







 本文详细探讨了Java虚拟机中的内存区域,特别是Java堆内存结构,包括虚拟机栈、本地方法栈、方法区、直接内存、新生代和老年代,以及它们在内存溢出情况下的处理。同时介绍了内存监控工具的使用,如JConsole和JMap,并提到了Kafka架构的相关面试问题和学习资源。
本文详细探讨了Java虚拟机中的内存区域,特别是Java堆内存结构,包括虚拟机栈、本地方法栈、方法区、直接内存、新生代和老年代,以及它们在内存溢出情况下的处理。同时介绍了内存监控工具的使用,如JConsole和JMap,并提到了Kafka架构的相关面试问题和学习资源。
第二,Java虚拟机栈和本地方法栈,这两个区域的区别不过是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则为虚拟机使用到的Native方法服务,在内存分配异常上是相同的。在JVM规范中,对Java虚拟机栈规定了两种异常:1.如果线程请求的栈大于所分配的栈大小,则抛出StackOverFlowError错误,比如进行了一个不会停止的递归调用;2. 如果虚拟机栈是可以动态拓展的,拓展时无法申请到足够的内存,则抛出OutOfMemoryError错误。
第三,直接内存。直接内存虽然不是虚拟机运行时数据区的一部分,但既然是内存,就会受到物理内存的限制。在JDK1.4中引入的NIO使用Native函数库在堆外内存上直接分配内存,但直接内存不足时,也会导致OOM。
第四,方法区。随着Metaspace元数据区的引入,方法区的OOM错误信息也变成了“java.lang.OutOfMemoryError:Metaspace”。对于旧版本的Oracle JDK,由于永久代的大小有限,而JVM对永久代的垃圾回收并不积极,如果往永久代不断写入数据,例如String.Intern()的调用,在永久代占用太多空间导致内存不足,也会出现OOM的问题,对应的错误信息为“java.lang.OutOfMemoryError:PermGen space”
| 内存区域 | 是否线程私有 | 是否可能发生OOM |
| — | — | — |
| 程序计数器 | 是 | 否 |
| 虚拟机栈 | 是 | 是 |
| 本地方法栈 | 是 | 是 |
| 方法区 | 否 | 是 |
| 直接内存 | 否 | 是 |
| 堆 | 否 | 是 |
堆内存结构是怎么样的?
===========
可以借助一些工具来了解JVM的内存内容,具体到特定的内存区域,应该用什么工具去定位呢?
-
图形化工具。图形化工具的优点是直观,连接到Java进程后,可以显示堆内存、堆外内存的使用情况,类似的工具有**JConsole**,VisualVm等。
-
命令行工具。这类工具可以在运行时进行查询,包括jstat,jmap等,可以对堆内存、方法区等进行查看。定位线上问题时也多会使用这些工具。jmap也可以生成堆转储文件(Heap Dump)文件,如果是在linux上,可以将堆转储文件拉到本地来,使用Eclipse MAT进行分析,也可以使用jhap进行分析。
关于内存的监控与诊断,在后面会进行深入了解。现在来看下一个问题:堆内的结构是怎么的呢?
站在垃圾收集器的角度来看,可以把内存分为新生代与老年代。内存的分配规则取决于当前使用的是哪种垃圾收集器的组合,以及内存相关的参数配置。往大的方向说,对象优先分配在新生代的Eden区域,而大对象直接进入老年代。
第一, 新生代的Eden区域,对象优先分配在该区域,同时JVM可以为每个线程分配一个私有的缓存区域,称为TLAB(Thread Local Allocation Buffer),避免多线程同时分配内存时需要使用加锁等机制而影响分配速度。TLAB在堆上分配,位于Eden中。TLAB的结构如下:
// ThreadLocalAllocBuffer: a descriptor for thread-local storage used by
// the threads for allocation.
// It is thread-private at any time, but maybe multiplexed over
// time across multiple threads. The park()/unpark() pair is
// used to make it avaiable for such multiplexing.
class ThreadLocalAllocBuffer: public CHeapObj {
friend class VMStructs;
private:
HeapWord* _start; // address of TLAB
HeapWord* _top; // address after last allocation
HeapWord* _pf_top; // allocation prefetch watermark
HeapWord* _end; // allocation end (excluding alignment_reserve)
size_t _desired_size; // desired size (including alignment_reserve)
size_t _refill_waste_limit; // hold onto tlab if free() is larger than this
从本质上来说,TLAB的管理是依靠三个指针:start、end、top。start与end标记了Eden中被该TLAB管理的区域,该区域不会被其他线程分配内存所使用,top是分配指针,开始时指向start的位置,随着内存分配的进行,慢慢向end靠近,当撞上end时触发TLAB refill。因此内存中Eden的结构大体为:

第二、新生代的Survivor区域。当Eden区域内存不足时会触发Minor GC,也称为新生代GC,在Minor GC存活下来的对象,会被复制到Survivor区域中。我认为Survivor区的作用在于避免过早触发Full GC。如果没有Survivor,Eden区每进行一次Minor GC都把对象直接送到老年代,老年代很快便会内存不足引发Full GC。新生代中有两个Survivor区,我认为两个Survivor的作用在于提高性能,避免内存碎片的出现。在任何时候,总有一个Survivor是empty的,在发生Minor GC时,会将Eden及另一个的Survivor的存活对象拷贝到该empty Survivor中,从而避免内存碎片的产生。新生代的内存结构大体为:

第三、老年代。老年代放置长生命周期的对象,通常是从Survivor区域拷贝过来的对象,不过当对象过大的时候,无法在新生代中用连续内存的存放,那么这个大对象就会被直接分配在老年代上。一般来说,普通的对象都是分配在TLAB上,较大的对象,直接分配在Eden区上的其他内存区域,而过大的对象,直接分配在老年代上。
第四、永久代。如前面所说,在早起的Hotspot JVM中有老年代的概念,老年代用于存储Java类的元数据、常量池、Intern字符串等。在JDK8之后,就将老年代移除,而引入元数据区的概念。
第五、Vritual空间。前面说过,可以使用Xms与Xmx来指定堆的最小与最大空间。如果Xms小于Xmx,堆的大小不会直接扩展到上限,而是留着一部分等待内存需求不断增长时,再分配给新生代。Vritual空间便是这部分保留的内存区域。
那么综上所述,可以画出Java堆内的内存结构大体为:

通过一些参数,可以来指定上述的堆内存区域的大小:
-Xmx value 指定最大的堆大小
-Xms value 指定初始的最小堆大小
-XX:NewSize = value 指定新生代的大小
-XX:NewRatio = value 老年代与新生代的大小比例。默认情况下,这个比例是2,也就是说老年代是新生代的2倍大。老年代过大的时候,Full GC的时间会很长;老年代过小,则很容易触发Full GC,Full GC频率过高,这就是这个参数会造成的影响。
-XX:SurvivorRation = value . 设置Eden与Srivivor的大小比例,如果该值为8,代表一个Survivor是Eden的1/8,是整个新生代的1/10。
常用的性能监控与问题定位工具有哪些?
==================
在系统的性能分析中,CPU、内存与IO是主要的关注项。很多时候服务出现问题,在这三者上会体现出现,比如CPU飙升,内存不足发生OOM等,这时候需要使用对应的工具,来对性能进行监控,对问题进行定位。
对于CPU的监控,首先可以使用top命令来进行查看,下面是使用top查看负载的一个截图:

load average 代表1分钟、5分钟、15分钟的系统平均负载,从这三个数字,可以判断系统负荷是大还是小。当CPU完全空闲的时候,平均负荷为0;当CPU工作量饱和的时候,平均负荷为1。因此 load average 这三个数值越低,代表系统负荷越小,那么什么时候能看出系统负荷比较重呢?这篇文章(Understanding Linux CPU Load - when should you be worried)里解释得非常通俗。如果电脑里只有一个CPU,把CPU看成一条单行桥,桥上只有一个车道,所有的车都必须从这个桥上通过。那么
- 系统负荷为0,代表桥上一辆车也没有

- 系统负荷0.5,意味着桥上一半路段上有车

- 系统负荷1,意味着桥上道路已经被车占满

自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

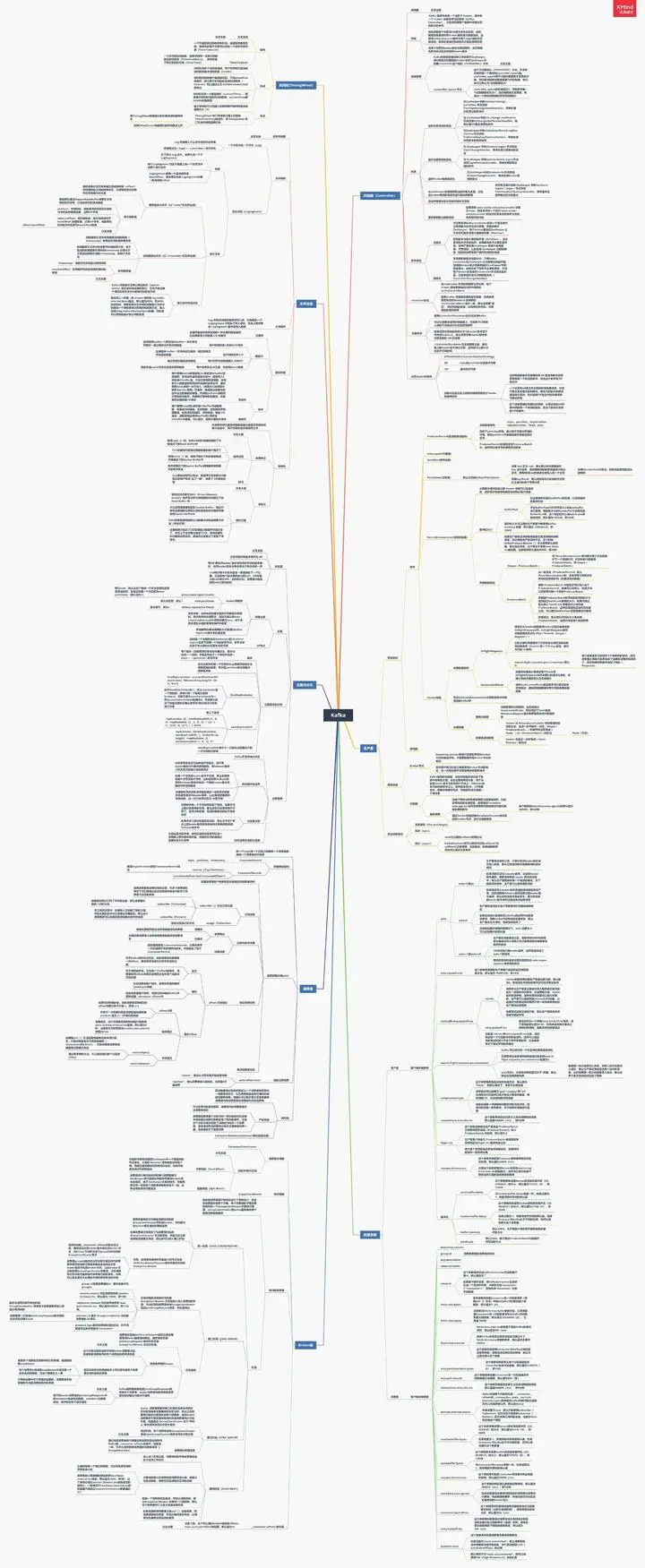
总结:绘上一张Kakfa架构思维大纲脑图(xmind)
其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)
[外链图片转存中…(img-MBOTXmUZ-1713537258489)]
[外链图片转存中…(img-zfXhcwgT-1713537258489)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









