







 本文深入探讨了在多核服务器环境下,如何通过RPS/RFS技术优化网络性能,避免网卡中断集中于单一CPU导致的性能瓶颈。介绍了RPS/RFS的工作原理,以及在不同配置下对网络性能的影响,特别强调了在单队列网卡环境下如何实现优化。
本文深入探讨了在多核服务器环境下,如何通过RPS/RFS技术优化网络性能,避免网卡中断集中于单一CPU导致的性能瓶颈。介绍了RPS/RFS的工作原理,以及在不同配置下对网络性能的影响,特别强调了在单队列网卡环境下如何实现优化。
背景
在服务器网卡收包发包数量非常大时,在系统繁忙时,如果过多网卡中断集中在单一cpu上导致cpu来不及响应造成网络性能下降,网络性能的瓶颈一般不在网卡而在cpu,现在的网卡很多支持万兆和多队列。
为了解决网卡中断集中在单一cpu的问题,在多核服务器上,需要通过将中断队列绑定到不同的cpu。主要有两种情况,多队列多重中断网卡通过SMP IRQ affinity方法绑定到不同的cpu,单队列网卡通过RPS/RFS模拟多队列多重中断网卡的功能,将模拟的软件队列绑定到不同的CPU。RPS/RFS在多队列多重中断网卡多cpu环境不起作用,在网卡队列少于cpu核数时,可以解决cpu负载不均衡的问题。
网卡多队列
网卡多队列需要多队列网卡的支持,是在硬件网卡上支持的。常用的Intel的82575、82576,I350,Boardcom的57711等网卡都支持多队列.如果是实体机,可通过如下方式判断是否支持多队列:lspci -vvv #lspci在centos 6.x之后的版本不会默认安装,可yum install pciutils进行安装。如果Ethernet条目下有Message Signaled Interrupts(MSI),则网卡支持多队列。

线上使用的是XEN镜像的虚拟机,为单队列网卡,不支持网卡多队列特征(升级的kvm镜像支持网卡多队列)。在linux 2.6.35内核版本以后,提交的patch RPS采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载, 把软中断分到各个CPU处理,而不需要硬件支持,大大提高了网络性能。
网卡中断
对于多队列网卡在硬件层支持了多队列中断,网卡发送硬件中断到中断控制器然后触发cpu软中断。对于单队列网卡,可以在操作系统层RPS/RFS模拟软件多队列中断触发cpu软中断。

RPS/RFS
- RPS 全称是 Receive Packet Steering, 这是Google工程师 Tom Herbert (therbert@google.com )提交的内核补丁, 在2.6.35进入Linux内核. 这个patch采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载, 把软中断分到各个CPU处理,而不需要硬件支持,大大提高了网络性能。
- RFS 全称是 Receive Flow Steering, 这也是Tom提交的内核补丁,它是用来配合RPS补丁使用的,是RPS补丁的扩展补丁,它把接收的数据包送达应用所在的CPU上,提高cache的命中率。
- 这两个补丁往往都是一起设置,来达到最好的优化效果, 主要是针对单队列网卡多CPU环境(多队列多重中断的网卡也可以使用该补丁的功能,但多队列多重中断网卡有更好的选择:SMP IRQ affinity)
SMP IRQ affinity
多队列网卡的cpu亲和性设置网上资料很多,这里不再做介绍。下面主要对我们使用的单队列网卡虚拟机采用RPS/RFS优化设置进行介绍。
优化过程
RPS cpu bitmap测试分类: 0(不开启rps功能,默认), one cpu per queue(每队列绑定到1个CPU核上), all cpus per queue(每队列绑定到所有cpu核上), 不同分类的设置值如下
- 0(不开启rps功能)
/sys/class/net/eth0/queues/rx-0/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-1/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-2/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-3/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-4/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-5/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-6/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-7/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 0 /proc/sys/net/core/rps_sock_flow_entries 0
- one cpu per queue(每队列绑定到1个CPU核上)
/sys/class/net/eth0/queues/rx-0/rps_cpus 00000001 /sys/class/net/eth0/queues/rx-1/rps_cpus 00000002 /sys/class/net/eth0/queues/rx-2/rps_cpus 00000004 /sys/class/net/eth0/queues/rx-3/rps_cpus 00000008 /sys/class/net/eth0/queues/rx-4/rps_cpus 00000010 /sys/class/net/eth0/queues/rx-5/rps_cpus 00000020 /sys/class/net/eth0/queues/rx-6/rps_cpus 00000040 /sys/class/net/eth0/queues/rx-7/rps_cpus 00000080 /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 4096 /proc/sys/net/core/rps_sock_flow_entries 32768
- all cpus per queue(每队列绑定到所有cpu核上)
/sys/class/net/eth0/queues/rx-0/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-1/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-2/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-3/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-4/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-5/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-6/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-7/rps_cpus 000000ff /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 4096 /proc/sys/net/core/rps_sock_flow_entries 32768
环境中设置为all cpus per queue,下图中优化后效果,优化前中断集中在cpu0,设置后均衡分配在cpu0-cpu3.
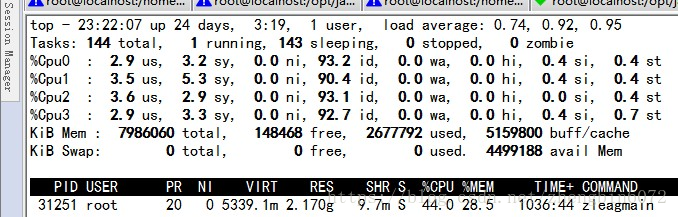
one cpu per queue方法在接收udp包时可能会造成网络性能下降,中断集中在单一cpu的情况。具体参考https://blog.youkuaiyun.com/yy405145590/article/details/9837839
参考文章:
https://blog.youkuaiyun.com/qiushanjushi/article/details/44244643 Linux系统中RPS/RFS介绍
https://www.cnblogs.com/zhjh256/p/6020609.html 年后vmware linux top si高以及网卡队列. 软负载相关优化
https://blog.youkuaiyun.com/yy405145590/article/details/9837839 Linux内核 RPS/RFS功能详细测试分析
https://blog.youkuaiyun.com/wangjianno2/article/details/48983999/ 网卡多队列学习小结
https://support.huaweicloud.com/usermanual-ecs/zh-cn_topic_0058758453.html# 开启网卡多队列功能

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









