




基于Flask的京东商品信息可视化系统
一、介绍
使用爬虫爬取[京东服装信息]数据,对数据进行清洗、存储、分析展示,应用Python爬虫、Flask框架、Vue、Echarts等技术实现。此系统适用于目标网站任何类型的商品分析。
二、系统功能
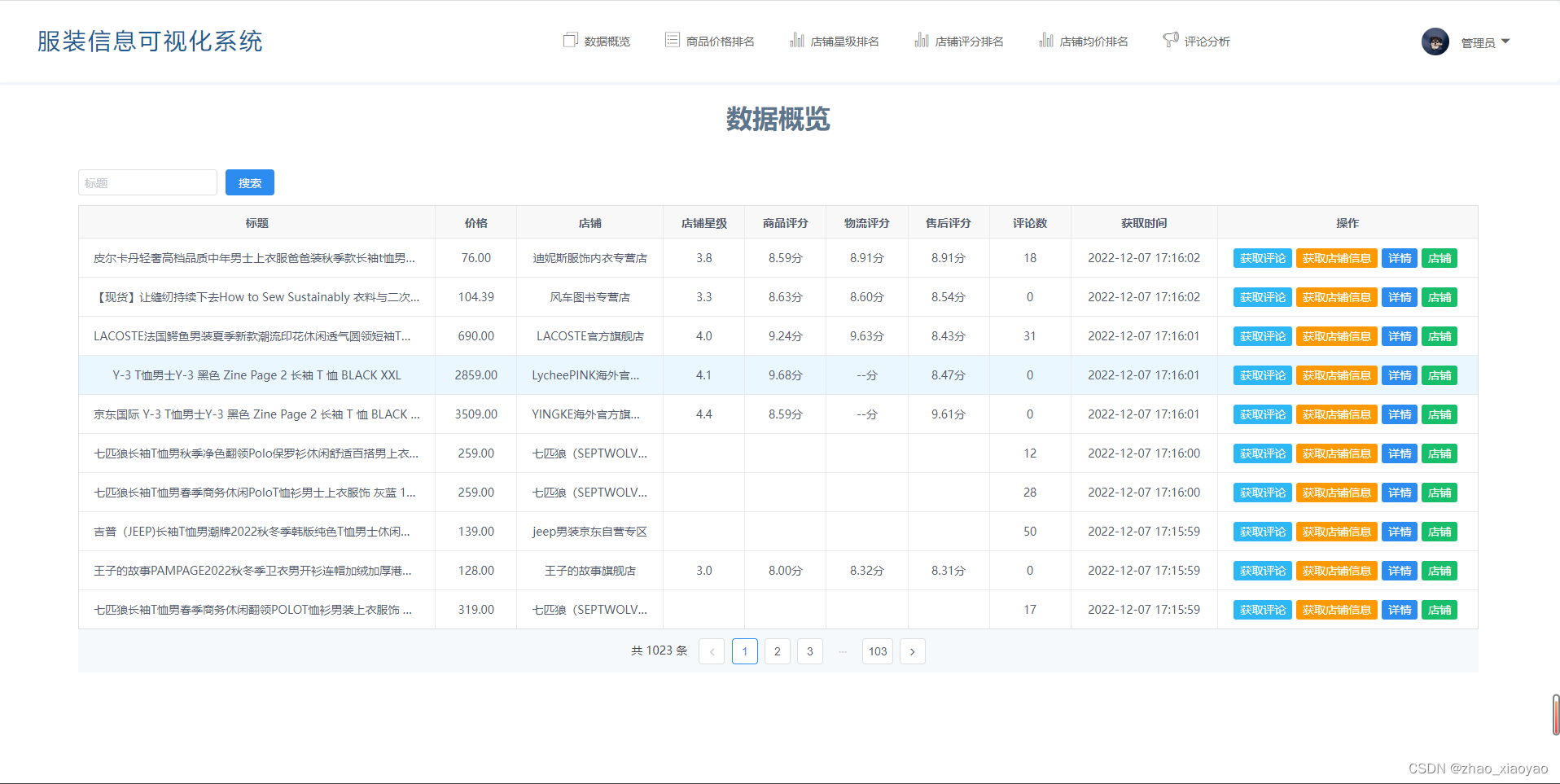
1、数据概览
使用爬虫爬取京东服装数据后,将数据在此模块进行展示。所有爬虫在文章后面进行介绍
搜索:输入商品标题,可对商品进行模糊查询
获取评论:管理员功能,点击此按钮调用获取评论爬虫,开始获取对应商品的评论信息,默认爬5页,可在程序中修改爬取页数
获取店铺信息:管理员功能,点击此按钮调用获取店铺信息爬虫,获取该商品对应店铺的信息,包括店铺星级、店铺评分等
详情:点击详情按钮,跳转到商品详情页面
店铺:点击按钮,跳转到店铺页面
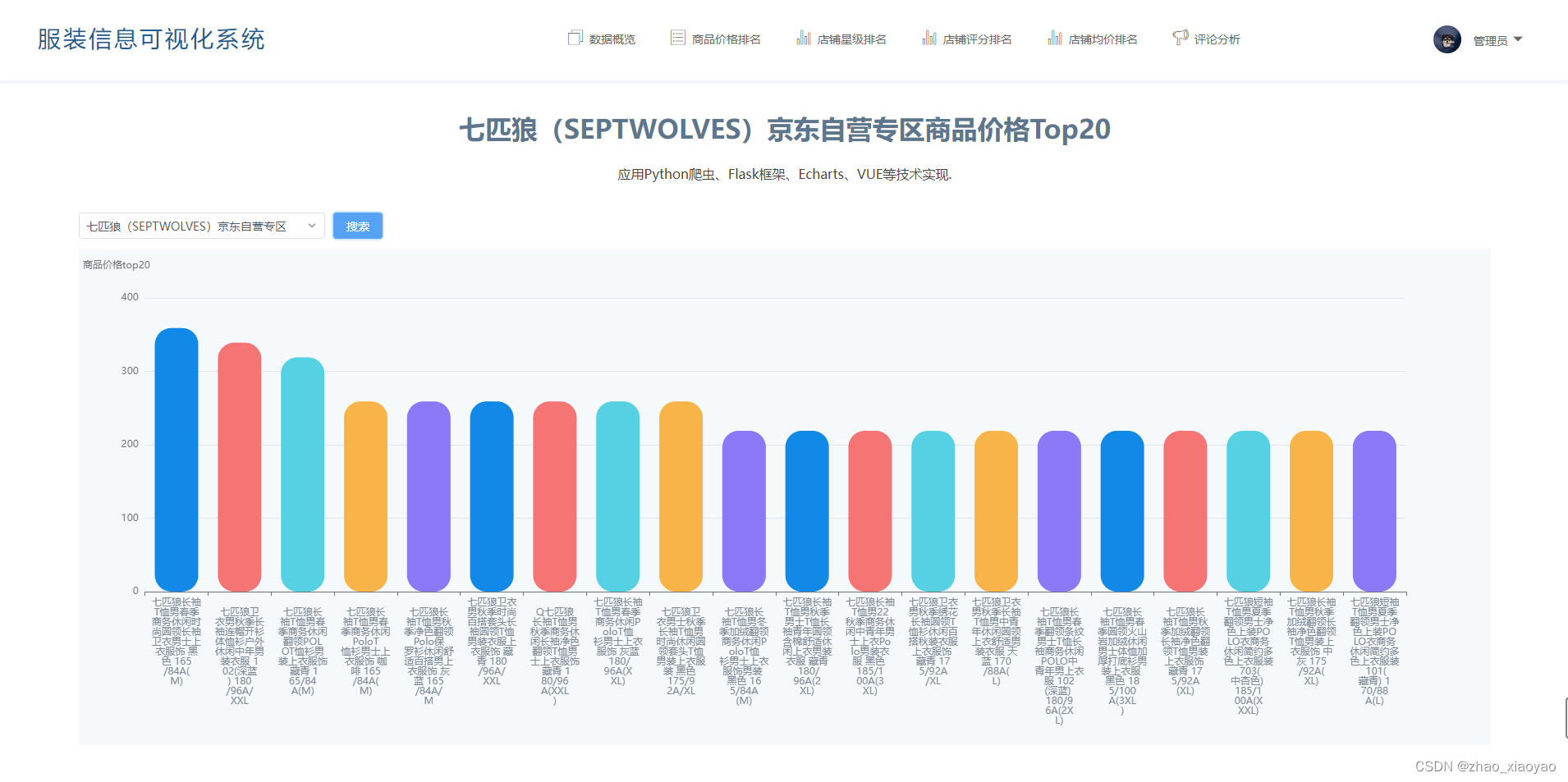
2、商品价格排名
将所有商品的价格进行排序,使用echarts柱状图从高到低展示前20条数据。支持按照店铺查询店内商品排名
搜索:选择店铺(可以输入)后点击搜索,查询该店铺所有商品排名
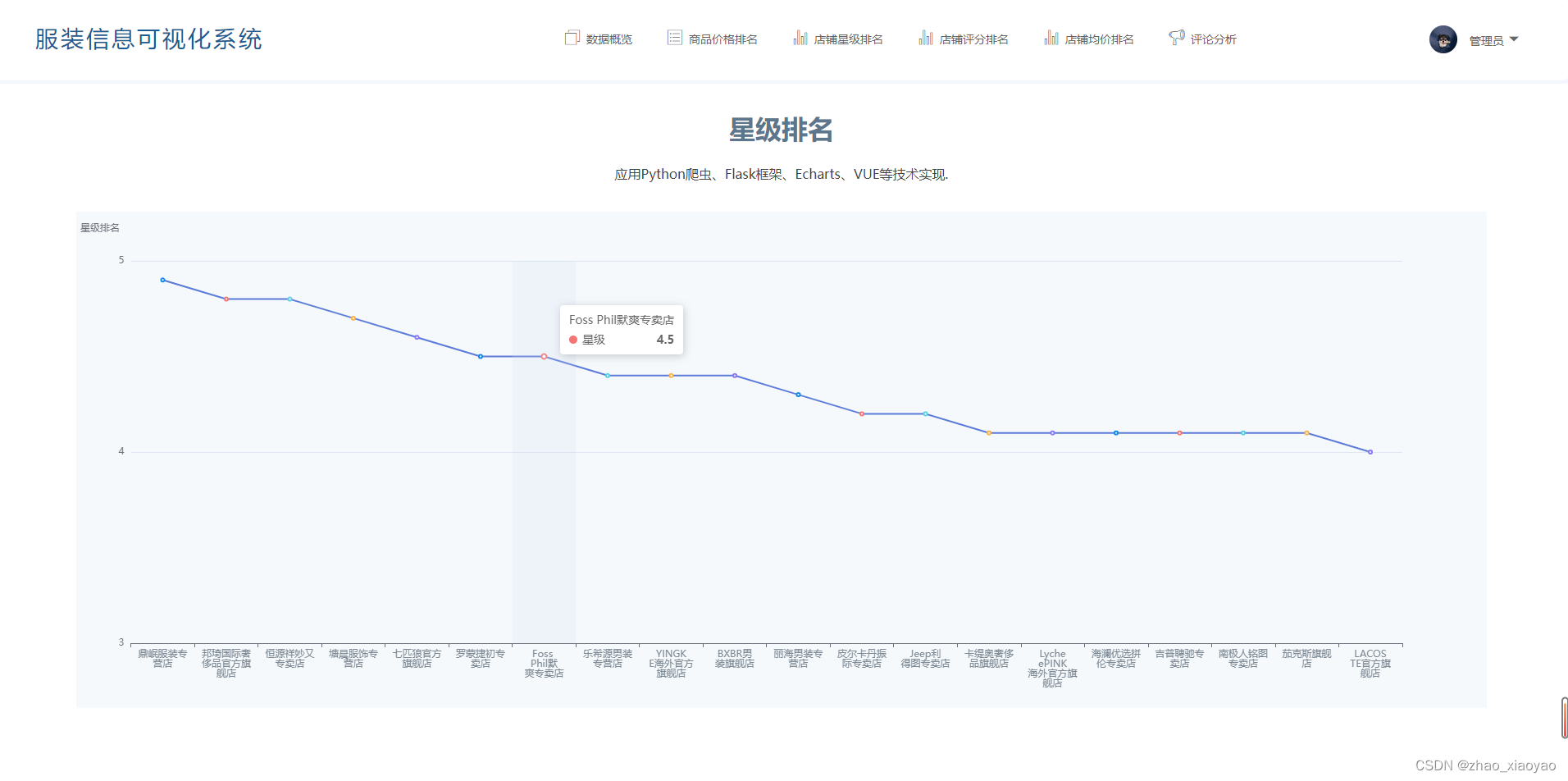
3、店铺星级排名
对已获取信息的店铺星级进行排序,使用echarts折线图进行展示。
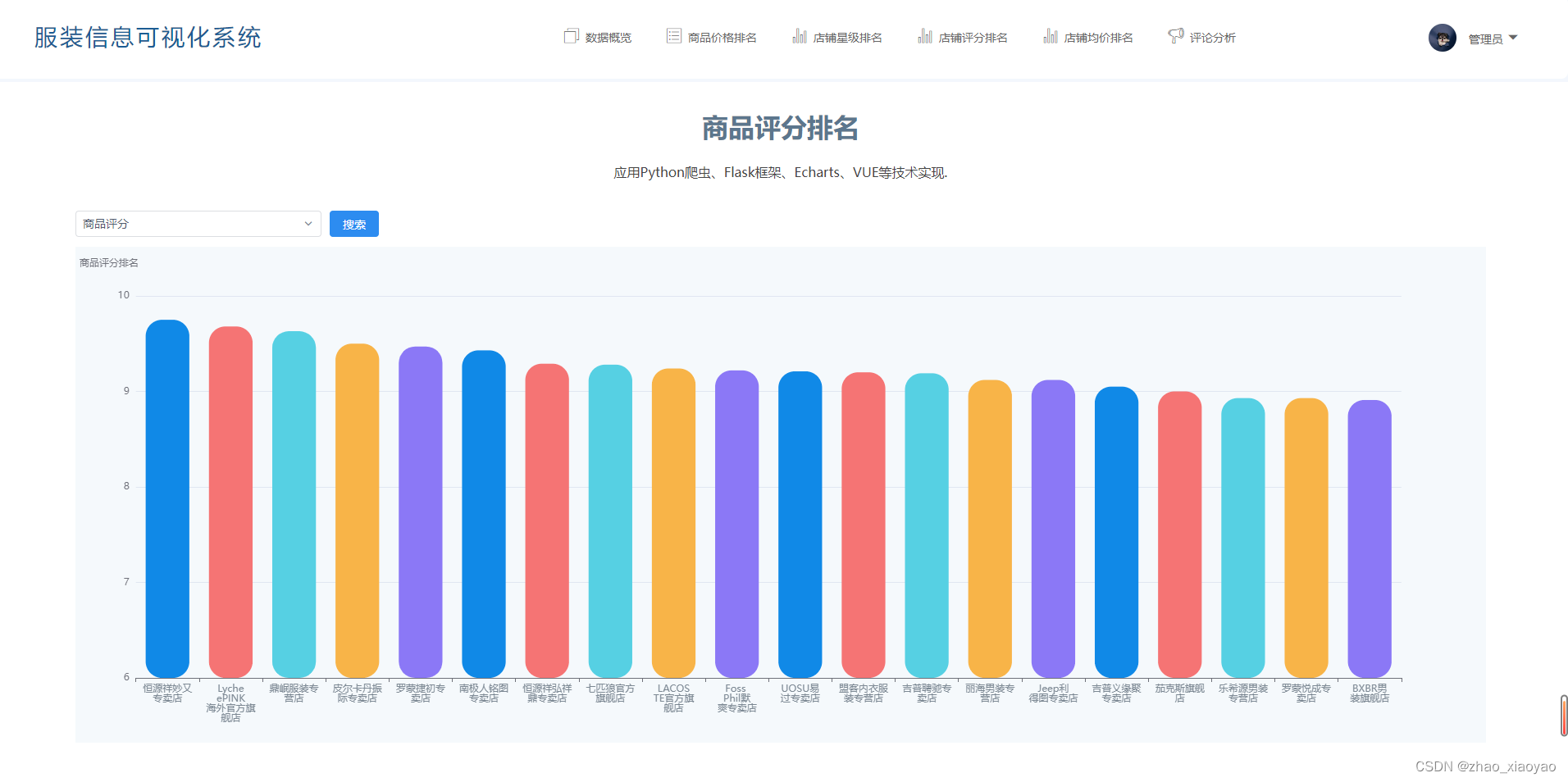
4、店铺评分排名
对已获取信息的店铺评分进行排序,可分别展示商品评分,物流评分和售后评分。
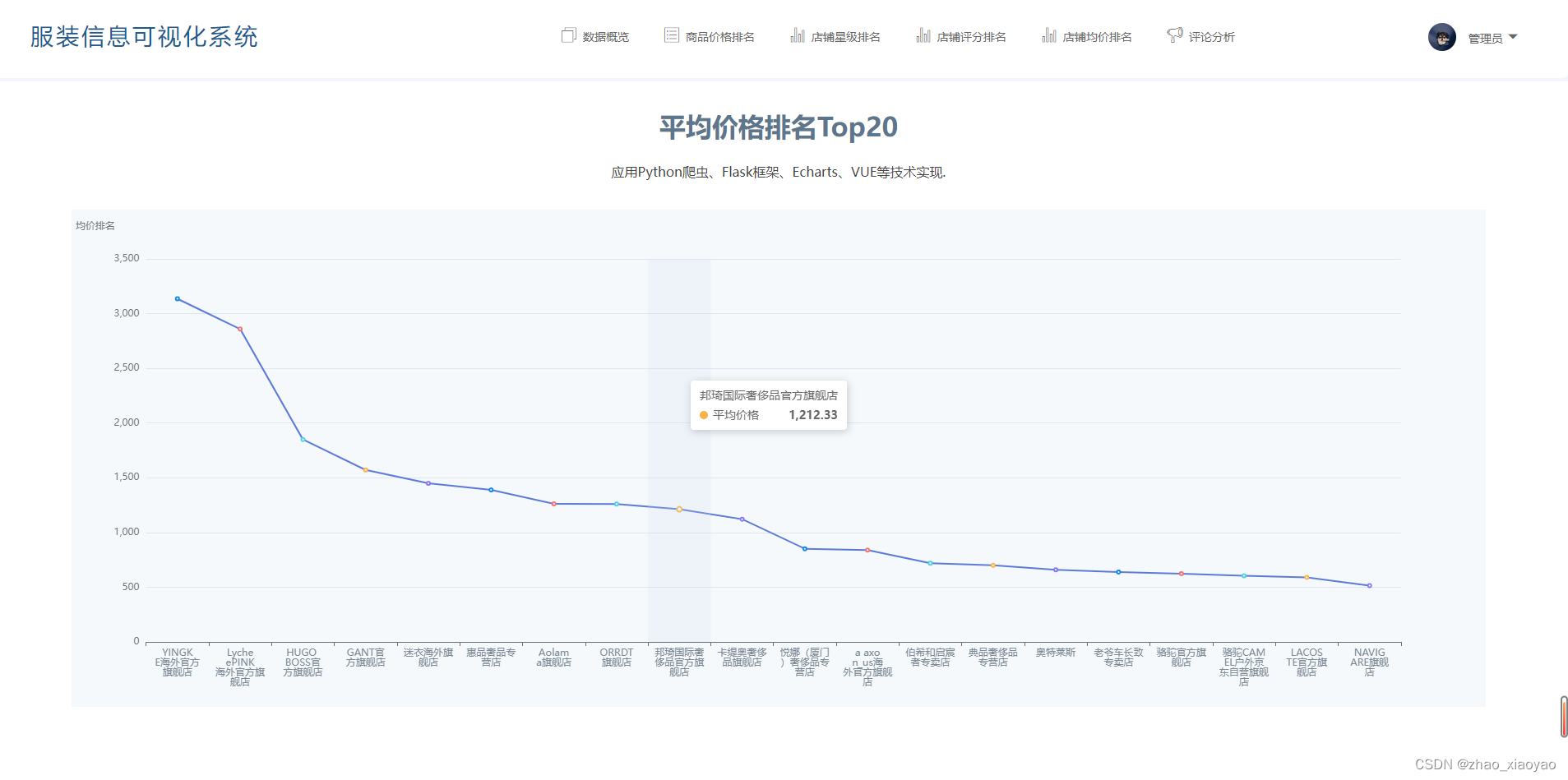
5、店铺均价排名
计算所有店铺的商品均价,使用echarts折线图从高到低展示前20条数据。
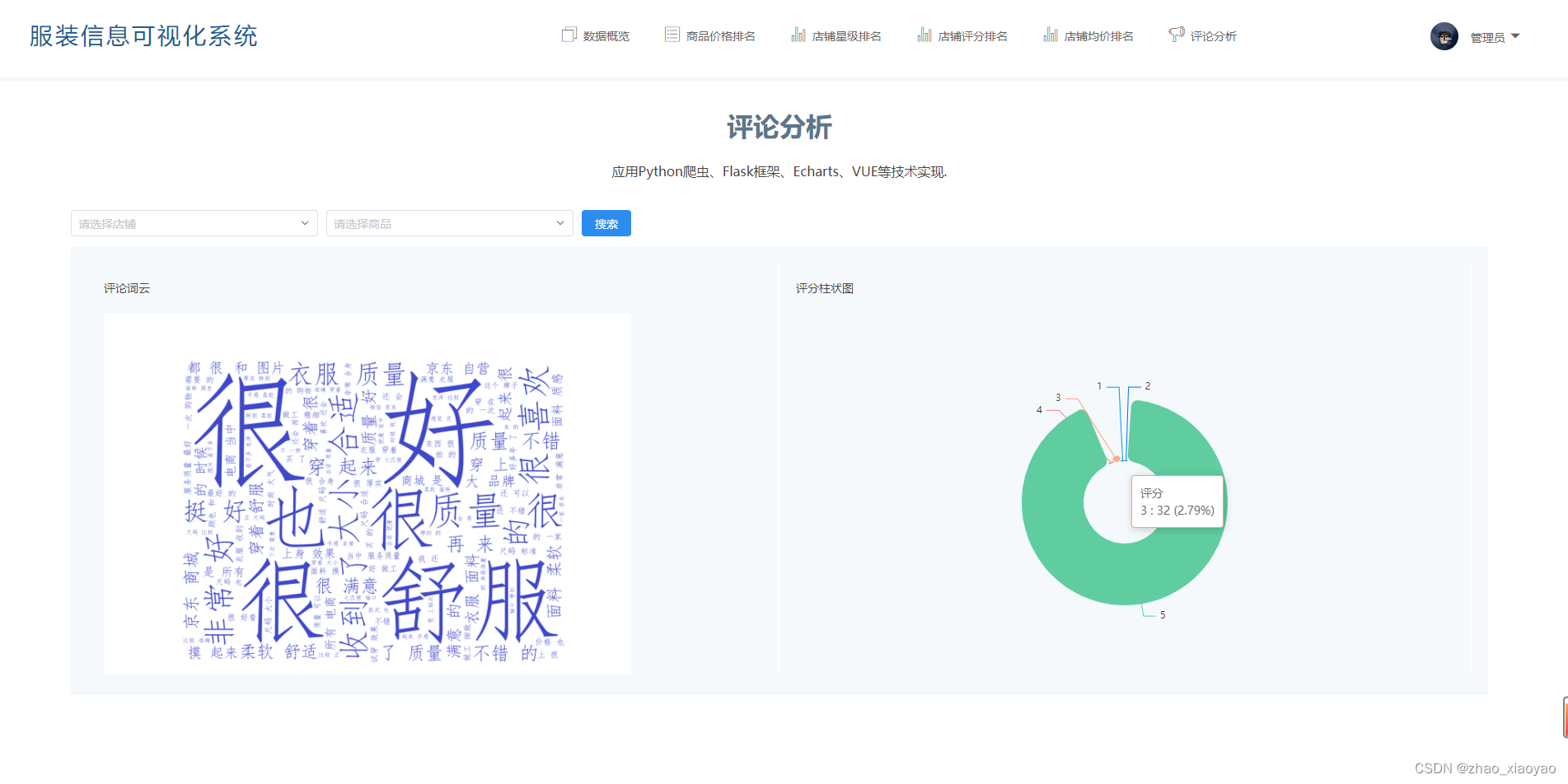
6、评论分析
展示评论信息的词云图和评分占比,使用词云和饼状图实现。可根据条件展示不同的结果
店铺空、商品空:展示所有数据的评论信息词云,以及评分占比
店铺不空、商品空:展示该店铺的评论信息词云,以及评分占比
店铺不空、商品不空:展示该商品的评论信息词云,以及评分占比
7、个人信息
用户查看个人信息,输入新的信息点击提交,可更新个人信息
9、修改密码
输入原密码与新密码,可修改密码
10、登录注册
用户登录注册
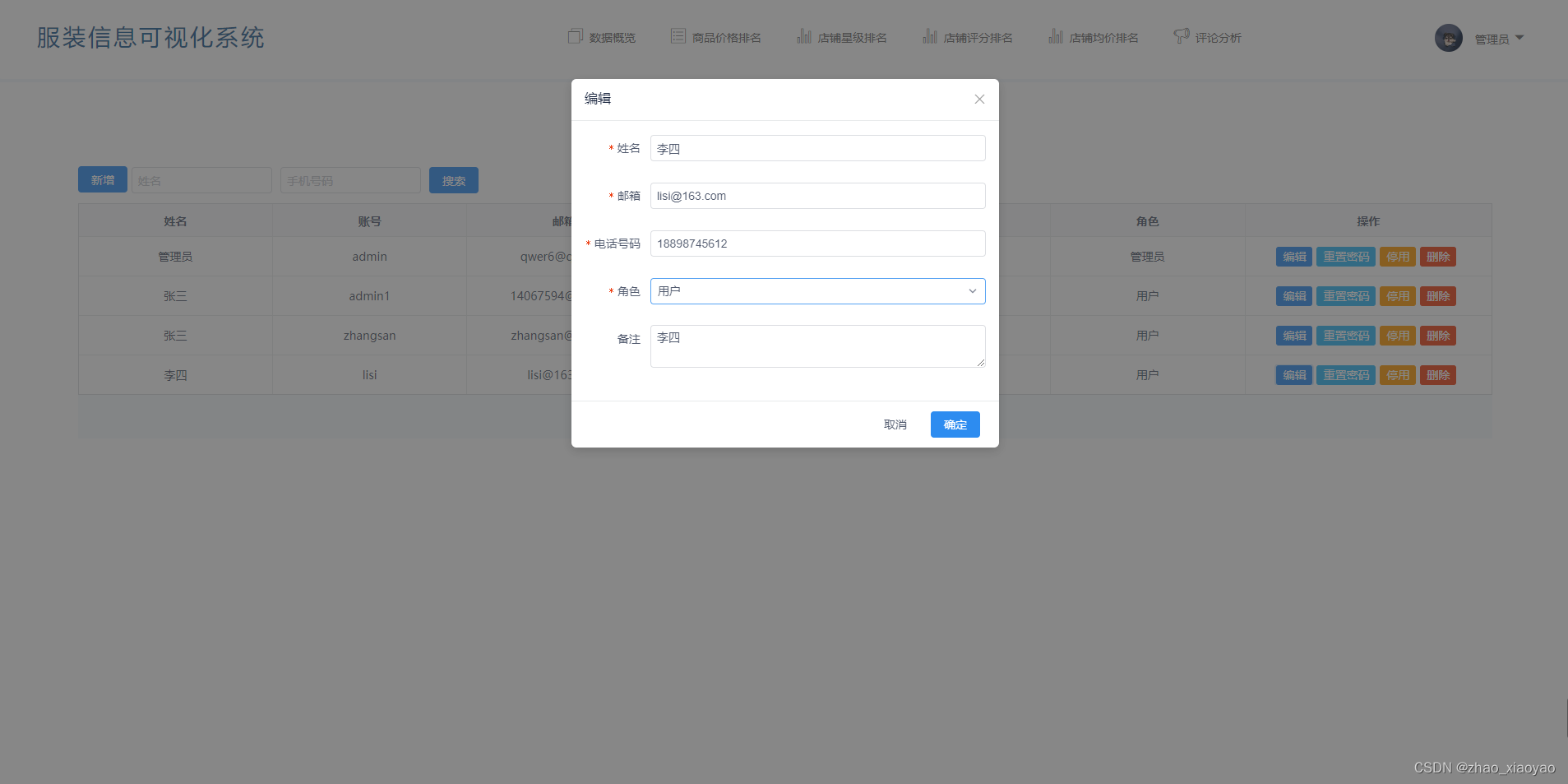
11、用户管理
该功能是管理员功能,管理用户信息
新增:点击新增按钮,输入用户信息,可添加新用户
搜索:输入用户名字和手机号码,点击搜索即可查询用户信息
编辑:编辑信息
重置密码:点击重置密码,可重置该用户密码
启用/停用:对用户账号状态进行修改,被停用的用户无法登录系统
删除:删除该账号
三、软件架构
后端
- python
- flask
前端
- vue
- iview
- echarts
python库
# 升级pip库,如果已升级可忽略
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip install --upgrade pip
# flask库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Flask
# pymysql
pip install pymysql
#requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
#xlwt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt
#jieba
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
#wordcloud
pip --default-timeout=100 install wordcloud
#lxml
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
#BeautifulSoup4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple BeautifulSoup4
#fake_useragent
pip install fake_useragent
四、安装教程
- 安装上述所有python库
- 启动flask
# 启动flask命令
python app.py
- 安装node.js
- 安装vue库
- 启动vue
# 安装vue库
npm i
# 启动vue
npm run serve
- 访问
http://localhost:8099/
五、工程目录结构
|jingdong
|-- jd_server 后端目录
|-- data 爬虫目录
|-- commit.py 评论爬虫
|-- goods.py 商品爬虫
|-- mysqlHelper.py mysql工具类
|-- shop.py 店铺信息爬虫
|-- app.py flask启动类
|-- bus_home.py 接口-业务相关
|-- bus_index.py 接口-系统管理
|-- cloud_commit.py 获取词云
|-- jd_web
|-- node_modules node包
|-- public 结构文件
|-- src
|--api 接口
|--assets 静态文件
|--components 系统组件
|--router 路由
|--store 路由
|--utils 工具类
|--views 页面
|-- tests 测试类
|-- vue.config.js vue配置类
六、表结构
|p_canyin
|-- tbl_goods 商品信息表
|-- tbl_shop 店铺信息表
|-- tbl_detail 商品评论表
|-- tbl_user 用户表
七、特别说明
此系统爬虫脚本仅可用户学习交流,切勿爬取大量数据,对网站服务器施压!!!
爬虫说明:
- goods.py
该爬虫用户爬取商品列表的商品信息,爬取前指定爬取页数,系统自动循环爬取
# 目标地址
https://search.jd.com/Search?keyword=%E6%9C%8D%E8%A3
# 防反爬设置
设置cookies,headers等信息,伪装成浏览器
每页爬取完延时5秒
# 参数设置
page:需要爬取的总页数
# 参考地址
https://www.bilibili.com/video/BV1XL41157Zw/?spm_id_from=333.337.search-card.all.click&vd_source=38baa41e7970816d06d61b5af65ad008
- commit.py
该爬虫用户爬取商取商品的评论信息
# 防反爬设置
设置cookies,headers等信息,伪装成浏览器
每页爬取完延时5秒
# 参数设置
page:需要爬取的总页数
detail_href:商品的详情地址(程序解析商品详情地址,获取商品id,根据商品id获取评论)
# 参考地址
https://www.cnblogs.com/lspis/p/16016374.html
- shop.py
爬取商品对应的店铺信息
# 放反爬设置
设置cookies,headers等信息,伪装成浏览器
# 参数设置
url:商品详情地址


















 2988
2988



 到【灌水乐园】发言
到【灌水乐园】发言







