







有数据库相关的问题,我有一个表,里面有三列,customer简化之后表结构如下:
| id | name | source |
|---|---|---|
| 1 | 客户1 | a渠道 |
| 2 | 客户1 | b渠道 |
| 3 | 客户2 | a渠道 |
| 4 | 客户3 | a渠道 |
| 5 | 客户1 | c渠道 |
我现在的逻辑是根据传进来的id查找name,然后再根据name来查找id;例如:传进来id是1和3,根据这两个id查到name值为客户1和客户2,然后根据这两个name去查询id,可得到1,2,3,5,翻译成sql就是下面的。
select id,name from customer where name in(select name from customer where id in(1,3));
现在有十万客户,这里面大概有1200左右的重复客户,有没有什么比较好的办法优化?传进来的id特别多,大概四万个id,所以执行起来很慢。现在id和name已经做了索引。
此问题记录一下,我现在正在找好的解决方案,出现这个问题的原因是,多个系统迭代,对接,遗留的老问题。改动原始数据的话,影响颇大!
解决方法不限制,可以redis之类的外部缓存。
解决办法:
select id,name from customer c1 left join customer c2 on c1.name=c2.name where c1.id in(1,3);
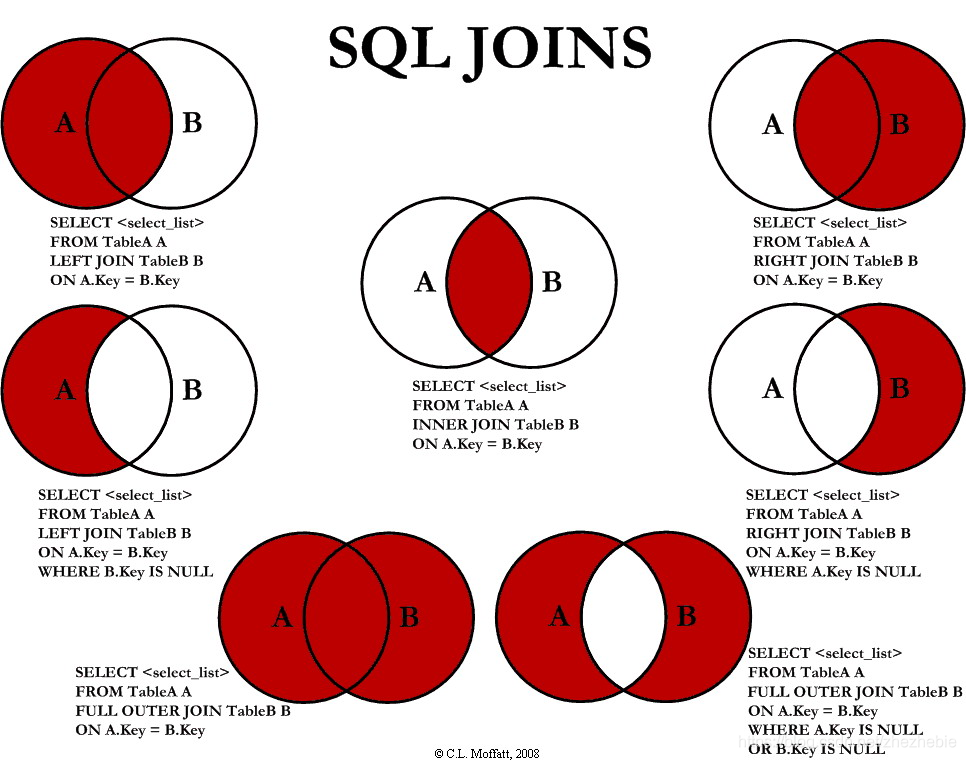
mysql各种join方法:
https://cloud.tencent.com/developer/article/1444315
https://mazhuang.org/2017/09/11/joins-in-sql/


















 2473
2473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











