



 在学习Python爬虫过程中,遇到一个网站需要处理__VIEWSTATE和__EVENTVALIDATION参数以进行分页和条件查询。传统的获取并填充这些参数的方法对于该特定网站无效,因为还需要传递其他四个空参数。同时,解决头信息问题,从不传到传入User-Agent和cookie,最终成功获取数据。
在学习Python爬虫过程中,遇到一个网站需要处理__VIEWSTATE和__EVENTVALIDATION参数以进行分页和条件查询。传统的获取并填充这些参数的方法对于该特定网站无效,因为还需要传递其他四个空参数。同时,解决头信息问题,从不传到传入User-Agent和cookie,最终成功获取数据。
最近初学了python爬虫,在爬取一个网站时遇到了__VIEWSTATE和__EVENTVALIDATION这几个参数导致分页和按条件查询获取不到数据。网上大部分能搜到的解决方式都是先用get或者post方法请求一次,并且通过正则或者其他方式获取到页面上的这两个数据,然后带入Post请求进行传参,这种方法并没用问题,但针对我所爬取的这个网站有两个踩坑的地方。
一、第一次请求时基本是不带任何参数的,在第一次请求之后,选择分页或者条件查询时,看清此次请求时需要传的参数,网上基本上说的是第二次请求时带入__VIEWSTATE和__EVENTVALIDATION这两个值,但我实际操作爬取这个网站时,单单传入这两个值是不够的

除了__VIEWSTATE和__EVENTVALIDATION以及条件查询时需要传入的参数之外,空框这四个参数也需要传入,哪怕没有值也得传一个空字符串过去,不然有可能会得不到数据。
二、就是大部分爬虫时遇到的头信息的问题
先从不传头信息,到传入User-Agent,再到传入cookie,这才获取到数据。在保证参数没有问题时,可以一点一点添加头信息尝试。
下面是我爬虫代码以及运行结果

# coding=utf-8
import re
from pip._vendor import requests
base_url = r'http://ggzy.bengbu.gov.cn/bbfwweb/ShowInfo/MoreInfo2zfcg.aspx?CategoryNum=003002'
headers2={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
}
r1 = requests.get(base_url, headers=headers2)
VIEWSTATE = re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', r1.content,re.I)
EVENTVALIDATION = re.findall(r'input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value="(.*?)" />', r1.content, re.I)
values = {}
print EVENTVALIDATION
print VIEWSTATE
headers2['Cookie'] = r1.headers['Set-Cookie']
values['__EVENTVALIDATION'] = EVENTVALIDATION[0]
values['__VIEWSTATE'] = VIEWSTATE[0]
values['__EVENTTARGET'] = ''
values['__EVENTARGUMENT'] = ''
values['__VIEWSTATEGENERATOR'] = '3F98F769'
values['__VIEWSTATEENCRYPTED'] = ''
values['xiaqucode'] = '全部'
values['jyfs'] = '全部'
values['Button1'] = '搜索'
r = requests.post(base_url, data=values, headers=headers2)
print r.content.decode('utf-8')
运行结果


如果操作分页时
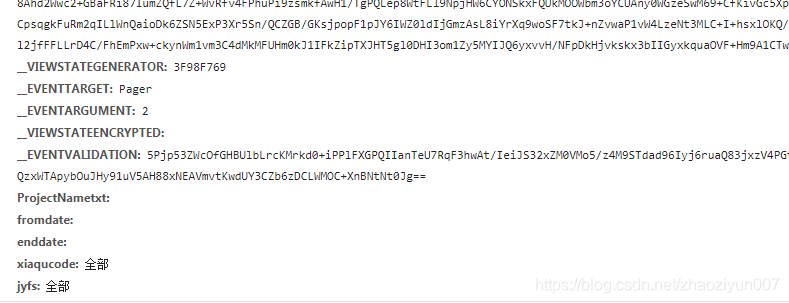
# coding=utf-8
import re
from pip._vendor import requests
base_url = r'http://ggzy.bengbu.gov.cn/bbfwweb/ShowInfo/MoreInfo2zfcg.aspx?CategoryNum=003002'
headers2={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
}
r1 = requests.get(base_url, headers=headers2)
VIEWSTATE = re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', r1.content,re.I)
EVENTVALIDATION = re.findall(r'input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value="(.*?)" />', r1.content, re.I)
values = {}
print EVENTVALIDATION
print VIEWSTATE
headers2['Cookie'] = r1.headers['Set-Cookie']
values['__EVENTVALIDATION'] = EVENTVALIDATION[0]
values['__VIEWSTATE'] = VIEWSTATE[0]
values['__EVENTTARGET'] = 'Pager'
values['__EVENTARGUMENT'] = '2'
values['__VIEWSTATEGENERATOR'] = '3F98F769'
values['__VIEWSTATEENCRYPTED'] = ''
values['xiaqucode'] = '全部'
values['jyfs'] = '全部'
r = requests.post(base_url, data=values, headers=headers2)
print r.content.decode('utf-8')
结果就不贴了反正是对的
知道了怎么传参,能获取到数据,就可以放到scrapy这种爬虫框架里慢慢玩了


















 9649
9649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









