




 本文详细介绍了Hive中MapReduce任务的执行过程,包括Map数量的确定,强调Map数量并非越多越好,尤其是对于小文件过多的情况。Reduce数量可以根据输入数据量自定义,过多的Reducer也会带来问题。建议通过调整参数和使用小文件合并机制来优化作业性能。
本文详细介绍了Hive中MapReduce任务的执行过程,包括Map数量的确定,强调Map数量并非越多越好,尤其是对于小文件过多的情况。Reduce数量可以根据输入数据量自定义,过多的Reducer也会带来问题。建议通过调整参数和使用小文件合并机制来优化作业性能。
一、总览MR执行过程
一般的 MapReduce 程序会经过以下几个过程:输入(Input)、输入分片(Splitting)、Map阶段、Shuffle阶段、Reduce阶段、输出(Final result)。
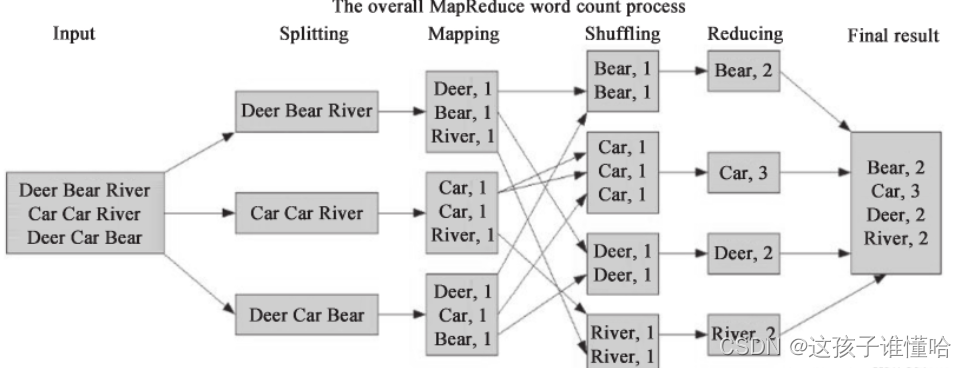
1、输入就不用说了,数据一般放在 HDFS 上面就可以了,而且文件是被分块的。关于文件块和文件分片的关系,在输入分片中说明。
2、输入分片:在进行 Map 阶段之前,MapReduce 框架会根据输入文件计算输入分片(split),每个输入分片会对应一个 Map 任务,输入分片往往和 HDFS 的块关系很密切。例如,HDFS 的块的大小是 128M,如果我们输入两个文件,大小分别是 27M、129M,那么 27M 的文件会作为一个输入分片(不足 128M 会被当作一个分片),而 129MB 则是两个输入分片(129-128=1,不足 128M,所以 1M 也会被当作一个输入分片),所以,一般来说,一个文件块会对应一个分片。Splitting 对应下面的三个数据应该理解为三个分片。
3、Map 阶段:这个阶段的处理逻辑就是编写好的 Map 函数,因为一个分片对应一个 Map 任务,并且是对应一个文件块,所以这里其实是数据本地化的操作,也就是所谓的移动计算而不是移动数据。如上图所示,这里的操作其实就是把每句话进行分割,然后得到每个单词,再对每个单词进行映射,得到单词和1的键值对。
4、Shuffle 阶段:这是“奇迹”发生的地方,MapReduce 的核心其实就是 Shuffle。那么 Shuffle 的原理呢?Shuffle 就是将 Map 的输出进行整合,然后作为 Reduce 的输入发送给 Reduce。简单理解就是把所有 Map 的输出按照键进行排序,并且把相对键
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 704
704




 到【灌水乐园】发言
到【灌水乐园】发言







