







 本文详细介绍了Spark的主要特点,如内存计算引擎、通用DAG计算和Hadoop集成。Spark程序由Driver和Executor构成,运行模式包括local、standalone(client/cluster)和YARN(client/cluster)。在standalone模式中,Driver可以在client或cluster模式下运行。在YARN模式下,Driver可以选择由YARN管理。Spark应用程序由Job、Stage和Task组成,每个阶段的任务可并行执行。
本文详细介绍了Spark的主要特点,如内存计算引擎、通用DAG计算和Hadoop集成。Spark程序由Driver和Executor构成,运行模式包括local、standalone(client/cluster)和YARN(client/cluster)。在standalone模式中,Driver可以在client或cluster模式下运行。在YARN模式下,Driver可以选择由YARN管理。Spark应用程序由Job、Stage和Task组成,每个阶段的任务可并行执行。
计算引擎Spark基本原理
一、Spark主要特点
1.性能高效
- 内存计算引擎:Spark允许用户将数据放到内存中以加快数据读取,进而提高数据处理性能。
- 通用DAG计算引擎:Spark可以使得数据通过本地磁盘或内存流向不同计算单元而不是像MapReduce那样借助低效的HDFS。
- 性能高效:Spark是在MapReduce基础上产生的,在相同资源消耗的情况下,Spark比MapReduce快几倍到几十倍。
2.简单易用
Spark提供了丰富的高层次的API,包括sortByKey、groupByKey等。实现相同功能模块,Spark比MapReduce少2~5倍。
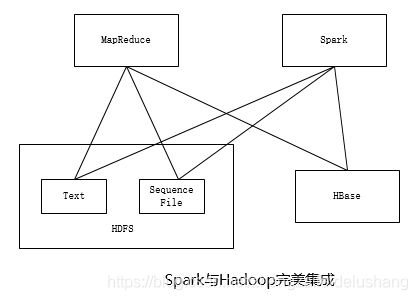
3.与Hadoop完好集成
Hadoop以及成为大数据标准解决方案,设计数据收集、数据存储、资源管理以及分布式计算等一系列系统。Spark作为新型计算框架,定位为除MapReduce等引擎之外的另一种可选的数据分析引擎,可以与Hadoop进行完好集成,可以与MapReduce等类型的应用一起运行在YARN集群,读取存储在HDFS/HBase中的数据,并写入各种存储系统中。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











