, “960210”)
.load()
五、Troubleshooting:
概念:The JDBC driver class must be visible(可见) to the primordial class loader on the client session and all executors. 意味着能访问的到
This is bacause Java’s DriverManager class does a security check(安全检查) that results in it ignoring all drivers not visible to the primordial class loader when one goes to open a connection. One convenient way to do this is to modify compute_classpath.sh on all worker nodes to include your driver JARs.
六、Performance Tuning(性能优化):
- Caching Data In Memory
- Other Configuration Options
- Broadcast Hint for SQL Queries
1、val emp = spark.read.text(“file:///home/hadoop/data/emp.txt”)
2、emp.cache
3、emp.count //此时是有cache
4、emp.unpersist //清除cache
一个参数:spark.sql.shuffle.partitions 默认的参数:200。如何在spark页面中体现和spark-shell中对应的位置;做join的时候体现了。
启动一个spark-sql,创建一个表:
1、create table dept(deptno int, dname string, loc string) row format delimited fields terminated by "\t";
2、load data local inpath '/home/hadoop/data/dept.txt' into table dept;
3、select * from dept;
4、select e.empno, e.ename, d.dname from emp e join dept d on e.deptno = d.deptno;
语句执行完后进入hadoop002:4040查看页面;有一个BroadCastHashJoin,
5、我们在spark-shell中修改参数set spark.sql.autoBroadcastJoinThreshold = -1
此时再进行join操作,去看DAG图和job页面。做了一个sortmerge,两个scan干了一个shuffle;参数设置与不设置性能会有很大区别
# 七、BroadCast Hint for SQL Queries:
## 概念:
eg:broadcast(spark.table("src")).join(spark.table("records"),"key").show()
问题:大小表搞错?
分割线:---------------------------------
## 扩展:
:存在如下几个外部数据源:Hive、JDBC、Hbase,电信运营商行业,很多数据存在MySQL中,
基本配置=>RDBMS,用户行为日志=>Hive/Spark SQL,那是不是每次都要去配置呢?
是否有这样一种机制,在我们spark启动的时候,我们想要的东西直接注册进来
==>我们可以直接使用。
在工作中很常见:
把很多东西都去配置好(WebUI)
==>Spark启动去读取配置信息,把他注册到Spark中。
==>后面使用的时候就可以直接进行操作。
# 八、Spark Packages
spark外部数据源集中整合的地方:
https://spark-packages.org
# 九、JDBC外部数据源如何实现
搜索:JDBCRelation.scala、JDBC外部数据源的执行流程
1、abstract class BaseRelation{
def sqlContext: SQLContext 传入SQLContext
def schema: StructType 传入一个结构
schema //构建schema后返回的是什么
val schema = JDBCRealtion.getSchema(resolver,jdbcOptios)
==>通过JDBC META获取到的
}
//select * from 读取数据
2、trait tableScan(){
def buildScan(): RDD[Row]
}
3、select a, b from 裁剪
trait PrunedScan{
def buildScan(requiredColumns: Array[String]): RDD[Row]
}
select a,b from XXX where a > 10 过滤条件
trait PrunedFilteredScan{
def buildScan(requiredColumns: Array[String],filters: Array[])
}
4、insert
RealtionProvider.scala
产生relation,创建relation。
Spark-sql处理要有对应的schema信息
对于Spark去处理JDBC数据源,就是拼SQL ==>通过JDBC API编程 ==> DataFrame
建议debug跑一下。
## 十、自定义外部数据源
我们通过文本让他给我们解析出来
编号 姓名 性别 月薪 年终奖
10000,PK,0,100000,200000
10001,jepson,1,15000,240000
10002,juhao,0,35000,50000

















 9370
9370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









