#!/usr/bin/env python3
#-*- coding:utf-8-*-
import os
import sys
import logging
from urllib import request
from bs4 import BeautifulSoup as bs
import pandas as pd
import re
from urllib.parse import urljoin
import codecs
import matplotlib.pyplot as plt
from matplotlib import font_manager
import matplotlib
import numpy as np
import logging
import time
import threading
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
logging.info('start...')
BookData=[]
UserfulData=[]
UrlData=[]
def Timer():
i=0
Process=""
while 1:
i=i+1
Process=Process+"="
print(Process+">wait "+str(i)+" s",end='\r')
time.sleep(1)
try:
if flag == True:
break
except:
print
else:
print
threading.Thread(target=Timer).start()
if __name__ == "__main__":
base_url = "https://movie.douban.com"
First_page_url = base_url+"/review/best"
UrlData.append(First_page_url)
temp_url=First_page_url
while 1:
try:
html = request.urlopen(temp_url).read()
html = str(html,encoding = "utf-8")
soup = bs(html,'html.parser')
netx_url = soup.find(rel='next')['href']
temp_url= base_url+netx_url
except Exception as err:
logging.info(' url get has done')
break
else:
UrlData.append(base_url+netx_url)
for http in UrlData:
respone = request.urlopen(http)
html = respone.read()
html = str(html,encoding = "utf-8") # encoding = "utf-8" 可查看网址源码确定 字符编码类型
with codecs.open('1.html','w','utf-8') as html_file:
html_file.write(html)
soup = bs(html,'html.parser')
#DIV = soup.find_all(class_="main review-item")
DIV = soup.find_all('img')
for i in range(len(DIV)):
if 'title' in DIV[i].attrs:
BookData.append(DIV[i].attrs['title'])
#print (BookData)
DIV = soup.find_all("div",class_="action")
for i in range(len(DIV)):
Approve=DIV[i].get_text().replace(' ','').strip().split('\n')[0]
UserfulData.append(Approve)
#print (UserfulData)
print (BookData)
print (UserfulData)
X=[]
Y=[]
LIST=sorted(zip(BookData,map(int,UserfulData)),key=lambda item:item[1])
for i in LIST:
X.append(i[0])
Y.append(i[1])
print (LIST)
flag=True
plt.rc('font', family='SimHei', size=13)
plt.title(" TOP 10",color='blue')
plt.barh(range(len(X)), Y,tick_label=X)
#c = np.arange(len(Y))
for i in np.arange(len(Y)):
plt.text(Y[i],i,str(Y[i]), fontsize=15,ha='left',wrap=True,va='center') # YX
#plt.text(i,Y[i],str(Y[i]), fontsize=15,ha='center',wrap=True,va='baseline') #XY
plt.show()
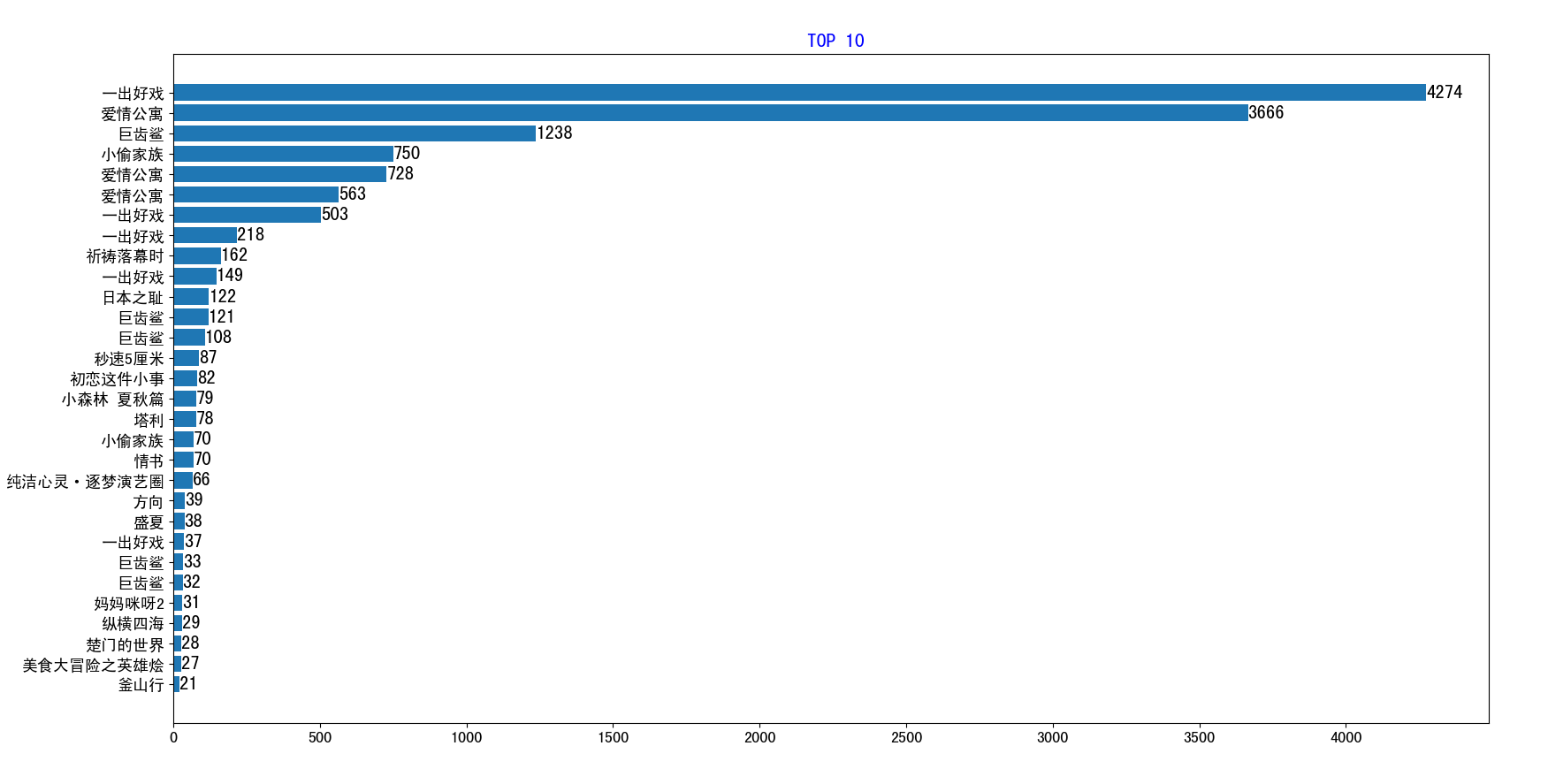








 本博客介绍了一个使用Python进行网页爬取的实例,针对豆瓣网站的电影评论页面,抓取了电影标题和用户点赞数,并利用matplotlib进行了数据可视化,展示了最受欢迎的电影排名。
本博客介绍了一个使用Python进行网页爬取的实例,针对豆瓣网站的电影评论页面,抓取了电影标题和用户点赞数,并利用matplotlib进行了数据可视化,展示了最受欢迎的电影排名。

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









