






资源:Tesla v100 32GBx8
测试原模型效果
python eval_llm.py --load_from ./MiniMind2
1. 预训练
预训练数据集
pretrain_hq.jsonl
{“text”: “<|im_start|>鉴别一组中文文章的风格和特点,例如官方、口语、文言等。需要提供样例文章才能准确鉴别不同的风格和特点。<|im_end|> <|im_start|>好的,现在帮我查一下今天的天气怎么样?今天的天气依据地区而异。请问你需要我帮你查询哪个地区的天气呢?<|im_end|> <|im_start|>打开闹钟功能,定一个明天早上七点的闹钟。好的,我已经帮您打开闹钟功能,闹钟将在明天早上七点准时响起。<|im_end|> <|im_start|>为以下场景写一句话描述:一个孤独的老人坐在公园长椅上看着远处。一位孤独的老人坐在公园长椅上凝视远方。<|im_end|> <|im_start|>非常感谢你的回答。请告诉我,这些数据是关于什么主题的?这些数据是关于不同年龄段的男女人口比例分布的。<|im_end|> <|im_start|>帮我想一个有趣的标题。这个挺有趣的:“如何成为一名成功的魔术师” 调皮的标题往往会吸引读者的注意力。<|im_end|> <|im_start|>回答一个问题,地球的半径是多少?地球的平均半径约为6371公里,这是地球自赤道到两极的距离的平均值。<|im_end|> <|im_start|>识别文本中的语气,并将其分类为喜悦、悲伤、惊异等。\n文本:“今天是我的生日!”这个文本的语气是喜悦。<|im_end|>”}
进行预训练
torchrun --nproc_per_node 8 train_pretrain.py
测试预训练的效果
python eval_llm.py --weight pretrain
2、SFT
SFT数据集
sft_mini_512.jsonl
{“conversations”: [{“role”: “user”, “content”: “请告诉我在中国古代的“四大发明”是什么?”}, {“role”: “assistant”, “content”: “中国古代的“四大发明”是指造纸术、印刷术、火药和指南针。这四项发明对世界文明的发展产生了深远的影响:\n\n1. 造纸术:据史书记载,东汉时期的蔡伦改进了造纸工艺,使得纸张的生产更加便捷、成本更低,质量也更加优良。这一发明极大地促进了文化的传播和保存。\n\n2. 印刷术:中国古代的印刷术最早可以追溯到唐代的雕版印刷,到了宋代发展出了活字印刷技术。印刷术的发明极大地促进了知识的传播,降低了书籍的成本,对教育和文化的发展起到了重要的推动作用。\n\n3. 火药:火药最初是在唐代被发现的,最初可能用于医疗或炼金术。到了宋代,人们开始将火药用于军事目的,发明了各种火器。火药的发明改变了战争的面貌,对世界军事技术的发展产生了重大影响。\n\n4. 指南针:指南针最初在中国被用于风水测量,后来逐渐发展成为航海导航的重要工具。这一发明极大地促进了海上航行技术的发展,对于新航路的开辟和世界地理大发现起到了关键作用。\n\n这四项发明不仅在中国历史上占有重要地位,而且对全世界的科技进步和文明发展都产生了深远的影响。”}]}
进行SFT
torchrun --nproc_per_node 8 train_full_sft.py

测试SFT 的效果
python eval_llm.py --weight full_sft
3、PPO
PPO数据集
rlaif-mini.jsonl
{“conversations”: [{“role”: “user”, “content”: “列出五个基本的人格理论,并分别以一句话概括。”}, {“role”: “assistant”, “content”: “空”}]}
进行PPO训练
torchrun --nproc_per_node 8 train_ppo.py --use_wandb
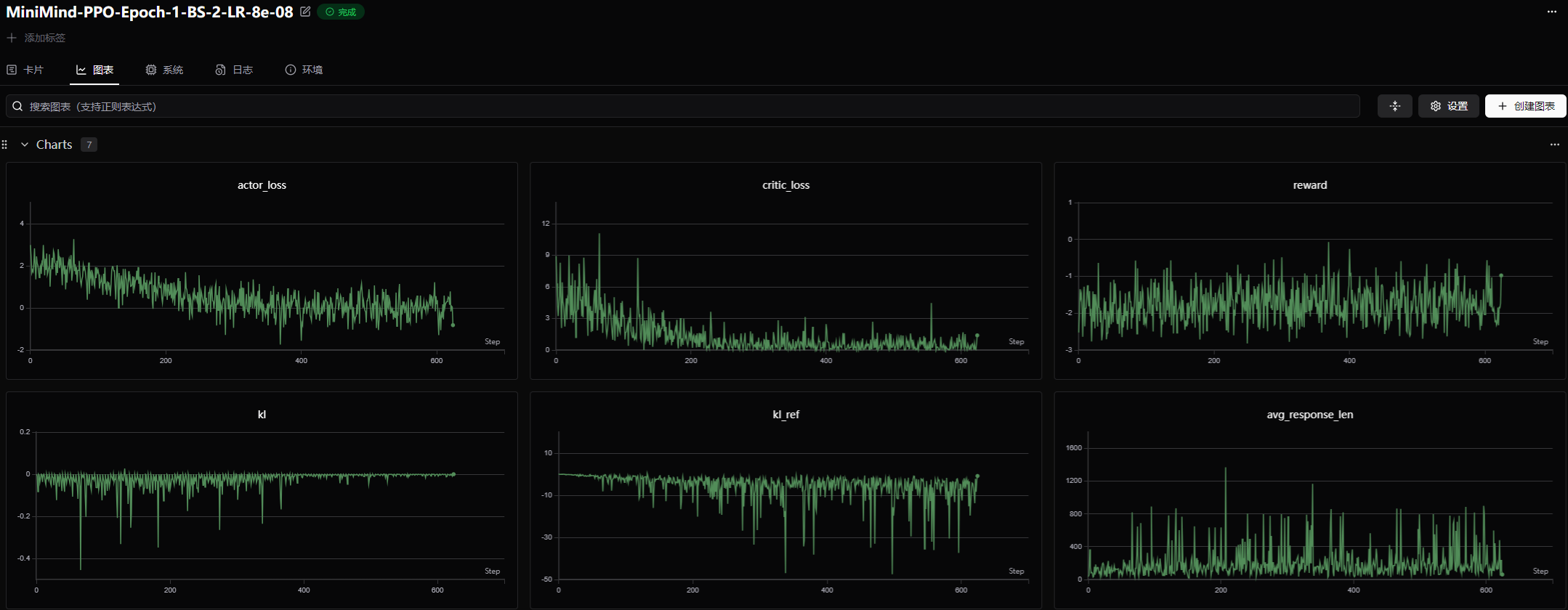
查看训练曲线
export SWANLAB_API_KEY=
swanlab: 🚀 View project at https://swanlab.cn/@lzh_xxx/MiniMind-PPO
swanlab: 🚀 View run at https://swanlab.cn/@lzh_xxx/MiniMind-PPO/runs/1tqoxu588uu1tgbfp8viq
测试PPO的效果
python eval_llm.py --weight ppo_actor

















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









