






 本文详细介绍了一种OCR图文识别软件的安装与配置过程,包括下载安装包、设置环境变量、安装语言包以及如何通过命令行进行图文识别,对处理大量图文数据提供了有效帮助。
本文详细介绍了一种OCR图文识别软件的安装与配置过程,包括下载安装包、设置环境变量、安装语言包以及如何通过命令行进行图文识别,对处理大量图文数据提供了有效帮助。
两个软件在附件
第一步,下载安装包。百度直达
第二步,把软件安装位置放在path变量中去D:\program files (x86)\Tesseract-OCR这时可以通过tesseract -v验证安装是否成功
第三步,安装语言包也就是把下载的文件放在下面的文件夹 ,下面的chi_sim.traineddata就是中文语言包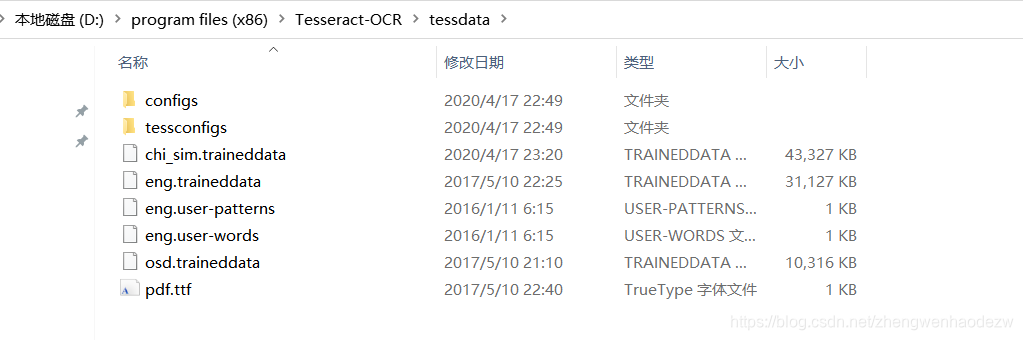
第三步.新增一个系统变量

第四步进行识别
tesseract im.jpg result -l chi_sim 命令
注意: im.jpg 是当前命令目录下的文件, result 是将会生成的txt名称, 后-l chi_sim是掉用中午语言包,如果不写,默认是采用英文语言包


生成的文件如下,可以看此识别出了图片中大部分的汉字,对我们处理数据还是相当有用的。

















01-02
 1万+
1万+
1万+
06-14
2572
2572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









