







我记录了自己在学习强化学习的过程中的学习进展、相关知识点的笔记以及个人的理解。这些内容可能不完全是专业的解释,但我相信它们对大家掌握深度强化学习会有所帮助。另外,我手写了一些证明过程,虽然字迹不太美观,还请大家多多包涵。
学习视频详情见王树森老师:wangshusen/DRL: Deep Reinforcement Learning (github.com)![]() https://github.com/wangshusen/DRL?tab=readme-ov-file
https://github.com/wangshusen/DRL?tab=readme-ov-file
也可参照赵世钰老师:【一张图讲完强化学习原理】 30分钟了解强化学习名词脉络 (youtube.com)![]() https://www.youtube.com/watch?v=TGIBuBd-V6I&list=PLEhdbSEZZbDYwsXT1NeBZbmPCbIIqlgLS这两位老师的讲解都非常出色。
https://www.youtube.com/watch?v=TGIBuBd-V6I&list=PLEhdbSEZZbDYwsXT1NeBZbmPCbIIqlgLS这两位老师的讲解都非常出色。
记得使用目录来查阅内容。这些资料非常详细、全面,不仅适合预习,还可以作为今后的参考。
目录
更加有效的方法 data efficient method:
stochastic gradient descentSGD随机梯度下降算法
TD算法:temporal difference learning
Deep Q-learning/Deep Q-network DQN
State-Action-Reward-State-Action (SARSA) 算法
Experience Replay (经验回放) 和 Prioritized Experience Replay (优先经验回放)
reinforce/Monte Carlo policy gradient
deterministic actor-critic的DPG方法(看个式子)
置信域策略优化 (Trust Region Policy Optimization, TRPO)
centralized training with decentralized execution
Inverse Reinforcement Learning逆向强化学习
Generative Adversarial Imitation Learning (GAIL)生成对抗性模仿学习 (GAIL)
强化学习概念
强化学习概念较多,本章节介绍一些基础概念以及将来用到的基础数学证明。
Agent (智能体):与环境交互的主体,动作的执行者,通过与环境的交互获取奖励,并根据奖励的累计和(回报)来调整其行为策略,以最大化回报
Environment (环境):与智能体交互的空间,包括所有可能影响 Agent 的状态和奖励的外部因素
State (状态):环境在某一时刻的具体情况或描述
state space(状态空间):所有状态的集合
goal space(目标空间):可以是状态空间的任意函数
Action (动作):Agent 在给定状态下可以采取的行为或决策
action space(状态空间):所有动作的集合
State Transition (状态转移):在状态s下采取动作a,最终转移到状态s‘的概率
例如状态s1执行动作a1到状态s2,

Reward (奖励):某一状态下对 Agent 所采取的动作的反馈。奖励用来衡量agent采取动作的好坏。强化学习希望得到的奖励尽可能的高。reward自己设置。强化学习与奖励的绝对数值无关,与相对的数值大小有关。
Return (回报),也叫cumulative future reward,从t时刻开始的所有奖励和,通常在奖励前面乘以折扣率
discounted return(折扣回报):discount rate折扣率(从0到1)(对未来较远回报的折扣系数)(一个微调的超参数),越小的
越短视,越大的
越长远
注意:奖励和折扣率都在调整策略
无意义的过程给定一个负数表示行动的花费看起来是符合事实的,比如设置中间r=-1,但是实际情况下发现并没有任何作用,因为也在限制减少无意义的行为,步数越长,有正值回报的折扣率越大,造成回报减小。
Policy (策略):,根据当前状态做出决策,做出什么动作
例如在状态有三种动作,
,
状态边缘分布ρ
-
符号表示:在这句话中,ρπ(st)\rho_\pi(s_t)ρπ(st) 表示由策略 π(at∣st)\pi(a_t | s_t)π(at∣st) 诱导的状态边缘分布。这意味着在特定策略 π\piπ 下,智能体在时间步 ttt 处于状态 sts_tst 的概率分布。
-
状态分布:在强化学习中,智能体根据策略 π(at∣st)\pi(a_t | s_t)π(at∣st) 从状态 sts_tst 出发选择动作 ata_tat,并通过环境的转移动态 p(st+1∣st,at)p(s_{t+1} | s_t, a_t)p(st+1∣st,at) 转移到下一个状态 st+1s_{t+1}st+1。经过多次这样的转移,系统会逐渐稳定在某种状态分布上,这就是状态边缘分布。
模型:根据环境定义的,不可以更改的
状态s和动作a情况下得到不同回报的概率
和状态s和动作a情况下状态转移到s’的概率
都是模型
model-based就是需要知道这个概率
Value Functions (价值函数):包括动作价值函数和状态价值函数
action value function(动作价值函数):
对状态采取动作
计算回报的期望作为(s,a)下的分数
最优动作价值函数
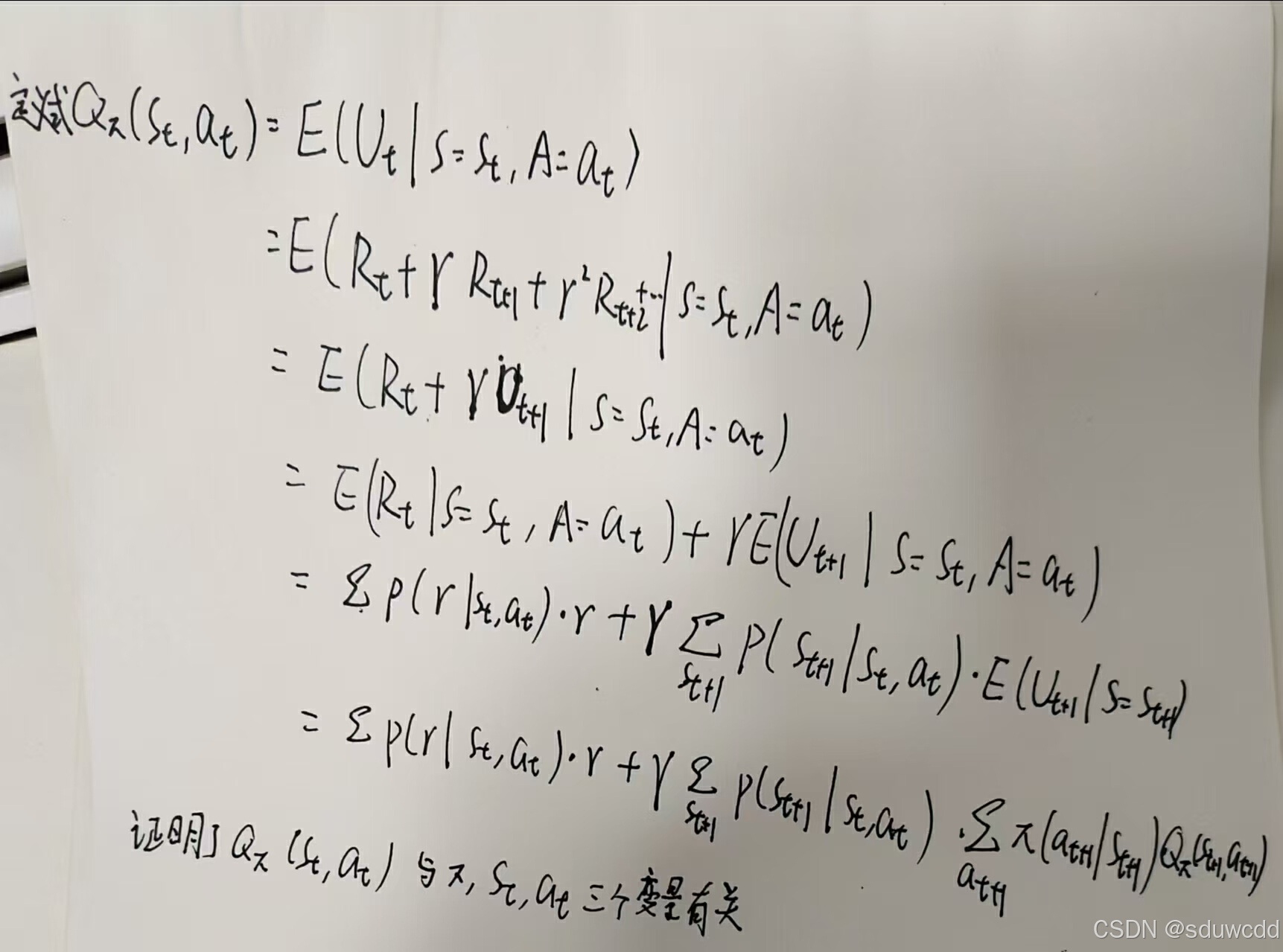
由以上证明可以看出,与策略有关,在不同的策略中,至少存在一个最佳策略使得动作回报最大
根据定义和联系有两种可行的计算公式

state value function(状态价值函数):衡量当前状态的好坏
最优状态价值函数:在不同策略下,挑选一个最佳策略使得
达到最大值,
和
存在联系,定义一个这样的价值函数并没有实际意义
trajectory(轨迹):一次试验的状态动作序列
episode:从开始到目标态的有限试验轨迹
experience(经验):多个已有的四元组集合
policy evaluation策略评价:在给定策略下,求一个状态的状态价值函数或者求一个(s,a)的动作价值函数
visit(访问):每一次尝试中出现一个 状态动作对 就认为是对 状态动作对 的一次访问
数据的使用
initial-visit method:对于每一个episode只对从头开始的状态价值对计算一次
更加有效的方法 data efficient method:
first visit method:对于一串episode,只使用第一次出现的 状态价值对 更新,以后次数出现的不进行更新
every visit method:对所有的episode,每个出现的状态价值对都更新一次
generalized policy iteraton GPI :是一种框架 表示在policy evaluation和policy improvement之间来回切换的过程
with probability 1(w.p.1):就是
依据概率采样得到,不是随意取的数
behavior policy(行为策略):用于生成经验采样
target policy(目标策略):优化该策略直到为最优策略
on-policy(基于策略的):behavior policy和target policy相同
off-policy(不基于策略的):behavior policy和target policy不同
exploitation充分利用: 选择当前最优的选择更高
exploration探索 : 在没有走过的路径进行探索
强化学习交互过程:

强化学习的随机性:
1.根据当前状态做出动作,如果输出动作不唯一,这样的策略具有随机性
2.根据当前状态和策略得到实际的新状态,模型具有随机性
强化学习学习的内容:
1.policy策略函数的概率值
2.最大动作价值函数
对应两大类学习:策略学习和价值学习
MDP马尔可夫决策过程:
1.马尔可夫决策正确性:决策具有历史无关性,即决策只根据当前情况,与之前的过程无关
2.决策:根据策略函数做出决策
3.决策过程:从状态s更新为s',用了什么动作a由策略决定,当
固定不变时,与决策变化无关,即为马尔可夫过程
bellman公式
等价形式
bellman公式推导如下
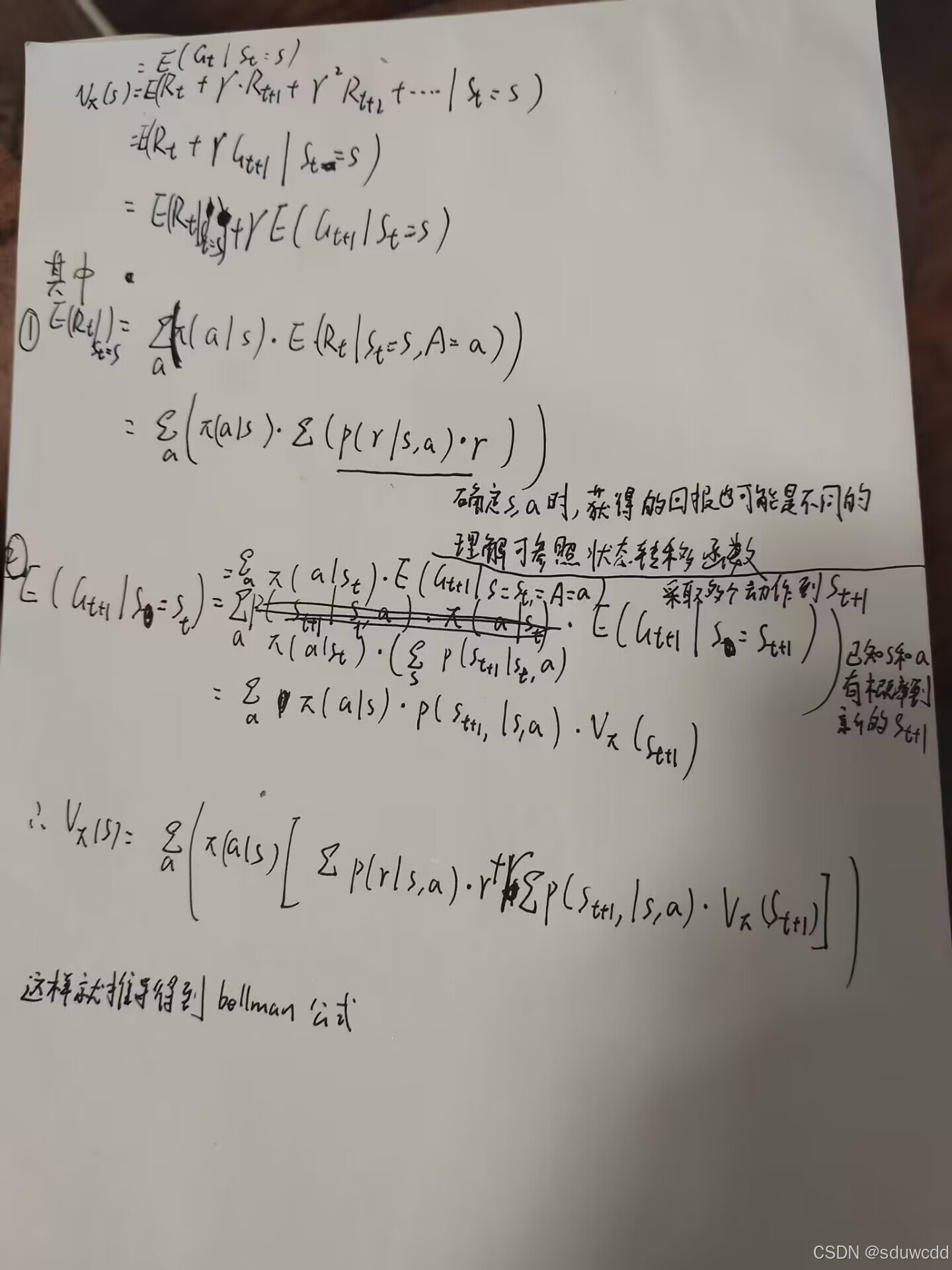
bellman公式求解状态价值函数时用到了
,这就是下面的其中一个问题——自举bootstraping,用自己更新自己
(简单数学问题下)bellman公式对任何状态都适用,所以列出每个状态的bellman公式,联立求解n个线性方程组即可
(在更为一般的情况),对bellman联立的公式用矩阵表示,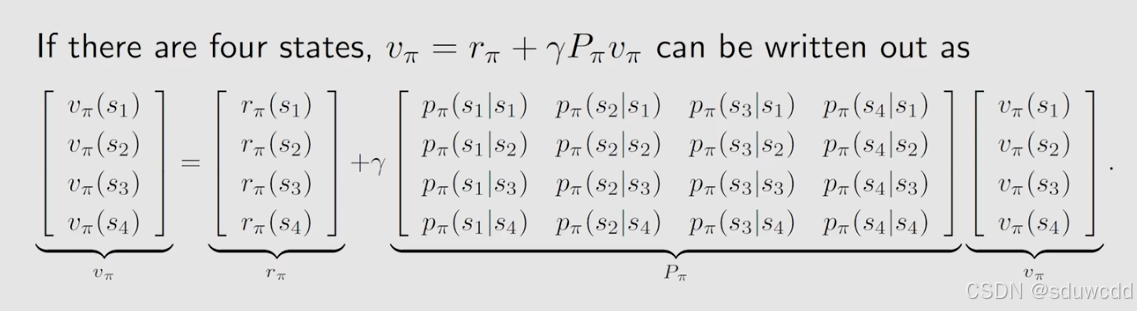
移项,乘以矩阵的逆可求对应解,
但是这种方法计算量大,实际情况也并不好用
注意这里的定义
bellman optimality equation贝尔曼最优公式
elementwise form:
matrix-vector form
贝尔曼最优公式求解正确性证明:
没有具体证明,大致想法是根据贝尔曼最优公式是v=f(v)的形式,证明下面的一个条件,可以使用压缩映射不动点原理,可以证明经过不断迭代过后值趋近于有且仅有一个不动点,这个不动点就是,但是对应的策略
是可以有多个的
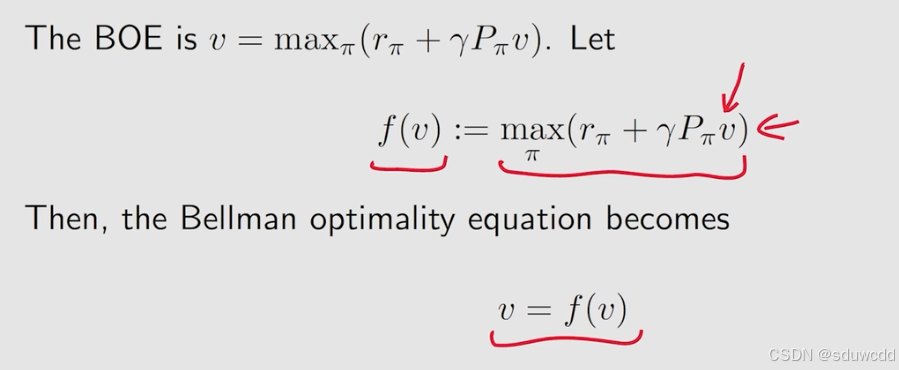

更深入一点,对奖励r做仿射变换ar+b,如何求解最优状态价值函数
以下公式给出了新的最优状态价值函数与变换前的最优状态价值函数之间的关系,新的最优状态价值函数也是原函数的仿射变换,说明原来的策略仍然是最优策略

下面给出证明

值迭代算法
给出一种实际的方法,以一种迭代方式求一个量的近似值,可以证明当k足够大时,二者相等
以下给出计算公式及其证明

基于值迭代算法的bellman最优方程求解算法
对应算法求解的是bellman最优公式,并且采用值迭代近似,这样在过程中最优化,还可得到贪心策略
matrix-vector form
求解时,给定一个随机值,那么括号中的内容都是已知的,对
修改,找到一个最大值,不断迭代更新求得
实际上略有出入


对算法的理解是,每一次动作的更新可能并不是当前所有最好的策略,但是只要v是最终准确的就行
策略迭代算法

截断策略迭代算法
在策略迭代算法的基础上更加实际,在求解时不求解到收敛,而是求解到有限步截断数值直接使用。只做了这一点点改动

蒙特卡洛近似算法
MC basic algorithm
用依据概率抽取的轨迹作无偏估计,不需要知道具体概率就能使用
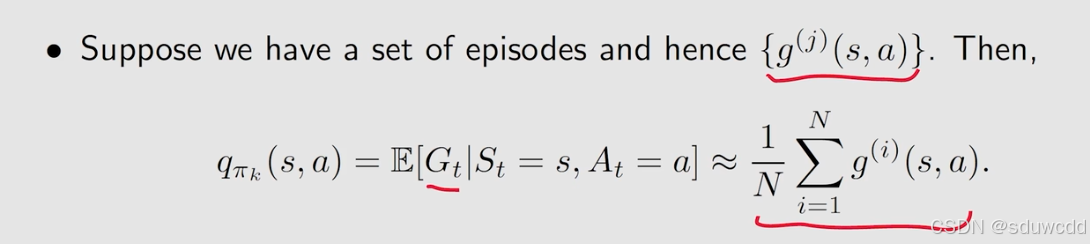

MC exploring starts

可以看到算法使用first-visit strategy
并且做出了优化从episode式子的右边开始计算,可以提高运算效率
MC epsilion greedy
在已知的情况下充分利用可以得到最优解,探索可以找到未来可能有用的地方

Robbins-Monro(RM)算法
RM算法是为了求形如g(w)=0的方程的解
随机梯度下降,EX均值估计属于RM算法

RM定理

可以选取ak=1/k是有效的
满足上面条件时,RM算法一定有效
不满足上面条件,RM算法可能有效
实际情况,ak并不总是=1/k,而是等于一个非常小的常数,让后面更新的数据和前面的数据同样有效果。因为当ak=1/k时,后面的数据的更新效果就很小了
随机梯度收敛性证明

求EX均值估计的可迭代的优化算法
特殊的SGD算法
1.,需要全部x都知道才能求
2.可迭代的优化算法证明如下 这个方法每抽样得到一个x就可以立即求一个迭代过程中的均值
这个方法每抽样得到一个x就可以立即求一个迭代过程中的均值
stochastic gradient descentSGD随机梯度下降算法
解决的问题

最小值有必要条件J的梯度=0
SGD由来,因为梯度下降公式求梯度的期望不符合实际。使用批量梯度下降近似速度还是太慢,令batch=1得到随机梯度下降


值函数近似
使用神经网络对进行近似
objective function:
目标是最小化
求解期望的重点在S的分布
1.所有S服从平均分布,求和求平均
2.更符合实际采用stationary distribution
agent运行多次后这个状态出现的概率
实际求解可以根据等式
求解步骤
梯度下降

对期望采用SGD近似

用蒙特卡洛近似

或者TD近似

注意数学上实际这个替换近似的是这样一个目标函数

伪代码

观察形式,采用值函数的式子,对应值换成了值函数^,并且在最后乘以梯度
价值学习
学习一个价值函数,依据价值函数做出动作
TD算法:temporal difference learning
TD算法只能用来估计state value
是特殊的RM算法,TD算法是不需要模型的

没有模型的基础上求解bellman公式



Q-learning
求最优动作状态价值函数
类似TD算法同理可推


可以强行是on-policy算法

off-policy算法

策略更新可以放到训练q好了再进行
Deep Q-learning/Deep Q-network DQN
DQN:用一个神经网络来近似Q*
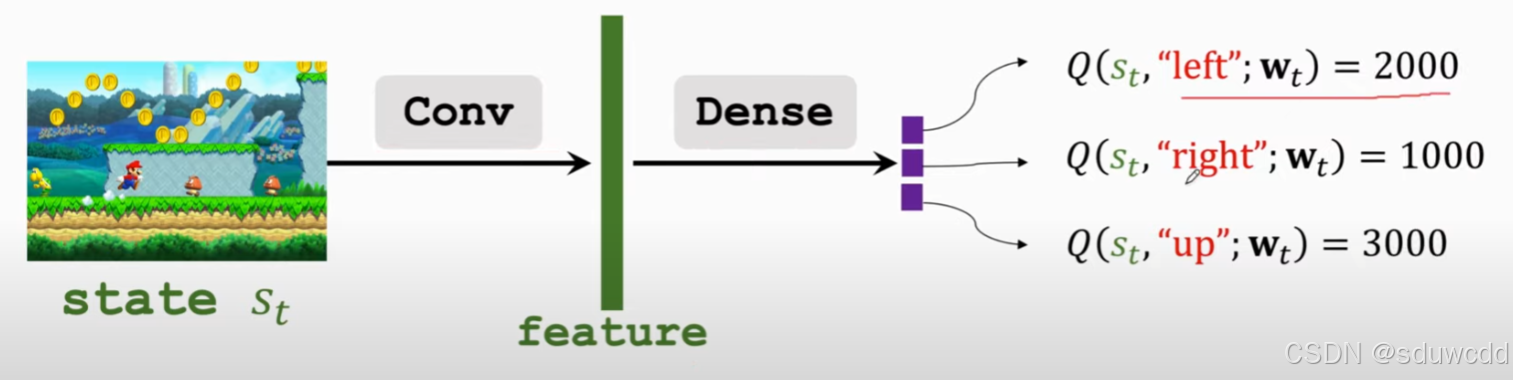
TD算法:
使用td算法条件:(是约等于)
输入:s
输出:对每个a的打分
预测值
执行at后环境更新为st+1并有奖励rt
TD target
loss=
梯度下降更新:


高估问题:

高估原因:
TD算法使DQN高估真实的动作价值
1.求max最大化会导致高估,数学上可证明。Q是DQN神经网络对Q的估计,估计存在误差,在误差均值为0的基础上即无偏估计,E[max(Q预测值)]大于E[max(Q真实值)]
2.bootstraping自举,不断高估
两种解决方案:Target Network 和 Double DQN
Target Network
在DQN的唯一改动在对Q(st+1)上,使用target network,其实就是一个类似于训练过程中的DQN,使用target network计算,一定程度上避免自举

参数w的更新方式

double DQN
不同之处
在a*的选择上


target network 缓解自举造成的高估
double DQN缓解自举和最大化造成的高估
DQN with experience replay

State-Action-Reward-State-Action (SARSA) 算法
直接用来估计动作价值函数
求解的bellman方程和TD算法类似,只是把v变成了q(s,a)

神经网络是标准的价值网络
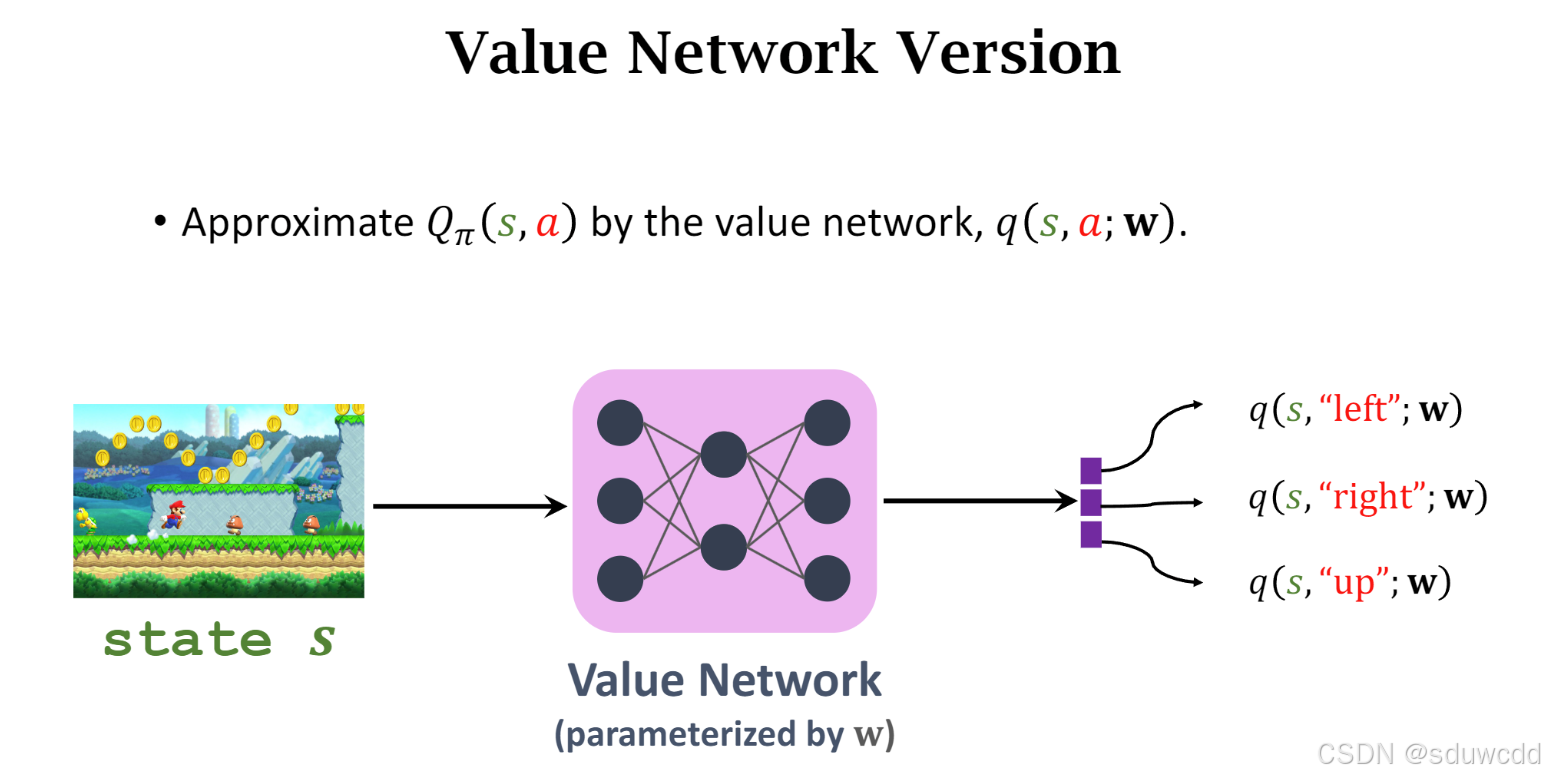
伪代码

可以看到是的策略更新
值函数近似的sarsa

Expected sarsa
在sarsa上做了一点改进,在TD target上

解决的bellman公式
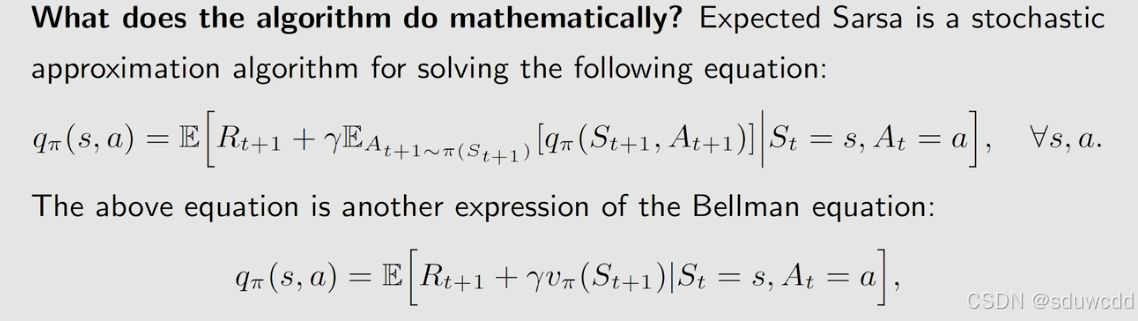
n-step sarsa
“多步 TD target”,它是对标准的 TD target 的推广。它是训练 DQN 和价值网络的常用技巧,它可以让 Sarsa 和 Q-learning 算法效果更好
是介于标准的sarsa和蒙特卡洛近似之间的折中方法,n=1时是sarsa,n=无穷是蒙特卡洛,等于无穷时不需要再求解这一方程了



Experience Replay (经验回放) 和 Prioritized Experience Replay (优先经验回放)
每一个平均概率采样就是经验回放
不平均概率采样就是优先经验回放,对时刻t出现的情况进行排名,出现多的rank高,p取rank的倒数,这样出现少的采样的概率变高,较少出现的情况也能训练得很好
经验回放,把数据都放到一个集合replay buffer中,每次从集合中拿出一些样品来训练神经网络
经验回放有两个好处:1. 重复利用收集到的奖励;2. 打破两条 transitions 之间的相关系



策略学习

策略梯度算法

求一个策略函数,通过
自动控制agent行动

想要求一个策略函数比较困难,将策略函数替换成策略网络,
评估条件
或者写作
有以下两种方式,对应state和策略有关的还有和策略无关的



是立刻奖励的平均期望
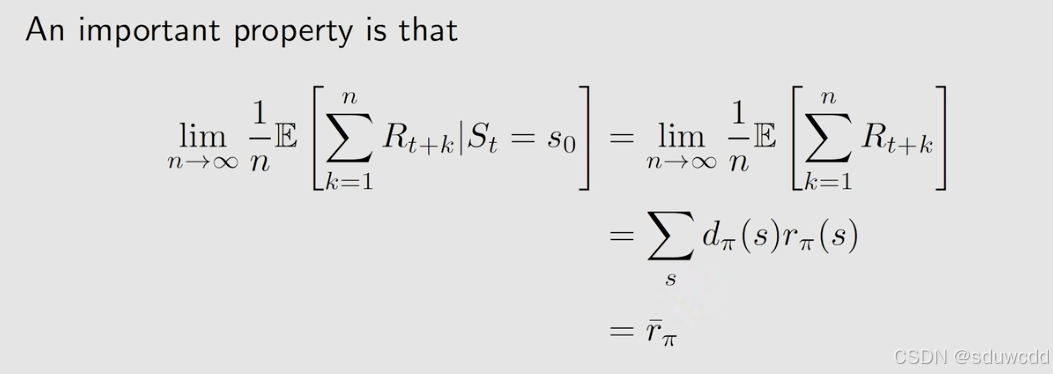
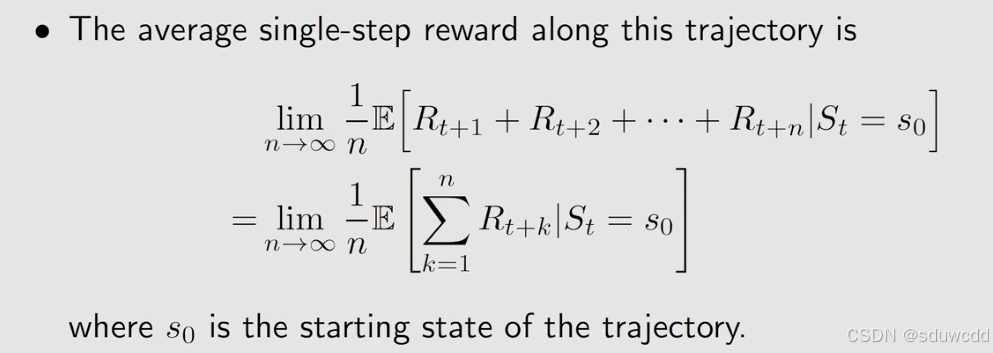
存在这一等式

对评估条件J(\theta)求梯度

写成期望的形式,注意式子中下方期望实际使用SGD来求

证明:
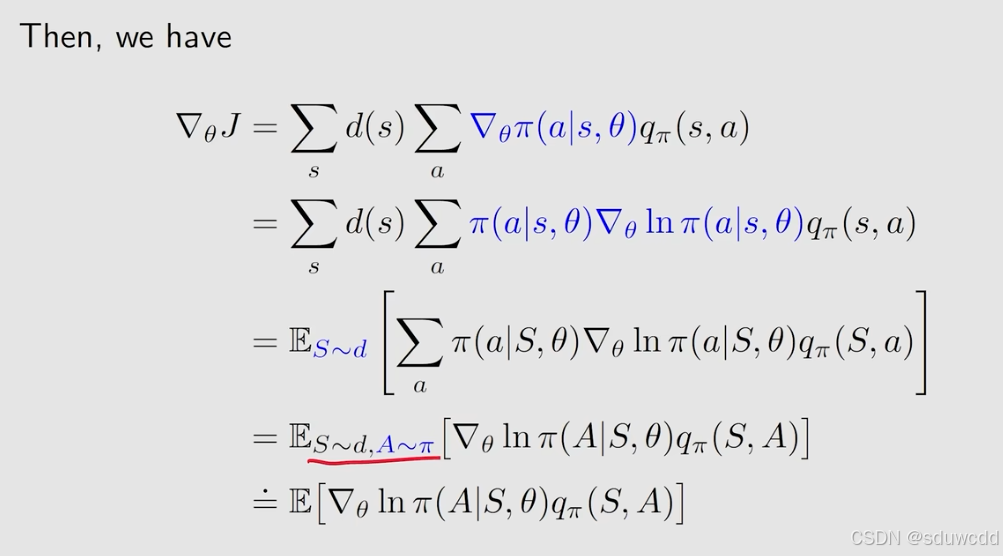
中
不能等于0,处理方法使用softmax函数

输入:s
更新,注意并不是J对\theta的导数,
是策略梯度
reinforce/Monte Carlo policy gradient
算法思想
更新参数时,标准式子采用SGD,但是无法计算,对
采用蒙特卡洛近似,多次从(s,a)出发求回报得到一个近似值估计
,这个就是reinforce算法


式子再修改一下

对beta t的理解:beta t是对充分利用和探索的一个平衡
伪代码

注意:因为每次模拟episode是用到模型的,在每一次迭代时不会对当前的theta修改



如何求


演员-评论家方法
actor-critic QAC 演员-评论家方法
对方法二 演员-评论家方法的具体描述
演员策略网络同价值学习
评论家 价值网络

算法:

使用baseline最后一项qt改为第5条,使用baseline往往效果更好
算法

上面的算法critic使用了sarsa
baseline证明:


b的选择:,因为
是
的期望,是接近
的
蒙特卡洛树搜索
实际上使用更加稳定的方法

Advantage actor-critic A2C方法
在J(\theta)求梯度上的一个优化方法,引入一个无关量b(S)

等式证明
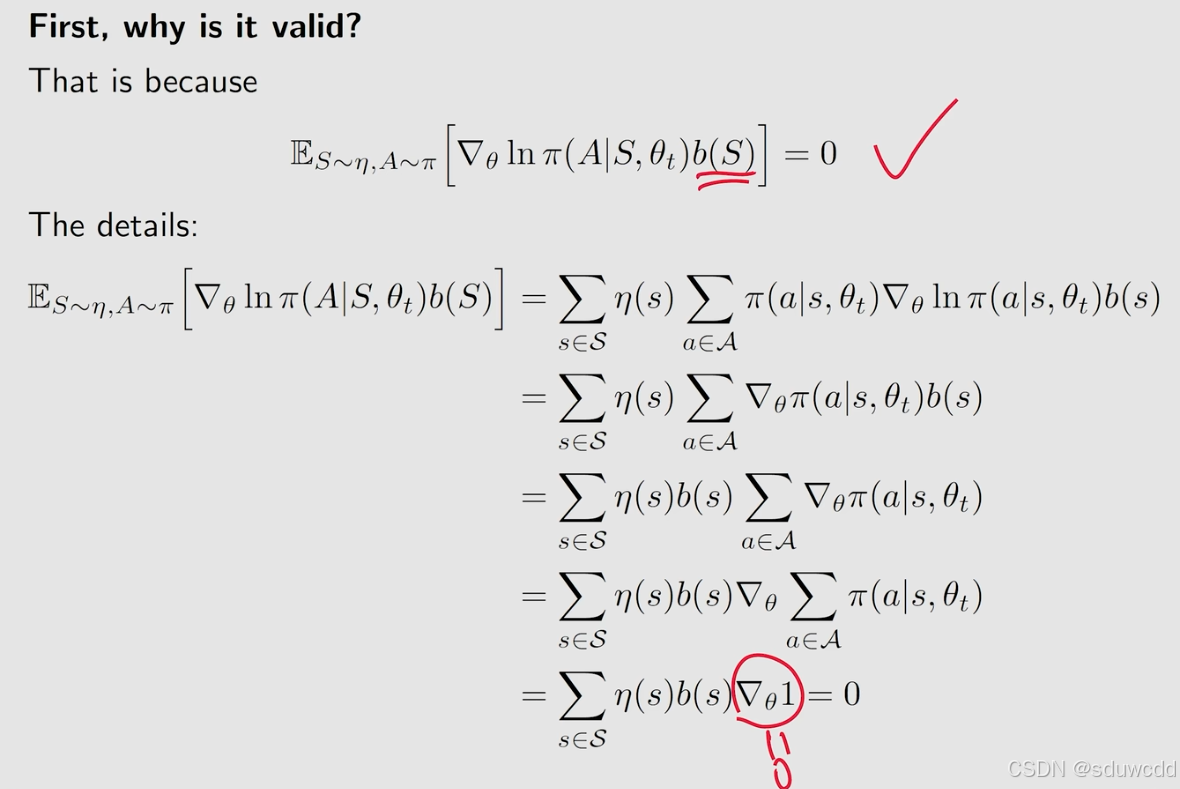
引入后期望不变,方差减小,可以找到一个使得方差最小的b(S)

由上式可以求得一个使得方差最小的b

advantage function
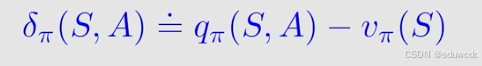



off-policy actor-critic方法
采用importance sampling重要性采样方法(求解期望的任务都可以用)

p0表达式未知,用的是神经网络近似
优化目标

使用baseline



deterministic actor-critic的DPG方法(看个式子)
策略输出从各种动作的概率变成了给定s输出某一个动作




置信域策略优化 (Trust Region Policy Optimization, TRPO)
是一种策略学习算法,目的是学到策略网络。TRPO 与策略梯度算法非常相似,目标函数都是 J(θ);两者的区别在于如何求解 max J(θ)。策略梯度算法使用随机梯度上升,而 TRPO 使用置信域算法 (Trust Region Algorithms)
一局具体的游戏做一次参数更新
每次根据观测值做一次近似
对观测后的函数的参数在置信域内求最大值
处理连续动作空间
见deterministic actor-critic的DPG方法deterministic actor-critic的DPG方法(看个式子)
多智能体强化学习
fully decentralized training
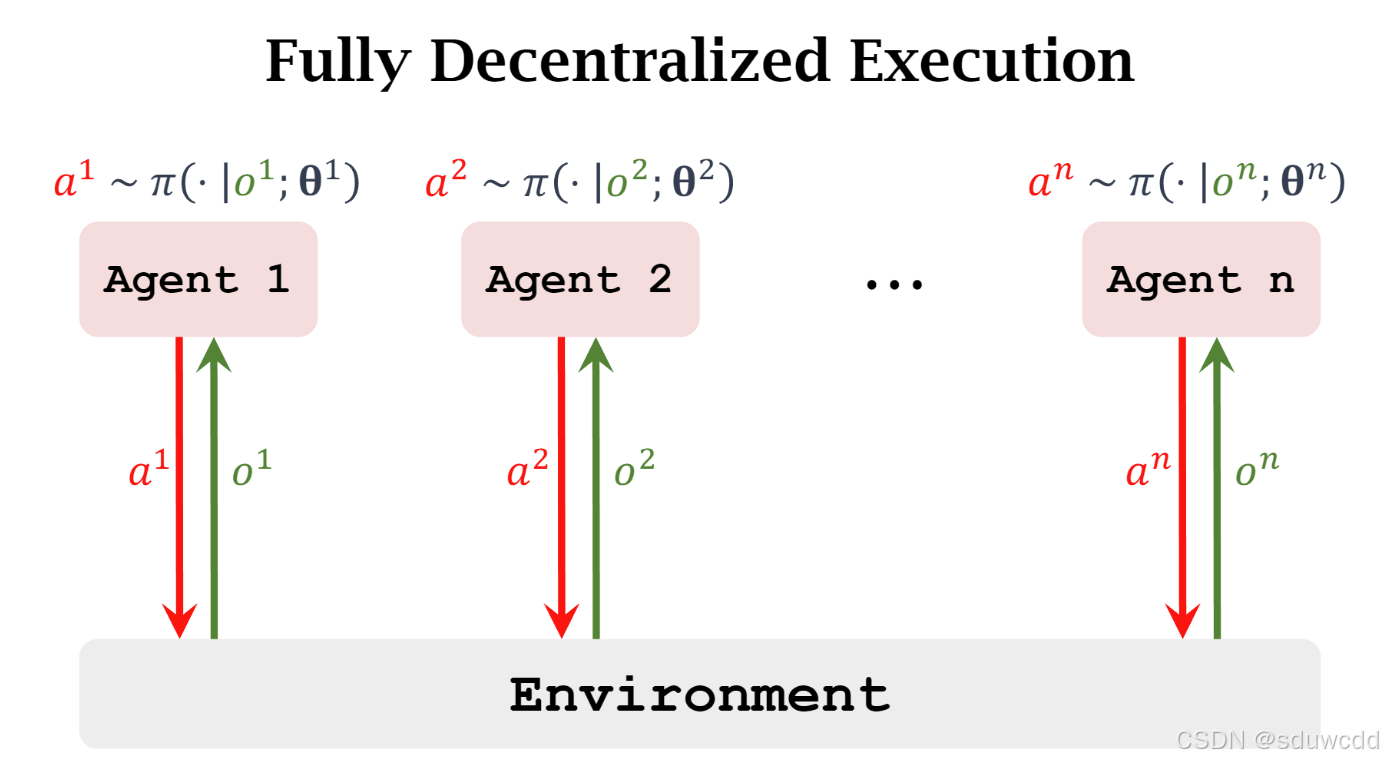
每一个agent独立交互环境,训练方法和之前的内容相同,训练结果往往不好
centralized training
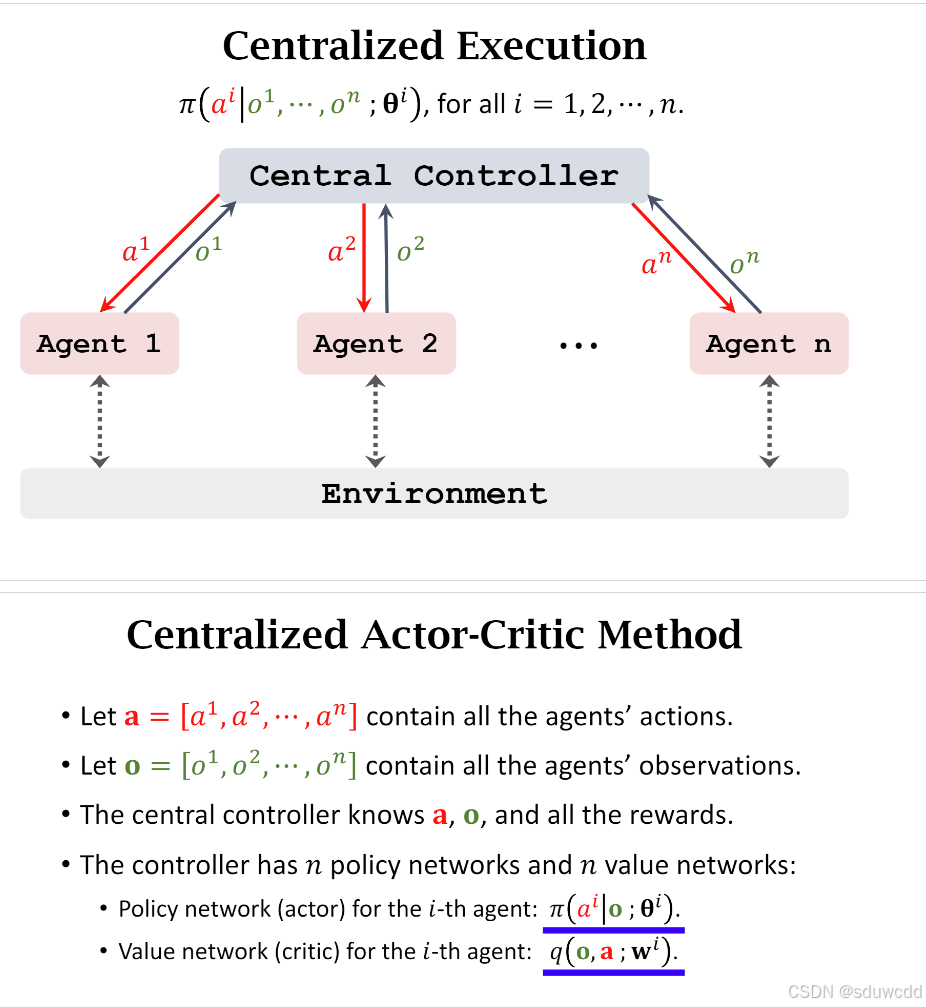
每一个agent将自己观测到的环境交给中央处理器,处理器根据所有的环境做出所有agent的动作,训练效果好但是执行效率低,要等待所有观测值就绪,统一处理
centralized training with decentralized execution
每个agent有自己的策略网络,将观测值都给中央处理器做出打分,agent 更新自己的策略,在执行时,每个agent可以独立快速执行,不需要等待其他agent与环境交互

parameter sharing参数共享

相同的agent用相同的参数
根据具体场景判断agent类型是否相同,如果相同可以使用参数共享
Imitation Learning模仿学习
一个类似监督学习的策略网络,输入观测o,策略网络输出动作a,并且会告诉策略网络正确的a应该是什么,从而模仿人类的行为
behavior cloning BC
采集观测值和人类的行为数据训练
DAgger
对数据集采取的一种方法,先用一些基础的数据集初步训练出一个模型,让模型运行并且采样得到新的数据,并让人类进行标记(也可以用一些准确度高的算法标记),合并入原来的数据集,再训练模型,反复迭代,这样的一个数据就是接近真实数据的,并且数据丰富


模仿学习和强化学习结合



Inverse Reinforcement Learning逆向强化学习
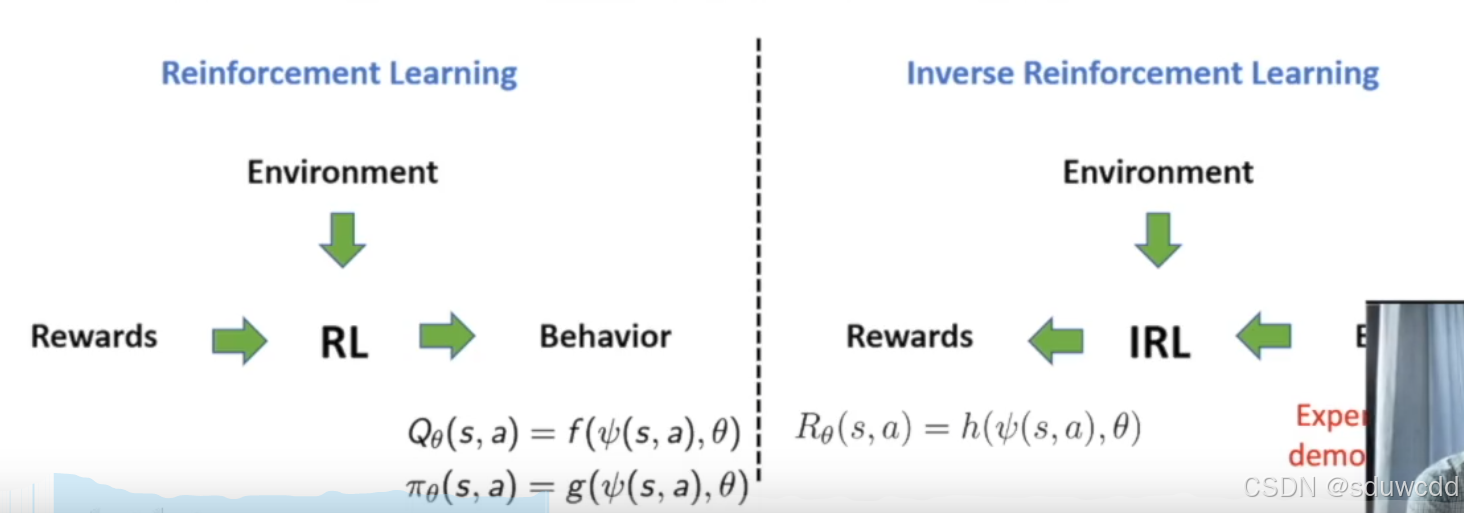
Generative Adversarial Imitation Learning (GAIL)生成对抗性模仿学习 (GAIL)
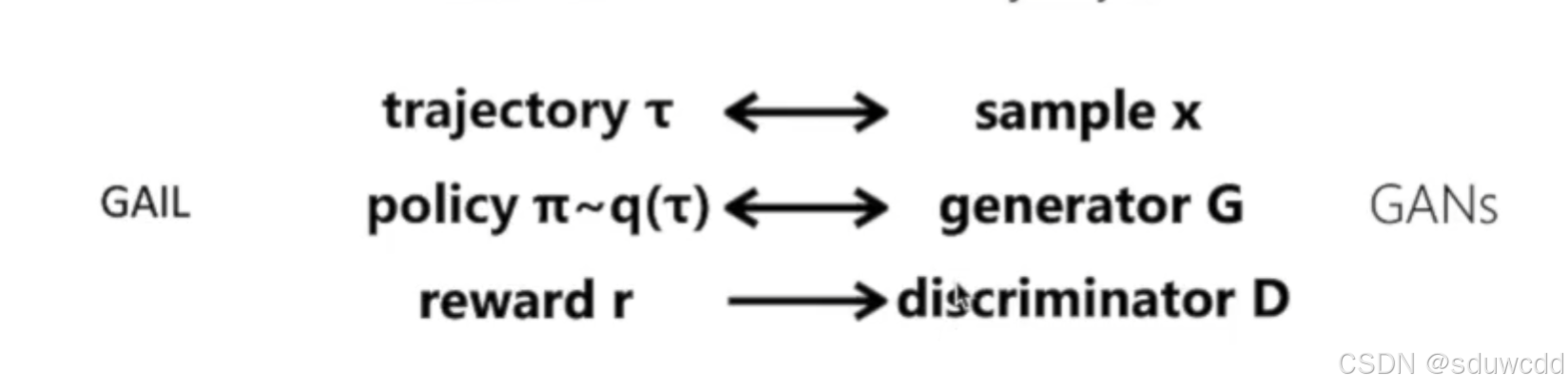
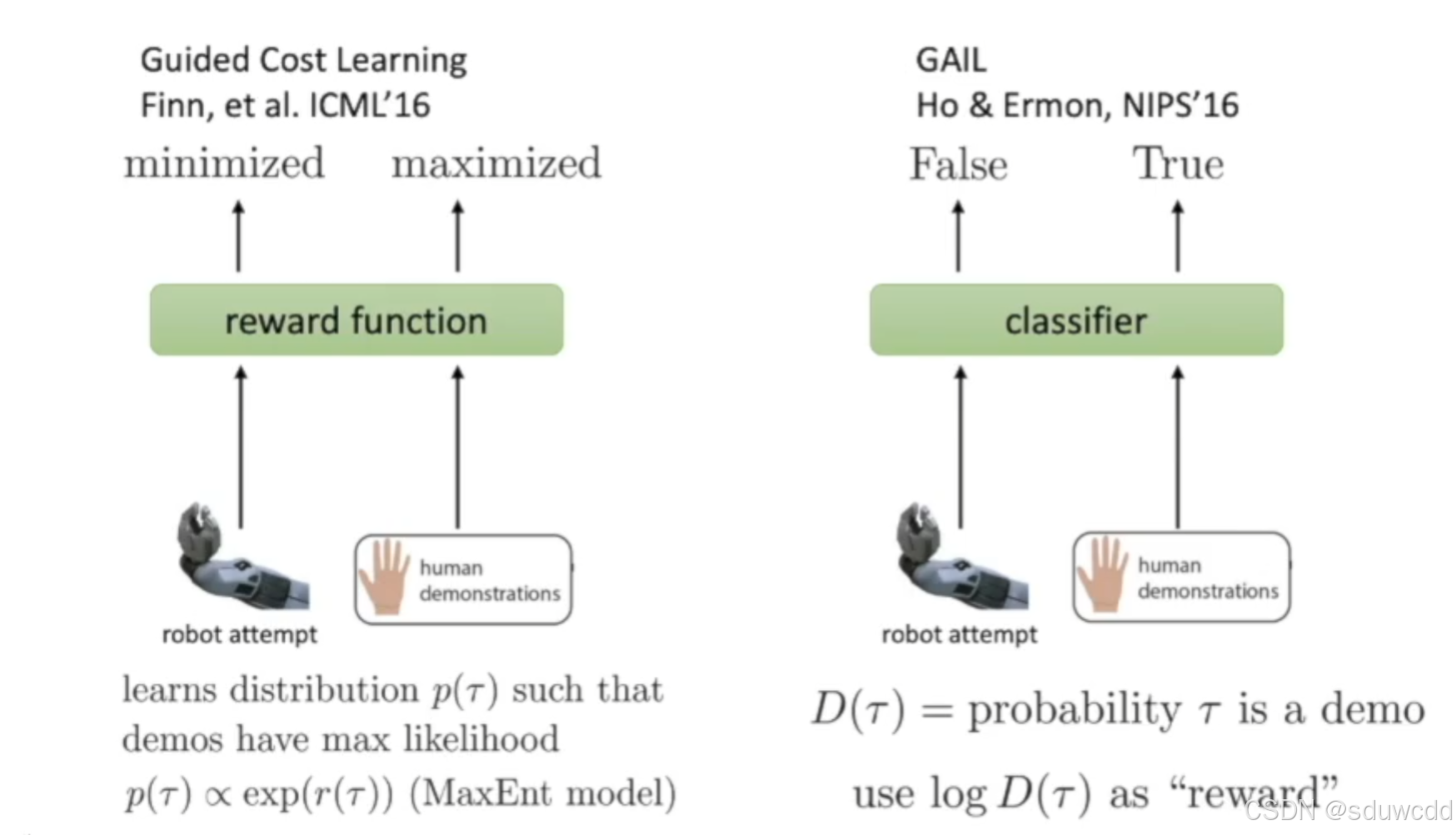
使用LSTM


















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









