




1. 如果你想按某个分割符号去把长长的一整列数据拆分成多列;
2. 如果你想导出拆分后数据,你希望勾选那一列就导出那一列数据,勾选多列就导出多列数据;
3. 如果你想让某列按日期范围导出数据,就能按某列的日期范围导出数据;
4. 如果你想按某列的数值大小范围导出数据,就能按某列的数值范围导出数据;
5. 如果你想按某列文本前缀包含什么内容,就能按设定的前缀条件导出数据;
6. 如果你想按某列文本后缀包含什么内容,就能按设定的后缀条件导出数据;
7. 如果你想按某列文本前缀包含什么内容,后缀同时必须包含什么内容 ,就能按设定的前缀和后缀条件导出数据;
8. 如果你想按某列文本前缀包含什么内容,中间偏后的部分包含什么内容 ,就能按设定的前缀和中间偏后的设定的条件导出数据;
9.如果你想按某列文本后缀包含什么内容,中间偏前的部分包含什么内容 ,就能按设定的后缀和中间偏前的设定的条件导出数据;
10. 如果你想按某列货币值的范围导出数据,就能按设定的货币范围导出数据;
11. 如果你想按某列等于或者不等于什么内容导出数据,就能按照你希望结果导出数据;
总结:我们可以每次导出一类数据,分多次导出,想想看,是不是就能实现从大数据里分类导出我想要的分类数据,
以上描述的功能这款 “大数据 - 文本文件数据提取工具” 都能帮你轻松完成!如果你想现在立刻就拥有它,赶快来联系我吧,
早一天拥有!你就早一天受益!请你先认真阅读一遍我的博客,看看是不是你一直在等待的大数据软件!
大数据 - 文本文件数据提取工具界面功能说明如下:
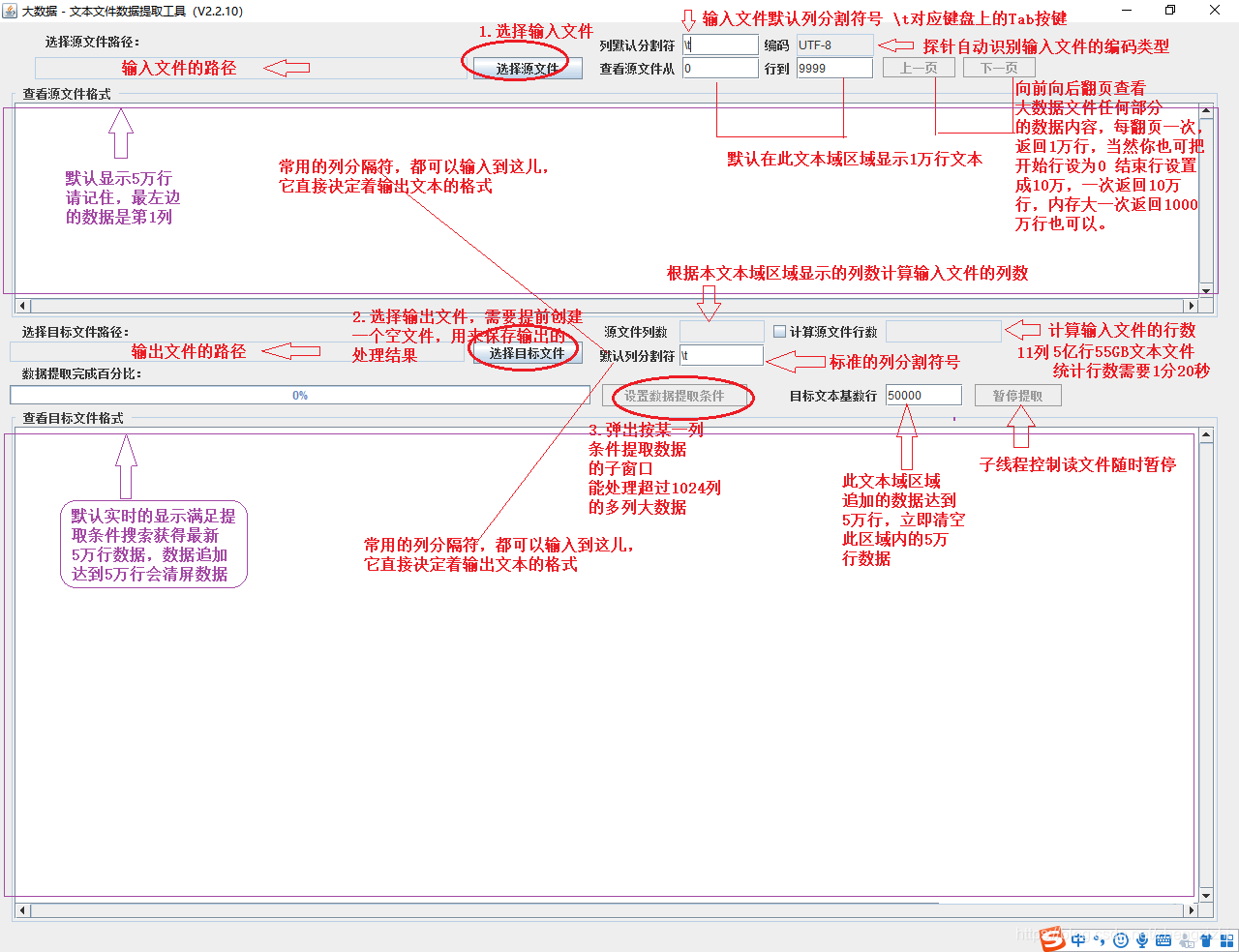
范例1:以下27个源文件都是由两列数据拼接而成,我们希望把一列数据
拆分成两列数据,然后导出我们勾选的那一列或者勾选的全部列数据。
为了简化博客的书写内容,你只能看视频了解 “大数据 - 文本文件数据提取工具”是如何使用的!
此软件可以处理超过1024列的超宽超大(1000GB以上的)文本提取导出数据,这个范例是最基础的,后面会举例
3列数据的范例还有11列数据的范例,再多列操作上跟范例一的处理步骤一样,请先下载视频教程
看看本软件是如何使用常见的分割符把一列数据拆分成多列数据的,
看看本软件是如何勾选任意一列或者多列导出数据的,操作非常简单。
范例1测试数据下载地址链接:https://pan.baidu.com/s/1OcZ7afyYvN9wiE1wGVAjQA
提取码:svsv
范例1视频教程下载地址链接:https://pan.baidu.com/s/1JyQeODbdAQCrdnXjsU0lxw
提取码:4260
Notepad++下载地址:(推荐使用这款工具查看500Mb以下的源文件和目标文件的内容及其格式)
链接:https://pan.baidu.com/s/1rt48H2yLTQKIOkuTH3cS8g
提取码:2lbk
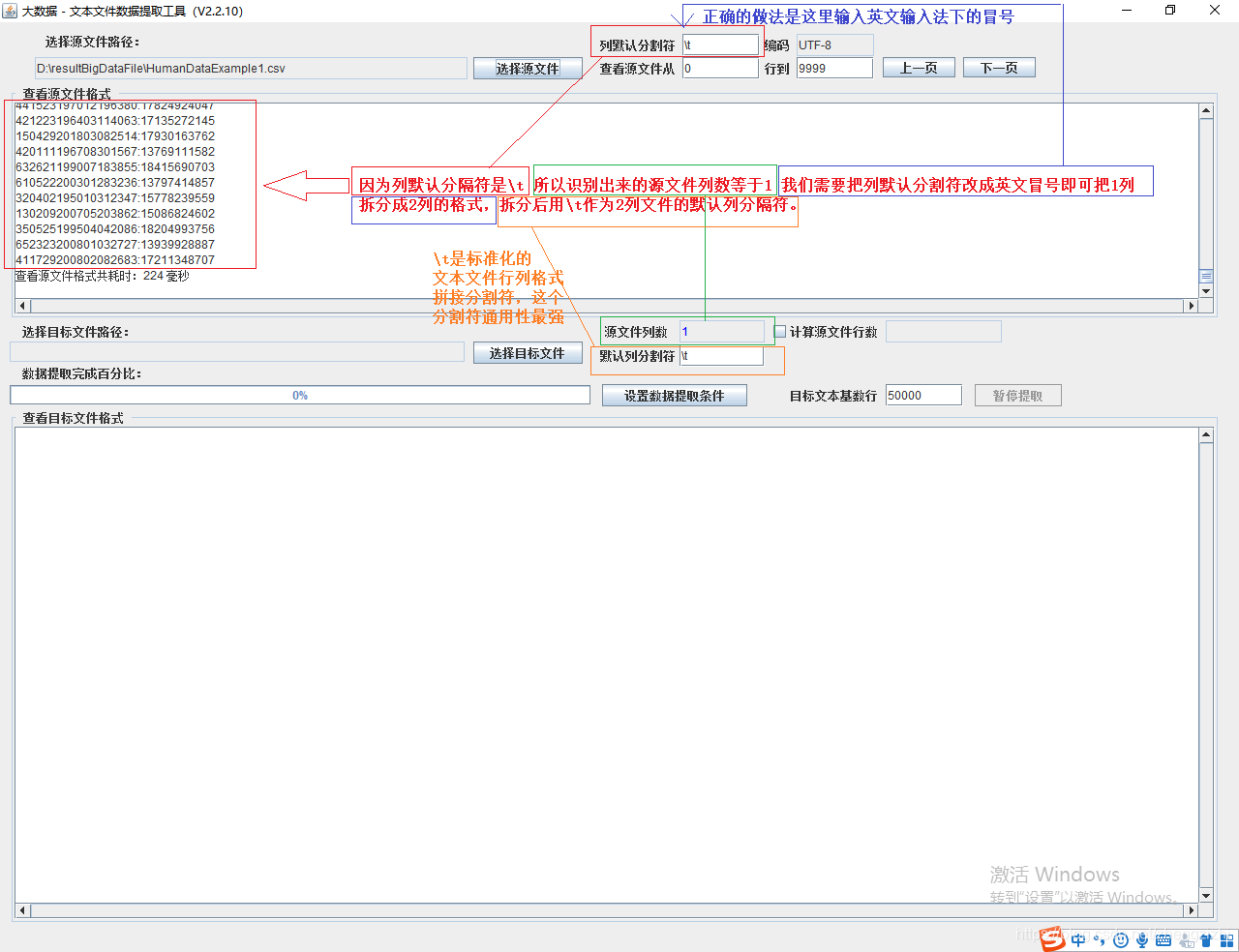
以下截图中出现的源文件里每行只有一长列数据,要么由1个连接分割符号把两列数据拼接
而成,要么有同样的两个分割符号把两列数据拼接而成,以下出现多种分割符号都是我们常
用的,但这些分割符号不是标准文本文件行列格式分割符,标准的列分割符号是 \t
就是你键盘上的Tab按键,以下27个范例中出现的列分割符号都不是标准的分割符号
标准化的文本行列格式文本文件,列与列之间是 \t 连接,行末尾是\n结束:
视频里你看到以下七行内容,我一同粘贴出来:
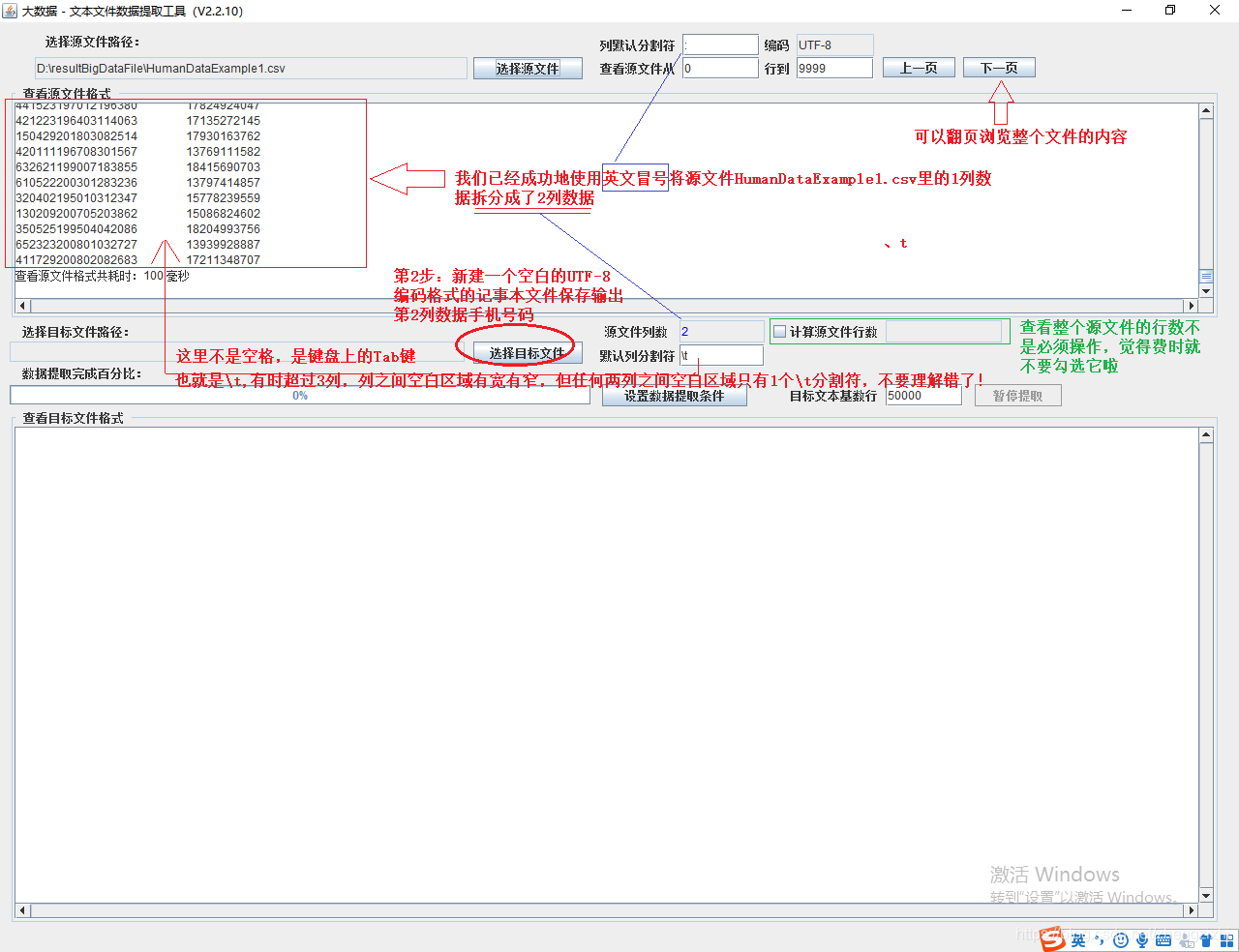
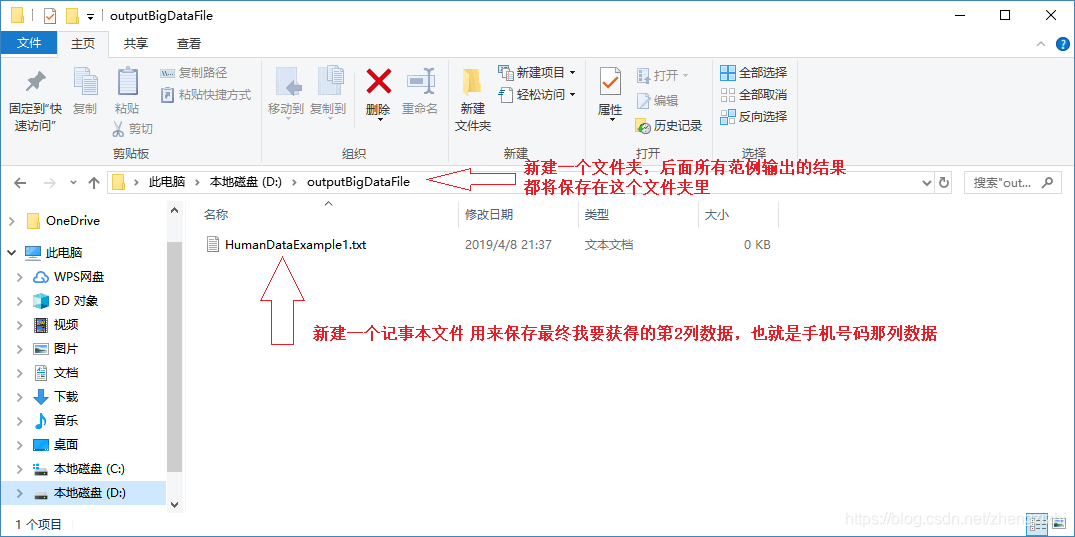
首先,我已经在D:\outputBigDataFile目录下建立了一个
空目标文件HumanDataExample1.txt用来保存输出结果
我们只需要输入与源文件一样的 ”列默认分割符“,才能正确的输出标准化的行列格式文件,
如果此步拆分列数不对,那么后面的一切操作就无法继续啦!
为了演示节省找文件的时间事先我已经记录了要使用的源文件和目标文件路径
D:\randomHunmanData\HumanDataExample1.csv // 源文件
D:\outputBigDataFile\HumanDataExample1.txt // 空目标文件
模仿范例1中的27个视频练习操作的时候,你会用到以下54个文件:
HumanDataExample1.csv HumanDataExample1.txt
HumanDataExample4.csv HumanDataExample4.txt
HumanDataExample7.csv HumanDataExample7.txt
HumanDataExample10.csv HumanDataExample10.txt
HumanDataExample13.csv HumanDataExample13.txt
HumanDataExample16.csv HumanDataExample16.txt
HumanDataExample19.csv HumanDataExample19.txt
HumanDataExample22.csv HumanDataExample22.txt
HumanDataExample25.csv HumanDataExample25.txt
HumanDataExample28.csv HumanDataExample28.txt
HumanDataExample31.csv HumanDataExample31.txt
HumanDataExample34.csv HumanDataExample34.txt
HumanDataExample37.csv HumanDataExample37.txt
HumanDataExample40.csv HumanDataExample40.txt
HumanDataExample43.csv HumanDataExample43.txt
HumanDataExample46.csv HumanDataExample46.txt
HumanDataExample49.csv HumanDataExample49.txt
HumanDataExample52.csv · HumanDataExample52.txt
HumanDataExample55.csv HumanDataExample55.txt
HumanDataExample58.csv HumanDataExample58.txt
HumanDataExample61.csv HumanDataExample61.txt
HumanDataExample64.csv HumanDataExample64.txt
HumanDataExample67.csv HumanDataExample67.txt
HumanDataExample70.csv HumanDataExample70.txt
HumanDataExample73.csv HumanDataExample73.txt
HumanDataExample76.csv HumanDataExample76.txt
HumanDataExample79.csv HumanDataExample79.txt
来看看下面我们随后会用到的27个测试数据源文件格式吧
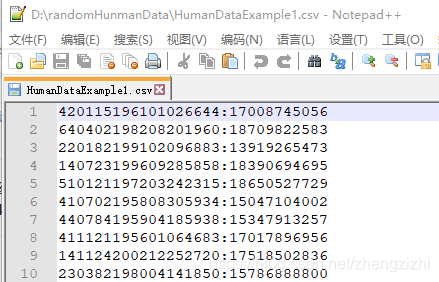
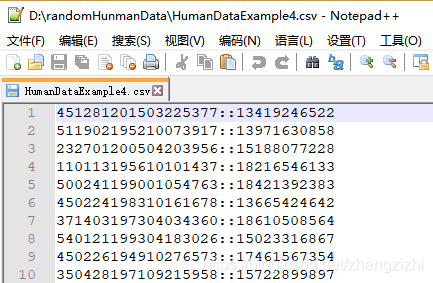
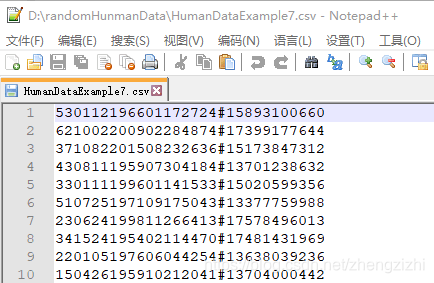
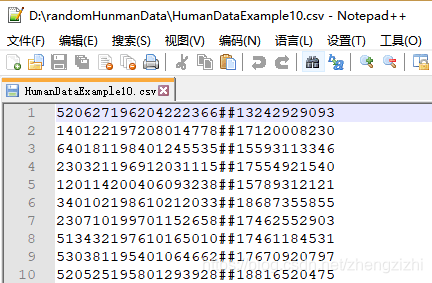
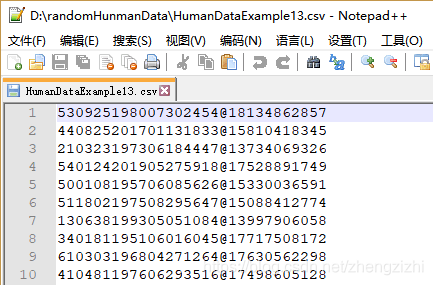
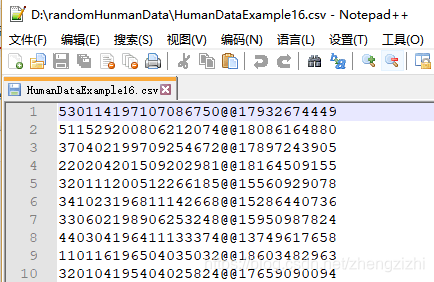
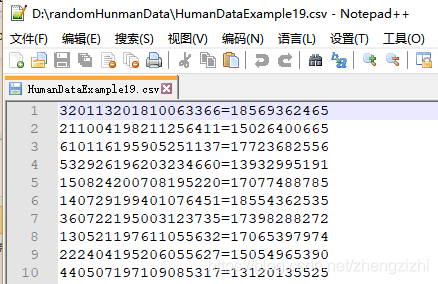
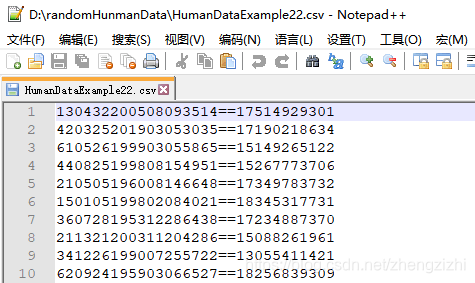
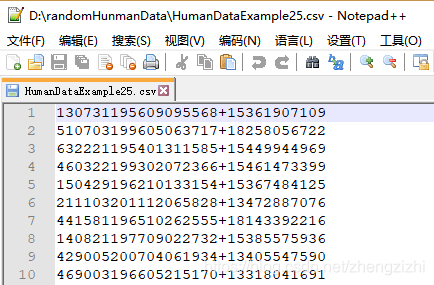
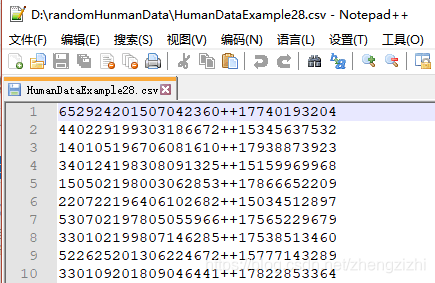
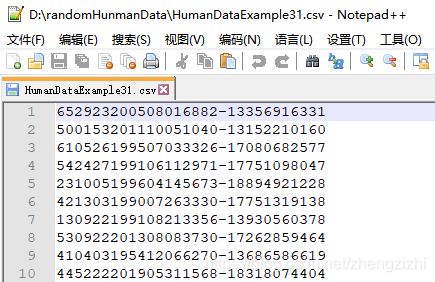
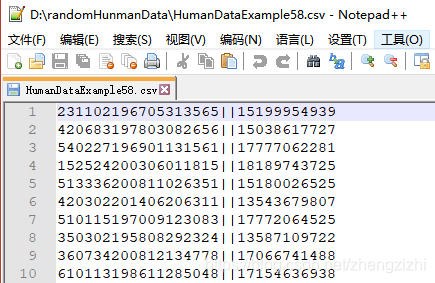
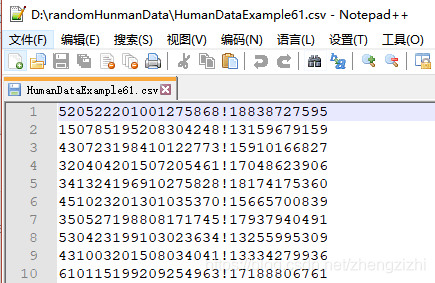
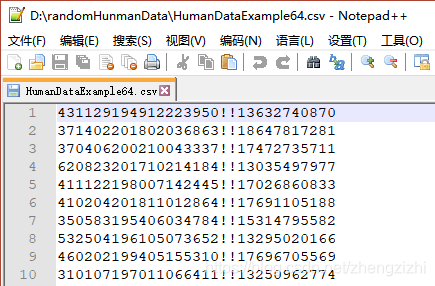
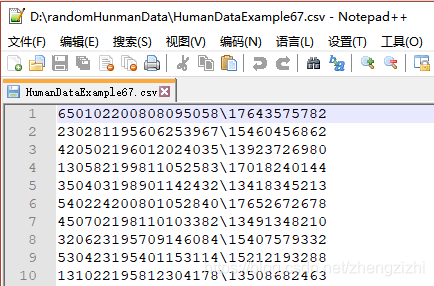
我们需要把1列数据用英文的冒号拆分成2列数据,然后提取一列数据,例如提取第2列数据,
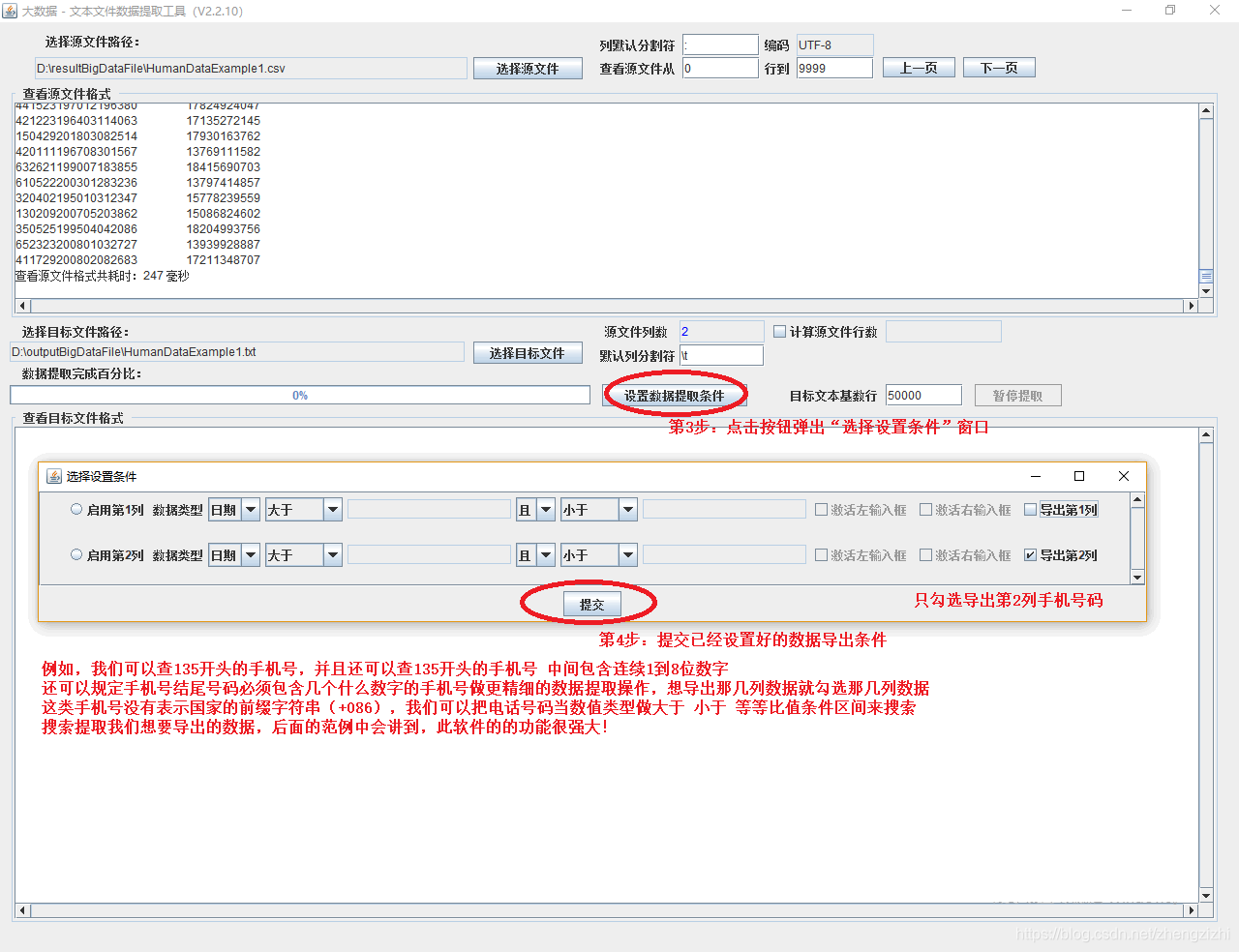
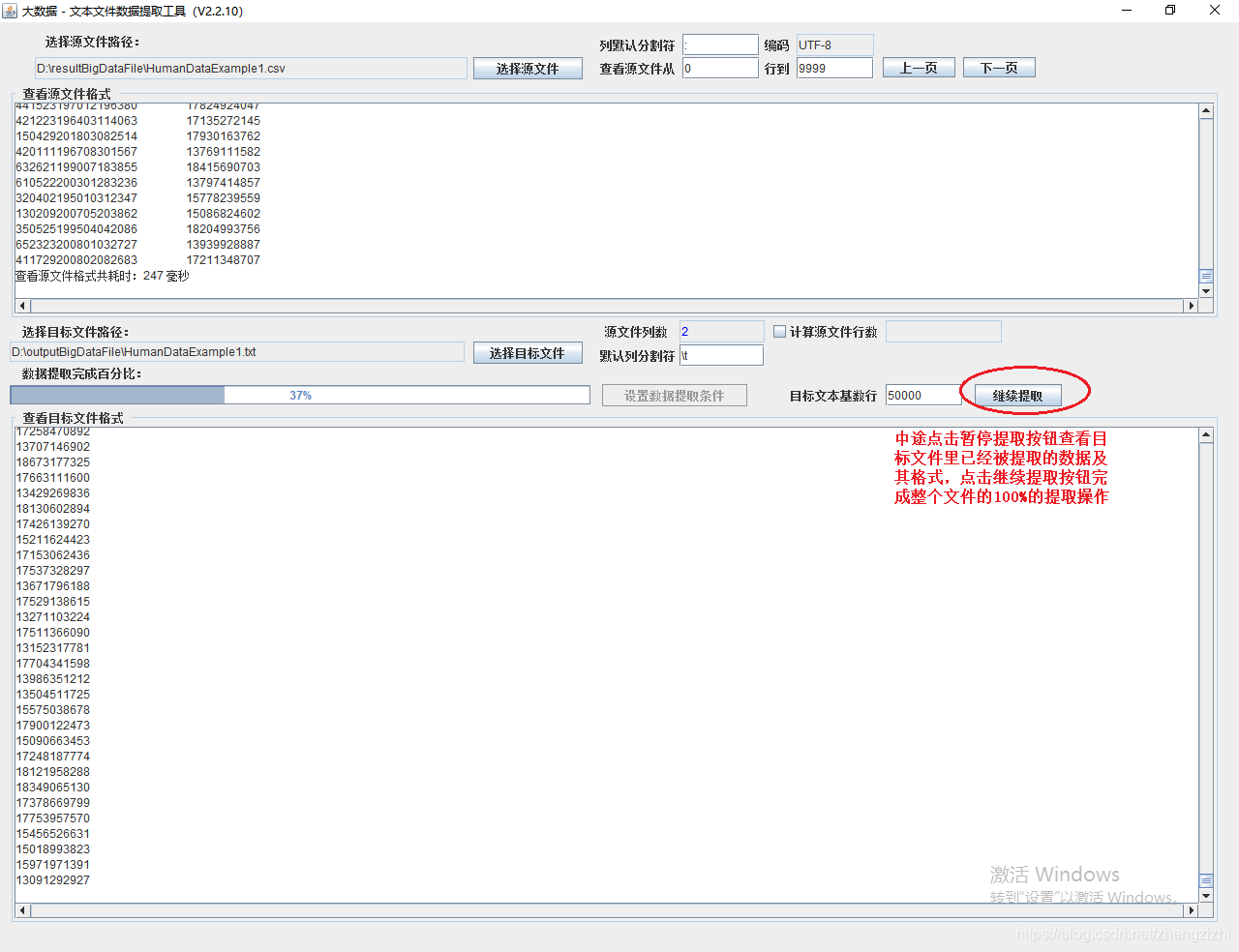
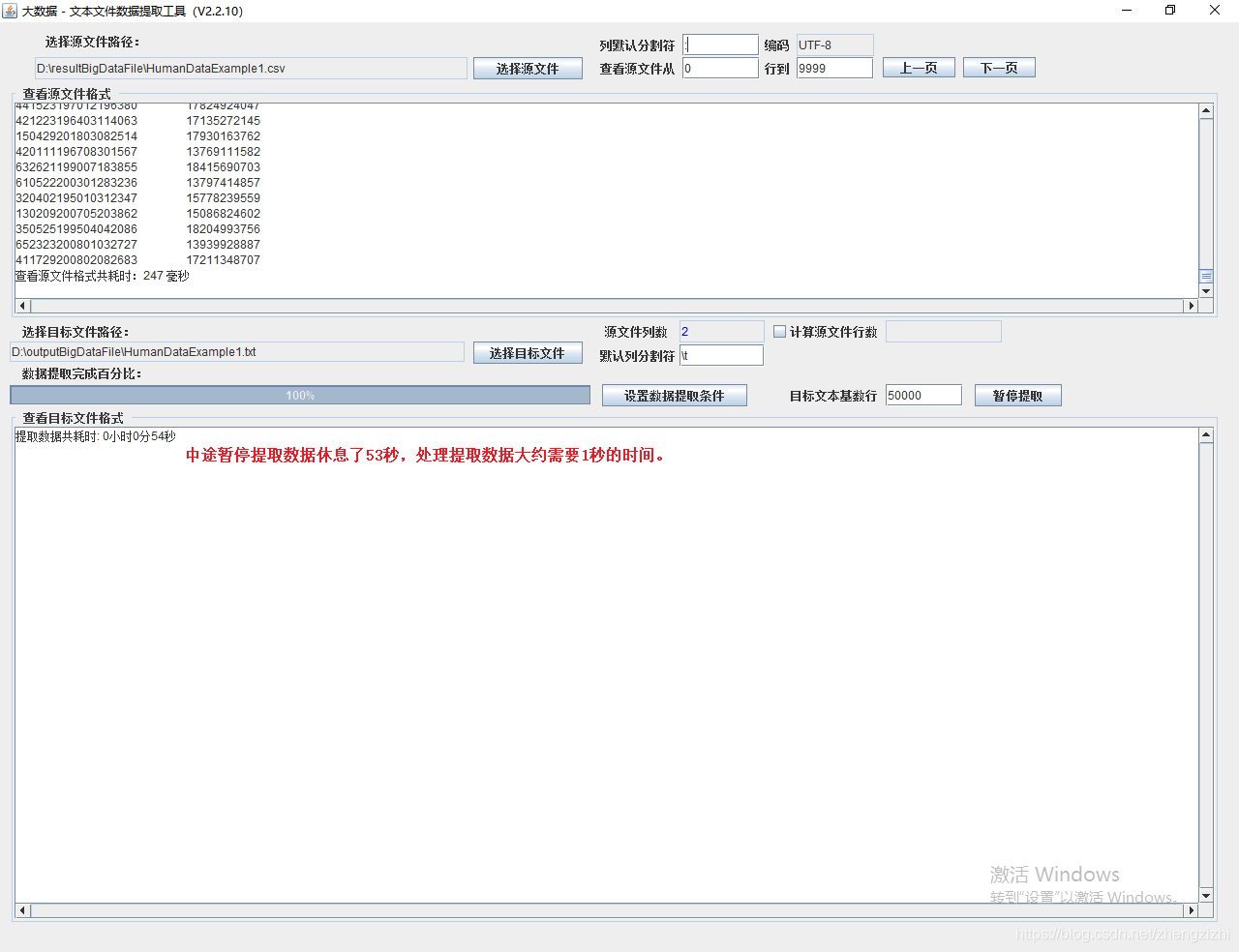
范例2:以下27个源文件都是由三列数据拼接而成,我们希望把一列数据
拆分成三列数据,然后导出我们勾选的那一列或者勾选的全部列数据。
为了简化博客的书写内容,你只能看视频了解 “大数据 - 文本文件数据提取工具”是如何使用的!
范例2视频教程下载地址链接:https://pan.baidu.com/s/1ARTwpuwB2t8eJ0i5XyQoJQ
提取码:pp99
视频里你看到以下七行内容,我一同粘贴出来:
首先,我已经在D:\outputBigDataFile目录下建立了一个
空目标文件HumanDataExample2.txt用来保存输出结果
我们只需要输入与源文件一样的 ”列默认分割符“,才能正确的输出标准化的行列格式文件,
如果此步拆分列数不对,那么后面的一切操作就无法继续啦!
为了演示节省找文件的时间事先我已经记录了要使用的源文件和目标文件路径
D:\randomHunmanData\HumanDataExample2.csv // 源文件
D:\outputBigDataFile\HumanDataExample2.txt // 空目标文件
模仿范例2中的27个视频练习操作的时候,你会用到以下54个文件:
HumanDataExample2.csv HumanDataExample2.txt
HumanDataExample5.csv HumanDataExample5.txt
HumanDataExample8.csv HumanDataExample8.txt
HumanDataExample11.csv HumanDataExample11.txt
HumanDataExample14.csv HumanDataExample14.txt
HumanDataExample17.csv HumanDataExample17.txt
HumanDataExample20.csv HumanDataExample20.txt
HumanDataExample23.csv HumanDataExample23.txt
HumanDataExample26.csv HumanDataExample26.txt
HumanDataExample29.csv HumanDataExample29.txt
HumanDataExample32.csv HumanDataExample32.txt
HumanDataExample35.csv HumanDataExample35.txt
HumanDataExample38.csv HumanDataExample38.txt
HumanDataExample41.csv HumanDataExample41.txt
HumanDataExample44.csv HumanDataExample44.txt
HumanDataExample47.csv HumanDataExample47.txt
HumanDataExample50.csv HumanDataExample50.txt
HumanDataExample53.csv · HumanDataExample53.txt
HumanDataExample56.csv HumanDataExample56.txt
HumanDataExample59.csv HumanDataExample59.txt
HumanDataExample62.csv HumanDataExample62.txt
HumanDataExample65.csv HumanDataExample65.txt
HumanDataExample68.csv HumanDataExample68.txt
HumanDataExample71.csv HumanDataExample71.txt
HumanDataExample74.csv HumanDataExample74.txt
HumanDataExample77.csv HumanDataExample77.txt
HumanDataExample80.csv HumanDataExample80.txt来看看下面我们随后会用到的27个测试数据源文件格式吧
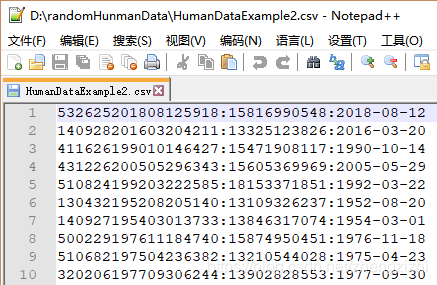
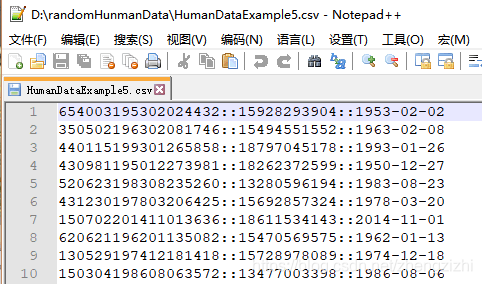
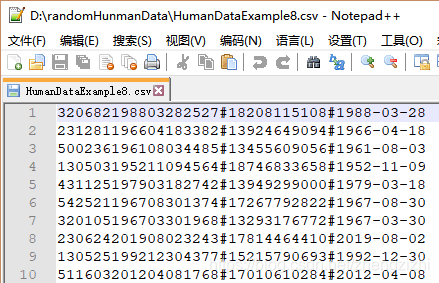
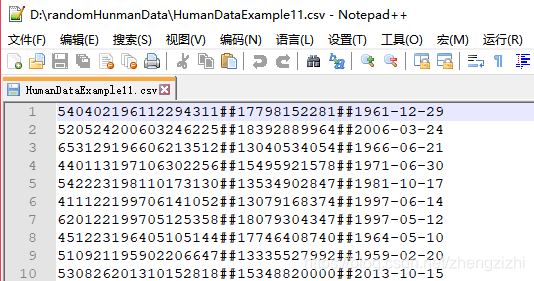
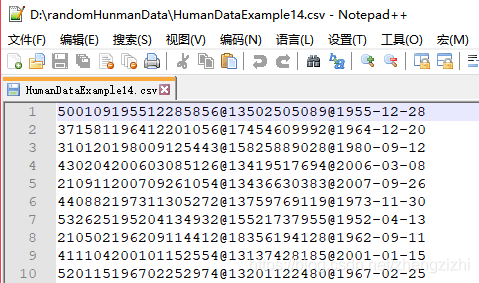
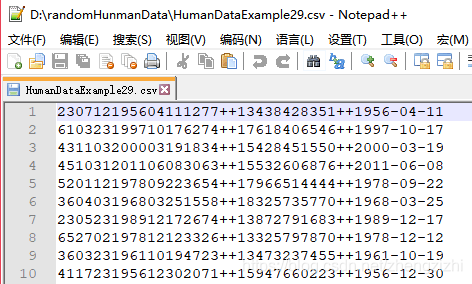
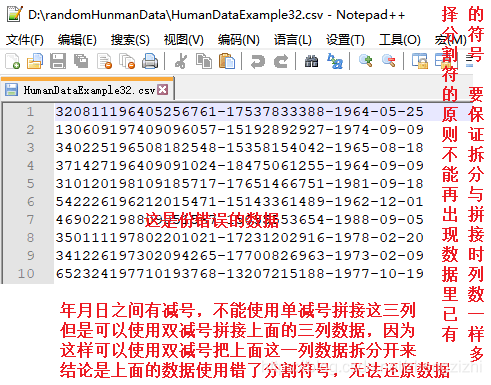
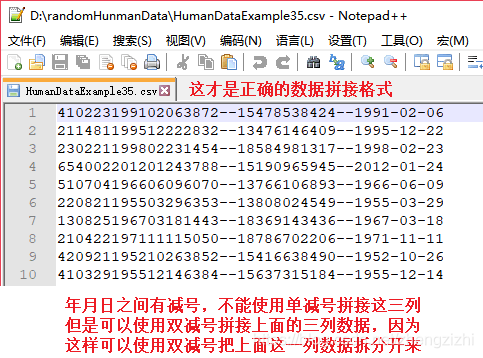
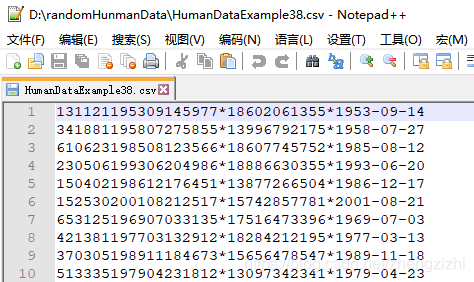
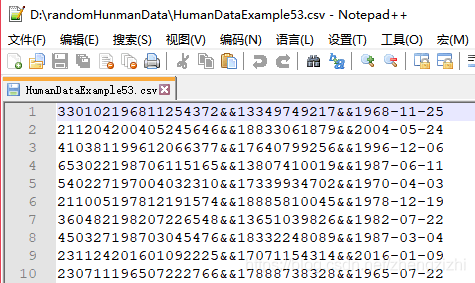
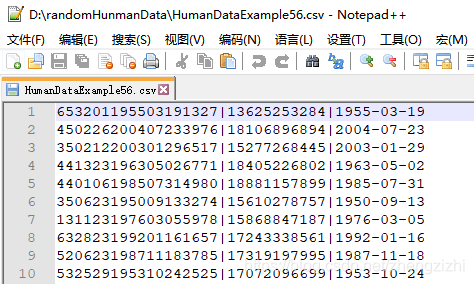
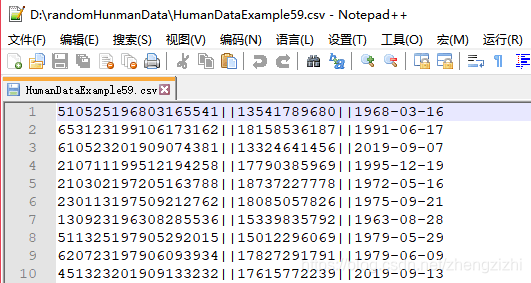
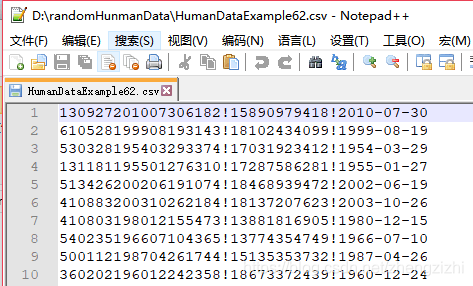
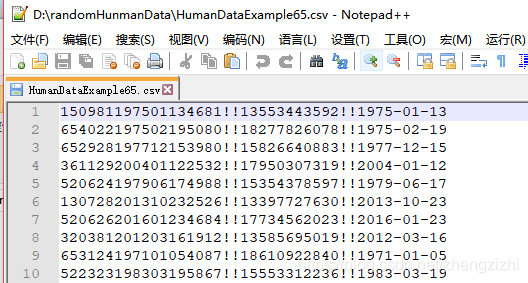
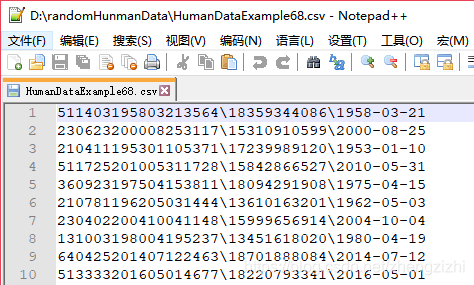
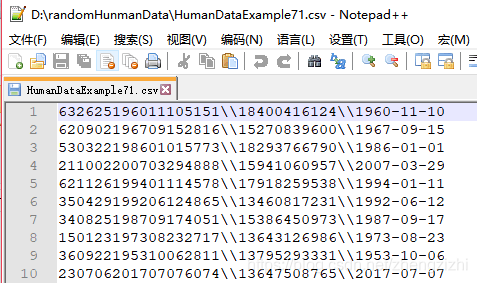
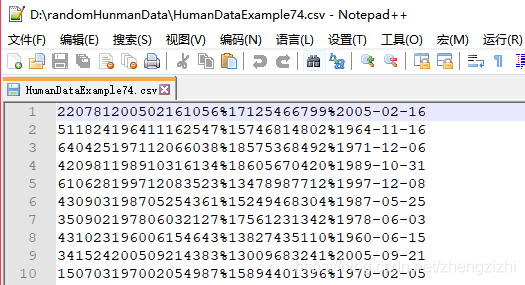
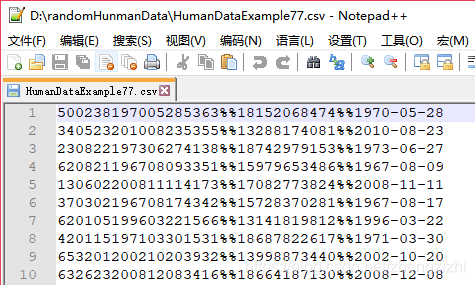
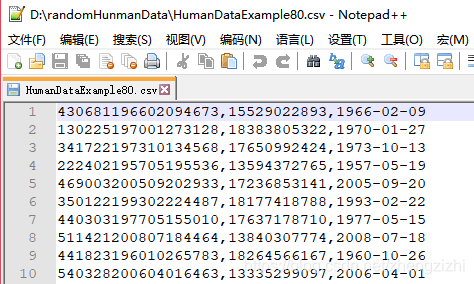
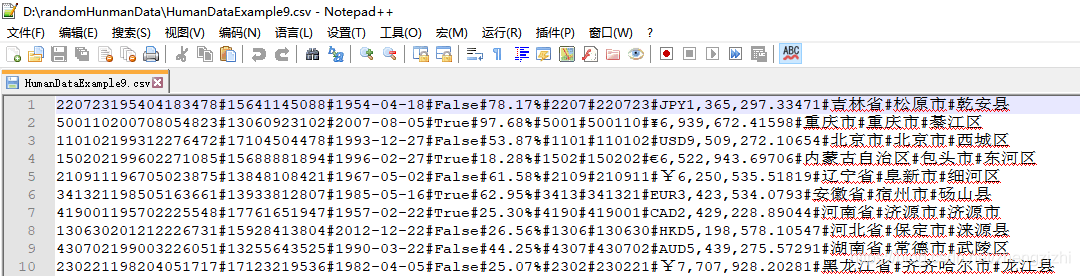
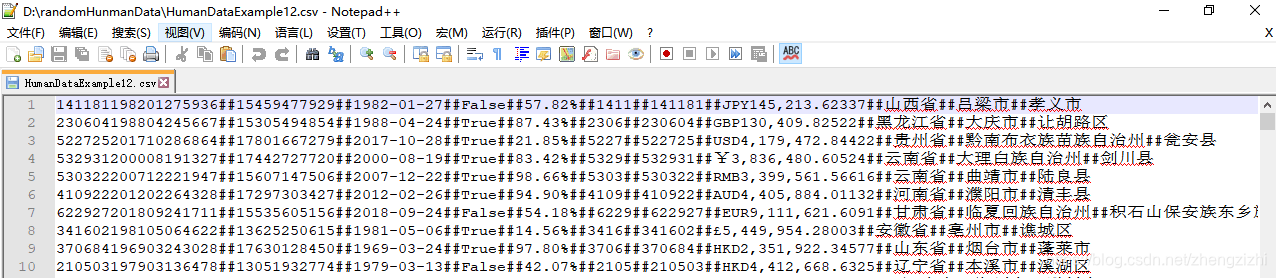
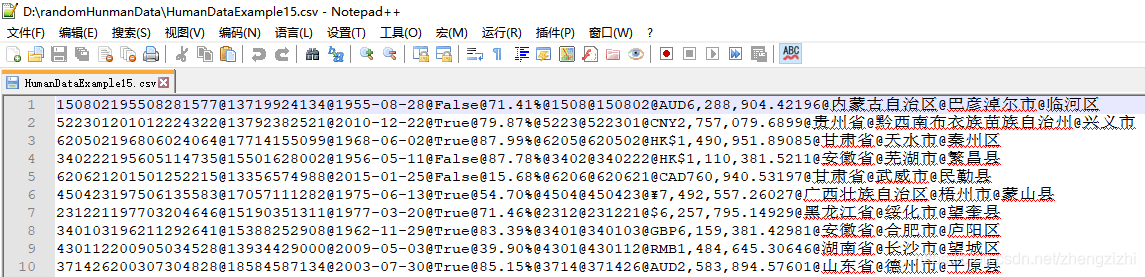
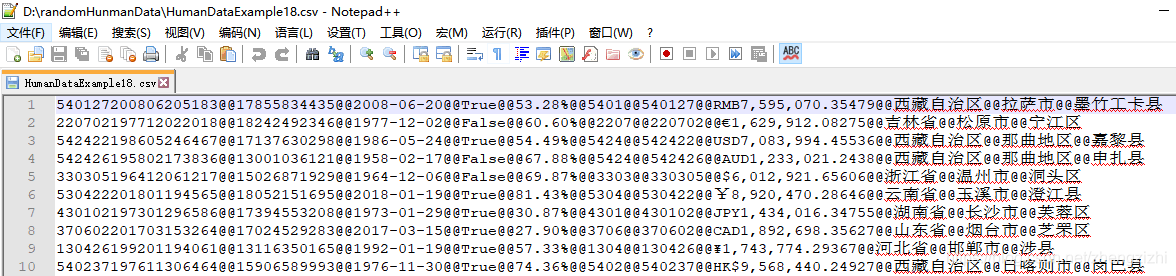
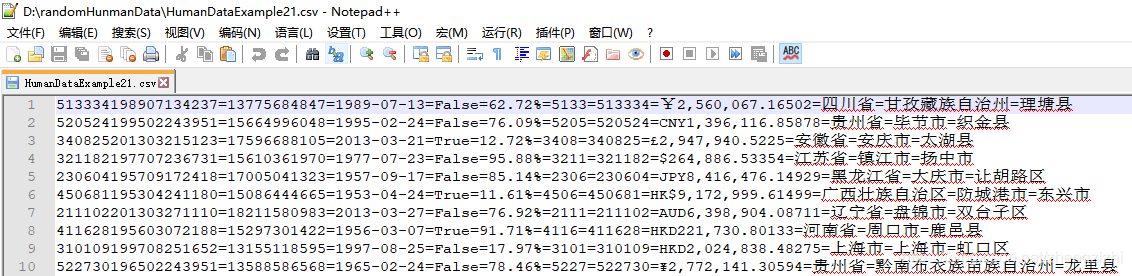
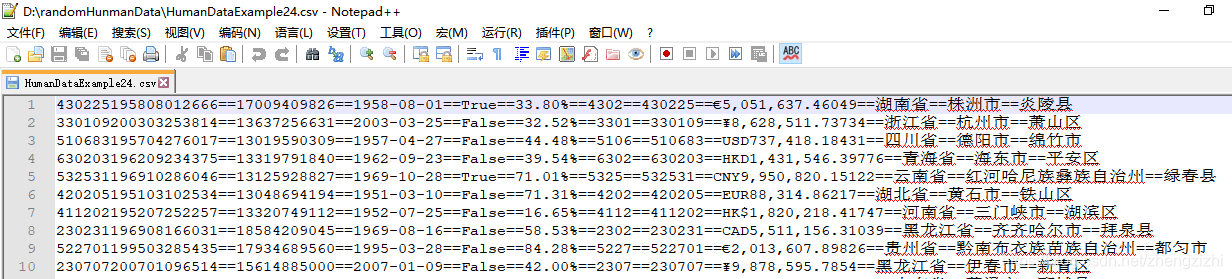
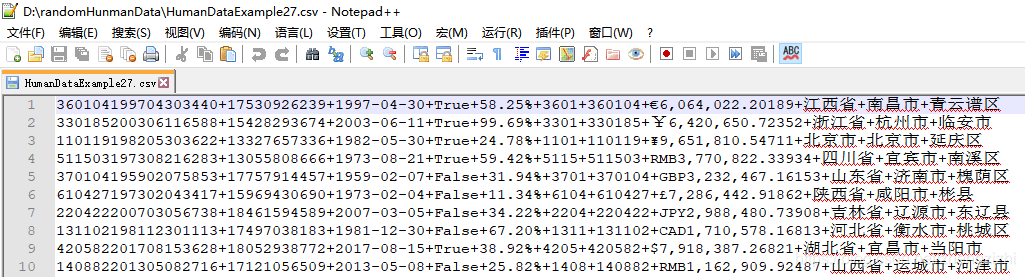
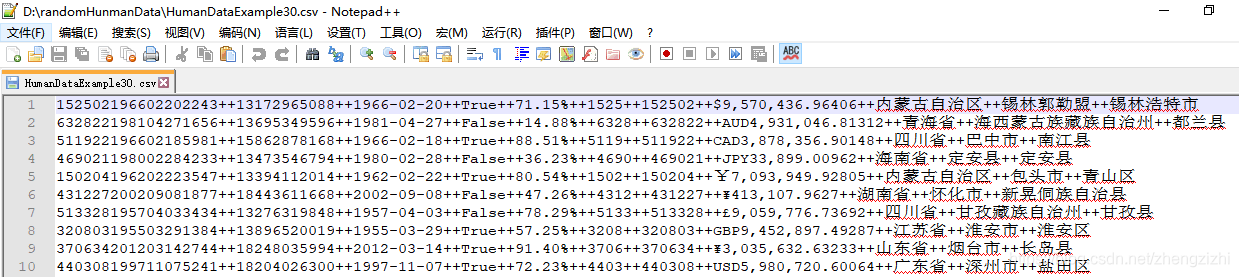
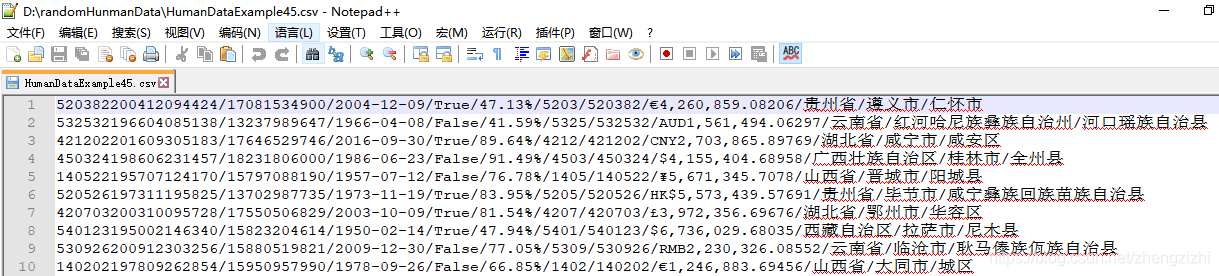
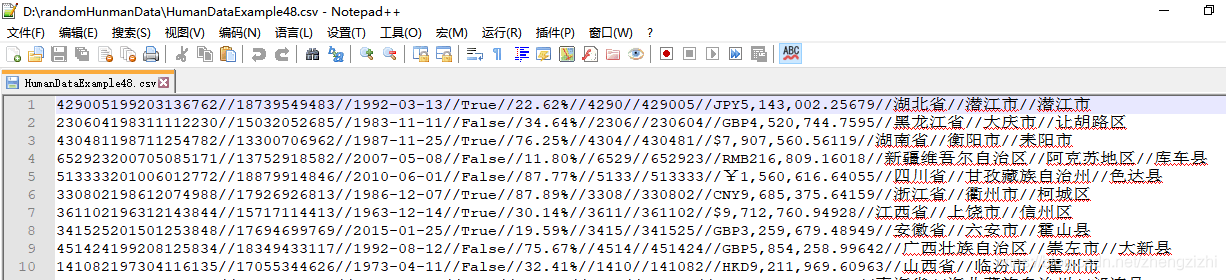
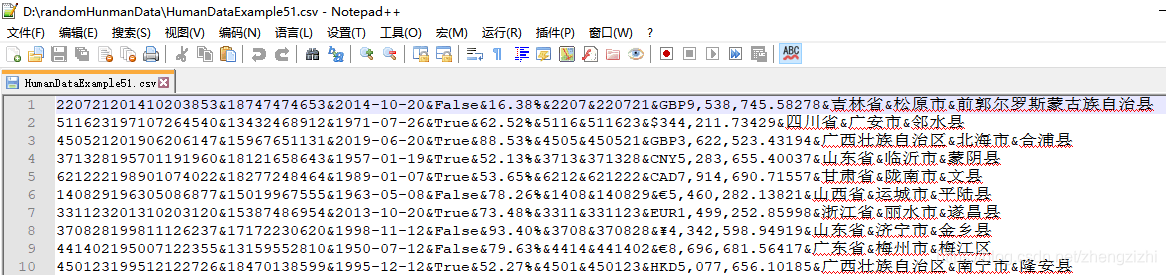
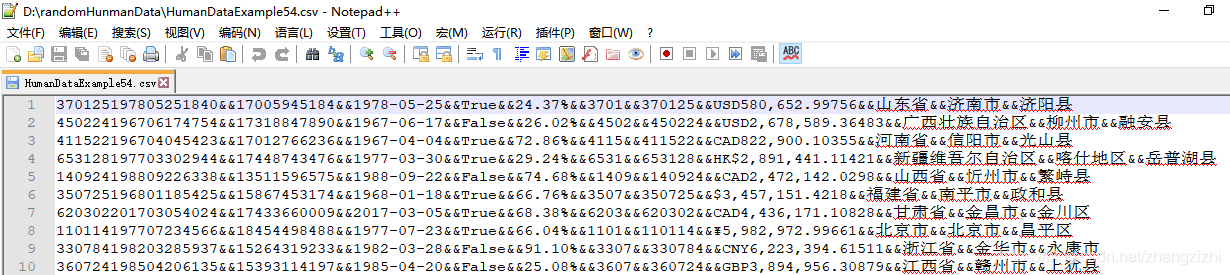
范例3:以下27个源文件都是由十一列数据拼接而成,我们希望把一列数
据拆分成十一列数据,然后导出我们勾选的那一列或者勾选的多列或者
勾选的全部列数据。
本软件能处理几千列或者数万列数据,这项功能超越了一切关系型数据库的处理能力
(因为所有的关系型数据库最多只能处理1024列数据)
为了简化博客的书写内容,你只能看视频了解 “大数据 - 文本文件数据提取工具”是如何使用的!
范例3视频教程下载地址链接:https://pan.baidu.com/s/1Np28dSTQSmqYb5LNzjFcDQ
提取码:0930
视频里你看到以下七行内容,我一同粘贴出来:
首先,我已经在D:\outputBigDataFile目录下建立了一个
空目标文件HumanDataExample3.txt用来保存输出结果
我们只需要输入与源文件一样的 ”列默认分割符“,才能正确的输出标准化的行列格式文件,
如果此步拆分列数不对,那么后面的一切操作就无法继续啦!
为了演示节省找文件的时间事先我已经记录了要使用的源文件和目标文件路径
D:\randomHunmanData\HumanDataExample3.csv // 源文件
D:\outputBigDataFile\HumanDataExample3.txt // 空目标文件
模仿范例3中的27个视频练习操作的时候,你会用到以下54个文件:
HumanDataExample3.csv HumanDataExample3.txt
HumanDataExample6.csv HumanDataExample6.txt
HumanDataExample9.csv HumanDataExample9.txt
HumanDataExample12.csv HumanDataExample12.txt
HumanDataExample15.csv HumanDataExample15.txt
HumanDataExample18.csv HumanDataExample18.txt
HumanDataExample21.csv HumanDataExample21.txt
HumanDataExample24.csv HumanDataExample24.txt
HumanDataExample27.csv HumanDataExample27.txt
HumanDataExample30.csv HumanDataExample30.txt
HumanDataExample33.csv HumanDataExample33.txt
HumanDataExample36.csv HumanDataExample36.txt
HumanDataExample39.csv HumanDataExample39.txt
HumanDataExample42.csv HumanDataExample42.txt
HumanDataExample45.csv HumanDataExample45.txt
HumanDataExample48.csv HumanDataExample48.txt
HumanDataExample51.csv HumanDataExample51.txt
HumanDataExample54.csv · HumanDataExample54.txt
HumanDataExample57.csv HumanDataExample57.txt
HumanDataExample60.csv HumanDataExample60.txt
HumanDataExample63.csv HumanDataExample63.txt
HumanDataExample66.csv HumanDataExample66.txt
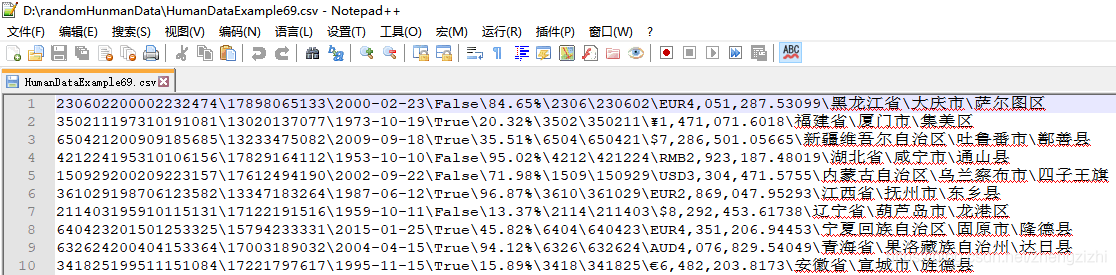
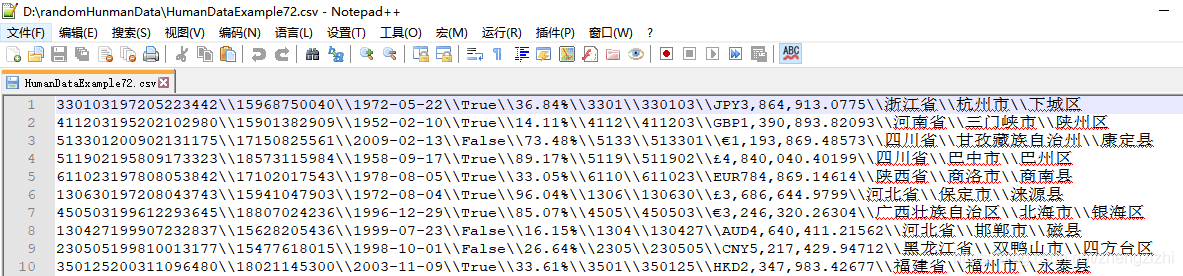
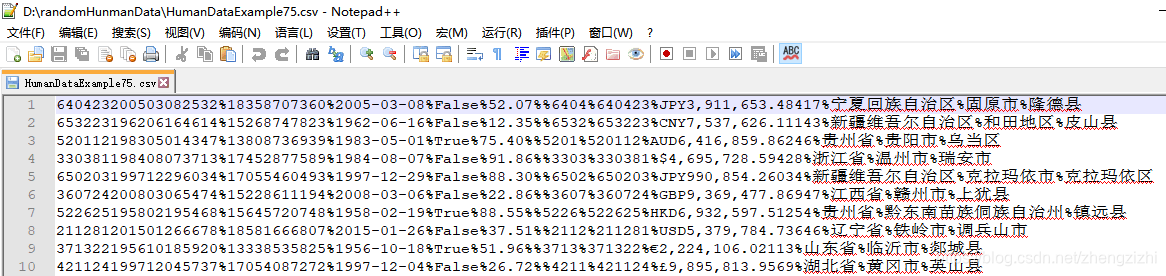
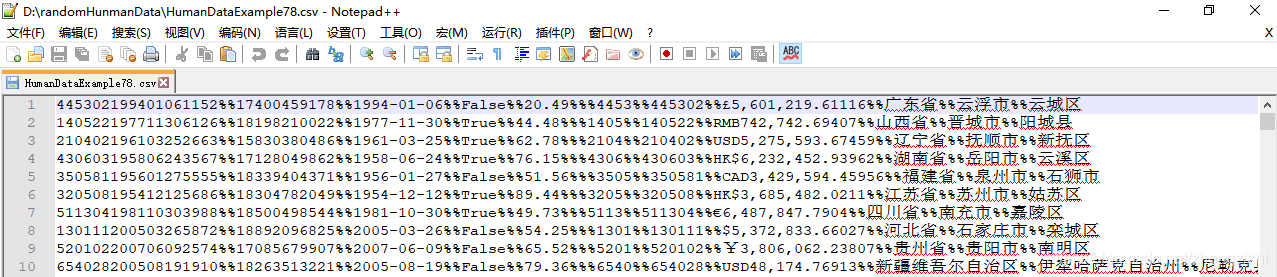
HumanDataExample69.csv HumanDataExample69.txt
HumanDataExample72.csv HumanDataExample72.txt
HumanDataExample75.csv HumanDataExample75.txt
HumanDataExample78.csv HumanDataExample78.txt
HumanDataExample81.csv HumanDataExample81.txt来看看下面我们随后会用到的27个测试数据源文件格式吧
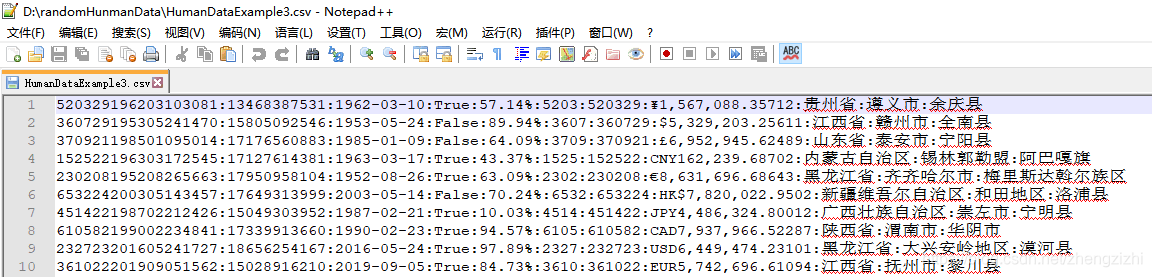
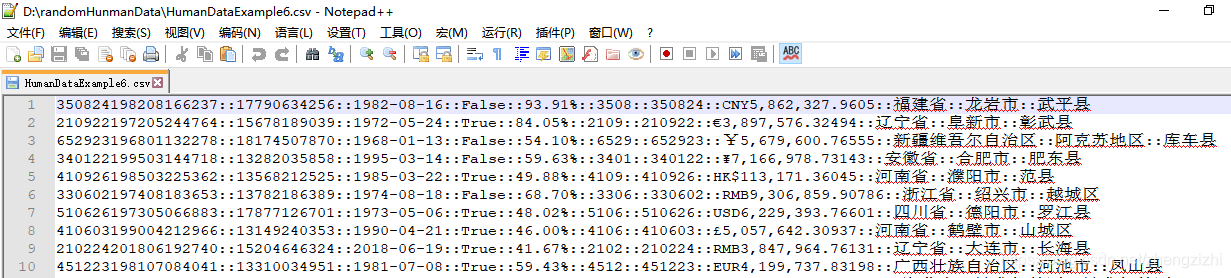

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









